BigQuery のフルマネージド リモート MCP サーバーでデータ分析エージェントを迅速に構築
Vikram Manghnani
Technical Program Manager
Prem Ramanathan
Software Engineer
※この投稿は米国時間 2026 年 1 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
AI エージェントをエンタープライズ データに接続するのに、複雑なカスタム統合や数週間の開発作業が必要であってはなりません。先月、フルマネージドのリモート Model Context Protocol(MCP)サーバー(Google サービス用)がリリースされたことで、BigQuery MCP サーバーを使用して、データを直接かつ安全に分析する手段を AI エージェントに提供できるようになりました。このフルマネージド MCP サーバーを使うと、管理上のオーバーヘッドが削減され、インテリジェント エージェントの開発に集中できるようになります。
BigQuery の MCP サーバーのサポートは、サーバーの柔軟性と制御性を高めたいユーザー向けに設計されたオープンソースのデータベース向け MCP ツールボックスでも利用できます。このブログ投稿では、2026 年 1 月時点でプレビュー版としてリリースされているフルマネージドのリモート BigQuery サーバーの統合について説明し、デモを行います。
リモート MCP サーバーはサービスのインフラストラクチャで実行され、AI アプリケーションに HTTP エンドポイントを提供します。これにより、定められた標準仕様に基づいて AI MCP クライアントと MCP サーバー間の通信が可能になります。

MCP は、定義されたツールセットを通じて LLM 搭載アプリケーションが分析データに直接アクセスできるようにすることで、AI エージェントの構築プロセスを加速します。Google OAuth 認証メソッドを使用して BigQuery MCP サーバーを ADK と統合するのは簡単です。詳しくは、Agent Development Kit(ADK)と Gemini CLI についての以下の説明をご覧ください。LangGraph、Claude コード、Cursor IDE、その他の MCP クライアントなどのプラットフォームやフレームワークも、大きな労力をかけずに統合できます。
では詳しく見ていきましょう。
ADK で BigQuery MCP サーバーを使用する
ADK を使用して BigQuery エージェントのプロトタイプを構築する手順は次の 6 つです。
-
前提条件: プロジェクト、必要な設定、環境を準備します。
-
構成: MCP と必要な API を有効にします。
-
サンプル データセットを読み込みます。
-
OAuth クライアントを作成します。
-
Gemini API キーを作成します。
-
エージェントを作成してテストします。
重要: 本番環境へのデプロイを計画する場合や、実際のデータで AI エージェントを使用する場合は、AI のセキュリティと安全性、安定性に関するガイドラインを遵守してください。
手順 1: 前提条件 > 構成と環境
1.1 Cloud プロジェクトを設定する課金が有効になっている Google Cloud プロジェクトを作成するか、既存のプロジェクトを使用します。
1.2 ユーザーロールユーザー アカウントに、プロジェクトに対する次の権限があることを確認します。
-
roles/bigquery.user(クエリの実行用)
-
roles/bigquery.dataViewer(データへのアクセス用)
-
roles/mcp.toolUser(MCP ツールへのアクセス用)
-
roles/serviceusage.serviceUsageAdmin(API の有効化用)
-
roles/iam.oauthClientViewer(OAuth)
-
roles/iam.serviceAccountViewer(OAuth)
-
roles/oauthconfig.editor(OAuth)
1.3 環境を設定するgcloud CLI がインストールされた MacOS または Linux ターミナルを使用します。
シェルで、Cloud の PROJECT_ID を指定して次のコマンドを実行し、Google Cloud アカウントを認証します。これは、ADK が BigQuery にアクセスできるようにするために必要です。
指示に沿って認証プロセスを完了します。
手順 2: 構成 > ユーザーロールと API
