Architettura
Il seguente diagramma mostra l'architettura di alto livello di una pipeline di estrazione, caricamento e trasformazione (ELT) serverless che utilizza Workflows.

Nel diagramma precedente, considera una piattaforma di vendita al dettaglio che raccoglie periodicamente eventi di vendita come file da vari negozi e poi scrive i file in un bucket Cloud Storage. Gli eventi vengono utilizzati per fornire metriche aziendali mediante l'importazione e l'elaborazione in BigQuery. Questa architettura fornisce un sistema di orchestrazione serverless e affidabile per importare i file in BigQuery ed è suddivisa nei due moduli seguenti:
- Elenco file: gestisce l'elenco dei file non elaborati aggiunti a un bucket Cloud Storage in una raccolta Firestore.
Questo modulo funziona tramite una funzione Cloud Run attivata da
un evento di archiviazione
Object Finalize, che viene generato quando un nuovo file viene aggiunto al
bucket Cloud Storage. Il nome file viene aggiunto all'array
filesdella raccolta denominatanewin Firestore. Workflow: esegue i workflow pianificati. Cloud Scheduler attiva un flusso di lavoro che esegue una serie di passaggi in base a una sintassi basata su YAML per orchestrare il caricamento e poi trasformare i dati in BigQuery chiamando funzioni Cloud Run. I passaggi del flusso di lavoro chiamano Cloud Run Functions per eseguire le seguenti attività:
- Crea e avvia un job di caricamento BigQuery.
- Estrai lo stato del job di caricamento.
- Crea e avvia il job della query di trasformazione.
- Estrai lo stato del job di trasformazione.
L'utilizzo delle transazioni per gestire l'elenco dei nuovi file in Firestore contribuisce a garantire che nessun file venga perso quando un flusso di lavoro li importa in BigQuery. Le esecuzioni separate del flusso di lavoro sono rese idempotenti memorizzando i metadati e lo stato del job in Firestore.
Obiettivi
- Crea un database Firestore.
- Configura un trigger della funzione Cloud Run per monitorare i file aggiunti al bucket Cloud Storage in Firestore.
- Esegui il deployment di Cloud Run Functions per eseguire e monitorare i job BigQuery.
- Esegui il deployment e l'esecuzione di un workflow per automatizzare il processo.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Al termine delle attività descritte in questo documento, puoi evitare l'addebito di ulteriori costi eliminando le risorse che hai creato. Per ulteriori informazioni, vedi Pulizia.
Prima di iniziare
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Build, Cloud Run functions, Identity and Access Management, Resource Manager, and Workflows APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Vai alla pagina Benvenuto e prendi nota dell'ID progetto da utilizzare in un passaggio successivo.
In the Google Cloud console, activate Cloud Shell.
prepara l'ambiente
Per preparare l'ambiente, crea un database Firestore, clona gli esempi di codice dal repository GitHub, crea risorse utilizzando Terraform, modifica il file YAML di Workflows e installa i requisiti per il generatore di file.
Per creare un database Firestore:
Nella console Google Cloud , vai alla pagina Firestore.
Fai clic su Seleziona modalità Native.
Nel menu Seleziona una località, seleziona la regione in cui vuoi ospitare il database Firestore. Ti consigliamo di scegliere una regione vicina alla tua posizione fisica.
Fai clic su Crea database.
In Cloud Shell, clona il repository di origine:
cd $HOME && git clone https://github.com/GoogleCloudPlatform/workflows-demos cd workflows-demos/workflows-bigquery-loadIn Cloud Shell, crea le seguenti risorse utilizzando Terraform:
terraform init terraform apply \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approveSostituisci quanto segue:
PROJECT_ID: il tuo ID progetto Google CloudREGION: una località geografica specifica Google Cloud in cui ospitare le tue risorse, ad esempious-central1ZONE: una località all'interno di una regione in cui ospitare le tue risorse, ad esempious-central1-b
Dovresti visualizzare un messaggio simile al seguente:
Apply complete! Resources: 7 added, 0 changed, 1 destroyed.Terraform può aiutarti a creare, modificare e aggiornare l'infrastruttura su larga scala in modo sicuro e prevedibile. Nel tuo progetto vengono create le seguenti risorse:
- Service account con i privilegi necessari per garantire l'accesso sicuro alle tue risorse.
- Un set di dati BigQuery denominato
serverless_elt_datasete una tabella denominataword_countper caricare i file in arrivo. - Un bucket Cloud Storage denominato
${project_id}-ordersbucketper la gestione temporanea dei file di input. - Le seguenti cinque funzioni Cloud Run:
file_add_handleraggiunge il nome dei file aggiunti al bucket Cloud Storage alla raccolta Firestore.create_jobcrea un nuovo job di caricamento BigQuery e associa i file nella raccolta Firebase al job.create_querycrea un nuovo job di query BigQuery.poll_bigquery_jobrecupera lo stato di un job BigQuery.run_bigquery_jobavvia un job BigQuery.
