In dieser Anleitung wird gezeigt, wie Sie eine BigQuery-Tabelle oder -Ansicht zum Lesen und Schreiben von Daten aus einem Databricks-Notebook verbinden. Die entsprechenden Schritte werden mit der Google Cloud -Konsole und den Databricks-Arbeitsbereichen beschrieben.
Sie können diese Schritte auch mit den Befehlszeilentools gcloud und databricks ausführen. Dies wird in dieser Anleitung jedoch nicht behandelt.
Databricks on Google Cloud ist eine in Google Cloudgehostete Databricks-Umgebung, die auf Google Kubernetes Engine (GKE) ausgeführt wird und eine integrierte Einbindung in BigQuery und andere Google Cloud -Technologien bietet. Wenn Sie noch nicht mit Databricks vertraut sind, können Sie sich das Video Introduction to Databricks Unified Data Platform ansehen, um einen Überblick über die Datahouses-Plattform von Databricks zu erhalten.
Databricks in Google Cloudbereitstellen
Führen Sie die folgenden Schritte aus, um die Bereitstellung von Databricks in Google Cloudvorzubereiten.
- Folgen Sie der Anleitung in der Dokumentation zu Databricks Databricks in Google Cloudeinrichten, um Ihr Databricks-Konto einzurichten.
