BigQuery でのテキスト分析が向上: 検索機能の一般提供開始
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
Google の Data Cloud の目的は、お客様のデータと価値のギャップを埋めることです。Google Cloud フルマネージド サーバーレス データ プラットフォームである BigQuery により、お客様は構造化、半構造化、非構造化などのあらゆるデータを組み合わせることができます。本日、Google は BigQuery の検索インデックスと検索機能の一般提供の開始を発表いたします。これらを組み合わせることで、テキスト情報のサイロ化により以前は検索が難しかったデータのリッチテキスト分析を効率的に行うことが可能になります。検索インデックスでは、スタンドアロンの検索エンジンへのテキストデータのエクスポートを行う必要性を減らすことができ、その代わりに、データドリブンなアプリケーションを構築したり、BigQuery 内の他の構造化データ、半構造化データ(JSON)、非構造化データ(ドキュメント、イメージ、音声)、ストリーミング データ、地理空間データと組み合わせたテキストデータに基づく情報を引き出すことができます。
検索インデックスの公開プレビュー版を発表した以前の投稿では、検索とインデックスにより、テーブルスキーマを事前に知らなくても、標準的な BigQuery SQL を使用して、非構造化テキストと半構造化 JSON に埋もれた一意のデータ要素を簡単に見つけることができるとご説明しました。
Google エンジニアリング チームは、Google 社内のテストプロジェクトの Google Cloud Logging データ(10 TB、100 TB、1 PB スケール)に SEARCH 関数と検索インデックスを使用してクエリを実行しました。それから、RXEGEP_CONTAINS 関数(検索インデックスなし)を使用した同等のロジックと比較した結果、評価されたユースケースについて、この新しい機能により全体的な改善が見られました(より詳細な内容を以下に示します)。
実行時間: 10 倍。平均すると、検索インデックスに支えられた BigQuery SEARCH 関数を使用したクエリは、一般的な検索ユースケースのクエリより 10 倍高速です。
処理されたバイト数: 2682 分の 1。平均すると、検索インデックスに支えられた BigQuery SEARCH 関数を使用したクエリは、一般的な検索ユースケースのクエリの 2682 分の 1 のバイト数で処理します。
スロットの使用(BigQuery コンピューティング単位数): 1271 分の 1。平均すると、検索インデックスに支えられた BigQuery SEARCH 関数を使用したクエリは、一般的な検索ユースケースのクエリの 1271 分の 1 のスロット時間で済みます。
こうした数字の大局的な理解のため、BigQuery において検索インデックスがよく使われるケースについて考えてみます。すべての改善した数値は、Google 社内テスト プロジェクトのログデータにおける一般的なユースケースとクエリを Google エンジニアリング チームが分析し、導き出したものです。この結果は、お客様のクエリに直接適応されるものではないかもしれません。ご自身のデータセットでテストすることをおすすめします。
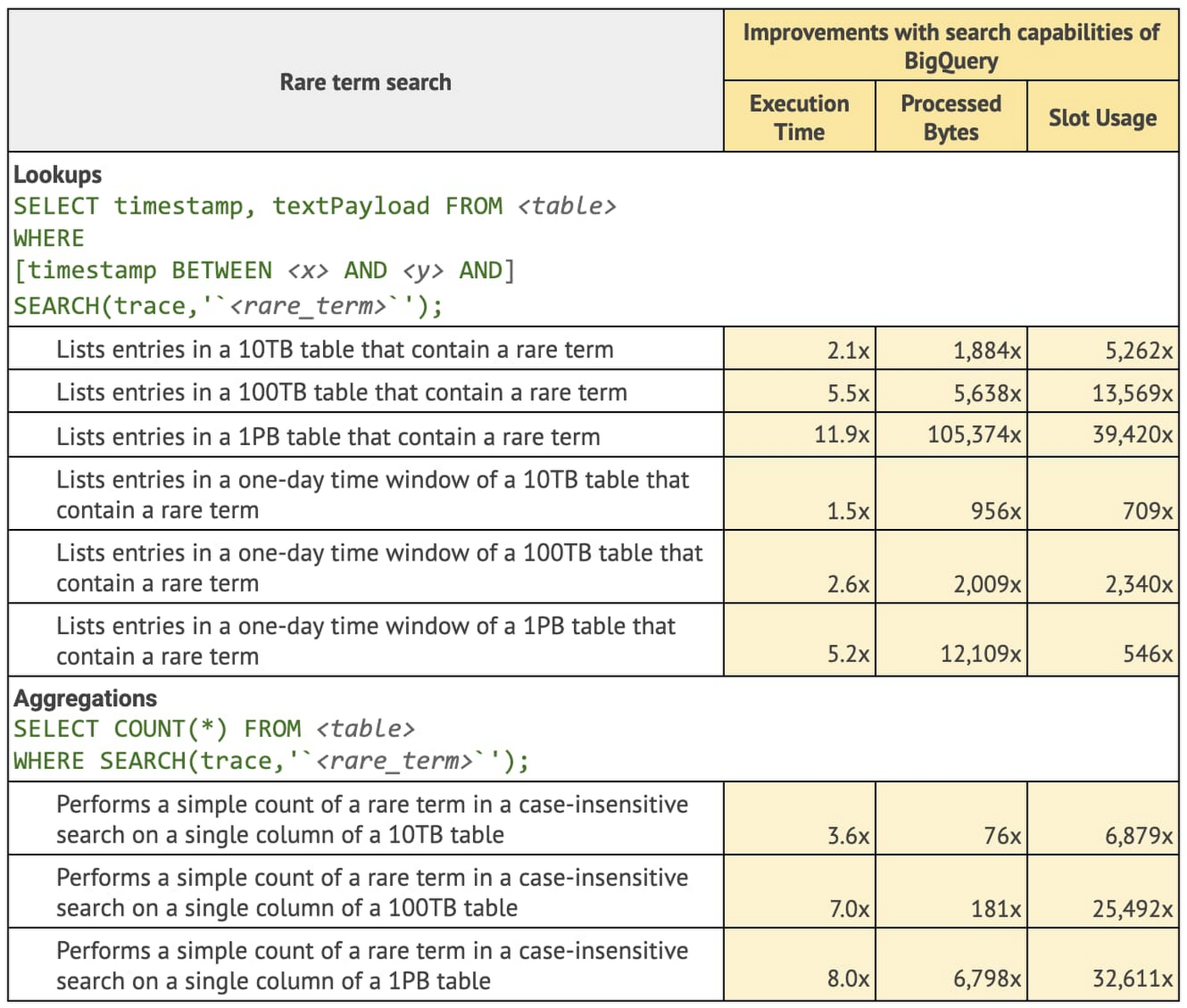
ログを分析するためのレアターム検索
