データ使用のさまざまなユースケースをサポートするようにデータメッシュを設計することをおすすめします。このドキュメントでは、組織での最も一般的なデータ使用のユースケースについて説明します。また、データ利用者がユースケースに適したデータ プロダクトを決定する際に考慮すべき情報と、データ プロダクトを検出して使用する方法についても説明します。組織はこれらの要素を理解することで、データ利用者をサポートする適切なガイダンスとツールを確実に用意できます。
このドキュメントは、 Google Cloudでデータメッシュを実装する方法を説明するシリーズの一部です。ここでは、データメッシュ内のアーキテクチャと機能、および Google Cloudで最新の分散データメッシュを構築するで説明するコンセプトをお読みになり、理解されていることを前提としています。
このシリーズは、次のパートから構成されています。
- データメッシュ内のアーキテクチャと機能
- データメッシュ用のセルフサービス データ プラットフォームを設計する
- データメッシュでデータ プロダクトを構築する
- データメッシュ内のデータ プロダクトを検出して使用する(このドキュメント)
データ使用レイヤの設計(特に、データドメイン ベースの利用者がデータ プロダクトをどのように使用するか)は、データ使用要件によって異なります。利用者が 1 つのユースケースを想定していることを前提としています。利用者は必要なデータを特定しており、これを中央データ プロダクト カタログの検索で見つけられることを前提としています。そのデータがカタログにないか、望ましい状態にない場合(インターフェースが適切でない場合や SLA が不十分な場合など)、利用者はデータ プロデューサーに連絡する必要があります。
また、利用者は、データメッシュのセンター オブ エクセレンス(COE)に連絡して、そのデータ プロダクトの作成にどのドメインが最も適しているかのアドバイスを求めることもできます。データ利用者は、そのリクエストを行う方法を尋ねることもできます。組織が大きい場合は、データ プロダクト リクエストをセルフサービス方式で行うプロセスが必要です。
データ利用者は、実行するアプリケーションを通じてデータ プロダクトを使用します。必要なインサイトの種類によって、データ使用アプリケーションの設計における選択が促されます。アプリケーションの設計時に、データ利用者はそのアプリケーションでのデータ プロダクトの好ましい使用法も特定します。データ利用者は、データの信頼性に対して持つ必要のある確信を抱きます。その後、データ利用者は、アプリケーションに必要なデータ プロダクト インターフェースと SLA に対する見解を確立できます。
データ使用のユースケース
データ利用者がデータ アプリケーションを作成する場合、ソースは 1 つ以上のデータ プロダクトのほか、場合によってはデータ利用者独自のドメインのデータになります。データメッシュでデータ プロダクトを構築するで説明したように、さまざまな物理的データ リポジトリに基づくデータ プロダクトから分析データ プロダクトを作成できます。
データ使用は同じドメイン内で行われることがありますが、最も一般的な使用パターンは、ドメインに関係なく、アプリケーションのソースとして適切なデータ プロダクトを検索するパターンです。適切なデータ プロダクトが別のドメインに存在する場合、この使用パターンでは、ドメインをまたいだデータのアクセスと使用のための後続のメカニズムを設定する必要があります。使用ドメイン以外のドメインで作成されたデータ プロダクトの使用については、データの使用手順をご覧ください。
アーキテクチャ
次の図は、利用者が承認済みデータセットや API などのさまざまなインターフェースを介してデータ プロダクトを使用するシナリオの例を示しています。
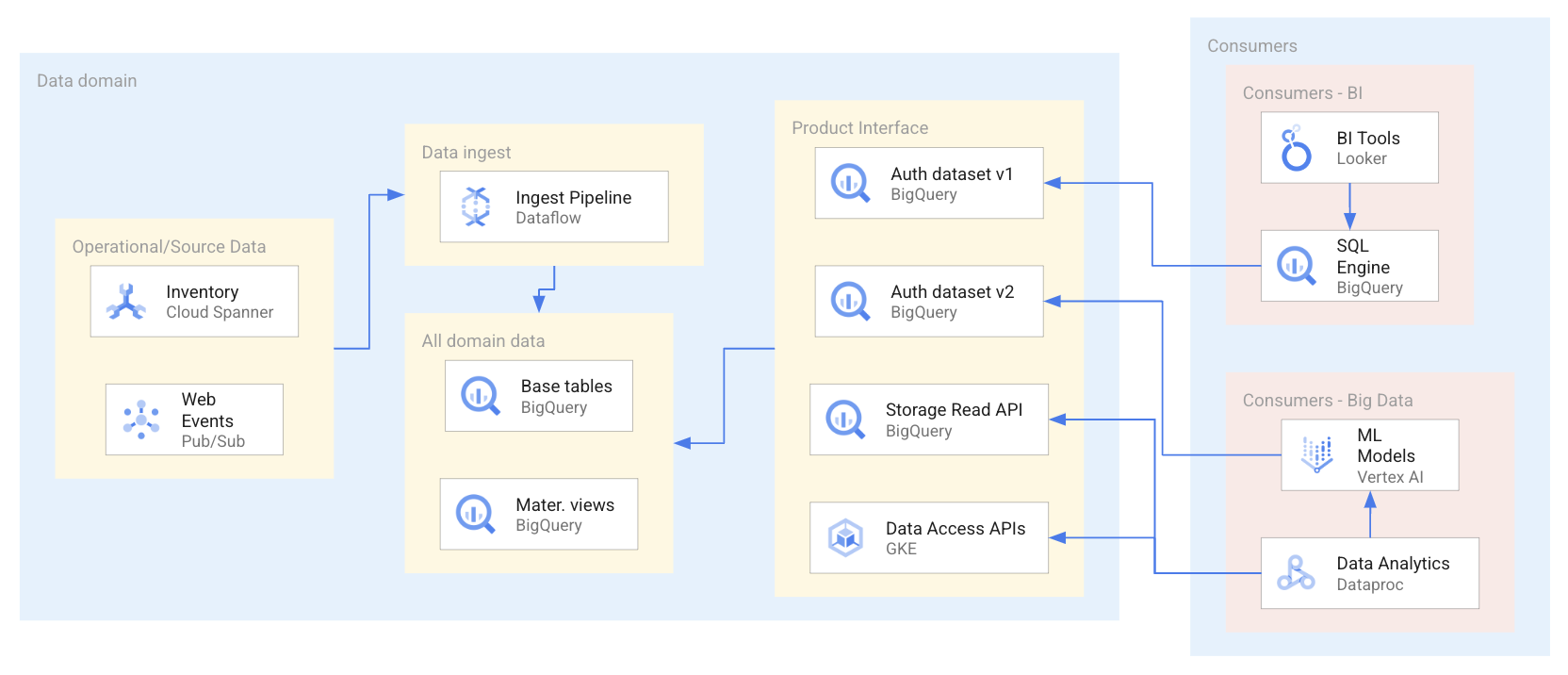
