BigQuery の仕組み: 高度なランタイムにおける短いクエリの最適化
Mohamed S. Hassan
Software Engineer
Stepan Yakovlev
Software Engineer
※この投稿は米国時間 2025 年 8 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
以前のブログ投稿では、BigQuery の高度なランタイムを紹介し、強化されたベクトル化について詳しく説明しました。また、辞書やランレングス エンコードされたデータ、ベクトル化されたフィルタ評価とコンピューティング プッシュダウン、並列化可能な実行などの手法についても説明しました。
このブログ投稿では、BigQuery の高度なランタイムの重要なコンポーネントである短いクエリの最適化について詳しく説明します。これらの最適化により、「短い」クエリを大幅に高速化できると同時に、BigQuery の「スロット」(計算能力)の使用量を減らすことができます。これらは、Looker Studio のようなビジネス インテリジェンス(BI)ツールや、BigQuery を活用したカスタム アプリケーションなどでよく使われています。
他の BigQuery 最適化手法と同様に、システムは一連の内部ルールを使用して、分散クエリプランを単一のより効率的なステップに統合して短いクエリを実行するかどうかを判断します。これらのルールでは、次のような要素が考慮されます。
- 読み取られるデータの推定量
- フィルタがデータサイズをどの程度効果的に削減しているか
- ストレージ内のデータの種類と物理的な配置
- クエリの全体的な構造
- 過去のクエリ実行のランタイム統計情報
ベクトル化の強化とともに、短いクエリの最適化は、BigQuery ユーザーのパフォーマンスと効率を継続的に向上させるための取り組みの一例です。
短いクエリの実行に特化した最適化
BigQuery のショートクエリ最適化により、対象となる短いクエリが大幅に高速化され、スロットの使用量が大幅に削減され、クエリのレイテンシが改善されます。通常、BigQuery はクエリを複数のステージに分割し、各ステージでより小さなタスクが分散システム全体で並列処理されます。ただし、適切なクエリの場合、短いクエリの最適化ではこの複数ステージの分散実行がスキップされるため、パフォーマンスと効率が大幅に向上します。また、可能であれば、結合や集計を含むクエリに対してもマルチスレッド実行を使用します。これらのクエリでは、クエリが適格であるかどうかが BigQuery によって自動的に判断され、単一のステージにディスパッチされます。BigQuery では、過去のクエリ実行から学習する履歴ベースの最適化(HBO)も採用されています。HBO は、クエリを単一ステージで実行するか、複数ステージで実行するかを、過去のパフォーマンスに基づいて BigQuery が判断できるようにします。これにより、ワークロードが進化しても、単一ステージのアプローチのメリットが維持されます。