- Nach der Registrierung finden Sie weitere Informationen zum Verwalten Ihres Databricks-Kontos.
Databricks-Arbeitsbereich, -Cluster und -Notebook erstellen
Die folgenden Schritte beschreiben, wie Sie einen Databricks-Arbeitsbereich, einen Cluster und ein Python-Notebook erstellen, um Code für den Zugriff auf BigQuery zu schreiben.
Bestätigen Sie die Databrick-Voraussetzungen.
Erstellen Sie Ihren ersten Arbeitsbereich. Klicken Sie in der Databricks-Kontokonsole auf Arbeitsbereich erstellen.
Geben Sie
gcp-bqals Arbeitsbereichnamen an und wählen Sie Ihre Region aus.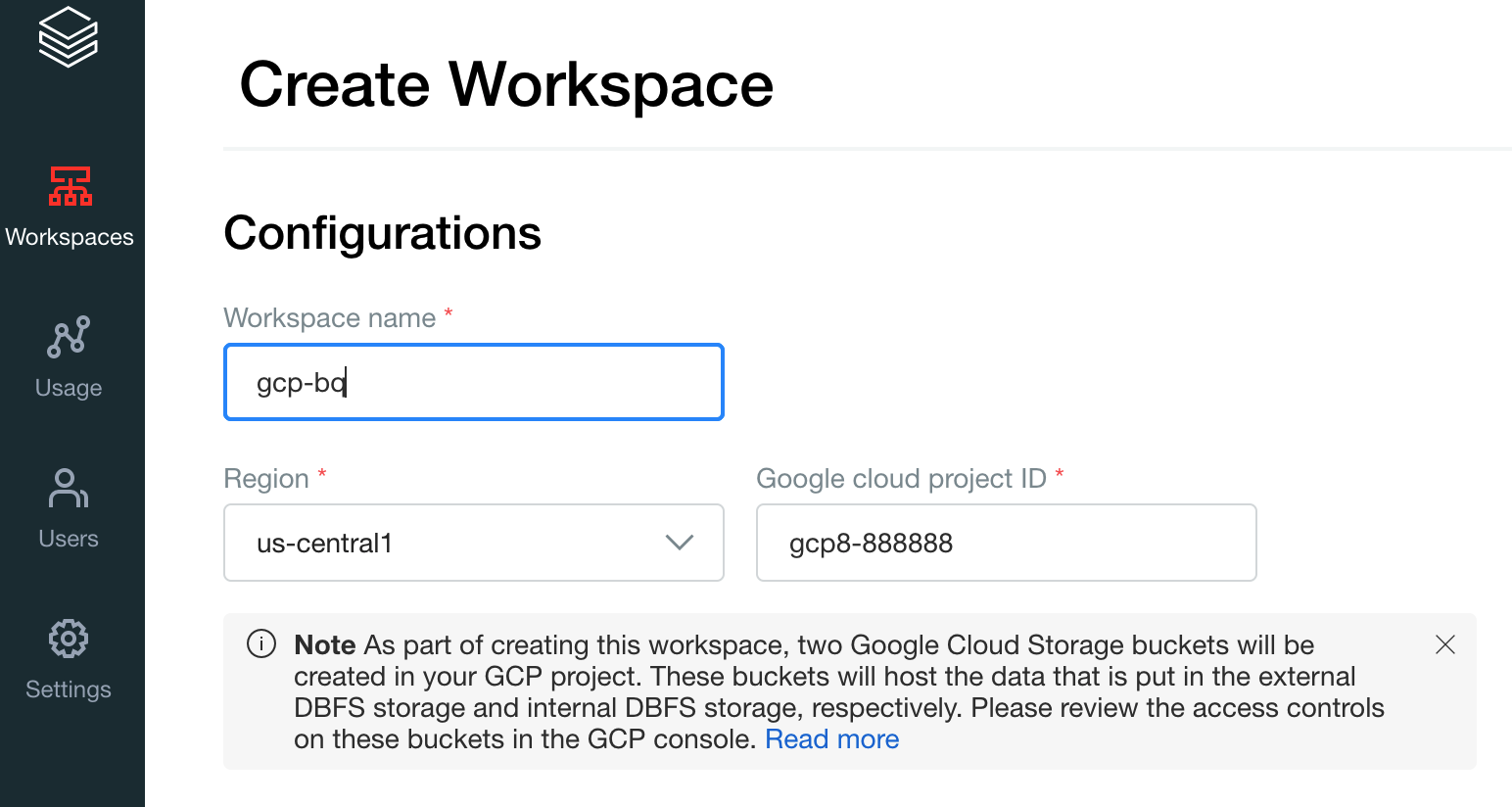
Um Ihre Google Cloud Projekt-ID zu ermitteln, rufen Sie die Google Cloud Console auf und kopieren den Wert in das Feld Google Cloud Projekt-ID.
Klicken Sie auf Speichern, um den Databricks-Arbeitsbereich zu erstellen.
Wählen Sie zum Erstellen eines Databricks-Clusters mit Databricks 7.6 oder höher in der linken Menüleiste Cluster aus und klicken Sie oben auf Cluster erstellen.
Geben Sie den Namen Ihres Clusters und seine Größe an, klicken Sie dann auf Erweiterte Optionen und geben Sie die E-Mail-Adressen Ihres Google Cloud-Dienstkontos an.
