Dataflow の ML インフラストラクチャに関する最新情報
Efesa Origbo
Product Manager, Google
Danny McCormick
Software Engineer, Google Cloud
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try now※この投稿は米国時間 2026 年 1 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
AI の世界は電光石火のスピードで変化しています。Google Cloud は、AI ワークロードと ML ワークロードを強化する最高水準のインフラストラクチャを提供することに尽力しています。Dataflow は、Google Cloud の AI スタックの重要なコンポーネントであり、さまざまな分析や AI のユースケースを支援するバッチ パイプラインとストリーミング パイプラインを作成できます。今回は、バッチ ML ワークロードとストリーミング ML ワークロードの実行において、より多くの選択肢の提供、取得可能性の増加、効率性の向上を実現する最新機能をご紹介します。
より多くの選択肢: パフォーマンスが最適化されたハードウェア
Google は、すべての ML ワークロードが同じように作成されているわけではないことを理解しています。そのため、提供するハードウェアを拡大し、お客様が固有のニーズに最適なアクセラレータを柔軟に選択できるようにしています。
-
新しい GPU: Google は常に最新かつ最高の GPU をラインナップに追加しています。最近では、H100 および H100 Mega GPU のサポートを発表しました。これにより、最先端のハードウェアを活用して AI 推論ワークロードを高速化できます。大手企業は、Dataflow で GPU を活用して、革新的なカスタマー エクスペリエンスを実現しています。たとえば、脅威インテリジェンス プラットフォーム プロバイダの Flashpoint はドキュメントの翻訳を強化し、メディア プロバイダの Spotify は大規模なポッドキャスト プレビューを可能にしています。