2.1 BigQuery API と MCP API を有効にする次のコマンドを実行して、BigQuery API と MCP API を有効にします。
手順 3: サンプル データセットを読み込む > cymbal_pets データセット
3.1 cymbal_pets データセットを作成するこのデモでは、cymbal_pets データセットを使用します。次のコマンドを実行して、公開ストレージ バケットから cymbal_pets データベースを読み込みます。
手順 4: OAuth クライアント ID を作成する
4.1 OAuth クライアント ID を作成するGoogle OAuth を使用して BigQuery MCP サーバーに接続します。
7. Google Cloud コンソールで、[Google Auth Platform] > [クライアント] > [クライアントの作成] に移動します。
-
* [アプリケーションの種類] の値には [デスクトップ アプリ] を選択します。
-
クライアントを作成したら、クライアント ID とシークレットをコピーして安全に保管してください。
省略可: OAuth クライアントに別のプロジェクトを使用した場合は、CLIENT_ID_PROJECT を指定して以下を実行します。
注 [Cloud Shell ユーザーのみ]: Google Cloud Shell または localhost 以外のホスティング環境を使用している場合は、「ウェブ アプリケーション」の OAuth クライアント ID を作成する必要があります。
Cloud Shell 環境の場合:
-
[承認済みの JavaScript 生成元] の値には、次のコマンドの出力を指定します。
echo "https://8000-$WEB_HOST" -
[承認済みのリダイレクト URI] の値には、次のコマンドの出力を使用します。
echo "https://8000-$WEB_HOST/dev-ui/"(Cloud Shell の URI は一時的なもので、現在のセッションの終了後に期限切れになります)
注: ウェブサーバーを使用する場合は、「ウェブ アプリケーション」タイプの OAuth クライアントを使用し、適切なドメインとリダイレクト URI を入力する必要があります。
手順 5: Gemini の API キー
5.1 Gemini の API キーを作成するAPI キーのページで Gemini API キーを作成します。ADK を使用して Gemini モデルにアクセスするには、生成されたキーが必要です。
手順 6: ADK ウェブ アプリケーションを作成する
6.1 ADK をインストールするADK をインストールしてエージェント プロジェクトを開始するには、ADK の Python クイックスタートに記載されている手順に沿って進めます。
6.2 新しい ADK エージェントを作成する次に、BigQuery リモート MCP サーバー統合用の新しいエージェントを作成します。
6.3 env ファイルを構成する次のコマンドを実行して、cymbal_pets_analyst/.env ファイルを以下の変数とその実際の値で更新します。
6.4 エージェント コードを更新するcymbal_pets_analyst/agent.py ファイルを編集し、ファイルの内容を次のコードに置き換えます。
6.5 ADK アプリケーションを実行するcymbal_pets_analyst フォルダを含む親ディレクトリから次のコマンドを実行します。
ブラウザを起動し、http://127.0.0.1:8000/ または ADK を実行するホストを指定して、プルダウンからエージェント名を選択します。これで、Cymbal のペットのデータに関する質問に答えるパーソナル エージェントができました。エージェントが MCP サーバーに接続すると、OAuth フローが開始され、アクセス権を付与できるようになります。
2 つ目のプロンプトでは、プロジェクト ID を指定する必要がなくなっています。エージェントは会話からこの情報を推測できるためです。
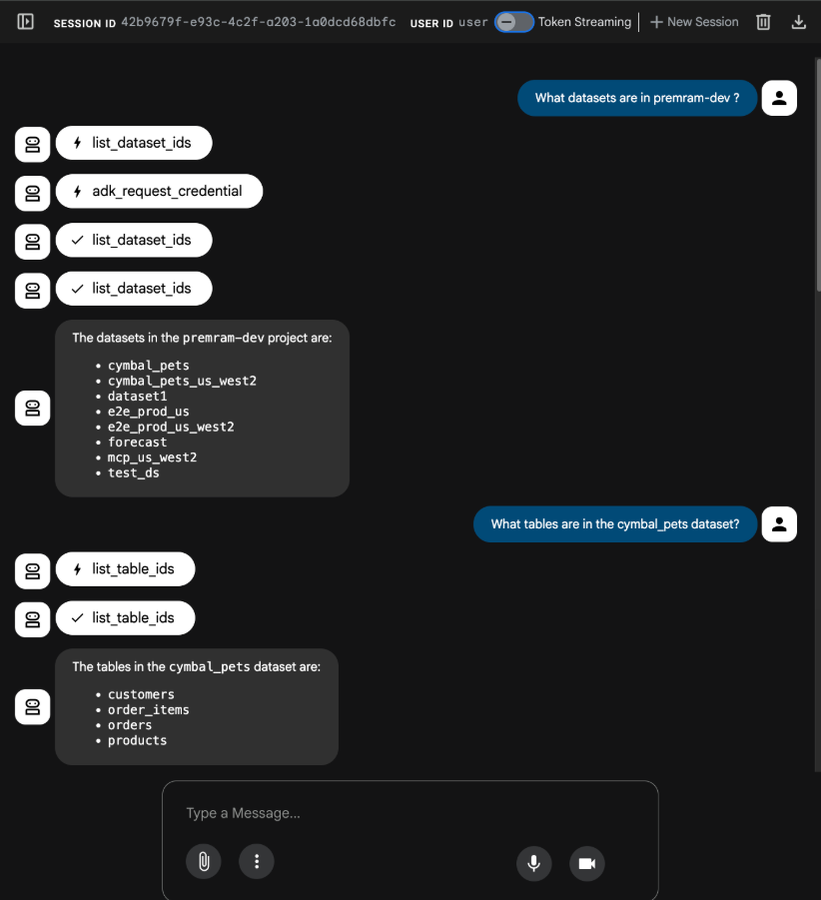
質問の例は次のとおりです。
-
my_project にはどのようなデータセットがある?
-
cymbal_pets データセットにはどのようなテーブルがある?
-
cymbal_pets データセットのテーブル customers のスキーマを取得して
-
米国西部地域の Cymbal のペットショップで、過去 3 か月間の注文数上位 3 件を特定して。注文したお客様とそのメール ID も特定して。
-
上位 1 件ではなく、上位 10 件の注文を取得できる?