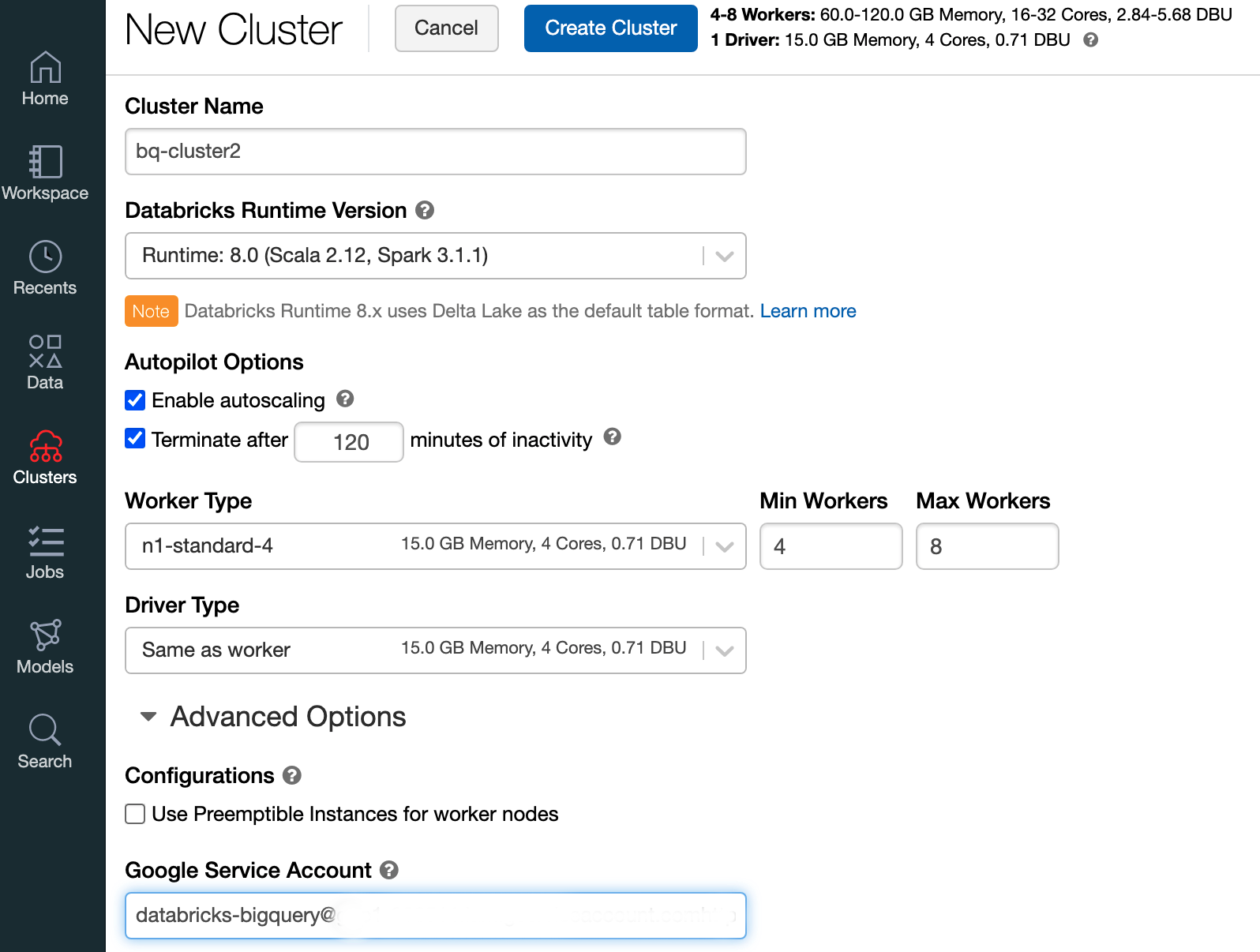
Klicken Sie auf Cluster erstellen.
Folgen Sie der Anleitung unter Notebook erstellen, um ein Python-Notebook für Databricks zu erstellen.
BigQuery über DataBricks abfragen
Mit der obigen Konfiguration können Sie Databricks sicher mit BigQuery verbinden. Databricks verwendet eine Fork des Open-Source-Adapters für Google Spark, um auf BigQuery zuzugreifen.
Databricks reduziert die Datenübertragung und beschleunigt Abfragen, indem bestimmte Abfrageprädikate automatisch übertragen werden, z. B. das Filtern von verschachtelten Spalten nach BigQuery. Darüber hinaus verringert sich die Möglichkeit, zuerst mit der API query() eine SQL-Abfrage in BigQuery auszuführen, und reduziert so die Übertragungsgröße des resultierenden Datasets.
In den folgenden Schritten wird beschrieben, wie Sie in BigQuery auf ein Dataset zugreifen und eigene Daten in BigQuery schreiben.
