新しいデータ サイエンティスト: アナリストからエージェント アーキテクトへ
Yasmeen Ahmad
Managing Director, Data Cloud, Google Cloud
※この投稿は米国時間 2025 年 9 月 25 日に、Google Cloud blog に投稿されたものの抄訳です。
データ サイエンティストの役割は急速に変化しています。過去 10 年間、同社の使命は、過去を分析してビジネス上の意思決定に役立つ予測モデルを実行することでした。しかし、今ではそれだけでは不十分です。市場は現在、企業に代わって推論、行動、学習できるインテリジェントな自律エージェントを設計、デプロイして未来を築くことをデータ サイエンティストに求めています。
この移行により、データ サイエンティストはアナリストからエージェント アーキテクトへと変わります。しかし、断片化されたノートブック、サイロ化されたデータシステム、複雑な本番環境への移行パスなど、従来のツールは創造的な流れを妨げる摩擦を生み出します。
Google は、Big Data London において、これらの課題に対処するために設計された、AI ネイティブ スタック上に構築された次世代のデータ イノベーションを発表します。これらの機能により、データ サイエンティストは以下が可能になり、分析を超えて行動が可能になります。
-
コンテキストの切り替えに時間を費やすのはもうやめましょう。Google は、SQL、Python、Spark を即座に組み合わせて使用できる単一のインテリジェントなノートブック環境を提供しています。これにより、ツールを操作するのではなく、1 か所で構築とイテレーションを行うことができます。
-
