This article is part of a series that discusses disaster recovery (DR) in Google Cloud. This part discusses the process for architecting workloads using Google Cloud and building blocks that are resilient to cloud infrastructure outages.
The series consists of these parts:
- Disaster recovery planning guide
- Disaster recovery building blocks
- Disaster recovery scenarios for data
- Disaster recovery scenarios for applications
- Architecting disaster recovery for locality-restricted workloads
- Disaster recovery use cases: locality-restricted data analytic applications
- Architecting disaster recovery for cloud infrastructure outages (this document)
Introduction
As enterprises move workloads on to the public cloud, they need to translate their understanding of building resilient on-premises systems to the hyperscale infrastructure of cloud providers like Google Cloud. This article maps industry standard concepts around disaster recovery such as RTO (Recovery Time Objective) and RPO (Recovery Point Objective) to the Google Cloud infrastructure.
The guidance in this document follows one of Google's key principles for achieving extremely high service availability: plan for failure. While Google Cloud provides extremely reliable service, disasters will strike - natural disasters, fiber cuts, and complex unpredictable infrastructure failures - and these disasters cause outages. Planning for outages enables Google Cloud customers to build applications that perform predictably through these inevitable events, by making use of Google Cloud products with "built-in" DR mechanisms.
Disaster recovery is a broad topic which covers a lot more than just infrastructure failures, such as software bugs or data corruption, and you should have a comprehensive end-to-end plan. However this article focuses on one part of an overall DR plan: how to design applications that are resilient to cloud infrastructure outages. Specifically, this article walks through:
- The Google Cloud infrastructure, how disaster events manifest as Google Cloud outages, and how Google Cloud is architected to minimize the frequency and scope of outages.
- An architecture planning guide that provides a framework for categorizing and designing applications based on the desired reliability outcomes.
- A detailed list of select Google Cloud products that offer built-in DR capabilities which you may want to use in your application.
For further details on general DR planning and using Google Cloud as a component in your on-premises DR strategy, see the disaster recovery planning guide. Also, while High Availability is a closely related concept to disaster recovery, it is not covered in this article. For further details on architecting for high availability see the Well-Architected Framework.
A note on terminology: this article refers to availability when discussing the ability for a product to be meaningfully accessed and used over time, while reliability refers to a set of attributes including availability but also things like durability and correctness.
How Google Cloud is designed for resilience
Google data centers
Traditional data centers rely on maximizing availability of individual components. In the cloud, scale allows operators like Google to spread services across many components using virtualization technologies and thus exceed traditional component reliability. This means you can shift your reliability architecture mindset away from the myriad details you once worried about on-premises. Rather than worry about the various failure modes of components -- such as cooling and power delivery -- you can plan around Google Cloud products and their stated reliability metrics. These metrics reflect the aggregate outage risk of the entire underlying infrastructure. This frees you to focus much more on application design, deployment, and operations rather than infrastructure management.
Google designs its infrastructure to meet aggressive availability targets based on our extensive experience building and running modern data centers. Google is a world leader in data center design. From power to cooling to networks, each data center technology has its own redundancies and mitigations, including FMEA plans. Google's data centers are built in a way that balances these many different risks and presents to customers a consistent expected level of availability for Google Cloud products. Google uses its experience to model the availability of the overall physical and logical system architecture to ensure that the data center design meets expectations. Google's engineers take great lengths operationally to help ensure those expectations are met. Actual measured availability normally exceeds our design targets by a comfortable margin.
By distilling all of these data center risks and mitigations into user-facing products, Google Cloud relieves you from those design and operational responsibilities. Instead, you can focus on the reliability designed into Google Cloud regions and zones.
