本页面介绍 Cloud SQL 中的灾难恢复。
概览
在 Google Cloud中,数据库灾难恢复 (DR) 的目的是让处理过程不中断,尤其是当某个区域出现故障或无法访问时。Cloud SQL 是一项区域级服务(当 Cloud SQL 配置为实现高可用性 [HA] 时)。因此,当托管 Cloud SQL 数据库的 Google Cloud 区域不可用时,Cloud SQL 数据库也会不可用。
如需继续处理,您必须尽快在辅助区域中提供该数据库。灾难恢复方案要求您在 Cloud SQL 中配置跨区域只读副本。您也可以根据导出/导入或备份/恢复执行故障切换,但这种方法需要花费更长时间,尤其是对于大型数据库而言。
以下业务场景是保证跨区域故障切换配置的示例:
- 业务应用的服务等级协议高于区域级 Cloud SQL 服务等级协议(可用性为 99.99%,具体取决于您的 Cloud SQL 版本)。通过故障切换切换到另一个区域,您可以缓解中断所造成的影响。
- 业务应用的所有层级已经属于多区域,其可在区域发生服务中断时继续处理。跨区域故障切换配置有助于实现数据库的持续可用性。
- 所需的恢复时间目标 (RTO) 和恢复点目标 (RPO) 都以分钟为单位,而不是以小时为单位。与重新创建数据库相比,通过故障切换切换到另一个区域的速度更快。
一般来说,灾难恢复过程包含两种变化形式:
- 数据库通过故障切换切换到辅助区域。数据库准备就绪并供应用使用后,它将作为新的主数据库并持续作为主数据库。
- 数据库通过故障切换切换到辅助区域,但在主区域从故障中恢复后,将回到主区域。
此 Google Cloud SQL 数据库灾难恢复概览介绍了第二个变体:发生故障的数据库恢复并回退到主要区域。对于因为网络延迟或者因为某些资源仅在主要区域中可用而必须在主要区域运行的数据库,这种灾难恢复变体尤为有用。使用此变体时,数据库只会在主要区域服务中断期间在辅助区域运行。
与此灾难恢复文档关联的两个教程:灾难恢复架构
下图显示了支持高可用性 Cloud SQL 实例进行数据库灾难恢复的最小架构:
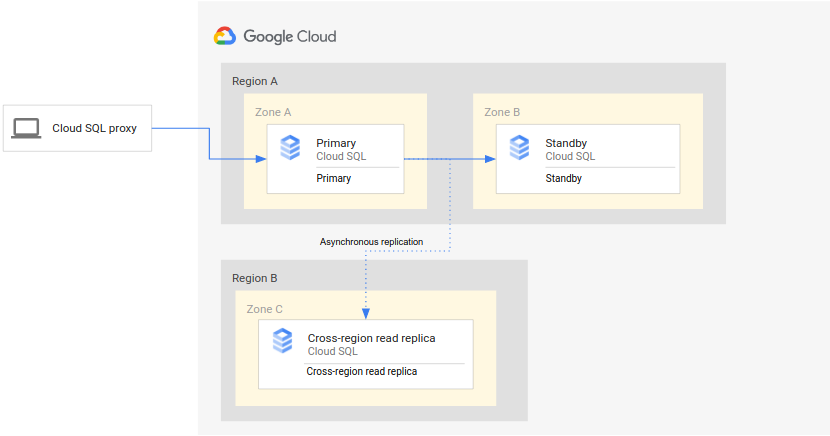
该架构的工作原理如下:
- Cloud SQL 的两个实例(主实例和备用实例)位于单个区域(主要区域)内的两个不同地区中。系统将使用区域永久性磁盘同步实例。
- 一个 Cloud SQL 实例(跨区域只读副本)位于另一个区域(辅助区域)。对于灾难恢复,设置跨区域只读副本以使用只读副本设置与主实例同步(使用异步复制)。
主实例和备用实例共享同一区域磁盘,因此它们的状态相同。
由于此类设置使用异步复制,因此跨区域只读副本可能会滞后于主实例。因此,当发生故障切换时,跨区域只读副本 RPO 可能不为零。
灾难恢复 (DR) 过程
灾难恢复 (DR) 过程会在主要区域不可用时启动。如需继续在次要区域中进行处理,请通过升级跨区域只读副本来触发主实例的故障切换。灾难恢复过程会设置必须手动或自动执行的操作步骤,从而减少区域级故障并在次要区域中建立正在运行的主实例。
下图展示了此灾难恢复过程:
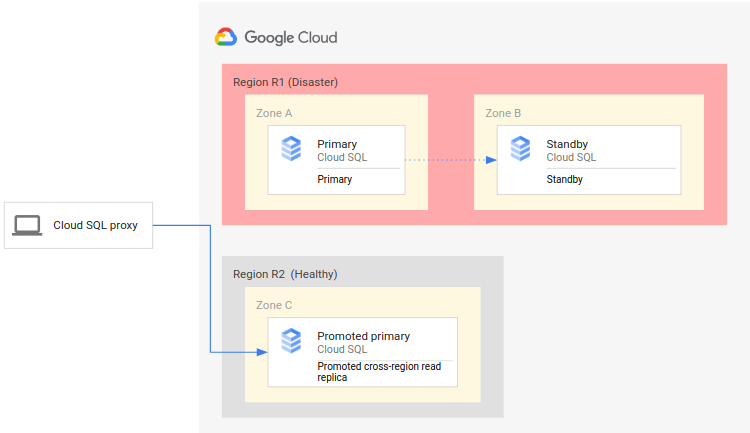
灾难恢复过程包括以下步骤:
- 运行主实例的主要区域 (R1) 不可用。
- 运营团队识别并正式确认灾难,并确定是否需要故障切换。
- 如果需要故障切换,您可以将次要区域 (R2) 中的跨区域只读副本提升为新的主实例。
- 客户端连接已重新配置为继续处理新的主实例,并访问 R2 中的主实例。