現実世界を理解するエージェントを構築します。エージェントがスマートでコンテキストを認識した意思決定を行うために必要な、ライブイベント ストリームや非構造化データなどの、煩雑なリアルタイム データに、SQL ベースでネイティブにアクセスできます。
-
プロトタイプから本番環境まで、数分で移行できます。単一のノートブックから安全な本番環境グレードの自律エージェント フリートにロジックを移行するための完全な「構築、デプロイ、接続」ツールキットを提供しています。
データ サイエンスの環境を統合
データ サイエンスの生産性における最大の課題は、摩擦です。データ サイエンティストは、常に強制的にコンテキストを切り替える状態に置かれています。あるクライアントで SQL を記述し、データをエクスポートして Python ノートブックに読み込み、重い処理のために別の Spark クラスタを構成し、結果を可視化するために BI ツールに切り替えるといった作業を繰り返しています。切り替えのたびに、ユーザーが真の何かを発見する「フロー状態」が途切れてしまいます。Google の優先事項は、予測モデルを実行するだけでなく、アーキテクトがエンジニアリング、構築、デプロイに必要な単一のインテリジェントな環境を作成することで、この摩擦を解消することです。
このたび、BigQuery と Vertex AI の Colab Enterprise ノートブックに基本的な機能強化が導入されました。ネイティブ SQL セル(プレビュー版)が追加されたため、SQL クエリと Python コードを同じ場所で反復処理できるようになりました。これにより、SQL を使用してデータを探索し、結果をすぐに BigQuery DataFrame に送って Python でモデルを構築できます。さらに、豊富なインタラクティブな可視化セル(プレビュー版)では、データから編集可能なグラフが自動的に生成されるため、分析をすばやく評価できます。この統合により、SQL、Python、可視化の間の障壁が取り除かれ、ノートブックはデータ サイエンス タスクの統合開発環境へと変わります。