-
過去 6 か月間で最も売れた商品は?
Gemini CLI で BigQuery MCP サーバーを使用する
Gemini CLI を使用するには、~/.gemini/settings.json ファイルで次の構成を使用します。既存の構成がある場合は、この構成を mcpServers フィールドの下にマージする必要があります。
次に、gcloud で認証を実行します。
Gemini CLI を実行します。
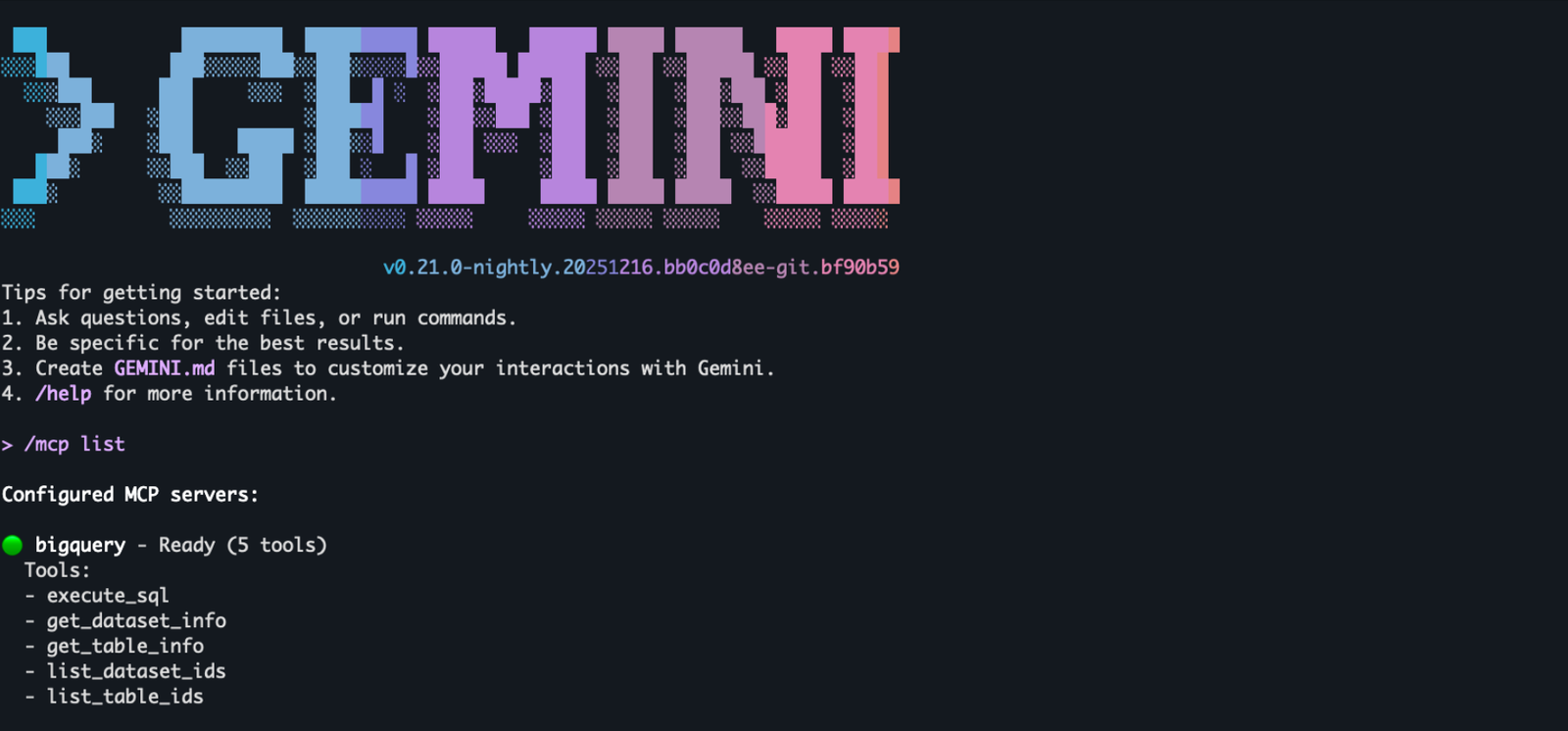
エージェント用の BigQuery MCP サーバー
BigQuery ツールを開発ワークフローに統合し、LLM と BigQuery MCP サーバーを使用してインテリジェントなデータ エージェントを作成できます。統合は、すべての主要なエージェント開発 IDE およびフレームワークと互換性のある単一の標準プロトコルに基づいています。もちろん、本番環境向けにエージェントを構築したり、実際のデータで使用したりする前に、AI のセキュリティと安全性に関するガイドラインを遵守してください。
皆様も BigQuery MCP サーバーを活用して、データ分析生成 AI アプリケーションをぜひ開発してみてください。
- テクニカル プログラム マネージャー、Vikram Manghnani- ソフトウェア エンジニア、Prem Ramanathan