此初始过程会再次建立一个正常运行的主数据库。但是,它不会建立完整的灾难恢复架构,其中新的主实例本身具有一个备用实例和一个跨区域只读副本。
完整的灾难恢复过程可确保为 HA 启用单个实例(即新的主实例),并确保该实例具有跨区域只读副本。完整的 DR 过程还会提供回退到原始主区域中的原始部署的机制。
通过故障切换切换到辅助区域
完整灾难恢复过程在基本灾难恢复过程的基础上进行了扩展,它在故障切换之后增加了建立完整灾难恢复架构的步骤。下图展示了故障切换之后的完整数据库灾难恢复架构:
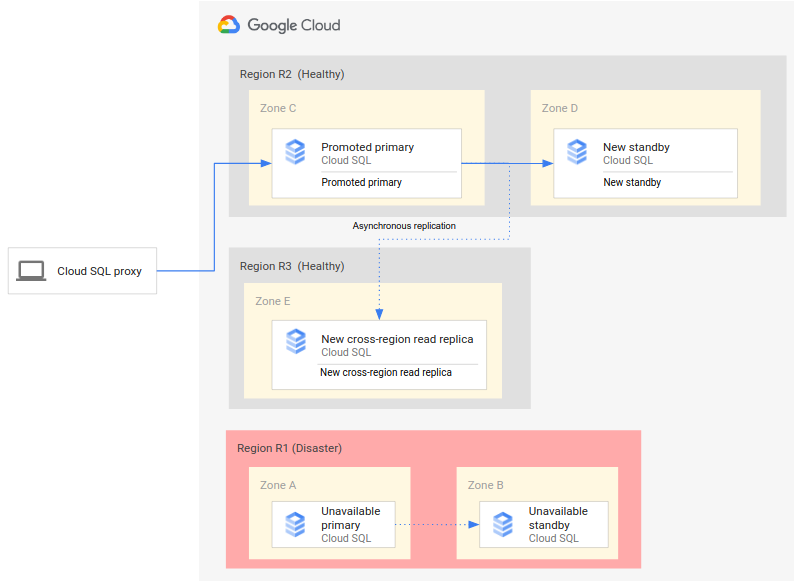
完整数据库灾难恢复过程包括以下步骤:
- 运行主数据库的主要区域 (R1) 不可用。
- 运营团队识别并正式确认灾难,并确定是否需要故障切换。
- 如果需要故障切换,您可以将辅助区域 (R2) 中的跨区域只读副本提升为新的主实例。
- 客户端连接已重新配置为访问并处理新的主实例 (R2)。
- 系统会在 R2 中创建并启动一个新的备用实例并将其添加到主实例中。备用实例与主实例位于不同的可用区。主实例现在具有高可用性,因为已为它创建备用实例。
- 在第三个区域 (R3) 中,系统会创建一个新的跨区域只读副本并将其附加到主实例。此时,完整灾难恢复架构将被重新创建且正常运行。
如果原始主要区域 (R1) 在实现第 6 步之前可用,则跨区域只读副本可以放在区域 R1 中,而不是立即放在区域 R3 中。在此情况下,回退到原始主要区域 (R1) 的步骤不太复杂,所需步骤较少。
避免出现脑裂状态
主要区域 (R1) 故障并不意味着原始主实例及其备用实例会自动关停、移除或在 R1 再次可用时无法访问。如果 R1 可用,客户端可能会在原始主实例上读取和写入数据(甚至意外读取和写入数据)。在这种情况下,脑裂情况可能会出现,即有些客户端访问旧主数据库中的过时数据,而有些客户端访问新的主数据库中的最新数据,从而导致业务出现问题。
为避免出现脑裂情况,在 R1 可用后,您必须确保客户端无法再访问原始主实例。理想情况下,您应先使原始主实例无法访问,再开始使用新的主实例,然后删除无法访问的原始主实例。
在故障切换后建立初始备份
在故障切换中,当您将跨区域只读副本提升为新的主实例时,新主实例中的事务可能不会完全与原始主实例中的事务同步。因此,这些事务在新实例中不可用。
根据最佳做法,我们建议您在故障切换开始时以及在客户访问数据库之前立即备份新的主实例。此类备份表示在进行故障切换时处于一致的已知状态。如果客户在访问新的主实例时遇到问题,则此类备份对于监管目的或恢复为已知状态而言可能很重要。
回退到原始主要区域
如前所述,本文档提供回退到原始区域 (R1) 的步骤。回退过程有两个不同版本。
- 如果您在第三区域 (R3) 中创建了新的跨区域只读副本,则必须在主要区域 (R1) 中创建另一个(第二个)跨区域只读副本。
- 如果您在主要区域 (R1) 中创建了新的跨区域只读副本,则无需在 R1 中另外创建一个跨区域只读副本。
当 R1 中存在跨区域只读副本后,Cloud SQL 实例便可以回退到 R1。由于此回退操作是手动触发而不是根据服务中断触发的,因此您可以为此维护活动选择合适的日期和时间。
因此,为实现具有主实例和备用实例以及跨区域只读副本的完整灾难恢复,您需要执行两次故障切换。第一次故障切换由服务中断触发(真正的故障切换),第二次故障切换会重新建立起始部署(回退)。
回退到原始主要区域 (R1) 的过程包括以下步骤:
- 升级原始主要区域 (R1) 中新创建的跨区域副本。
- 如果升级的实例最初并非作为高可用性副本创建,请在实例上启用高可用性以防止发生可用区故障。
- 重新配置您的应用以连接到新的主实例。
- 在灾难恢复区域 (R2) 中为新的主实例创建一个跨区域副本。
- (可选)为避免运行多个独立的主实例,请清理灾难恢复区域 (R2) 中的主实例。
高级灾难恢复 (DR)
如果您使用的是 Cloud SQL 企业 Plus 版,则可以利用高级灾难恢复。高级灾难恢复简化了跨区域故障切换后的恢复和回退过程。如灾难恢复过程中所述,执行灾难恢复时,您需要移除旧主实例的故障区域与新主实例的操作区域之间的连接。使用灾难恢复时,如需恢复与原始部署区域的连接并重新获得旧的主实例,您必须执行一系列手动回退步骤。
使用高级灾难恢复时,如果发生区域性故障,您可以调用副本故障切换。使用副本故障切换时,您需要升级跨区域只读副本,此过程与执行常规灾难恢复类似,不同之处是需要升级指定的灾难恢复 (DR) 副本。提升灾难恢复副本的过程很快。
系统不会移除旧的主实例,该实例仍会保留为 Cloud SQL 异步复制拓扑的一部分。在灾难恢复副本升级为新的主实例后,旧的主实例(实例 A)最终会成为其灾难恢复副本(实例 B)的副本。
旧的主实例 (A) 转换为副本后,您可以执行高级灾难恢复的最后一步。您可以将 Cloud SQL 部署恢复为原始状态,并将旧的主实例 (A) 恢复为以前的角色(即主实例),而不会丢失任何数据。如需对旧的主实例 (A) 执行无任何数据丢失的恢复过程,您可以使用切换操作。执行切换时,不会丢失任何数据,因为主实例 (B) 在其指定的灾难恢复副本 (A) 完成与主实例 (B) 的同步之前一直保持只读模式。在灾难恢复副本 (A) 收到所有复制更新后,灾难恢复副本 (A) 会充当主实例,而之前的主实例 (B) 会自动重新配置为当前主实例 (A) 的灾难恢复副本。实例会恢复为原始角色,从而将拓扑恢复到进行灾难恢复和副本故障切换之前的原始状态。
在整个高级灾难恢复过程中,副本故障切换和切换操作涉及的所有实例都将保留其 IP 地址。
您还可以使用高级灾难恢复的切换操作执行例行灾难恢复深入分析,以便在灾难发生之前测试和准备用于跨区域故障切换的 Cloud SQL 拓扑。如果发生实际灾难,您可以执行已测试的跨区域副本故障切换。
灾难恢复 (DR) 副本
作为高级灾难恢复的必需组成元素,灾难恢复副本具有以下特征:
- 灾难恢复副本是直接连接的跨区域只读副本。
- 您可以多次更改指定的灾难恢复副本。
- 除了在切换或副本故障切换操作期间外,您可以随时更改指定的灾难恢复副本。
此外,为了在使用高级灾难恢复后降低 RTO,我们建议您执行以下操作:
- 配置与主实例大小相同的灾难恢复副本。
- 如果主实例启用了高可用性,我们建议您也对灾难恢复副本启用高可用性。为此,请先验证主实例是否启用了高可用性。然后,执行切换到灾难恢复副本的操作。切换操作完成后,对新的主实例启用高可用性。然后,您可以切换回旧的主实例。即使灾难恢复副本再次成为副本,它也会保留其高可用性配置。
副本故障切换
总而言之,副本故障切换包含以下事件:
- 创建和分配灾难恢复副本。
- 主要区域变为不可用。
- 执行副本故障切换以切换到灾难恢复副本。
- 写入端点会被更新,并开始指向新的主实例。
- 当原始主实例恢复在线状态后,它会成为新的主实例的读取副本。
- 您可以使用切换操作将部署恢复到其原始拓扑。