上の図に示すように、データ プロデューサーは 4 つのデータ プロダクト インターフェースを公開しています。BigQuery 承認済みデータセットが 2 つ、BigQuery Storage Read API によって公開される BigQuery データセット、Google Kubernetes Engine でホストされているデータアクセス API です。データ プロダクトを使用する際、データ利用者は、データ プロダクト内のデータリソースに対するクエリ実行や直接アクセスを行うさまざまなアプリケーションを使用します。このシナリオでは、データ利用者は特定のデータアクセス要件に基づいて、2 つの異なる方法のいずれかでデータリソースにアクセスします。1 つ目の方法では、Looker が BigQuery SQL を使用して承認済みデータセットに対してクエリを実行します。2 つ目の方法では、Dataproc が BigQuery API を介してデータセットに直接アクセスし、取り込んだデータを処理して ML モデルをトレーニングします。
データ使用アプリケーションを使用しても、ビジネス インテリジェンス(BI)レポートや BI ダッシュボードで結果が生成されないことがあります。ドメインのデータの使用により、分析プロダクトをさらに拡充する ML モデル、データ分析で使用される ML モデル、不正行為検出などの運用プロセスの一部となる ML モデルが作成されることもあります。
データ プロダクトの典型的な使用ユースケースには、次のようなものがあります。
- BI レポートとデータ分析: この場合、データ アプリケーションは複数のデータ プロダクトのデータを使用するように構築されます。たとえば、顧客管理(CRM)チームのデータ利用者は、販売、顧客、財務など、複数のドメインのデータにアクセスする必要があります。このようなデータ利用者が開発した CRM アプリケーションでは、1 つのドメインで BigQuery の承認済みビューをクエリし、別のドメインの Cloud Storage Read API からデータを抽出する必要がある場合があります。データ利用者にとって、どのインターフェースが好ましいか影響を与える要因は、コンピューティング費用と、データ プロダクトをクエリした後に必要となる追加のデータ処理です。BI やデータ分析のユースケースでは、最もよく使用される可能性があるのは BigQuery 承認済みビューです。
- データ サイエンスのユースケースとモデルのトレーニング: この場合、データ使用チームは他のドメインのデータ プロダクトを使用して、ML モデルなどの独自の分析データ プロダクトを拡充します。Google Cloud Apache Spark 向け Serverless for Spark を使用すると、 Google Cloud はデータの前処理と特徴量エンジニアリングの機能を提供し、ML タスクを実行する前にデータを拡充できるようにします。主な考慮事項は、妥当な費用で十分な量のトレーニング データを利用できることと、トレーニング データが適切なデータであることに対する確信です。費用を抑えるために、好ましい使用インターフェースは直接読み取り API になる可能性が高くなります。データ使用チームが ML モデルをデータ プロダクトとして構築すると、このデータ使用チームも新たにデータ作成チームになります。
- 運用プロセス: データ使用は、データ使用ドメイン内の運用プロセスの一部になります。たとえば、不正行為を扱うチームのデータ利用者は、販売者ドメインの運用データソースからのトランザクション データを使用している可能性があります。変更データ キャプチャなどのデータ統合方法を使用することで、このトランザクション データは準リアルタイムでインターセプトされます。Pub/Sub を使用してこのデータのスキーマを定義し、その情報をイベントとして公開できます。この場合、適切なインターフェースは Pub/Sub トピックとして公開されるデータになります。