データの全体像
短いクエリの最適化では、クエリ全体が 1 つのステージとして処理されるため、ランタイムは関係するすべてのテーブルを完全に把握できます。これにより、ランタイムは結合の両側を読み取り、列のカーディナリティなどの正確なメタデータを収集できます。たとえば、以下のクエリの結合列はカーディナリティが低いため、辞書エンコードとランレングス エンコード(RLE)を使用して効率的に保存されます。その結果、ランタイムは実行中にエンコードを利用することで、はるかに単純なクエリ実行プランを考案します。
次のクエリは、e コマースのシナリオで上位にランク付けされた商品とそのパフォーマンス指標を計算します。これは、短いクエリの最適化によってメリットが得られた、Google の内部データ パイプラインで確認されたクエリタイプに基づいています。次のクエリでは、この BigQuery 一般公開データセットを使用しているため、結果を再現できます。このブログ全体で紹介している指標は、Google の内部テスト中に取得されたものです。
図 1: クエリの例
シャッフル レイヤをスキップすることで、クエリの実行全体に必要な CPU、メモリ、ネットワーク帯域幅が少なくなります。さらに、短いクエリの最適化では、BigQuery の拡張ベクトル化についてのブログ投稿で説明されている拡張ベクトル化を最大限に活用します。
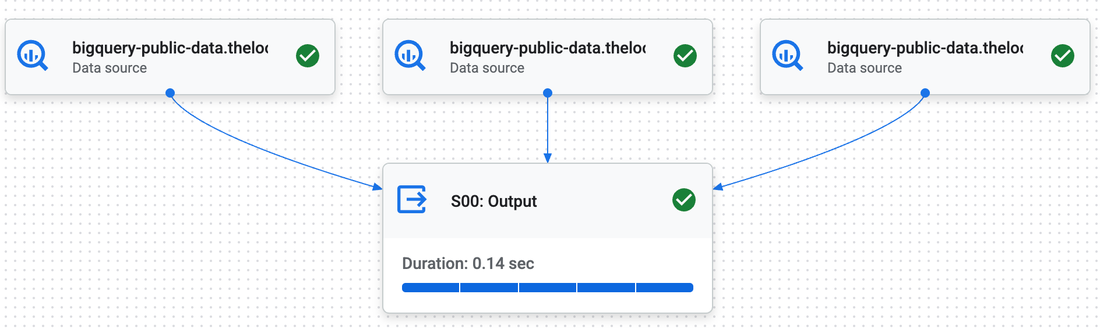
図 2: Google 内部テスト: 図 1 のクエリの内部テストの 1 段階計画。
結合と集計を含むクエリ
データ分析では、複数のテーブルのデータを結合して集計結果を計算するのが一般的です。通常、この分散オペレーションを実行するクエリは、多くのステージを経由します。各ステージでデータのシャッフルが行われる可能性があり、オーバーヘッドが増加して処理が遅くなります。BigQuery の短いクエリの最適化により、このプロセスを大幅に改善できます。有効にすると、BigQuery は、クエリ対象のデータ量が、より単純なプランで処理できる小ささかをインテリジェントに認識します。この最適化により、大幅な改善が実現します。図 3 で説明したクエリの場合、Google における内部テストでは、実行速度が 2 倍から 8 倍速くなり、スロット秒数が平均で 9 分の 1 に短縮されました。
図 3: 6 つのテーブルを結合してから集計を計算するクエリの例。
図 3 のクエリに短いクエリの最適化を適用すると、実行グラフがどのように変化するかを確認できます。

図 4: Google 内部テスト: BigQuery の分散実行を使用して結合集計クエリを 9 段階で実行。