-
TPU: 大規模な ML タスクには、Tensor Processing Unit(TPU)が強力かつ費用対効果の高いソリューションとなります。Google は最近、TPU V5E、V5P、V6E のサポートを発表しました。これにより、最先端の ML ビルダーは、Dataflow ジョブ内で直接、大容量低レイテンシの ML 推論ワークロードを大規模かつ効率的に実行できます。
アクセラレータの取得可能性の向上
必要なときに必要なハードウェアにアクセスできることは、ML プロジェクトを順調に進めるために不可欠です。Google は、必要なリソースをこれまで以上に簡単に取得できる、アクセラレータの新たな使い方を導入いたしました。
-
GPU / TPU の予約: このたび Dataflow ジョブの GPU と TPU を予約できるようになりました。これにより、必要なときに必要なリソースを確保できます。これは、リソースが利用可能になるまで待機できない重要なワークロードにとってきわめて重要です。
-
Flex Start GPU プロビジョニング: 開始時間が柔軟なバッチジョブの場合、GPU は業界全体で需要が高いため、その確保は手動による不確実なプロセスになる可能性があります。Dynamic Workload Scheduler(DWS)によって実現した新しいFlex Start プロビジョニング モデルは、この問題を効果的に解決します。アクセラレータ リソースを利用できない場合、Dataflow はジョブをエラーにするのではなくキューに入れ、必要な GPU が利用可能になり次第、自動的にジョブを開始します。これにより、手動で繰り返し再送信する必要がなくなり、リソース不足のリスクが軽減し、デベロッパーの生産性が向上します。
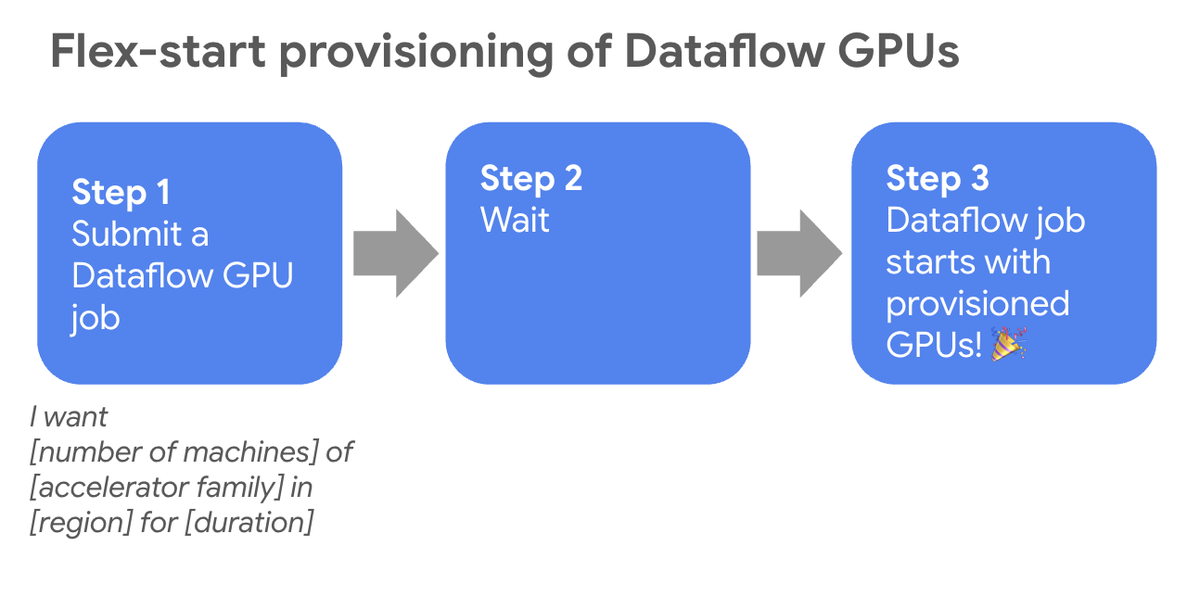
AI ワークロードの効率性が向上
Google は、お客様が AI ワークロードをより効率的に実行できるようにする方法を常に模索しています。最近発表した Right Fitting や ML 対応ストリーミングなどの機能は、AI への投資を最大限に活かせるように設計されています。
-
