BigQuery のベクトル検索のご紹介
Google Cloud Japan Team
※この投稿は米国時間 2024 年 2 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
高度な AI と機械学習(ML)テクノロジーの登場は、組織のデータ活用法を一変させ、データの潜在能力を引き出す新たな機会をもたらしています。そこでこのたび、BigQuery データのベクトル類似検索が可能になる、BigQuery のベクトル検索の公開プレビュー版をリリースいたしました。この機能は一般に近似最近傍探索とも呼ばれ、セマンティック検索、類似性検出、大規模言語モデル(LLM)による検索拡張生成(RAG)など、多数の新しいデータや AI のユースケースを強化するうえで重要になります。
ベクトル検索は、高次元の数値ベクトル(エンベディング)に対して実行されることがよくあります。エンベディングはエンティティのセマンティック表現を組み込み、テキストや画像、動画などの多数のソースから生成できます。BigQuery のベクトル検索はインデックスに基づき、一致度の高いエンベディングを識別するために必要なルックアップと距離計算を最適化します。
では、BigQuery のベクトル検索の概要をご紹介します。
- BigQuery の使い慣れたテキスト検索機能に似た、シンプルで直感的な CREATE VECTOR INDEX および VECTOR_SEARCH 構文が用意されています。これにより、ベクトル検索操作と他の SQL プリミティブの組み合わせが簡素化され、あらゆるデータを BigQuery スケールで処理できるようになります。
- 特に LLM ベースモデルや事前トレーニング済みモデルを通じて、BigQuery のエンベディング生成機能と連携します。さらに、汎用インターフェースを使用すると、他の手段で生成されたエンベディングも使用できます。
- BigQuery ベクトル インデックスは、基盤になるテーブルデータが変化すると自動的に更新され、インデックス作成の進捗を簡単にモニタリングできます。この拡張可能なフレームワークは複数のベクトル インデックス タイプをサポートできます。最初に実装されたタイプ(IVF)は、最適化されたクラスタリング モデルとツーピース インデックスの転置行ロケーターを組み合わせています。
- LangChain の実装により、他のオープンソースやサードパーティのフレームワークとの Python ベースのインテグレーションが簡素化されます。
- VECTOR_SEARCH 関数は分析ユースケース向けに最適化されており、大量のクエリ(行)のバッチを効率的に処理できます。また、処理する入力データが少量の場合も、低レイテンシの推論結果が得られます。Vertex AI とのインテグレーションを通じて、同じデータに対してより高速かつ超低レイテンシのオンライン予測を実行できます。
- BigQuery の組み込みガバナンス機能、特に行レベル、データ マスキング、列レベルのセキュリティ ポリシーと統合されています。
ユースケース
エンベディング生成とベクトル検索を組み合わせると、典型的な例である RAG をはじめ、多くの興味深いユースケースが可能になります。以下の例では、ベクトル検索を使用してデータ アプリケーションやクエリでエンコードできるものについて、高度なアルゴリズムを説明します。