しかし、統合環境はソリューションの半分にすぎません。インテリジェントである必要もあります。これが、Colab 内で「インタラクティブなパートナー」として機能する データ サイエンス エージェントの力です。このエージェントの最近の機能強化により、 高度なツール使用(プレビュー版)を詳細な計画に組み込めるようになりました。これには、トレーニングと推論に BigQuery ML を使用すること、Python を使用した分析に BigQuery DataFrames を使用すること、大規模な Spark 変換などが含まれます。つまり、分析がより高度になり、要求の厳しいワークロードをより費用対効果の高い方法で実行でき、モデルをより迅速に本番環境に移行できるのです。
また、Lightning Engine の一般提供も開始します。Lightning Engine は、 Spark のパフォーマンスをオープンソースの Spark と比較して 4 倍以上高速化します。Lightning Engine はデフォルトで ML と AI に対応しており、BigQuery Notebooks、Vertex AI、VS Code とシームレスに統合されます。つまり、ノートブックでの初期探索から Vertex AI での分散トレーニングまで、ワークフロー全体で同じ高速化された Spark ランタイムを任意のツールで使用できるということです。また、Spark 4.0(プレビュー版)の高度なサポートも発表し、最新のイノベーションを直接お客様にお届けします。
現実世界を理解するエージェントの構築