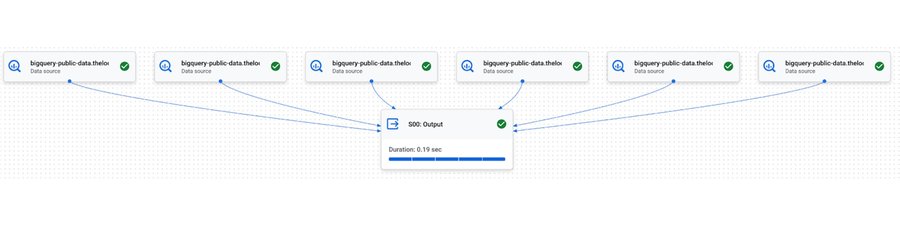
図 5: Google 内部テスト: 高度なランタイムの短いクエリの最適化により、結合集計クエリが 1 ステージで完了。
オプション ジョブ作成
短いクエリの最適化とオプション ジョブ作成モードは、クエリのパフォーマンスを向上させる、独立した補完的な 2 つの機能です。オプション ジョブ作成モードは、短いクエリの最適化に関係なく、短いクエリの効率に大きく貢献しますが、両方を組み合わせるとさらに効果的です。両方を有効にすると、高度なランタイムによって内部オペレーションが合理化され、クエリ キャッシュがより効率的に利用されるため、結果がさらに速く提示されます。
スループットの向上
クエリに必要なリソースを削減することで、短いクエリの最適化はパフォーマンスの向上だけでなく、全体的なスループットの大幅な改善も実現します。この効率性により、同じリソース割り当て内でより多くのクエリを同時に実行できます。
Google の内部データ パイプラインから取得した次のグラフは、短いクエリの最適化のメリットが得られるクエリの例を示しています。青い線は、維持できる最大 QPS(またはスループット)を示しています。赤い線は、高度なランタイムが有効になった後の同じ予約の QPS を示しています。レイテンシが改善されただけでなく、同じ予約で 3 倍以上のスループットを処理できるようになりました。
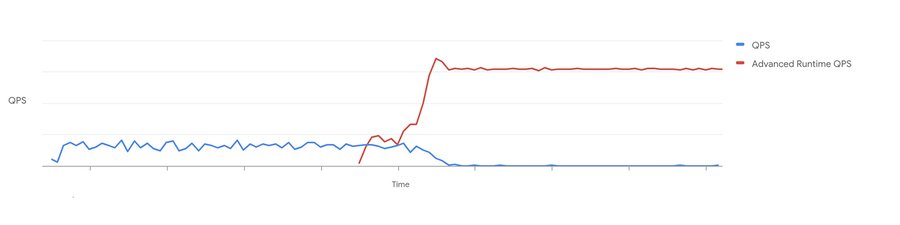
図 6: Google 内部テスト: スループットの比較。赤線は、高度なランタイムにおける短いクエリの最適化による改善を示しています。
最適な効果
BigQuery の短いクエリの最適化機能は、主に人間が読める出力を目的とした BI クエリ向けに設計されています。BigQuery は、動的アルゴリズムを使用して対象となるクエリを特定しますが、履歴ベースの最適化、BI Engine、オプションのジョブ作成など、パフォーマンスを向上させる他の機能と連携します。それでも、ワークロード パターンによっては、短いクエリの最適化が他のパターンよりも効果的です。
この最適化では、大量のデータの読み取りや生成が必要なクエリでは、改善があまりみられない可能性があります。短いクエリのパフォーマンスを最適化するには、事前集計とフィルタリングによってクエリのワーキング セットと結果のサイズを小さく保つことが重要です。ワークロードに適したパーティショニングとクラスタリングの戦略を実装することで、処理されるデータ量を大幅に削減できます。また、オプション ジョブ作成モードを利用すると、簡単に再試行できる短時間のクエリにメリットがあります。
短いクエリの最適化の動作
図 1 のクエリと図 2 のクエリプランを詳しく見て、これらの最適化がテストクエリに実際にどのような影響を与えるかを確認しましょう。クエリの形状は、本番環境で観測された実際のワークロードに基づいており、BigQuery の一般公開データセットに対して動作するように作成されているため、ご自身でテストできます。
