BigQuery AI: Gemini 3.0 対応、エンベディング生成の簡素化、新しい類似度関数
Tianxiang Gao
Software Engineer
Derrick Li
Software Engineer
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try now※この投稿は米国時間 2026 年 1 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
デジタル環境には、画像、動画、音声、ドキュメントなどの非構造化データが溢れており、多くの場合、これらは活用されていません。このデータの可能性を最小限の摩擦で活用できるよう、Google は Gemini やその他の Vertex AI モデルを BigQuery に直接統合しました。これにより、BigQuery SQL を使用して生成 AI やエンベディング モデルを簡単に操作できます。この分野での新たなリリースにより、設定がさらに簡素化され、AI 関数でできることが広がります。
-
エンドユーザー認証情報(EUC)を使用した権限設定の簡素化
-
テキストと構造化データの両方を生成する AI.generate() 関数
-
エンベディング生成用の AI.embed() 関数
-
テキストと画像のセマンティック類似度スコアを計算する AI.similarity()
-
Gemini 3.0 Pro / Flash のサポート
EUC による合理化された設定
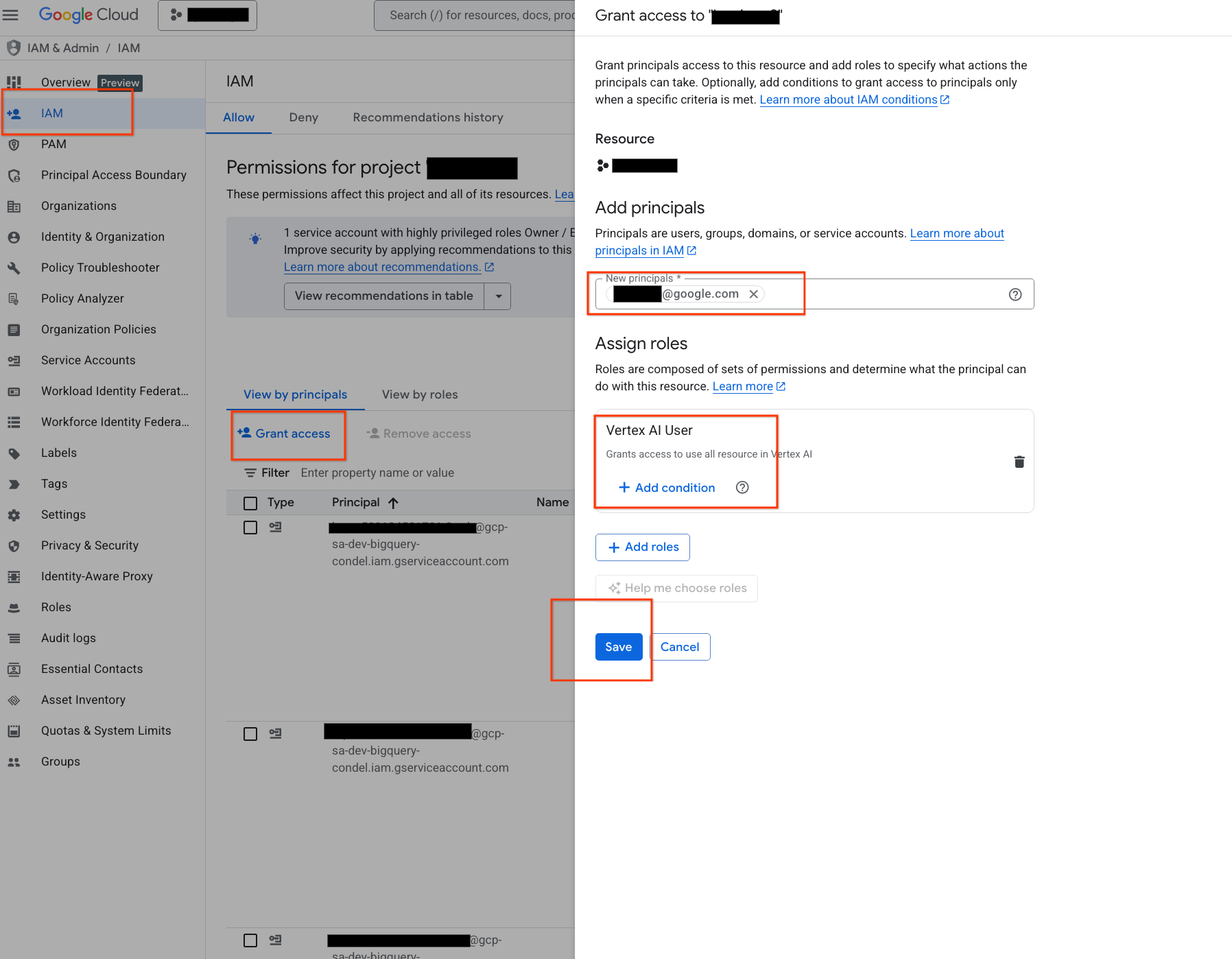
以前は、Vertex AI モデルを BigQuery と統合する際に、個別の接続を構成し、サービス アカウントの権限を管理する必要がありました。EUC を有効にすることで、個人の IAM ID を使用して Vertex AI リクエストを認証できるようになりました。これにより、標準的なインタラクティブ クエリの中間接続が不要になり、connection_id パラメータがオプションになります。EUC を利用するには、アカウントに IAM で Vertex AI ユーザーロールが付与されていることを確認するだけです。手順を示した以下のスクリーンショット、または詳しく説明した一般公開ドキュメントをご覧ください。プロジェクト オーナーの場合は、必要な権限がすでに付与されているため、この設定を行う必要はありません。
一般提供版の次世代テキストと構造化生成関数
次世代の BigQuery 生成 AI 関数である AI.GENERATE と AI.GENERATE_TABLE が、プレビュー版から一般提供版になりました。これらの新しい関数により、BigQuery の生成 AI 推論機能で次のことが可能になります。
-
あらゆる種類のデータを分析: 新しい関数は、テキスト、画像、動画、音声、ドキュメントなど、あらゆる種類の入力を受け付けます。
-