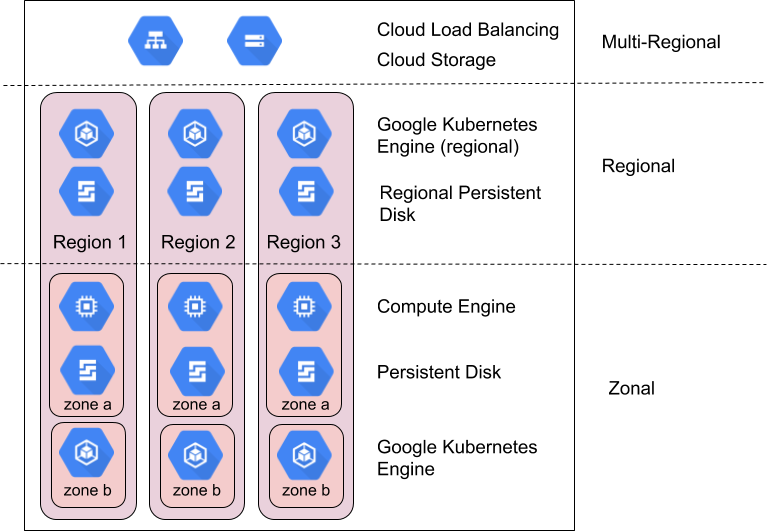
Regions and zones
Regions are independent geographic areas that consist of zones. Zones and regions are logical abstractions of underlying physical resources. For more information about region-specific considerations, see Geography and regions.
Google Cloud products are divided into zonal resources, regional resources, or multi-regional resources.
Zonal resources are hosted within a single zone. A service interruption in that zone can affect all of the resources in that zone. For example, a Compute Engine instance runs in a single, specified zone; if a hardware failure interrupts service in that zone, that Compute Engine instance is unavailable for the duration of the interruption.
Regional resources are redundantly deployed across multiple zones within a region. This gives them higher reliability relative to zonal resources.
Multi-regional resources are distributed within and across regions. In general, multi-regional resources have higher reliability than regional resources. However, at this level products must optimize availability, performance, and resource efficiency. As a result, it is important to understand the tradeoffs made by each multi-regional product you decide to use. These tradeoffs are documented on a product-specific basis later in this document.
How to leverage zones and regions to achieve reliability
Google SREs manage and scale highly reliable, global user products like Gmail and Search through a variety of techniques and technologies that seamlessly leverage computing infrastructure around the world. This includes redirecting traffic away from unavailable locations using global load balancing, running multiple replicas in many locations around the planet, and replicating data across locations. These same capabilities are available to Google Cloud customers through products like Cloud Load Balancing, Google Kubernetes Engine (GKE), and Spanner.
Google Cloud generally designs products to deliver the following levels of availability for zones and regions:
| Resource | Examples | Availability design goal | Implied downtime |
|---|---|---|---|
| Zonal | Compute Engine, Persistent Disk | 99.9% | 8.75 hours / year |
| Regional | Regional Cloud Storage, Replicated Persistent Disk, Regional GKE | 99.99% | 52 minutes / year |
Compare the Google Cloud availability design goals against your acceptable level of downtime to identify the appropriate Google Cloud resources. While traditional designs focus on improving component-level availability to improve the resulting application availability, cloud models focus instead on composition of components to achieve this goal. Many products within Google Cloud use this technique. For example, Spanner offers a multi-region database that composes multiple regions in order to deliver 99.999% availability.
Composition is important because without it, your application availability cannot exceed that of the Google Cloud products you use; in fact, unless your application never fails, it will have lower availability than the underlying Google Cloud products. The remainder of this section shows generally how you can use a composition of zonal and regional products to achieve higher application availability than a single zone or region would provide. The next section gives a practical guide for applying these principles to your applications.
Planning for zone outage scopes
Infrastructure failures usually cause service outages in a single zone. Within a region, zones are designed to minimize the risk of correlated failures with other zones, and a service interruption in one zone would usually not affect service from another zone in the same region. An outage scoped to a zone doesn't necessarily mean that the entire zone is unavailable, it just defines the boundary of the incident. It is possible for a zone outage to have no tangible effect on your particular resources in that zone.
It's a rarer occurrence, but it's also critical to note that multiple zones will eventually still experience a correlated outage at some point within a single region. When two or more zones experience an outage, the regional outage scope strategy below applies.
Regional resources are designed to be resistant to zone outages by delivering service from a composition of multiple zones. If one of the zones backing a regional resource is interrupted, the resource automatically makes itself available from another zone. Carefully check the product capability description in the appendix for further details.
Google Cloud only offers a few zonal resources, namely Compute Engine virtual machines (VMs) and Persistent Disk. If you plan to use zonal resources, you'll need to perform your own resource composition by designing, building, and testing failover and recovery between zonal resources located in multiple zones. Some strategies include:
- Routing your traffic quickly to virtual machines in another zone using Cloud Load Balancing when a health check determines that a zone is experiencing issues.