Recupera gli URL delle funzioni Cloud Run
create_job,create_query,poll_joberun_bigquery_jobdi cui hai eseguito il deployment nel passaggio precedente.gcloud functions describe create_job | grep url gcloud functions describe poll_bigquery_job | grep url gcloud functions describe run_bigquery_job | grep url gcloud functions describe create_query | grep url
L'output è simile al seguente:
url: https://REGION-PROJECT_ID.cloudfunctions.net/create_job url: https://REGION-PROJECT_ID.cloudfunctions.net/poll_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/run_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/create_query
Prendi nota di questi URL perché ti serviranno quando implementerai il workflow.
Crea ed esegui il deployment di un flusso di lavoro
In Cloud Shell, apri il file di origine del flusso di lavoro,
workflow.yaml:Sostituisci quanto segue:
CREATE_JOB_URL: l'URL della funzione per creare un nuovo jobPOLL_BIGQUERY_JOB_URL: l'URL della funzione per eseguire il polling dello stato di un job in esecuzioneRUN_BIGQUERY_JOB_URL: l'URL della funzione per avviare un job di caricamento BigQueryCREATE_QUERY_URL: l'URL della funzione per avviare un job di query BigQueryBQ_REGION: la regione BigQuery in cui vengono archiviati i dati, ad esempioUSBQ_DATASET_TABLE_NAME: il nome della tabella del set di dati BigQuery nel formatoPROJECT_ID.serverless_elt_dataset.word_count
Esegui il deployment del file
workflow:gcloud workflows deploy WORKFLOW_NAME \ --location=WORKFLOW_REGION \ --description='WORKFLOW_DESCRIPTION' \ --service-account=workflow-runner@PROJECT_ID.iam.gserviceaccount.com \ --source=workflow.yamlSostituisci quanto segue:
WORKFLOW_NAME: il nome univoco del flusso di lavoroWORKFLOW_REGION: la regione in cui viene eseguito il deployment del flusso di lavoro, ad esempious-central1WORKFLOW_DESCRIPTION: la descrizione del workflow
Crea un ambiente virtuale Python 3 e installa i requisiti per il generatore di file:
sudo apt-get install -y python3-venv python3 -m venv env . env/bin/activate cd generator pip install -r requirements.txt
Generare file da importare
Lo script Python
gen.pygenera contenuti casuali in formato Avro. Lo schema è lo stesso della tabellaword_countBigQuery. Questi file Avro vengono copiati nel bucket Cloud Storage specificato.In Cloud Shell, genera i file:
python gen.py -p PROJECT_ID \ -o PROJECT_ID-ordersbucket \ -n RECORDS_PER_FILE \ -f NUM_FILES \ -x FILE_PREFIXSostituisci quanto segue:
RECORDS_PER_FILE: il numero di record in un singolo fileNUM_FILES: il numero totale di file da caricareFILE_PREFIX: il prefisso per i nomi dei file generati
Visualizzare le voci dei file in Firestore
Quando i file vengono copiati in Cloud Storage, viene attivata la funzione Cloud Run
handle_new_file. Questa funzione aggiunge l'elenco dei file all'array dell'elenco dei file nel documentonewnella raccolta Firestorejobs.Per visualizzare l'elenco dei file, nella console Google Cloud , vai alla pagina Dati di Firestore.
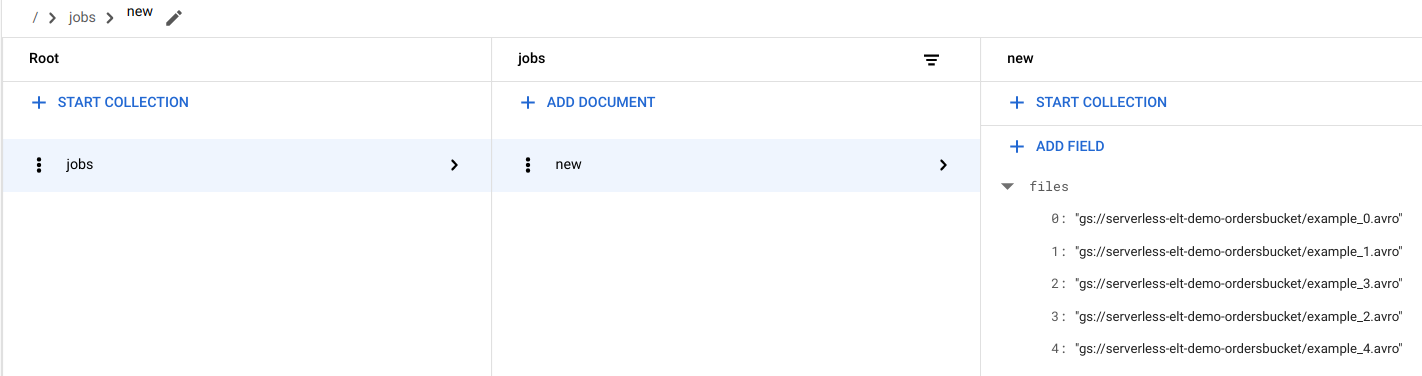
Attivare il workflow
Workflows collega una serie di attività serverless daGoogle Cloud e servizi API. I singoli passaggi di questo flusso di lavoro vengono eseguiti come funzioni Cloud Run e lo stato viene archiviato in Firestore. Tutte le chiamate alle funzioni Cloud Run vengono autenticate utilizzando l'account di servizio del flusso di lavoro.
