このドキュメントは、 Google Cloudの障害復旧(DR)について説明するシリーズのパート 2 です。このパートでは、DR 計画の構成要素として使用できるサービスと製品( Google Cloud プロダクトと、プラットフォームを横断して動作する製品の両方)について説明します。
シリーズは次のパートで構成されています。
- 障害復旧計画ガイド
- 障害復旧の構成要素(この記事)
- データの障害復旧シナリオ
- アプリケーションの障害復旧シナリオ
- 地域制限があるワークロードの障害復旧の設計
- 障害復旧のユースケース: 地域制限のあるデータ分析アプリケーション
- クラウド インフラストラクチャの停止に対する障害復旧の設計
Google Cloud には、障害復旧アーキテクチャの一部として使用できる幅広いプロダクトが用意されています。このセクションでは、 Google Cloud DR 構成要素として最も一般的に使用されているプロダクトの DR 関連の機能について説明します。
これらのサービスの多くは、高可用性(HA)機能を備えています。HA は DR と完全に重複するわけではありませんが、HA の目標の多くは DR 計画の設計にも該当します。たとえば HA 機能を活用することで、稼働時間を最適化し、単一の VM の障害といった小規模な障害の影響を軽減できるアーキテクチャを設計できます。DR と HA の関係の詳細については、障害復旧計画ガイドをご覧ください。
以降のセクションで、こうした Google Cloud DR 構成要素の概要と、これらの構成要素が DR 目標の達成にどのように役立つかについて説明します。
コンピューティングとストレージ
次の表に、DR の構成要素として機能する Google Cloud のコンピューティング サービスとストレージ サービスの機能の概要を示します。
| プロダクト | 機能 |
|---|---|
| Compute Engine |
|
| Cloud Storage |
|
| Google Kubernetes Engine(GKE) |
|
こうしたGoogle Cloud プロダクトの機能と設計が DR 戦略に与える影響の詳細については、クラウド インフラストラクチャの停止に対する障害復旧の設計: プロダクト リファレンスをご覧ください。
Compute Engine
Compute Engine は仮想マシン(VM)インスタンスを提供する、 Google Cloudの主力サービスです。Compute Engine インスタンスの構成、起動、モニタリングに加えて、DR 計画を実装するために、通常はさまざまな機能を使用します。
DR シナリオでは、削除保護フラグを設定すると、VM を誤って削除することを防止できます。これは特に、データベースなどのステートフルなサービスをホストする場合に便利です。
低い RTO 値と RPO 値を達成する方法については、復元性に優れたシステムの設計をご覧ください。
インスタンス テンプレート
Compute Engine のインスタンス テンプレートを使用して VM の構成の詳細を保存すると、既存のインスタンス テンプレートから Compute Engine インスタンスを作成できます。テンプレートを使用すると、好みの方法で構成した必要な数のインスタンスを必要なときに起動して、DR ターゲット環境を立ち上げられます。インスタンス テンプレートはグローバルに複製されるため、インスタンスを Google Cloud 内の任意の場所に同じ構成で再作成できます。
詳しくは、次のリソースをご覧ください。
Compute Engine イメージの使用方法については、このドキュメントの後半のイメージ構成とデプロイ速度のバランスをとるをご覧ください。
マネージド インスタンス グループ
マネージド インスタンス グループは、Cloud Load Balancing(このドキュメントの後半で説明)と連携して、ゾーン間でコピーされた同一構成のインスタンスのグループにトラフィックを分散させます。マネージド インスタンス グループでは、自動スケーリングや自動修復などの機能を使用できます。こうした機能により、インスタンスの削除や再作成を自動的に行うことができます。
予約