ログ分析は、Google の Data Cloud によって可能になる業界の主要なユースケースです。先日の Google Cloud Next ‘22 の Operational Data Lakes に関する講演で、The Home Depot は、費用削減とログ保存の改善のために、既存の企業ログ分析ソリューションをやめ、代わりに BigQuery と Looker を 1,400 人以上のアクティブ ユーザー向けに使用した方法についてご紹介しました。Goldman Sachs は、マルチクラウドとロギングデータのスケーリングの問題を解決するために BigQuery を使用しました。Goldman Sachs は、既存のロギング ソリューションから BigQuery へ移行し、長期保存の改善、Google DLP でのログ内の個人情報(PII)の検知、新しい費用管理と配分の実施を実現させました。
ログ分析において、非常に一般的なクエリパターンはレアターム検索といい、俗に言う、「干し草の山から 1 本の針を探し出す」ようなものです。これはつまり、数百万から数十億の行を素早く検索して完全一致する特定のネットワーク ID、エラーコード、ユーザー名を見つけ出し、問題のトラブルシューティングやセキュリティ監査を実行するということです。これは、データ ウェアハウスにおける検索インデックスの典型的なユースケースでもあります。テキストデータのテーブルで検索インデックスを使用することで、BigQuery オプティマイザーが大規模なスキャン オペレーションを回避し、クエリ回答に必要な関連データを正確に特定します。
Google のエンジニアリング チームが、検索インデックスを使用する場合と使用しない場合でレアタームを検索するクエリをレビューした結果についてご覧ください。
Cloud Logging での IP アドレス検索
Home Depot と Goldman Sachs は、独自のカスタマイズされたログ分析アプリケーションを開発するために BigQuery の基本的な構成要素を活用しました。しかし、その他のお客様は、Cloud Logging 内に事前構築済みの統合として、Google の Data Cloud 上でログ分析を使用することを選ぶかもしれません。
BigQuery を活用した Log Analytics(プレビュー版)は、ログ分析に特化したインターフェースをもつサービスとしてのマネージド Log Analytics ソリューションをお客様に提供します。BigQuery の検索機能を活用し、IP アドレス、URL、メールなどの一般的なロギングデータ要素を検索するための特別な方法を提供します。Google エンジニアリング チームが検索機能を使用して IP アドレスを調べた結果わかったことをご覧ください。
セキュリティ運用のための最新データでの共通用語検索
セキュリティ分析と SIEM MQ の業界をリードする Exabeam は、Google の Data Cloud 上に構築した最新の Security Operation Platform において、数年分のデータを数秒で検索するため、BigQuery の検索機能と検索インデックスを活用しています。(詳しくは、データ ジャーニー インタビューをご覧ください。)
多くのセキュリティ ユースケースは、最近のデータのクエリに対して、ORDER BY 句と LIMIT 句を使用した共通の用語でデータを検索できる、検索最適化を活用できます。ORDER BY 句と LIMIT 句を使用した最近のデータのクエリについて Google エンジニアが発見したことをご覧ください。