主要な AI / ML タスクのほとんどを実行: LLM に実行させたいことのプロンプトを入力するだけで、抽出、翻訳、要約、感情分析などのタスクを簡単に実行できます。
-
SQL のどこでも AI を使用: これらの関数は完全にコンポーズ可能で、標準 SQL 関数が使用できる場所ならどこでも使用できます(SELECT ステートメント、WHERE 句、ORDER BY 句など)。これにより、高度で柔軟なデータ処理が可能になります。
-
構造化出力を生成: 目的の output_schema を指定して、非構造化データを構造化された分析情報に変換します。
AI.GENERATE は自由形式のテキスト生成に優れており、単純なプロンプトを入力するだけで、要約、翻訳、感情分析など、LLM を利用した幅広い一般的なタスクに活用できます。
さらに、AI.GENERATE は構造化された出力も生成できます。output_schema パラメータを使用すると、出力フィールドの名前とタイプを定義できるため、結果をすぐに解析して、ダウンストリームのアプリケーションで使用できます。
さらに、「sentiment」や「summarize_in_one_sentence」などの説明的な出力フィールド名を指定することで、AI.GENERATE は 1 回の関数呼び出しで複数の AI タスクを実行できます。結果は、簡単に使用できる複数の列で返されます。
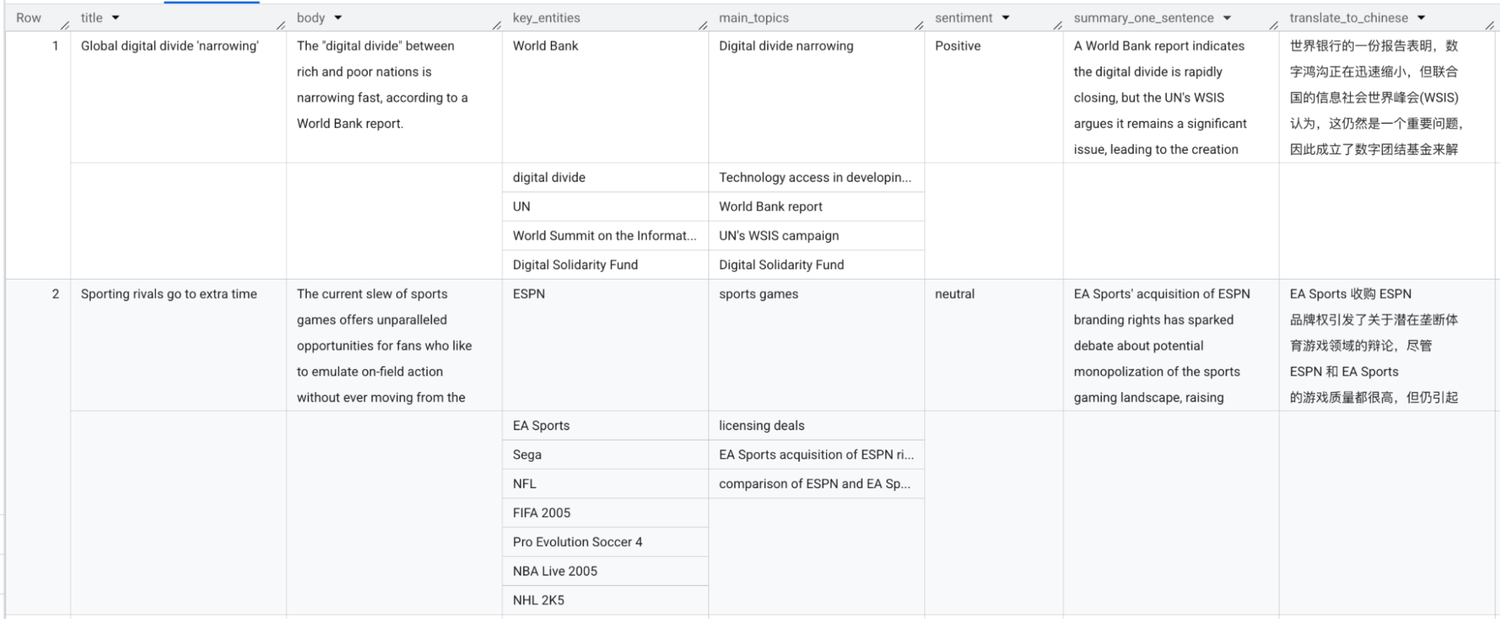