Compute Engine では、カスタムまたは事前定義のマシンタイプを使用して、特定のゾーンの VM インスタンスを予約できます。予約する VM インスタンスには、GPU またはローカル SSD を追加することもできます。DR 用のミッション クリティカルなワークロードの容量を確保するには、DR ターゲット ゾーンに予約を作成する必要があります。予約がない場合、復旧時間目標を満たすために必要なオンデマンド容量が得られない可能性があります。予約は、コールド、ウォーム、ホット DR のシナリオで役立ちます。これにより、低 RTO のニーズを満たせるように、フェイルオーバーに利用可能なリカバリ リソースを保持できます。事前にリソースをフル構成してデプロイする必要はありません。
永続ディスクとスナップショット
永続ディスクは長期的なネットワーク ストレージ デバイスで、インスタンスからアクセスできます。永続ディスクはインスタンスから独立しているため、インスタンスを削除した後でも、永続ディスクを接続解除または移動してデータを保持することが可能です。
障害の発生時には、Compute Engine VM の増分バックアップまたはスナップショットを作成し、それをリージョン間でコピーして、永続ディスクを再作成できます。さらに永続ディスクのスナップショットを作成すると、ユーザーエラーによりデータが失われることを防止できます。スナップショットは増分なので、スナップショット ディスクが実行中のインスタンスにアタッチされている場合でも、わずか数分で作成できます。
永続ディスクには冗長性が組み込まれているため、機器の故障からデータを保護するとともに、データセンターのメンテナンス中でもデータの可用性を保証します。永続ディスクはリージョン リソースまたはゾーンリソースのいずれかです。リージョン永続ディスクでは同じリージョン内の 2 つのゾーン間で書き込みが複製されます。ゾーンが停止した場合、バックアップ VM インスタンスで、もう一方のゾーンのリージョン永続ディスクを強制接続できます。詳細については、リージョン永続ディスクを使用した高可用性オプションをご覧ください。
透過的メンテナンス
Google では、インフラストラクチャを定期的にメンテナンスしています。最新のソフトウェアを使用してシステムにパッチを適用し、ルーチンテストと予防的メンテナンスを実施して、Google インフラストラクチャが可能な限り高速かつ効率的に機能するようにしています。
デフォルトで、すべての Compute Engine インスタンスは、メンテナンス イベントがアプリケーションやワークロードに影響を与えないように構成されます。詳しくは、透過的メンテナンスをご覧ください。
メンテナンス イベントが発生すると、Compute Engine はライブ マイグレーションを使用して、実行中のインスタンスを同じゾーンの別のホストに自動的に移行します。このライブ マイグレーションにより、Google は VM の処理を妨げることなくインフラストラクチャのメンテナンスを行い、保護状態と信頼性を維持できます。
仮想ディスク インポート ツール
仮想ディスク インポート ツールを使用すると、VMDK、VHD、RAW などのファイル形式をインポートして、新しい Compute Engine 仮想マシンを作成できます。このツールを使用すると、オンプレミスの仮想マシンと同じ構成の Compute Engine 仮想マシンを作成できます。この方法は、イメージにすでにインストールされているソフトウェアのソースバイナリから Compute Engine イメージを構成できない場合に適しています。
自動バックアップ
タグを使用すると、Compute Engine インスタンスのバックアップを自動化できます。たとえば、Backup and DR サービスを使用してバックアップ プラン テンプレートを作成し、そのテンプレートを Compute Engine インスタンスに自動的に適用できます。
詳細については、新しい Compute Engine インスタンスの保護を自動化するをご覧ください。
Cloud Storage
Cloud Storage は、バックアップ ファイルの保存に理想的なオブジェクト ストアです。次の図のような特定のユースケースに適した、さまざまなストレージ クラスが用意されています。

DR シナリオで重要となるのは、Nearline Storage、Coldline Storage、Archive Storage です。これらのストレージ クラスでは、Standard Storage に比べてストレージ コストを削減できます。ただし、これらのクラスに格納されているデータやメタデータには、最小保存期間の課金に加え、取得に関連する追加コストがかかります。Nearline はアクセスが最大でも月 1 回のバックアップ シナリオ用に設計されているため、費用を抑えながら定期的な DR ストレステストを実施するのに最適です。