如需查看副本故障切换操作的详细信息和图表,请点击以下标签页。
分配灾难恢复副本
在执行副本故障切换之前,您已为主实例分配了一个灾难恢复副本,并且可能已经通过执行切换测试了该过程。

发生服务中断
运行主数据库的主要区域不可用。

副本故障切换
确定需要执行灾难恢复后,您可以执行副本故障切换以切换到指定的跨区域灾难恢复副本。
指定的跨区域灾难恢复副本会立即成为主实例,并开始接受传入的读取和写入。写入端点会被更新,并开始指向新的主实例。

原始主实例变为副本
提升副本后,Cloud SQL 会定期检查原始主实例是否已恢复为在线状态。如果原始主实例处于在线状态,Cloud SQL 会将旧的主实例重新创建为提升的实例的副本。旧的主实例会保留其 IP 地址。

故障恢复到原始状态
执行副本故障切换后,您可以通过执行切换来恢复相同的灾难恢复副本和主实例对,从而恢复原始区域中的主实例。

切换
总而言之,切换操作包括以下事件:
- 创建和分配灾难恢复副本。
- 启动切换。
- 当复制延迟时间减少到零时,新的主实例开始接受传入的连接。
- 旧的主实例成为读取副本。
- 如果 DNS 写入端点正在使用中,则 DNS 写入端点会更新为指向新的主实例。
如需查看切换操作的详细信息和图表,请点击以下标签页。
分配灾难恢复副本
在开始 *切换* 操作之前,您必须为主实例分配灾难恢复副本。
验证主实例的运行状况是否良好。只有在主实例和灾难恢复副本都处于在线状态时,才能执行切换。
启动切换
您可以启动切换。启动切换时,主实例会停止接受写入,变为只读状态。Cloud SQL 等待事务日志复制到 Cloud Storage。指定的灾难恢复副本完全与主实例同步。
当复制延迟时间减少到零时,灾难恢复副本将提升为新的主实例。新的主实例开始接受传入的连接,包括应用读取和写入。
端点已更新
灾难恢复副本提升为新的主实例后,DNS 写入端点会更新并开始指向新的主实例。如果您未使用 DNS 写入端点,则必须将应用配置为指向新的主实例的 IP 地址。
旧的主实例重新配置为只读副本。
系统会自动为新的主实例启用 PITR。只有在首次自动备份后才可以使用 PITR。
写入端点
写入端点是一个全球域名服务 (DNS) 名称,它会自动解析为当前主实例的 IP 地址。如果发生副本故障切换或切换操作,此端点会自动将传入连接重定向到新的主实例。您可以在 SQL 连接字符串中使用写入端点,而不是 IP 地址。通过使用写入端点,您可以避免在发生区域级服务中断时不得不更改应用连接。
写入端点要求在其中创建 Cloud SQL 企业 Plus 版主实例或已有 Cloud SQL 企业 Plus 版主实例的项目已启用 Cloud DNS API。当您创建具有专用 IP 地址和已获授权的网络的 Cloud SQL 企业 Plus 版实例时,Cloud SQL 会自动为该实例生成写入端点。如果您已有 Cloud SQL 企业 Plus 版主实例,则 Cloud SQL 会在您创建灾难恢复副本(您为主实例指定的跨区域副本)时生成写入端点。如果主实例因切换或副本故障切换操作而更改,则 Cloud SQL 会在灾难恢复副本成为新的主实例时将写入端点分配给灾难恢复副本。
如需详细了解如何使用写入端点连接到实例,请参阅使用写入端点连接到实例。
后续步骤
- 使用高级灾难恢复 (DR)。
- 尝试 Cloud SQL for MySQL 灾难恢复教程。
- 探索有关 Google Cloud的参考架构、图表、教程和最佳实践。查看我们的 Cloud 架构中心。