- 新しい一連のサポートケースの場合、密接に関連する既存のケースを 10 件見つけ、コンテキストとして LLM に渡し、解決策の候補を要約して提案します。
- 監査ログエントリの場合、過去 30 日間で一致度が最も高いエントリを見つけます。
- プロファイルの似た患者の類似性マッチングを行い、その患者コホートに処方され成功した治療計画を調べる場合、患者のプロファイル データ(診断、病歴と薬歴、現在の処方、その他の EMR データ)からエンベディングを生成します。
- 保有しているスクールバス内に設置されているすべてのセンサーとカメラから取得した事故直前の記録を表すエンベディングの場合、保有している他の全車両から類似する瞬間の記録を見つけ、安全機能の作動を管理するモデルをさらに分析、調整、再トレーニングします。
- 画像の場合、そのユーザーの BigQuery オブジェクト テーブル内で最も関連性の高い画像を見つけてモデルに渡し、キャプションを生成します。
BigQuery ベースの RAG の詳細
BigQuery を使用すると、ベクトル エンベディングを生成し、ベクトル類似検索を実行して、RAG で生成 AI デプロイの品質を向上させることができます。手順とヒントをいくつかご紹介します。
- LLM ベースのモデルなど、サポートされているさまざまなモデルを使用して、テキストデータからベクトル エンベディングを生成できます。こうしたモデルは、単語やフレーズのコンテキストとセマンティクスを効果的に理解し、高次元空間でその意味を表すベクトルにテキストをエンコードできるようにします。
- BigQuery のスケーリングと使いやすさにより、ベクトル エンベディングを生成元のデータの横にある新しい列に保存できます。その後、ベクトル エンベディングに対してクエリを実行したり、インデックスを作成して取得パフォーマンスを向上させたりできます。
- 効率的でスケーラブルな類似検索は、システムがクエリのセマンティックな意味に基づいて最も関連性の高い情報を迅速に見つけることができるため、RAG にとって非常に重要です。ベクトル類似検索では、ベクトル データストアの数百万から数十億ものベクトルに対して効率的に検索を行い、最も類似するベクトルを見つけます。BigQuery ベクトル検索はインデックスを使用して、コサインやユークリッドなどの距離測定手法に従って最も近いベクトルを効率的に見つけます。
- RAG を使用してプロンプト エンジニアリングを行う場合、まずナレッジベースのエンコードに使用したものと同一または同様のモデルを使用して、入力をベクトルに変換します。これにより、保存した情報とクエリとが同じベクトル空間に存在するようになり、類似性を測定できます。
- クエリに最も類似していると識別されたベクトルは、対応するテキストデータにマッピングされます。このテキストデータはクエリとの関連性が最も高いナレッジベースの情報を表します。
- 取得したテキストデータは生成モデルにフィードされます。このモデルは、取得した情報によって提供される追加のコンテキストを使用して回答を生成します。この回答は事前トレーニング済みの知識に基づくだけでなく、クエリに対して取得した特定の情報によって強化されます。このため、最新の情報や特定トピックに関する詳細な知識が必要な質問に特に有用です。
以下の図は、BigQuery の RAG ワークフローを簡略化したものを表しています。