クエリがスキャンするのは 6.5 MB のみですが、高度なランタイムなしでこのクエリを実行すると 1 秒以上かかり、約 20 スロット秒を消費します(実行時間はプロジェクトで利用可能なリソースによって異なる場合があります)。
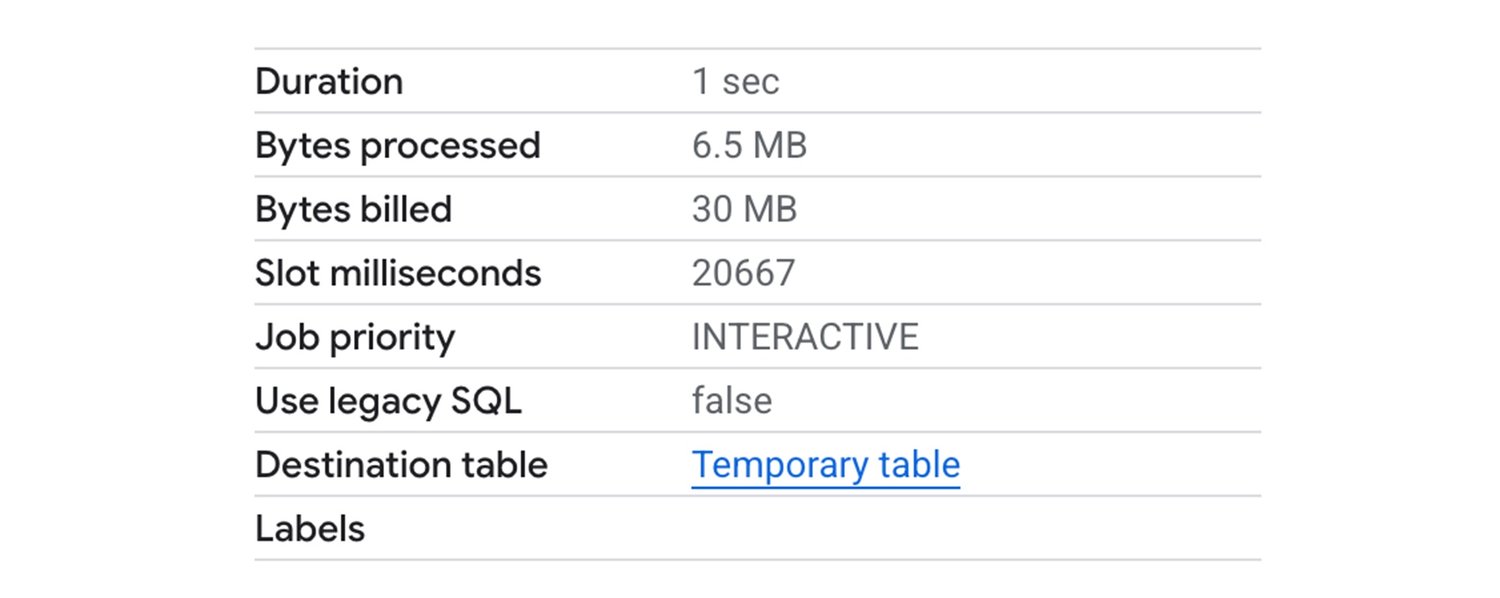
図 7: Google 内部テスト: 高度なランタイムを使用しない場合のサンプルクエリの実行の詳細
高度なランタイムにおける BigQuery のベクトル化の強化により、Google の内部テストでは、このクエリを 0.5 秒で完了させ、リソースの使用量を 50 分の 1 に抑えることができました。
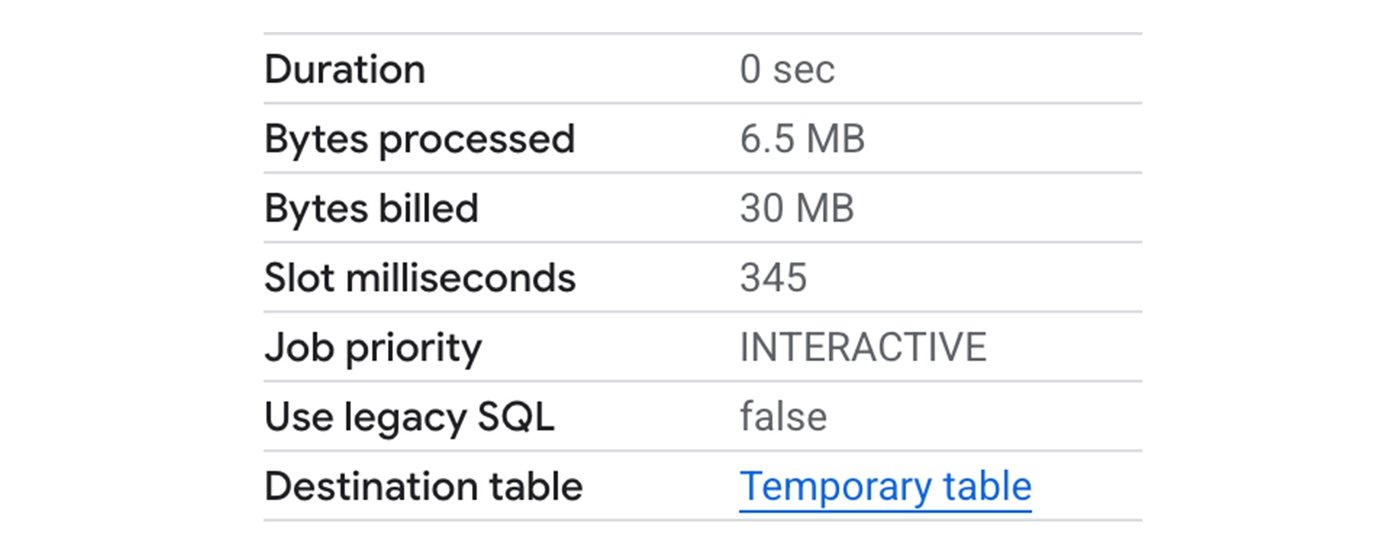
図 8: Google 内部テスト: 高度なランタイムの短いクエリの最適化を使用したクエリ実行の詳細の例
こちらは Google の内部パイプラインによる実際のワークロードの改善例ですが、このような規模の改善はさほど頻繁には見られません。また、複数の集計、フィルタ、グループ化、並べ替え、またはスノーフレーク結合を含む従来の BI クエリでも、パフォーマンスの向上とスロット使用率の改善が実現されています。
使ってみる
短いクエリの最適化により、クエリのコスト パフォーマンスが向上し、一般的な BI の小さなクエリのスループットが向上し、レイテンシが短縮されます。これを実現するために、最先端のアルゴリズムと、ストレージ、コンピューティング、ネットワーキングにわたる Google の最新のイノベーションを組み合わせています。これは、強化されたベクトル化、履歴ベースの最適化、オプションのジョブ作成モード、列メタデータ インデックス(CMETA)など、Google が BigQuery のお客様に継続的に提供している多くのパフォーマンス改善の 1 つにすぎません。
高度なランタイムの 2 つの主要な柱が公開プレビュー版で利用可能になったため、こちらに記載されているように、単一の ALTER PROJECT コマンドを使用して有効にするだけでワークロードでテストしていただけます。これにより、ベクトル化の強化と短いクエリの最適化の両方が可能になります。拡張ベクトル化ですでに有効にしている場合は、短いクエリの最適化も自動的に有効になります。
BigQuery の高度なランタイムに関するドキュメント(こちら)の手順に沿って、ご自身のワークロードで今すぐお試しください。フィードバックやご意見は bqarfeedback@google.com までお寄せください。
-ソフトウェア エンジニア、Mohamed S. Hassan
-ソフトウェア エンジニア、Stepan Yakovlev