エージェント アーキテクトは、世界をリアルタイムで感知して対応するシステムを構築します。これには、ライブイベント ストリームや非構造化データなど、これまで別々の専用システムにサイロ化されていたデータへのアクセスが必要です。この課題に対処するため、Google はデータ サイエンス チームがリアルタイム ストリームと非構造化データにアクセスしやすくしています。
まず、SQL を使用してリアルタイム データを処理するために、BigQuery 継続的クエリ (プレビュー版)のステートフル処理を発表します。以前は、ライブデータに対して SQL を使用するだけでは、時間の経過に伴うパターンに関する質問をすることが困難でした。この新機能により、状況が変わります。SQL クエリに「メモリ」が与えられ、複雑な状態認識型の質問をすることができます。たとえば、単一のトランザクションを見るだけでなく、「このクレジットカードの過去 5 分間の平均トランザクション値は突然 300% 急増したか?」と質問できます。エージェントは、個々のアラートを確認する人間のアナリストでは見逃すような、この不審な速度パターンを検出できるようになりました。そして、大規模な不正請求が行われる前に、カードの一時的なブロックを事前にトリガーします。これにより、リアルタイムの不正行為検出から、新しい攻撃パターンを学習して特定する適応型セキュリティ エージェントまで、強力な新しいユースケースが実現します。
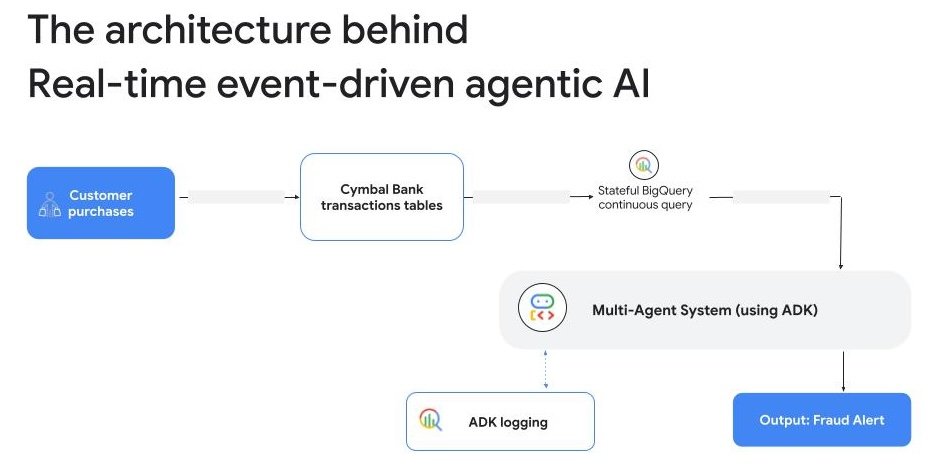
2 つ目は、マルチモーダル データに対する BigQuery の自律型エンベディング生成(プレビュー版)によってデータチームを支援し、ベクトルデータベースを使用した AI アプリケーションの構築における摩擦を解消することです。BigQuery ベクトル検索の機能を利用することで、ベクトル エンベディングを作成して更新するためだけに、複雑なデータ パイプラインを別途構築、管理、維持する必要がなくなります。