Auf ein öffentliches Dataset in BigQuery zugreifen
BigQuery enthält eine Liste der verfügbaren öffentlichen Datasets. So fragen Sie das BigQuery-Shakespeare-Dataset ab, das Teil der öffentlichen Datasets ist:
Verwenden Sie das folgende Code-Snippet in Ihrem Databricks-Notebook, um die BigQuery-Tabelle zu lesen.
table = "bigquery-public-data.samples.shakespeare" df = spark.read.format("bigquery").option("table",table).load() df.createOrReplaceTempView("shakespeare")Führen Sie den Code aus, indem Sie auf
Shift+Returndrücken.Sie können Ihre BigQuery-Tabelle jetzt über den Spark DataFrame (
df) abfragen. Verwenden Sie zum Beispiel Folgendes, um die ersten drei Zeilen des DataFrames anzuzeigen:df.show(3)Zum Abfragen einer anderen Tabelle aktualisieren Sie die Variable
table.Ein wichtiges Feature von Databricks-Notebooks ist, dass Sie die Zellen verschiedener Sprachen wie Scala, Python und SQL in einem einzigen Notebook kombinieren können.
Mit der folgenden SQL-Abfrage können Sie die Wortzahl in Shakespeare nach dem Ausführen der vorherigen Zelle visualisieren, die die temporäre Ansicht erstellt.
%sql SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word ORDER BY word_count DESC LIMIT 12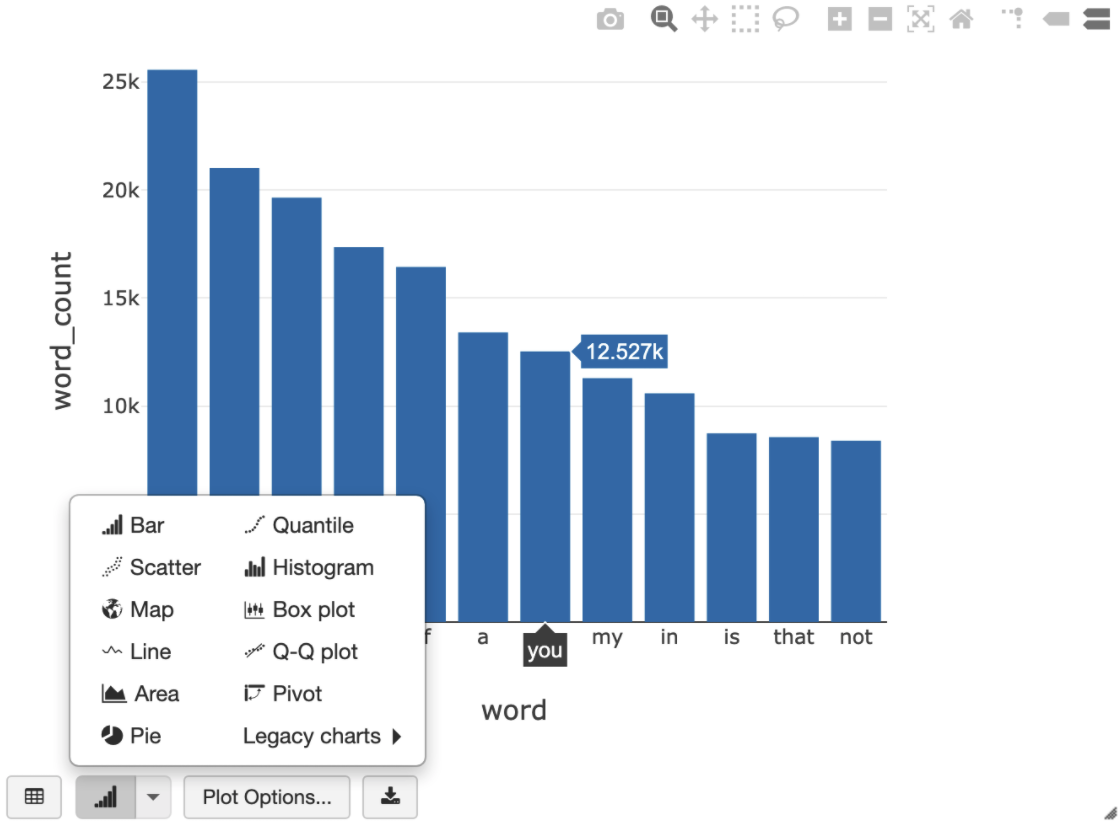
In der Zelle oben wird eine Spark SQL-Abfrage für den DataFrame in Ihrem Databricks-Cluster ausgeführt, nicht in BigQuery. Der Vorteil dieses Ansatzes besteht darin, dass die Datenanalyse auf Spark-Ebene erfolgt, keine weiteren BigQuery API-Aufrufe erfolgen und keine zusätzlichen BigQuery-Kosten entstehen.