Nearline、Coldline、Archive はいずれも低いアクセス頻度に合わせて最適化されており、料金モデルはこの点を念頭に置いて設計されています。そのため課金は最小保存期間に対して行われ、クラスの最小保存期間よりも早い時期には、これらのクラスのデータまたはメタデータの取得に対して追加料金が発生します。
Cloud Storage バケット内のデータが誤ってまたは悪意を持って削除された場合でもデータを保護するために、削除(復元可能)機能を使用して、削除されたオブジェクトと上書きされたオブジェクトを一定期間保持できます。また、オブジェクト保持機能を使用して、オブジェクトの削除や更新を防止することもできます。
Storage Transfer Service を使用すると、Amazon S3、Azure Blob Storage、またはオンプレミス データソースから Cloud Storage にデータをインポートできます。DR のシナリオでは、Storage Transfer Service を使用して次のことができます。
- データを他のストレージ プロバイダから Cloud Storage バケットにバックアップする。
- デュアルリージョンまたはマルチリージョンのバケットからリージョン内のバケットにデータを移動して、バックアップの保存コストを削減する。
Filestore
Filestore インスタンスは、Compute Engine インスタンスまたは GKE クラスタで実行するアプリケーションで使用するフルマネージド NFS ファイル サーバーです。
Filestore の基本ティアとゾーンティアはゾーンリソースであり、ゾーン間のレプリケーションをサポートしていません。Filestore の Enterprise ティア インスタンスは、リージョン リソースです。Filestore 環境の復元力を高めるには、Enterprise ティア インスタンスを使用することをおすすめします。
Google Kubernetes Engine
GKE は、コンテナ化されたアプリケーションをデプロイするためのプロダクション レディなマネージド環境です。GKE では HA システムをオーケストレートすることができ、次のような機能が用意されています。
- ノードの自動修復。ノードが長い期間(10 分前後)連続してヘルスチェックに失敗すると、GKE はそのノードの修復プロセスを開始します。
- liveness プローブと readiness プローブ。liveness プローブを指定すると、定期的に GKE に Pod が稼働中であることが通知されます。Pod がプローブに失敗した場合、プローブを再起動できます。
- マルチゾーン クラスタとリージョン クラスタ。Kubernetes リソースは、リージョン内の複数のゾーンを横断して分散できます。
- マルチクラスタ Gateway を使用すると、異なるリージョンの複数の GKE クラスタ間で共有されたロード バランシング リソースを構成できます。
- Backup for GKE を使用すると、GKE クラスタのワークロードをバックアップおよび復元できます。
ネットワーキングとデータ転送
次の表に、DR の構成要素として機能する Google Cloud ネットワーキング サービスとデータ移転サービスの機能の概要を示します。
| プロダクト | 機能 |
|---|---|
| Cloud Load Balancing |
|
| Cloud Service Mesh |
|
| Cloud DNS |
|
| Cloud Interconnect |
|
Cloud Load Balancing
Cloud Load Balancing は、アプリケーションの複数のインスタンスにユーザー トラフィックを分散することで、 Google Cloud コンピューティング プロダクトの高可用性を実現します。インスタンスが使用可能かどうかを判断するヘルスチェックを Cloud Load Balancing で構成すると、障害が発生したインスタンスにトラフィックがルーティングされることを防止できます。
Cloud Load Balancing は、アプリケーションの前に単一のエニーキャスト IP アドレスを配置します。アプリケーションでは異なるリージョン(ヨーロッパと米国など)でインスタンスを実行することができ、エンドユーザーは最も近いインスタンスに誘導されます。インターネットに公開されているサービスのロード バランシングを実現できるだけでなく、プライベート ロード バランシング IP アドレスの背後にあるサービスに対して内部ロード バランシングを構成することもできます。この IP アドレスには、Virtual Private Cloud(VPC)の内部にある VM インスタンスでのみアクセスできます。