BigQuery では、データが到着したときや、ユーザーが自然言語で新しい用語を検索したときに、これが自動的に処理されるようになりました。この機能により、エージェントはユーザーの意図を企業データに結び付けることができます。この機能はすでに、Morrisons の店舗内商品検索システムなどのシステムを強化しており、忙しい日には 50,000 件の顧客検索を処理しています。スーパーマーケットを歩き回りながら、スマートフォンで商品検索ツールを使用できます。商品名を入力するだけで、その商品がどの通路のどの部分にあるかをすぐに確認できます。システムはセマンティック検索を使用して特定の商品 SKU を特定し、リアルタイムの店舗レイアウトと商品カタログデータをクエリします。
信頼できる本番環境対応のマルチエージェント開発
アナリストがレポートを提出して、仕事が完了したとき。アーキテクトが自律型アプリケーションやエージェントをデプロイするとき、その仕事は始まったばかりです。ノートブックをプロトタイプとして使用するのではなく、エージェントをプロダクトとして使用するこの移行により、新たな重要な課題が生じます。それは、ノートブックのロジックを、スケーラブルで安全な、本番環境に対応したエージェントのフリートにどのように移行するかということです。
これを解決するために、Google はエージェント アーキテクト向けの完全な「構築、デプロイ、接続」ツールキットを提供しています。まず、Agent Development Kit(ADK) は、ロジックを構築、テスト、オーケストレーションして、専門的な本番環境グレードのエージェントのフリートに組み込むためのフレームワークを提供します。このようにして、単一ファイルのプロトタイプから堅牢なマルチエージェント システムに移行します。