以下に 2 つの例を示します。最初の例では、bigquery-public-data.bbc_news.fulltext テーブルのテキストデータを使用します。1 回の AI.GENERATE 呼び出しで、1)主要エンティティの抽出、2)トピックのモデリング、3)感情分析、4)翻訳、5)要約の 5 つのタスクを同時に実行します。
上記のクエリを実行すると、次の出力が得られます。
2 つ目の例では、画像を分析します。まず、Cloud Storage の画像を指す BigQuery 外部テーブルを作成します。
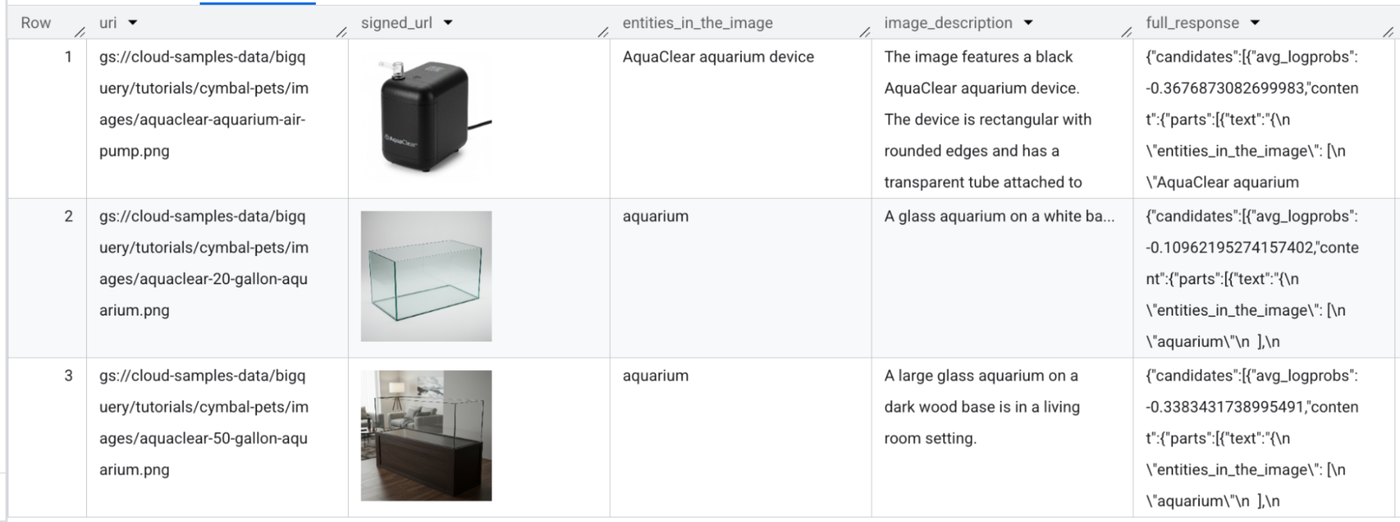
続けて、次のクエリを実行します。このクエリでは、1 つの AI.GENERATE 関数呼び出しを使用して、画像の説明を生成し、主要なエンティティを抽出します。
結果は次のようになります。BigQuery は、署名付き URL を使用して画像を自動的に可視化できます。
BigQuery には、構造化された出力の生成に関して AI.GENERATE と同様の機能を持つ AI.GENERATE_TABLE TVF も用意されています。詳しくは、公式ドキュメントと以前のブログ投稿 BigQuery で生成 AI モデルから構造化データを作成をご覧ください。
エンベディング生成と類似度計算のための新しい簡素化された関数