詳細については、Cloud Load Balancing の概要をご覧ください。
Cloud Service Mesh
Cloud Service Mesh は、 Google Cloudで利用可能な Google 管理のサービス メッシュです。Cloud Service Mesh は、アプリケーションに関する詳しい分析情報の収集に役立つ詳細なテレメトリーを提供します。さまざまなコンピューティング インフラストラクチャで実行されるサービスをサポートしています。
Cloud Service Mesh は、回路遮断やフォールト インジェクションなどの高度なトラフィック管理機能とルーティング機能もサポートしています。回路遮断を使用すると、特定のサービスに対するリクエスト数を制限できます。回路遮断の制限に達すると、リクエストはそのサービスに到達できなくなるため、サービスのさらなるパフォーマンス低下を防ぐことができます。フォールト インジェクションを使用すると、Cloud Service Mesh でリクエストの一部を意図的に遅延または中断させることができます。これにより、リクエストの遅延や中断に対するサービスの耐性をテストできます。
詳細については、Cloud Service Mesh の概要をご覧ください。
Cloud DNS
Cloud DNS は自動復旧プロセスの一環として、DNS エントリをプログラムで管理する方法を提供します。Cloud DNS は、Google のエニーキャスト ネームサーバーの世界的ネットワークを使用して、全世界のあらゆる場所からお客様の DNS ゾーンをサポートし、ユーザーに高可用性と低レイテンシを提供します。
オンプレミスで DNS エントリを管理する場合、Google Cloud 内で VM を有効化し、Cloud DNS の転送によってこれらのアドレスを解決できます。
Cloud DNS は、DNS リクエストへの応答方法を構成するポリシーをサポートしています。たとえば、特定の条件に基づいてトラフィックをステアリングするように DNS ルーティング ポリシーを構成できます。具体的には、バックアップ構成へのフェイルオーバーを有効にして高可用性を実現したり、地理的位置に基づいて DNS リクエストを転送したりできます。
Cloud Interconnect
Cloud Interconnect は、情報を他のソースから Google Cloudに移動する方法を提供します。このプロダクトについては、後述する Google Cloudとの間でデータを転送するのセクションで説明します。
管理とモニタリング
次の表に、DR の構成要素として機能する Google Cloud 管理サービスとモニタリング サービスの機能の概要を示します。
| プロダクト | 機能 |
|---|---|
| Cloud Status ダッシュボード |
|
| Google Cloud Observability |
|
| Google Cloud Managed Service for Prometheus |
|
Cloud Status ダッシュボード
クラウド ステータス ダッシュボードには、 Google Cloud サービスの現在の可用性が表示されます。ステータスはページ上で確認でき、サービスに関するニュースがあるたびに更新される RSS フィードも購読できます。
Cloud Monitoring
Cloud Monitoring は、 Google Cloud、AWS、ホストされた稼働時間プローブ、アプリケーションの計測、その他のさまざまなアプリケーション コンポーネントから、指標、イベント、メタデータを収集します。Slack や Pagerduty などのサードパーティ ツールに通知を送信するようにアラートを構成すると、適切なタイミングで管理者にアップデートを提供できます。
Cloud Monitoring では、一般公開されているエンドポイントと VPC 内のエンドポイントの稼働時間チェックを作成できます。たとえば、URL、Compute Engine インスタンス、Cloud Run リビジョン、サードパーティ リソース(Amazon Elastic Compute Cloud(EC2)インスタンスなど)をモニタリングできます。
Google Cloud Managed Service for Prometheus