In Cloud Shell, esegui il flusso di lavoro:
gcloud workflows execute WORKFLOW_NAME
Il seguente diagramma mostra i passaggi utilizzati nel flusso di lavoro:

Il flusso di lavoro è suddiviso in due parti: il flusso di lavoro principale e il flusso di lavoro secondario. Il workflow principale gestisce la creazione dei job e l'esecuzione condizionale, mentre il workflow secondario esegue un job BigQuery. Il flusso di lavoro esegue le seguenti operazioni:
- La funzione Cloud Run
create_jobcrea un nuovo oggetto job, recupera l'elenco dei file aggiunti a Cloud Storage dal documento Firestore e associa i file al job di caricamento. Se non ci sono file da caricare, la funzione non crea un nuovo job. - La funzione Cloud Run
create_queryaccetta la query da eseguire insieme alla regione BigQuery in cui deve essere eseguita. La funzione crea il job in Firestore e restituisce l'ID job. - La funzione Cloud Run
run_bigquery_jobrecupera l'ID del job da eseguire, quindi chiama l'API BigQuery per inviare il job. - Anziché attendere il completamento del job nella funzione Cloud Run, puoi eseguire periodicamente il polling dello stato del job.
- La funzione Cloud Run
poll_bigquery_jobfornisce lo stato del job. Viene chiamato ripetutamente fino al completamento del job. - Per aggiungere un ritardo tra le chiamate alla funzione Cloud Run, viene chiamata una routine
sleepda Workflows.poll_bigquery_job
- La funzione Cloud Run
Visualizzare lo stato del job
Puoi visualizzare l'elenco dei file e lo stato del job.
Nella console Google Cloud , vai alla pagina Dati di Firestore.
Per ogni job viene generato un identificatore univoco (UUID). Per visualizzare
job_typeestatus, fai clic sull'ID job. Ogni job può avere uno dei seguenti tipi e stati:job_type: Il tipo di job eseguito dal flusso di lavoro con uno dei seguenti valori:- 0: Carica i dati in BigQuery.
- 1. Esegui una query in BigQuery.
status: lo stato attuale del job con uno dei seguenti valori:- 0: Il job è stato creato, ma non avviato.
- 1: Il job è in esecuzione.
- 2: L'esecuzione del job è stata completata correttamente.
- 3: Si è verificato un errore e il job non è stato completato correttamente.
L'oggetto job contiene anche attributi di metadati come la regione del set di dati BigQuery, il nome della tabella BigQuery e, se si tratta di un job di query, la stringa di query in esecuzione.