AI.EMBED 関数は、複雑なデータをエンベディングに変換します。エンベディングとは、意味的類似度を数学的な近さで表現した数値ベクトルです。AI.EMBED を使用してデータを変換することで、抽象的なコンセプトを測定可能な距離に変換し、アイテムを数学的に比較して最適な一致を見つけることができます。これらの機能はどちらも現在プレビュー版で利用できます。
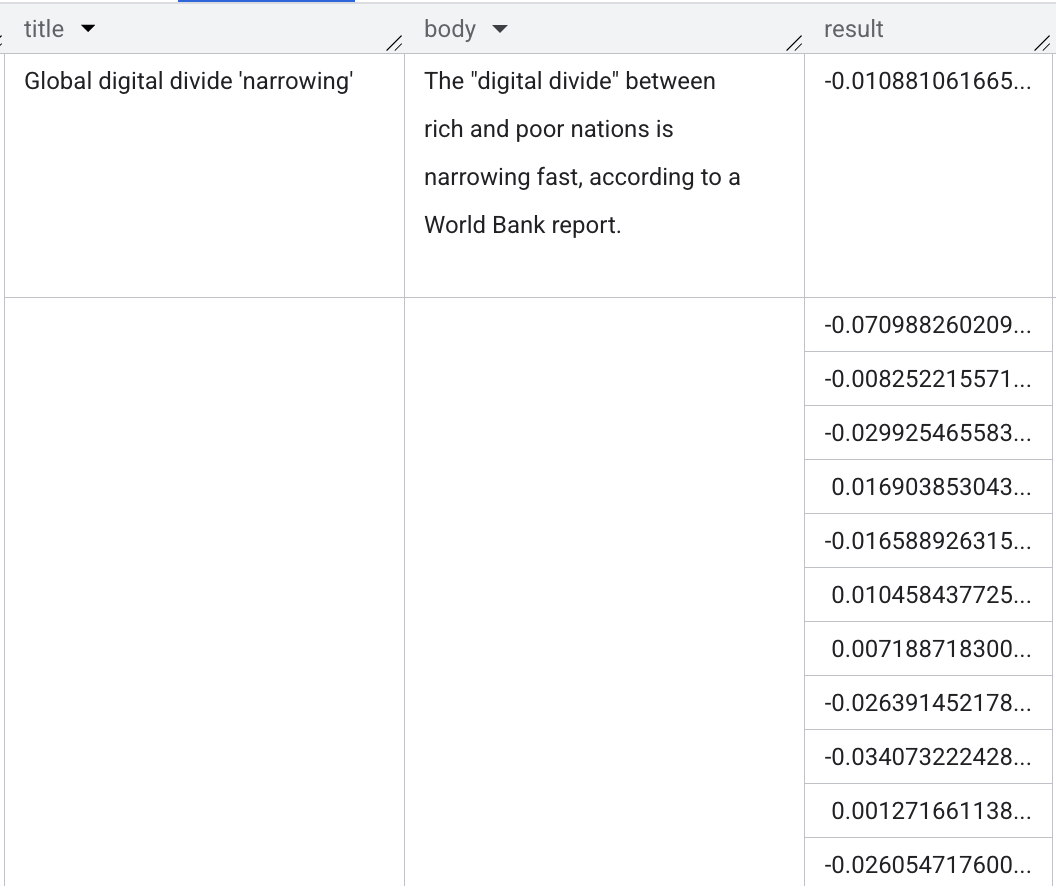
上記で使用した BBC ニュースのデータセットに戻り、次のクエリを使用してテーブル全体のエンベディングを生成できます。
次のスクリーンショットは、生成された出力を示しています。
さらに、新しい AI.SIMILARITY スカラー関数は、2 つのテキスト、2 つの画像、またはテキストと画像の間で、意味的類似度を計算します。この関数は、内部で 2 つの入力のエンベディングを計算し、それらのコサイン類似度を計算します。これを使用してみるため、住宅市場の下落傾向に関する記事を検索します。次のクエリを使用して、コンテンツが最も類似しているデータセット内の上位 5 件の記事を取得できます。
出力は以下のとおりです。
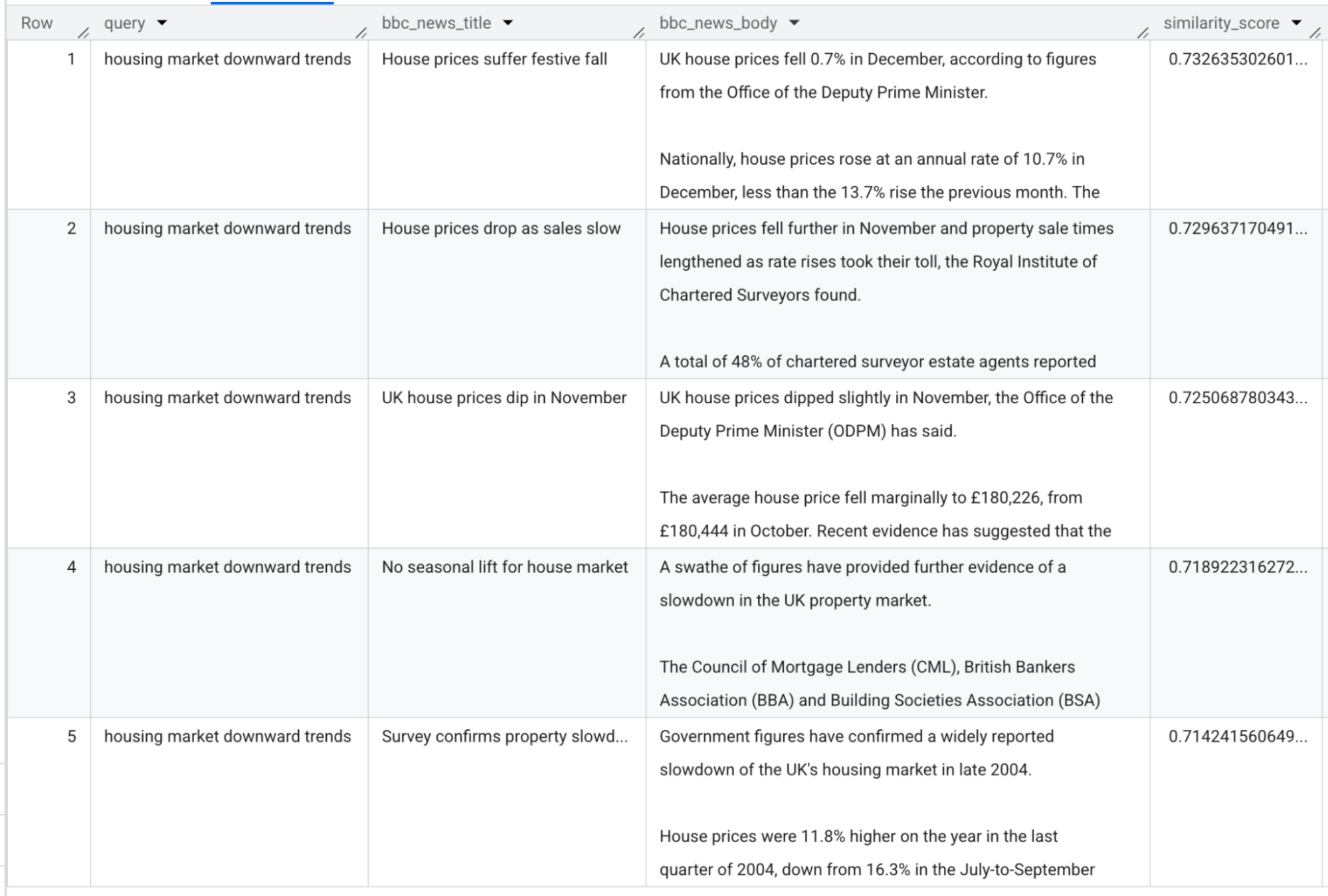
これは、AI.SIMILARITY がクエリの根底にあるコンセプトを理解することで、単純な部分文字列検索を超越していることを示しています。エンベディング生成と類似度計算の両方を 1 つの洗練されたステップで処理するため、BigQuery でセマンティック検索を実行する最も効率的な方法です。事前計算や複雑なパイプラインは必要ありません。そのため、アジリティが重要となるインタラクティブな分析、プロトタイピング、小規模から中規模のデータセットの結合に最適です。
これらのセマンティック機能を数百万行または数十億行にわたってスケールする必要があるユースケースでは、VECTOR_SEARCH 関数にシームレスに移行して、事前計算されたエンベディングとベクトル インデックスを利用できます。
Gemini 3.0 のサポート
BQML は、AI.GENERATE などの生成 AI 関数において Gemini 3.0 に対応しています。次のクエリを使用して Gemini 3.0 を呼び出すことができます。
Gemini 3.0 のプレビュー期間中は、上記の例のように、HTTP エンドポイント文字列全体を指定する必要があります。近い将来、指定するエンドポイント名は endpoint => 'gemini-3-flash' に簡略化される予定です。
使ってみる
BigQuery の AI 関数を使用してデータを探索する準備はできましたか?使用を開始するには、ドキュメントをご覧ください。これらの新機能に関するご意見や、追加機能のご要望がありましたら、bqml-feedback@google.com までお寄せください。
- ソフトウェア エンジニア、Tianxiang Gao
- ソフトウェア エンジニア、Derrick Li