Google Cloud Managed Service for Prometheus は、Google が管理する Prometheus 指標向けマルチクラウド ソリューションで、複数のプロジェクトに対して使用できます。Prometheus を大規模に手動で管理、運用することなく、Prometheus を使用してワークロードをモニタリングし、アラートを送信できます。
詳細については、Google Cloud Managed Service for Prometheus をご覧ください。
クロスプラットフォームの DR 構成要素
複数のプラットフォームを横断してワークロードを実行する場合、運用上のオーバーヘッドを削減する一つの方法は、使用するすべてのプラットフォームで動作するツールを選ぶことです。このセクションでは、プラットフォームに依存せず、クロスプラットフォームの DR シナリオをサポートできるいくつかのツールとサービスについて説明します。
Infrastructure as code
グラフィカル インターフェースやスクリプトではなく、コードを使用してインフラストラクチャを定義することで、宣言型テンプレート ツールを採用し、プラットフォームをまたいだインフラストラクチャのプロビジョニングと構成を自動化できます。たとえば、Terraform と Infrastructure Manager を使用すると、宣言型インフラストラクチャ構成を実行できます。
構成管理ツール
大規模または複雑な DR インフラストラクチャの場合は、Chef や Ansible のようなプラットフォームに依存しないソフトウェア管理ツールをおすすめします。こうしたツールにより、コンピューティング ワークロードがどこにあっても再現可能な構成を適用できるようになります。
オーケストレーター ツール
コンテナは DR 構成要素と見なすこともできます。コンテナはサービスをパッケージ化し、プラットフォーム間の整合性をもたらすための方法です。
コンテナを使用する場合、通常はオーケストレーターを利用します。Kubernetes は Google Cloud 内のコンテナを(GKE を使用して)管理するだけでなく、複数のプラットフォーム間でコンテナベースのワークロードをオーケストレートする手段を提供します。 Google CloudAWS、Microsoft Azure はすべて、マネージド バージョンの Kubernetes を提供しています。
異なるクラウド プラットフォームで動作している Kubernetes クラスタにトラフィックを分散するには、重み付きレコードをサポートしヘルスチェックを組み込んだ DNS サービスを利用できます。
また、イメージは必ずターゲット環境に pull できる必要があります。つまり、障害の発生時にはイメージ レジストリにアクセスできなければなりません。プラットフォームにも依存しない有効な選択肢は Artifact Registry です。
データ転送
データ転送はクロスプラットフォームの DR シナリオの重要な要素です。クロスプラットフォームの DR シナリオは必ず、DR データ転送シナリオで必要になる内容の現実的なモックアップを使用して、設計、実装、テストしてください。データ転送のシナリオについては、次のセクションで説明します。
Backup and DR サービス
Backup and DR サービスは、クラウド ワークロードのバックアップと DR のためのソリューションです。データの復元と重要なビジネス オペレーションの再開を支援し、複数のGoogle Cloud プロダクト、サードパーティ データベース、データ ストレージ システムをサポートしています。
詳細については、Backup and DR サービスの概要をご覧ください。
DR のパターン
このセクションでは、前述した構成要素に基づく DR アーキテクチャの最も一般的なパターンをいくつか説明します。
Google Cloudとの間でデータを転送する
DR 計画の 1 つの重要な側面は、 Google Cloudとの間でデータをどのくらい速く転送できるかということです。これは DR 計画が、オンプレミスから Google Cloud へ、または別のクラウド プロバイダから Google Cloudへのデータの移動に基づいている場合は極めて重要になります。このセクションでは、優れたスループットを保証できるネットワーキングとGoogle Cloud サービスについて説明します。
オンプレミスまたは別のクラウド環境にあるワークロードの復旧サイトとして Google Cloud を使用する場合は、次の重要事項を考慮する必要があります。
- Google Cloudに接続するにはどうすればよいですか?