データの使用手順
データ プロデューサーは、データ プロダクトを中央のカタログにドキュメント化し、データの使用方法に関するガイダンスを含めます。複数のドメインを持つ組織向けに、このドキュメントのアプローチにより、プロセッサがビジネス ドメインの境界なしで出力を作成する従来の一元的に構築された ELT/ETL パイプラインとは異なるアーキテクチャが作成されます。データメッシュ内のデータ利用者には、データ使用ライフサイクルを構築するために、適切に設計された検出と使用のためのレイヤが必要です。このレイヤには次のものが含まれている必要があります。
ステップ 1: データ プロダクト仕様の宣言型検索および探索を通じたデータ プロダクトの検出: データ利用者は、データ プロデューサーが中央カタログに登録したデータ プロダクトを自由に検索できます。すべてのデータ プロダクトで、データ プロダクト タグはデータアクセスをリクエストする方法と、必要となるデータ プロダクト インターフェースからデータを使用するモードを指定します。データ プロダクト タグのフィールドは、検索アプリケーションで検索できます。データ プロダクト インターフェースはデータ URI を実装します。つまり、利用者に提供するために、データを別の使用ゾーンに移動する必要はありません。リアルタイムのデータが必要ない場合、利用者はデータ プロダクトに対してクエリを実行し、生成された結果でレポートを作成します。
ステップ 2: インタラクティブなデータアクセスとプロトタイピングによるデータ探索: データ利用者は、BigQuery Studio や Jupyter Notebook などのインタラクティブ ツールを使用してデータの解釈とテストを行い、本番環境での使用に必要なクエリを改良します。インタラクティブなクエリにより、データ利用者はデータのより新しい次元を探索し、本番環境シナリオで生成されるインサイトの正確性を改善できます。
ステップ 3: プログラマティックなアクセスとプロダクト構築による、アプリケーションを介したデータ プロダクトの使用。
- BI レポート。バッチおよび準リアルタイムのレポートとダッシュボードは、データ利用者が必要とする分析ユースケースの最も一般的なグループです。意思決定を容易にするために、レポートで複数のデータ プロダクトにまたがるアクセスが必要になる場合があります。たとえば、顧客データ プラットフォームで、スケジュールに従って注文と CRM データ プロダクトの両方をプログラマティックにクエリする必要があります。このようなアプローチにより得られた結果に基づいて、データを使用するビジネス ユーザーに包括的な顧客ビューが提供されます。
- バッチ予測とリアルタイム予測のための AI/ML モデル。データ サイエンティストは、MLOps の一般原則に基づいて、データ プロダクト チームによって提供されるデータ プロダクトを使用する ML モデルを構築して提供します。ML モデルは、不正行為の検出などのトランザクションのユースケースにリアルタイムの推論機能を提供します。同様に、探索的データ分析では、データ利用者がソースデータを拡充できます。たとえば、販売データやマーケティング キャンペーン データの探索的データ分析では、売り上げが最も高くなると予測される顧客セグメント、つまりキャンペーンを実施すべきユーザー層を特定できます。
次のステップ
- データメッシュ アーキテクチャのリファレンス実装を参照する。
- BigQuery の詳細を確認する。
- Vertex AI の詳細を確認する。
- Dataproc のデータ サイエンスについて学習する。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。