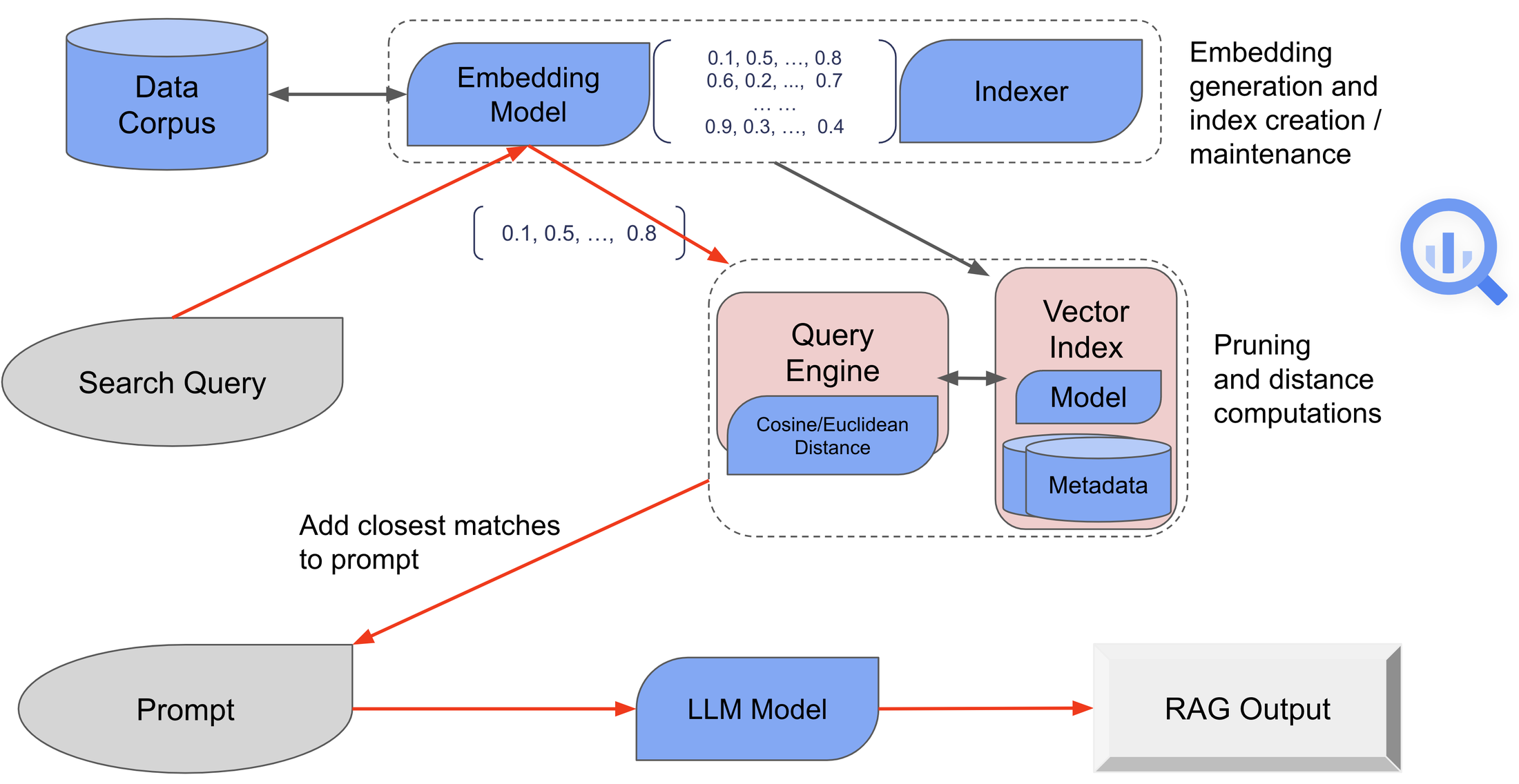
公開データの検索と RAG の例
次の 3 つのセクションでは、Google 特許検索の公開データセット テーブルにある「patents-public-data.google_patents_research.publications」テーブルを運用例として使用し、BigQuery ベクトル検索で可能になる多数のユースケースの中から 3 つの例をご紹介します。
ケース 1: 事前生成済みエンベディングを使用した特許検索
BigQuery ベクトル検索で最も基本的なユースケースの一つは、事前に生成されたエンベディングを含むデータを使用して類似検索を実行することです。これは、独自モデルや事前トレーニング済みモデルからあらかじめ生成されたエンベディングを使用する場合に一般的なユースケースです。たとえば、データとクエリをそれぞれ <my_patents_table> と <query_table> に保存した場合、検索の手順としてはインデックス作成の後にベクトル検索を行うことになります。
ただし、インデックス作成は主に近似最近傍探索のパフォーマンス最適化メカニズムであり、ベクトル検索クエリはインデックスなしでも成功し、正しい結果を返すことがあります。再現率計算などの詳細については、こちらのチュートリアルをご覧ください。
ケース 2: BigQuery のエンベディング生成を使用した特許検索
BigQuery の機能を使用してエンベディングを生成すると、より完全なエンドツーエンドのセマンティック検索を実現できます。具体的には、LLM ベースの基盤モデルまたは事前トレーニング済みモデルを使用して BigQuery でエンベディングを生成できます。以下の SQL スニペットは、BigQuery 経由で Vertex AI テキスト エンベディング基盤モデルを参照する BigQuery <LLM_embedding_model> がすでに作成されていることを前提としています(詳細については、こちらのチュートリアルをご覧ください)。
インデックス作成手順の説明は上記の「ケース 1」と似ているため省略します。インデックスが作成されたら、VECTOR_SEARCH と ML.GENERATE_TEXT_EMBEDDING を組み合わせて使用し、関連する特許を検索できます。以下は、「improving password security(パスワードのセキュリティ向上)」に関連する特許を検索するクエリの例です。
ケース 3: 生成モデルとのインテグレーションによる RAG
BigQuery の高度な機能を使用すると、上記の検索ケースを RAG の完全な手順に簡単に拡張できます。具体的には、BigQuery の ML.GENERATE_TEXT 関数で Google の自然言語基盤(LLM)モデルを呼び出すためのコンテキストとして、VECTOR_SEARCH クエリからの出力を使用できます(詳細については、こちらのチュートリアルをご覧ください)。
以下のサンプルクエリは、ユーザー パスワードのセキュリティを向上させるプロジェクトに関するアイデアを提案するよう LLM に指示する方法を示しています。セマンティック類似度ベクトル検索を通じて取得された上位 top_k 件の特許を、LLM モデルに渡されるコンテキストとして使用し、回答の根拠にします。