このエージェント フリートは、問題を見つけるだけでなく、それに対処します。ADK を使用すると、エージェントはインテリジェントな自律的アクションを実行して「ループを閉じる」ことができます。たとえば、アラートのトリガーから、ServiceNow や Salesforce などの運用システムで詳細なケースファイルを作成して入力するまでを自動化できます。
これまで大きな課題となっていたのは、これらのエージェントをエンタープライズ データに安全に接続することでした。そのため、デベロッパーは独自のカスタム統合を構築して維持する必要がありました。この問題を解決するために、Google は ADK 内に直接統合された、または MCP 経由のファーストパーティの BigQuery ツールをリリースしました。これらは Google が管理する安全なツールで、エージェントがデータセットをインテリジェントに検出したり、テーブル情報を取得したり、SQL クエリを実行したりできます。これにより、チームは基盤となる配管ではなく、エージェントのロジックに集中できます。さらに、MCP ツールボックスを使用することで、エージェント フリートを Google Cloud の任意のデータ プラットフォームに簡単に接続できるようになりました。BigQuery、AlloyDB、Cloud SQL、Spanner で利用可能な MCP Toolbox は、エージェント フリート向けの安全でユニバーサルな「プラグ」を提供し、エージェントをデータソースと機能に必要なツールに接続します。
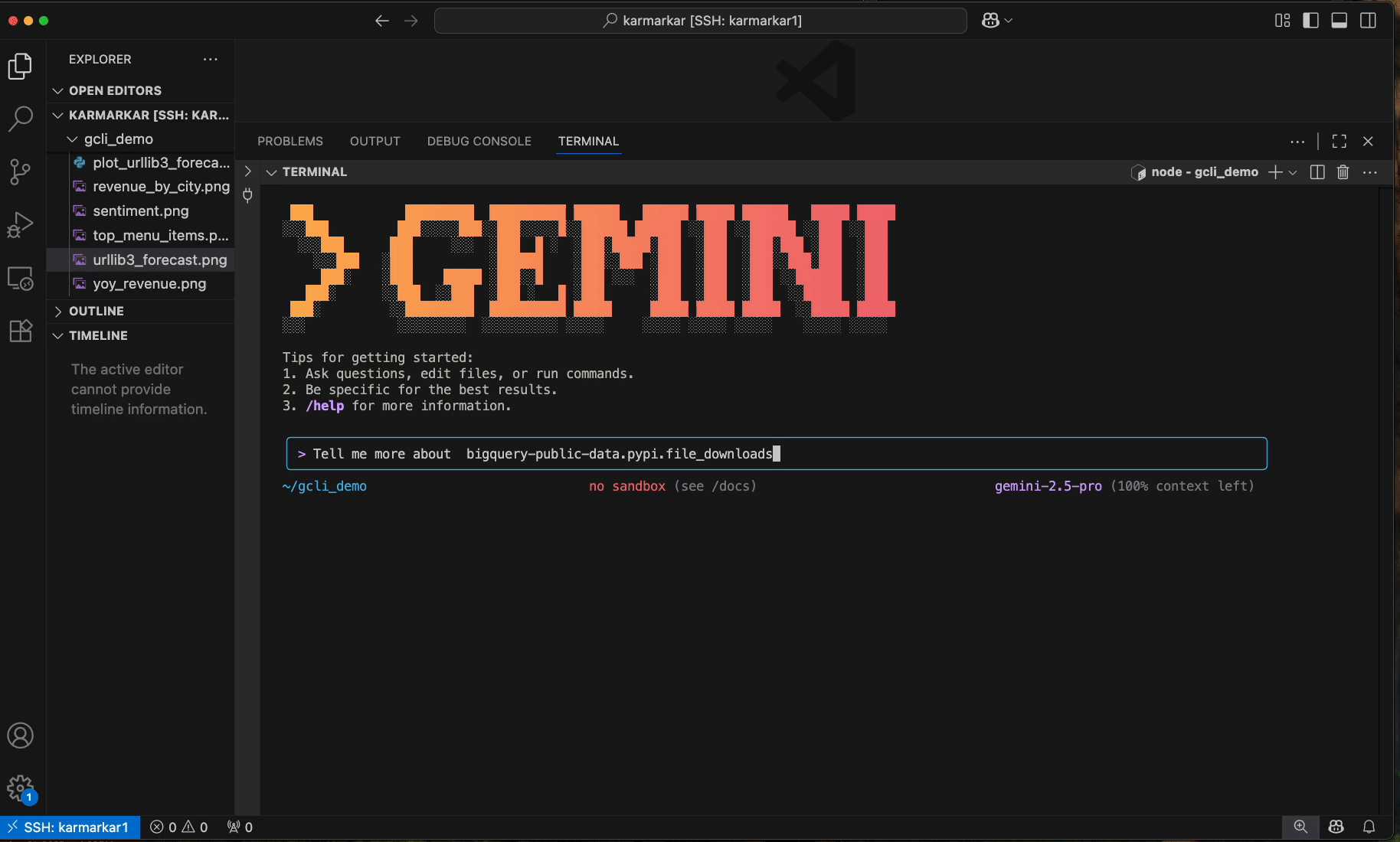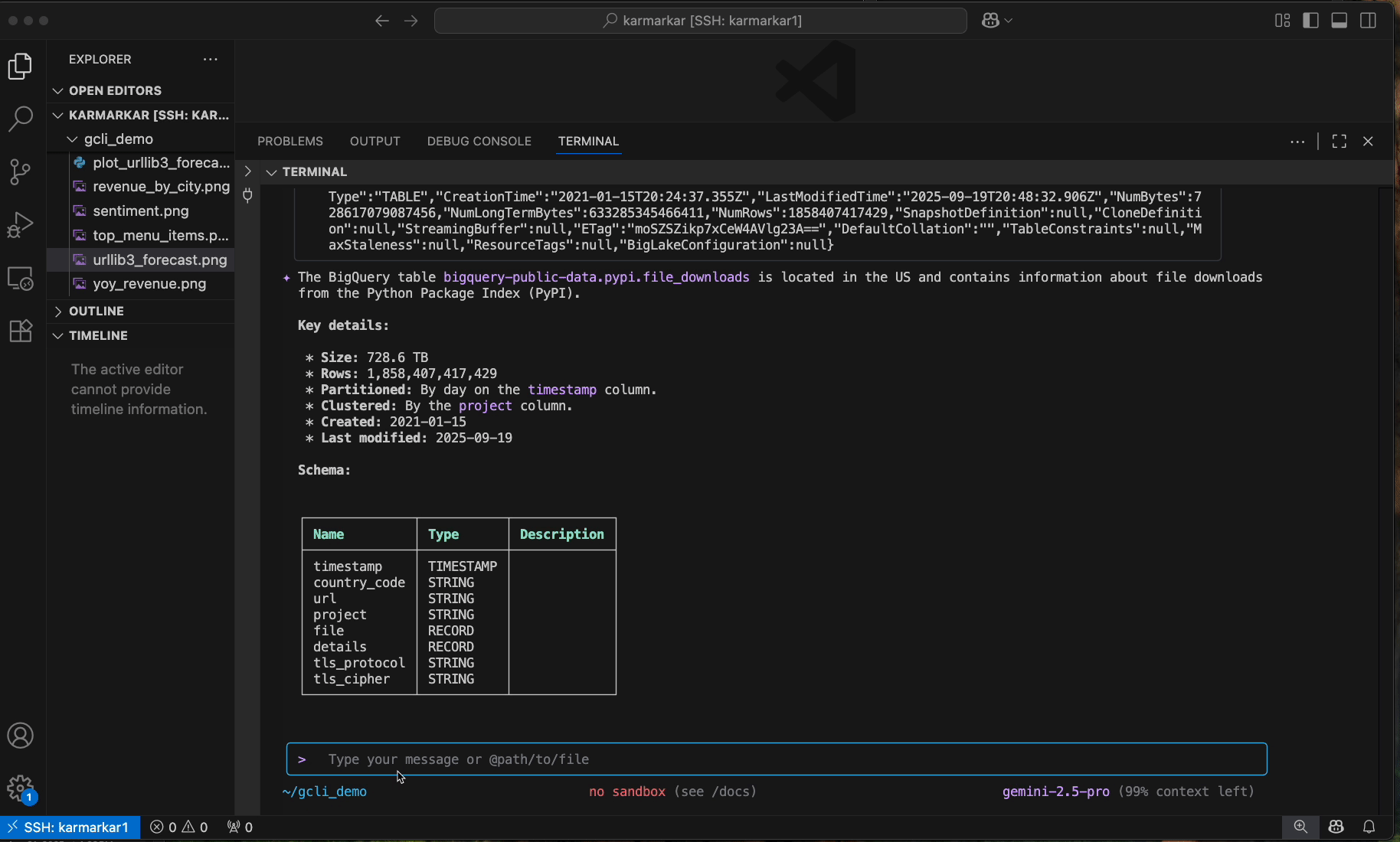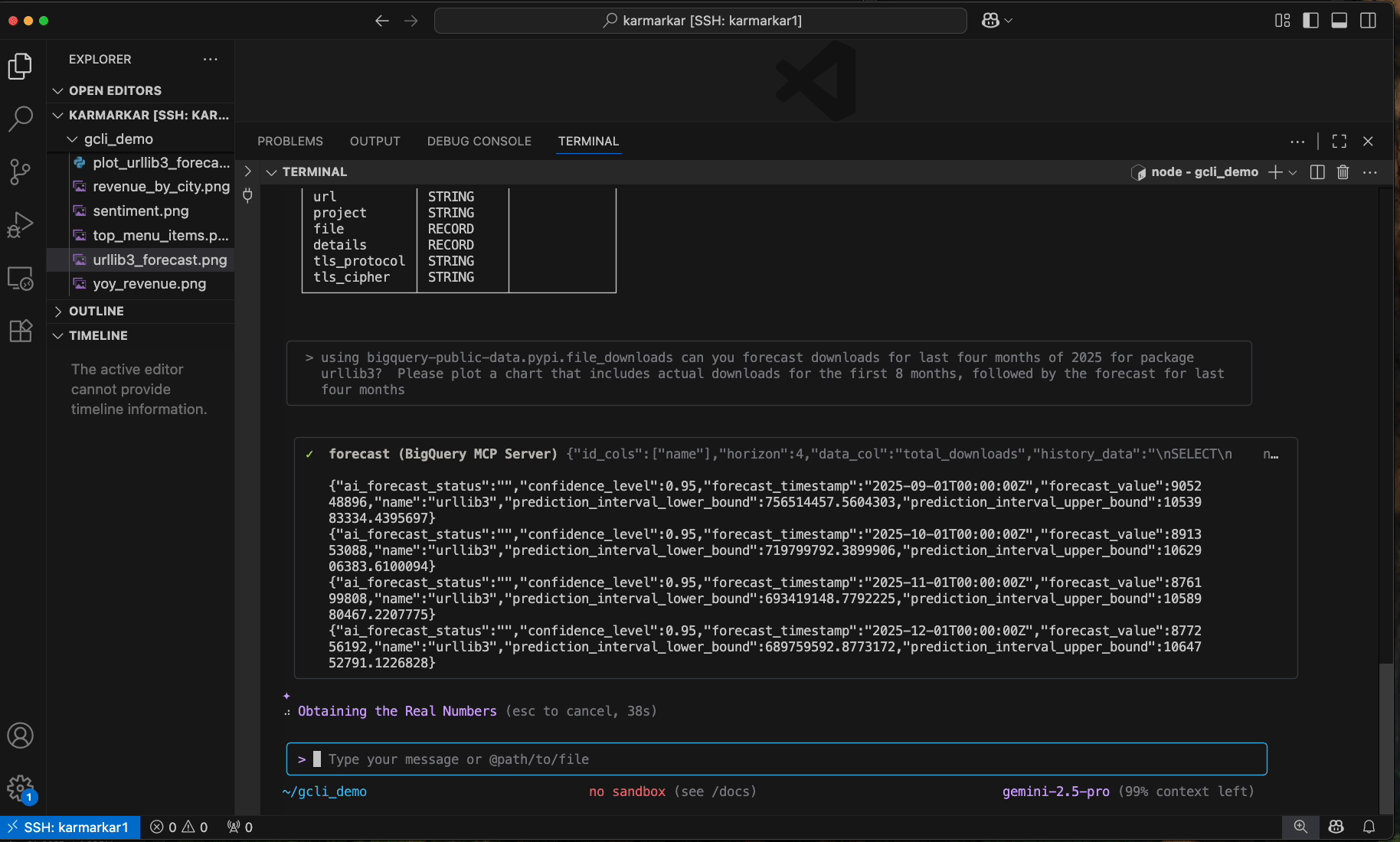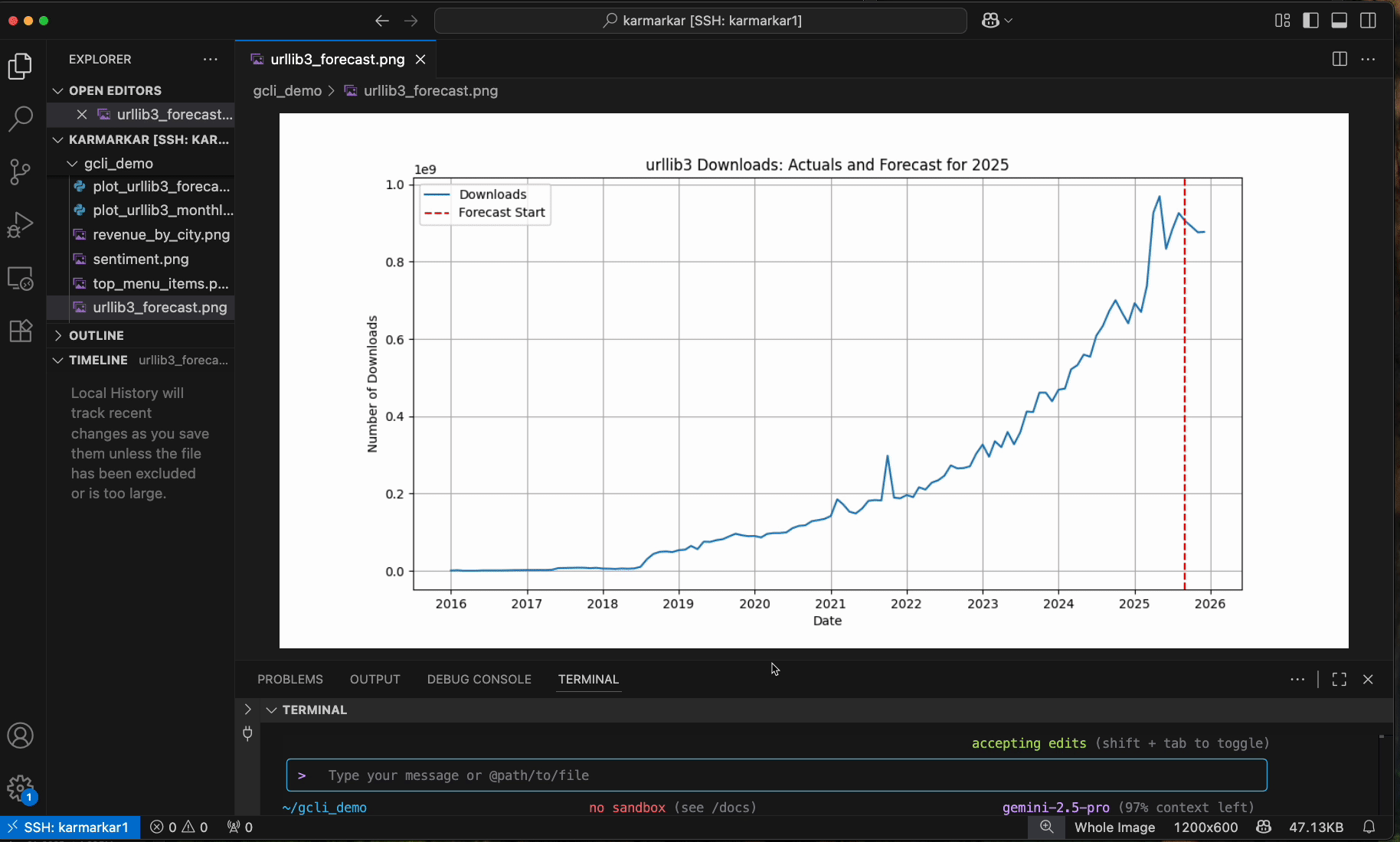