ML 対応のストリーミング: ストリーミング エンジンが ML 対応になったため、ストリーミング ML パイプラインの実行方法についてよりスマートな意思決定ができるようになりました。たとえば、Dataflow の水平自動スケーリングは通常、バックログのサイズや CPU の使用率といったさまざまな入力シグナルを利用しています。アクセラレータが ML ワークロード処理用コンピューティング インフラストラクチャの重要な部分になるにつれ、自動スケーリングの判断にアクセラレータを考慮することが必要となってきています。Google は最近、GPU ベースの自動スケーリングをリリースしました。これにより、Dataflow サービスで並列処理度などの GPU 関連シグナルを水平自動スケーリング アルゴリズムの重要な入力として使用し、ストリーミング ML ジョブの効率性を高めることが可能になります。
-
Right Fitting: Dataflow パイプラインでは、ステージごとに必要なリソースが異なることがよくあります。以前は、最も要求の厳しいステージに対応できる性能を備えた単一のマシンタイプを選択する必要があったため、ジョブのリソース使用量が少ないステージでは非効率的で、費用が無駄になっていました。Right Fitting は、異種混合のリソースプールを使用できるようにすることで、この「ワンサイズですべてに対応」しなければならないという問題を解決します。つまり、ジョブのコンピューティング負荷の高いステージは大容量メモリや GPU を備えた専用のハードウェアで実行し、その他のステージは汎用的な費用対効果の高いワーカーで実行できるということです。これにより、効率性が大幅に向上し、費用が最適化されます。
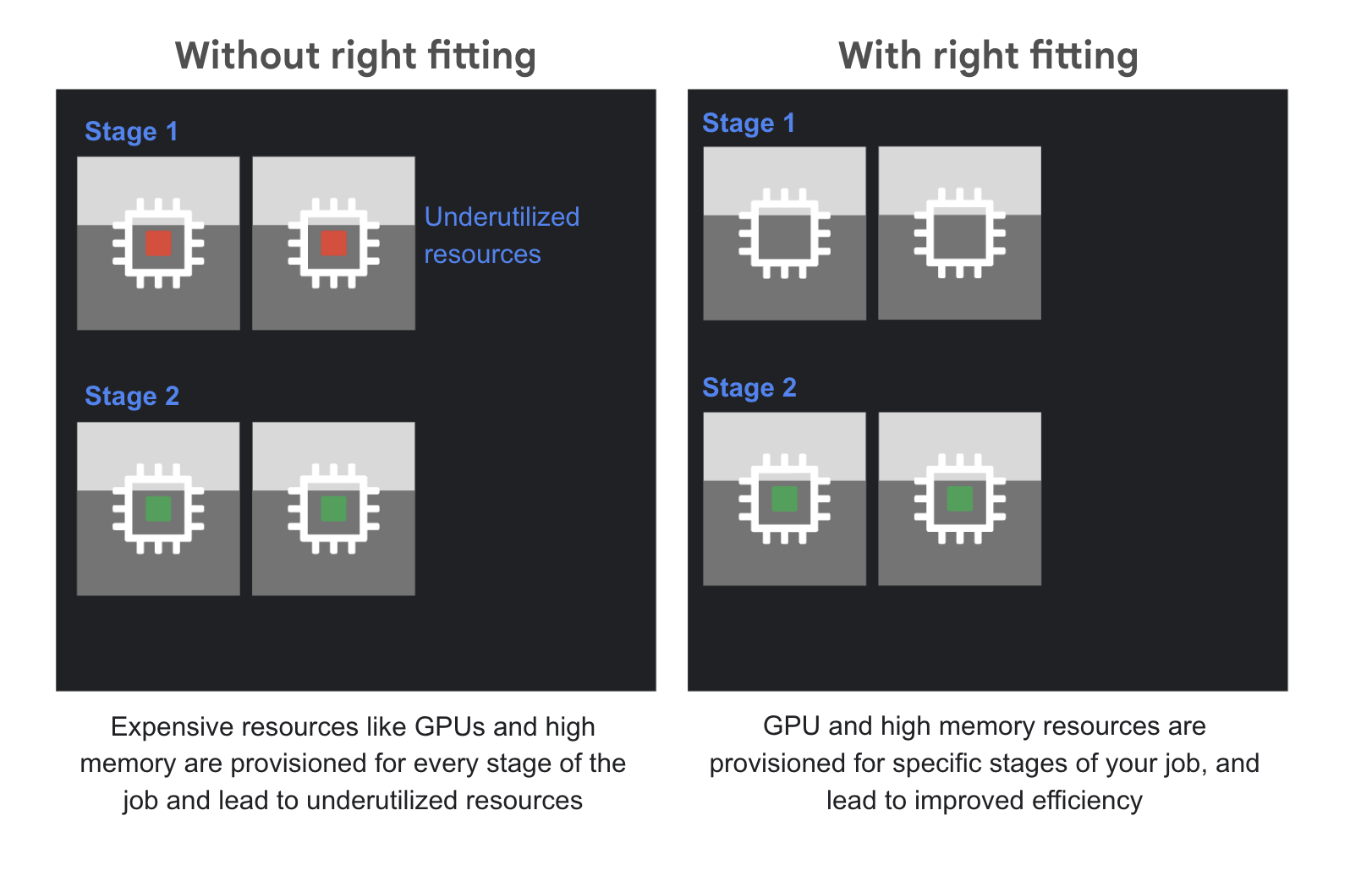
Google は、Dataflow の ML 機能とお客様にもたらされる可能性に大きな期待を寄せています。今すぐ Dataflow の使用を開始し、これらの機能を活用して、ML の最も困難な課題を解決しましょう。
- Google、プロダクト マネージャー、Efesa Origbo
- Google Cloud、ソフトウェア エンジニア、Danny McCormick