Alternativ können Sie die Ausführung einer SQL-Abfrage mit der
query()API an BigQuery delegieren und für eine Reduzierung der Übertragungsgröße des resultierenden Datenframes optimieren. Anders als im obigen Beispiel, in dem die Verarbeitung in Spark durchgeführt wurde, gelten bei diesem Ansatz Preis- und Abfrageoptimierungen für die Ausführung der Abfrage in BigQuery.Im folgenden Beispiel werden Scala, die
query()API und das öffentliche Shakespeare-Dataset in BigQuery verwendet, um die fünf häufigsten Wörter in den Werken von Shakespeare zu berechnen. Bevor Sie den Code ausführen, müssen Sie in BigQuery ein leeres Dataset mit dem Namenmdataseterstellen, auf das der Code verweisen kann. Weitere Informationen finden Sie unter Daten in BigQuery schreiben.%scala // public dataset val table = "bigquery-public-data.samples.shakespeare" // existing dataset where the Google Cloud user has table creation permission val tempLocation = "mdataset" // query string val q = s"""SELECT word, SUM(word_count) AS word_count FROM ${table} GROUP BY word ORDER BY word_count DESC LIMIT 10 """ // read the result of a GoogleSQL query into a DataFrame val df2 = spark.read.format("bigquery") .option("query", q) .option("materializationDataset", tempLocation) .load() // show the top 5 common words in Shakespeare df2.show(5)Weitere Codebeispiele finden Sie im BigQuery-Beispiel-Notebook für Databricks.
Daten in BigQuery schreiben
BigQuery-Tabellen sind in Datasets vorhanden. Bevor Sie Daten in eine BigQuery-Tabelle schreiben können, müssen Sie in BigQuery ein neues Dataset erstellen. So erstellen Sie ein Dataset für ein Databricks-Python-Notebook:
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf.
Maximieren Sie die Option Aktionen, klicken Sie auf Dataset erstellen und vergeben Sie dann den Namen
together.Erstellen Sie im Databricks-Python-Notebook mit dem folgenden Code-Snippet einen einfachen Spark-DataFrame aus einer Python-Liste mit drei Stringeinträgen:
from pyspark.sql.types import StringType mylist = ["Google", "Databricks", "better together"] df = spark.createDataFrame(mylist, StringType())Fügen Sie dem Notebook eine weitere Zelle hinzu, die den Spark-DataFrame aus dem vorherigen Schritt in die BigQuery-Tabelle
myTableim Datasettogetherschreibt. Die Tabelle wird entweder erstellt oder überschrieben. Verwenden Sie den zuvor angegebenen Bucket-Namen.bucket = YOUR_BUCKET_NAME table = "together.myTable" df.write .format("bigquery") .option("temporaryGcsBucket", bucket) .option("table", table) .mode("overwrite").save()Prüfen Sie, ob Sie die Daten erfolgreich geschrieben haben, und fragen Sie Ihre BigQuery-Tabelle über den Spark DataFrame (
df) ab und zeigen Sie sie an:display(spark.read.format("bigquery").option("table", table).load)