この「構築、デプロイ、接続」ツールキットは、アーキテクト自身のワークフローにも拡張されます。ADK はエージェントがデータに接続するのに役立ちますが、アーキテクト(人間の開発者)は、コマンドライン(CLI)という新しいプライマリ インターフェースを使用してこのシステムを管理する必要があります。データタスクのために UI に切り替えるという煩わしさを解消するため、Google は新しい Gemini CLI 拡張機能(Data Cloud 向け、プレビュー版)でデータタスクをターミナルに直接統合しています。エージェント型の Gemini CLI を使用すると、開発者は自然言語を使用してデータセットの検索、データの分析、予測の生成を行うことができます。たとえば、ターミナルを離れることなく、gemini bq "analyze error rates for 'checkout-service'" と入力するだけで、結果を Matplotlib などのローカルツールにパイプできます。
未来を設計する
これらのイノベーションにより、データ サイエンティストが組織内で与える影響は大きく変化しました。AI ネイティブ スタックを使用することで、開発環境を新しい方法で統合し、データの境界を拡大し、信頼できる本番環境対応の開発が実現しています。
タスクを自動化し、エージェントを使用して、組織がインテリジェンスで感知、推論、行動できるように支援するエージェント アーキテクトになることが可能です。この変革を体験してみませんか?8 つの実用的なユースケースとノートブックを掲載した新しいデータ サイエンスの電子書籍をご覧ください。今すぐ構築を始められます。
- Google Cloud、データクラウド担当マネージング ディレクター、Yasmeen Ahmad