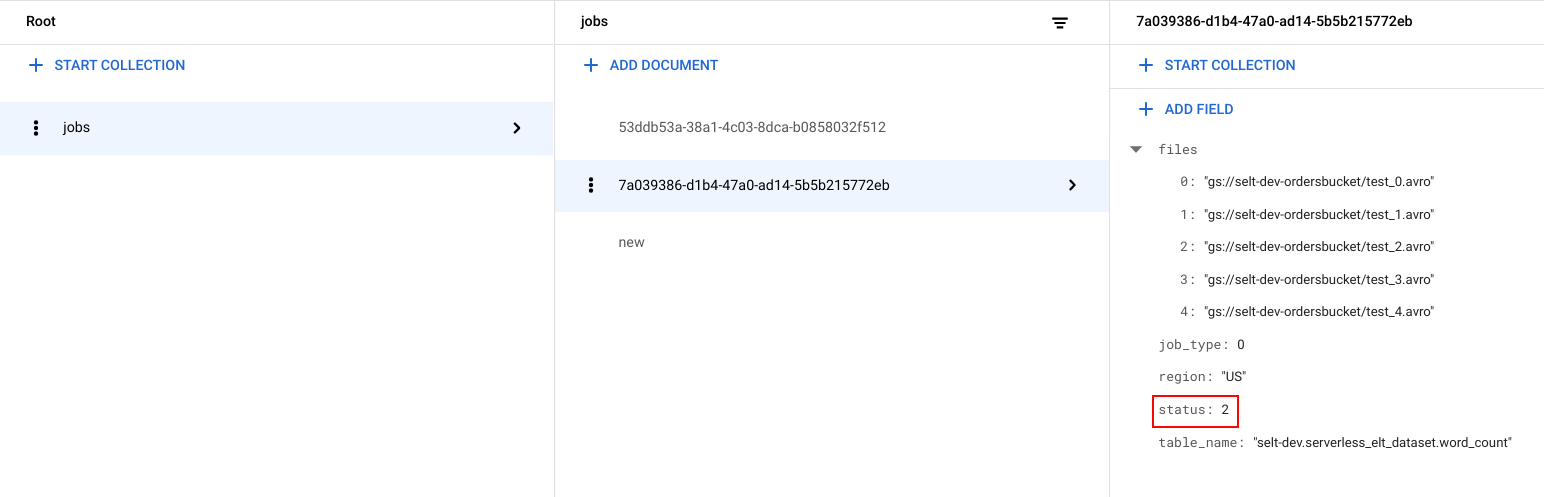
Visualizzare i dati in BigQuery
Per verificare che il job ELT sia andato a buon fine, controlla che i dati vengano visualizzati nella tabella.
Nella console Google Cloud , vai alla pagina Editor di BigQuery.
Fai clic sulla tabella
serverless_elt_dataset.word_count.Fai clic sulla scheda Anteprima.
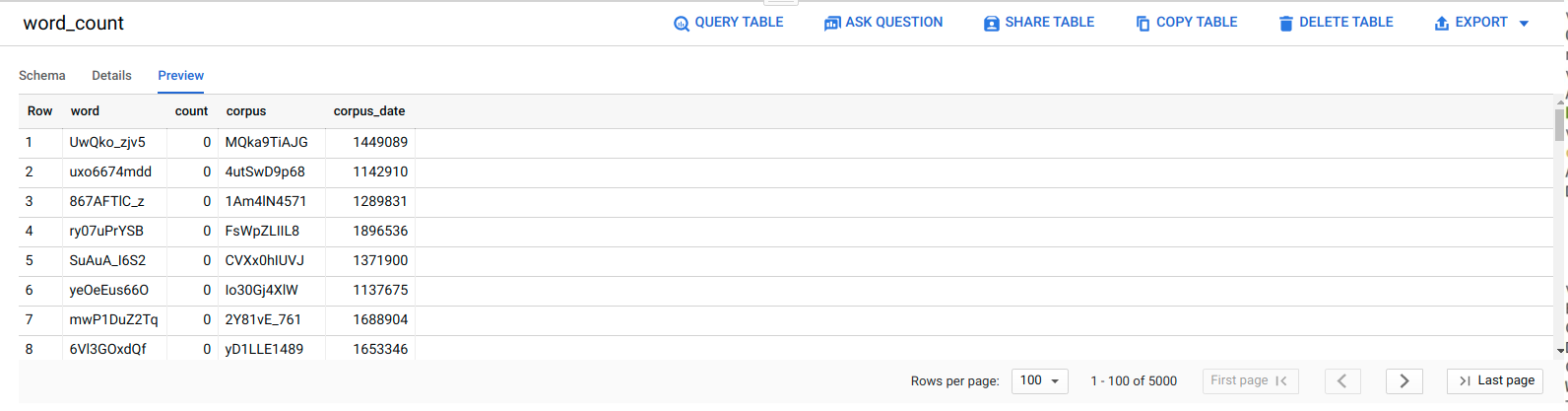
Pianifica il workflow
Per eseguire periodicamente il flusso di lavoro in base a una pianificazione, puoi utilizzare Cloud Scheduler.
Esegui la pulizia
Il modo più semplice per eliminare la fatturazione è eliminare il progetto che hai creato per il tutorial. Google Cloud In alternativa, puoi eliminare le singole risorse.Elimina le singole risorse
In Cloud Shell, rimuovi tutte le risorse create utilizzando Terraform:
cd $HOME/bigquery-workflows-load terraform destroy \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve
Nella console Google Cloud , vai alla pagina Dati di Firestore.
Accanto a Lavori, fai clic su Menu e seleziona Elimina.
Elimina il progetto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Per scoprire di più su BigQuery, consulta la documentazione di BigQuery.
- Scopri come creare pipeline di machine learning personalizzate serverless.
- Per ulteriori architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center.