Elasticsearch 互換のための JSON オブジェクトでの検索
Google テクニカル パートナーである Mach5 Software は、自社の顧客に、BigQuery の検索最適化と JSON 関数によりサポートされる Elasticsearch と OpenSearch 対応のプラットフォームを提供しています。Mach5 を利用することで、お客様は Kibana、OpenSearch Dashboards、構築済みのアプリケーションなどの慣れ親しんだツールを BigQuery へシームレスに移行でき、費用と管理のオーバーヘッドの大幅な削減が可能です。Mach5 は、BigQuery のネイティブ JSON データタイプに保存している、深くネストされたデータを細部まで検索するため、BigQuery の検索インデックス機能を活用しています。Mach5 Community Edition は、Google Cloud Platform 環境内で自由にデプロイ、利用可能です。
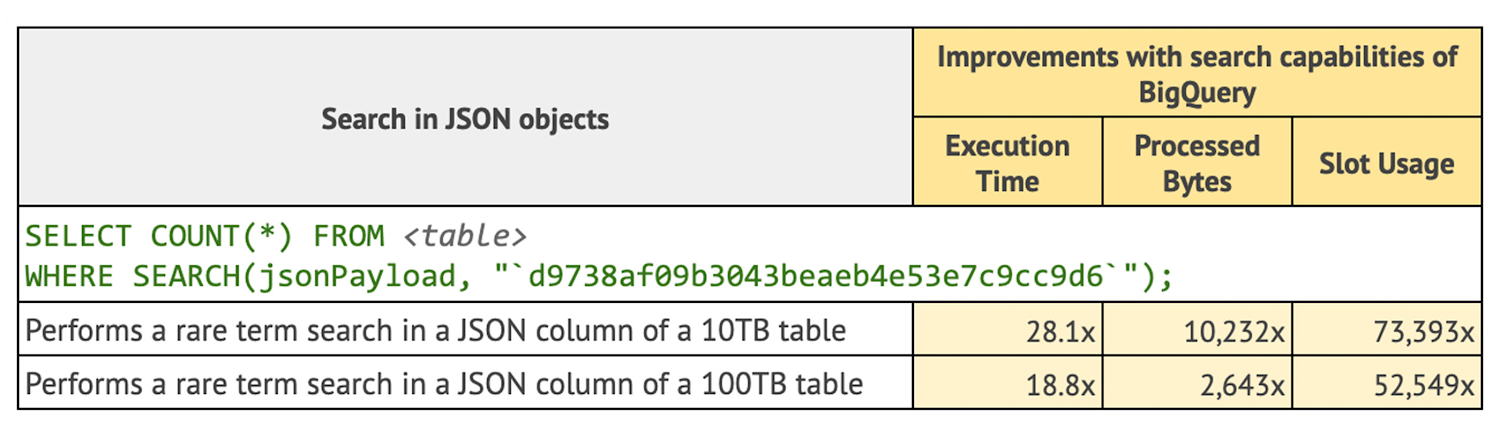
BigQuery の SEARCH 関数は BigQuery の JSON タイプで直接動作します。Google エンジニアリング チームが JSON データでインデックス付き検索を使用した際に発見した改善についてご覧ください。
詳細情報
ご覧のとおり、BigQuery の検索機能やインデックスを使用することで、ペタバイト レベルでもコストパフォーマンスが大幅に改善されています。一般的に、データセットが大きいほど、BigQuery はより最適化することができます。つまり、ペタバイトのデータを BigQuery に持ち込んでも効果的な運用が可能だということです。また、多くのお客様が BigQuery 検索機能と BigQuery の Storage Write API で構築された大規模なストリーミング パイプラインを組み合わせて利用しています。この Write API は、デフォルトの取り込み速度が毎秒 3GB で、リクエストに応じて追加の割り当てが利用可能です。また、BigQuery が提供する従来のストリーミング API と比較して、1 GB あたり 50% の費用を削減しました。これらのストリーミング パイプラインは BigQuery によるフルマネージドで、ストリーミングからインデックスまですべてのオペレーションを引き受けます。ストリーム上でデータが利用可能になると、SEARCH 関数で実行されるすべてのクエリで、正確で利用可能なデータを得ることができます。
BigQuery 検索機能が運用データレイクの構築にどのように役立つかは、こちらの Modern Security Analytics platforms に関する講演をご覧ください。実際の検索を見るには、こちらのデモをご覧ください。このデモでは、ビジョンデータで機械学習を行うことで生成されるラベルやオブジェクト データの簡易検索を向上させるために検索インデックスを構築しています。
BigQuery サンドボックスを使用して、これらの検索機能を無料でお試しいただき、BigQuery がお客様のニーズに合うかどうかご確認ください。サンドボックスでは、クレジット カード情報の登録、請求先アカウントの作成、プロジェクトの課金の有効化を行うことなく、BigQuery と Google Cloud コンソールを体験できます。
- データ分析担当プロダクト マネージャー Christopher Crosbie
- Google、ソフトウェア エンジニア Huong Phan