- 使用している環境と相互接続プロバイダとの間にどの程度の帯域幅があるか
- プロバイダから Google Cloudに直接提供される帯域幅はどうなっているか
- 他にどのようなデータがそのリンクを使用して転送されるか
Google Cloudへのデータ転送の詳細については、 Google Cloudへの移行: 大規模なデータセットの転送をご覧ください。
イメージ構成とデプロイ速度のバランスをとる
新しいインスタンスをデプロイするためのマシンイメージを構成するときは、構成がデプロイの速度に及ぼす影響を考慮してください。イメージの事前構成量、イメージを維持するためのコスト、そしてデプロイ速度の間にはトレードオフがあります。たとえばマシンイメージの構成が最小限である場合、それを使用するインスタンスは、依存関係をダウンロードしてインストールする必要があるため、起動にかかる時間が長くなります。一方マシンイメージが高度に構成されていれば、それを使用するインスタンスはより早く起動しますが、イメージはより頻繁に更新する必要があります。すべての機能が動作するインスタンスの起動にかかる時間は、RTO に直接関係します。
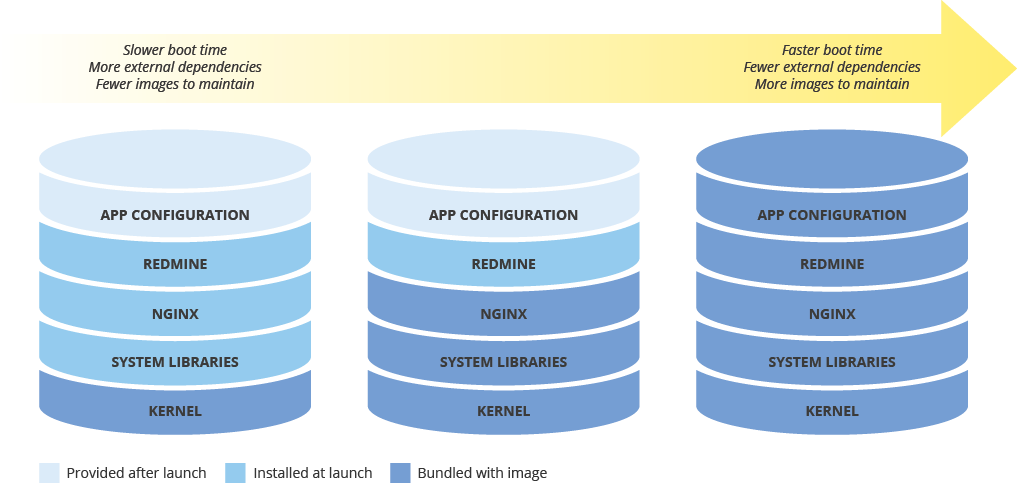
ハイブリッド環境全体でマシンイメージの整合性を維持する
ハイブリッド ソリューション(オンプレミスからクラウドまたはクラウドからクラウド)を実装する場合は、本番環境全体でイメージの整合性を維持する方法を見つける必要があります。
完全に構成されたイメージが必要な場合は、Packer などのソフトウェアの使用を検討してください。このソフトウェアを使えば、複数のプラットフォーム向けに同じマシンイメージを作成できます。ここでは同じスクリプトをプラットフォーム固有の構成ファイルとともに使用できます。Packer の場合は、構成ファイルをバージョン管理に格納して、本番環境にデプロイされたバージョンを追跡できます。
別の方法として、Chef、Puppet、Ansible、Saltstack などの構成管理ツールを利用してより細かくインスタンスを構成すると、必要に応じてベースイメージ、最小限の構成のイメージ、または完全な構成のイメージを作成できます。
また、Amazon AMI、Virtualbox イメージ、RAW ディスク イメージなどの既存のイメージを手動で変換し、Compute Engine にインポートすることもできます。
階層型ストレージの実装
階層型ストレージ パターンは通常、バックアップに利用され、最新のバックアップがより高速なストレージに保存されて、古いバックアップはより低コストの低速ストレージにゆっくりと移行されます。このパターンを適用すると、さまざまなストレージ クラスのバケット間でバックアップを移行できます。通常は、Standard から低コストのストレージ クラス(Nearline や Coldline など)に移行します。
このパターンを実装するには、オブジェクトのライフサイクル管理を使用します。たとえば、一定の期間が経過したオブジェクトのストレージ クラスを Coldline に自動的に変更できます。
次のステップ
- Google Cloud 地域とリージョンについて読む。
この DR シリーズの他の記事を読む:
Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。
寄稿者
作成者:
- Grace Mollison | ソリューション リード
- Marco Ferrari | クラウド ソリューション アーキテクト