- Use Compute Engine instance templates and/or managed instance groups to run and scale identical VM instances in multiple zones.
- Use a regional Persistent Disk to synchronously replicate data to another zone in a region. See High availability options using regional PDs for more details.
Planning for regional outage scopes
A regional outage is a service interruption affecting more than one zone in a single region. These are larger scale, less frequent outages and can be caused by natural disasters or large scale infrastructure failures.
For a regional product that is designed to provide 99.99% availability, an outage can still translate to nearly an hour of downtime for a particular product every year. Therefore, your critical applications may need to have a multi-region DR plan in place if this outage duration is unacceptable.
Multi-regional resources are designed to be resistant to region outages by delivering service from multiple regions. As described above, multi-region products trade off between latency, consistency, and cost. The most common trade off is between synchronous and asynchronous data replication. Asynchronous replication offers lower latency at the cost of risk of data loss during an outage. So, it is important to check the product capability description in the appendix for further details.
If you want to use regional resources and remain resilient to regional outages, then you must perform your own resource composition by designing, building, and testing their failover and recovery between regional resources located in multiple regions. In addition to the zonal strategies above, which you can apply across regions as well, consider:
- Regional resources should replicate data to a secondary region, to a multi-regional storage option such as Cloud Storage, or a hybrid cloud option such as GKE Enterprise.
- After you have a regional outage mitigation in place, test it regularly. There are few things worse than thinking you're resistant to a single-region outage, only to find that this isn't the case when it happens for real.
Google Cloud resilience and availability approach
Google Cloud regularly beats its availability design targets, but you should not assume that this strong past performance is the minimum availability you can design for. Instead, you should select Google Cloud dependencies whose designed-for targets exceed your application's intended reliability, such that your application downtime plus the Google Cloud downtime delivers the outcome you are seeking.
A well-designed system can answer the question: "What happens when a zone or region has a 1, 5, 10, or 30 minute outage?" This should be considered at many layers, including:
- What will my customers experience during an outage?
- How will I detect that an outage is happening?
- What happens to my application during an outage?
- What happens to my data during an outage?
- What happens to my other applications due to an outage (due to cross-dependencies)?
- What do I need to do in order to recover after an outage is resolved? Who does it?
- Who do I need to notify about an outage, within what time period?
Step-by-step guide to designing disaster recovery for applications in Google Cloud
The previous sections covered how Google builds cloud infrastructure, and some approaches for dealing with zonal and regional outages.
This section helps you develop a framework for applying the principle of composition to your applications based on your desired reliability outcomes.
Customer applications in Google Cloud that target disaster recovery objectives such as RTO and RPO must be architected so that business-critical operations, subject to RTO/RPO, only have dependencies on data plane components that are responsible for continuous processing of operations for the service. In other words, such customer business-critical operations must not depend on management plane operations, which manage configuration state and push configuration to the control plane and the data plane.
For example, Google Cloud customers who intend to achieve RTO for business-critical operations should not depend on a VM-creation API or on the update of an IAM permission.
Step 1: Gather existing requirements
The first step is to define the availability requirements for your applications. Most companies already have some level of design guidance in this space, which may be internally developed or derived from regulations or other legal requirements. This design guidance is normally codified in two key metrics: Recovery Time Objective (RTO) and Recovery Point Objective (RPO). In business terms, RTO translates as "How long after a disaster before I'm up and running." RPO translates as "How much data can I afford to lose in the event of a disaster."

Historically, enterprises have defined RTO and RPO requirements for a wide range of disaster events, from component failures to earthquakes. This made sense in the on-premises world where planners had to map the RTO/RPO requirements through the entire software and hardware stack. In the cloud, you no longer need to define your requirements with such detail because the provider takes care of that. Instead, you can define your RTO and RPO requirements in terms of the scope of loss (entire zones or regions) without being specific about the underlying reasons. For Google Cloud this simplifies your requirement gathering to 3 scenarios: a zonal outage, a regional outage, or the extremely unlikely outage of multiple regions.
Recognizing that not every application has equal criticality, most customers categorize their applications into criticality tiers against which a specific RTO/RPO requirement can be applied. When taken together, RTO/RPO and application criticality streamline the process of architecting a given application by answering:
- Does the application need to run in multiple zones in the same region, or in multiple zones in multiple regions?
- On which Google Cloud products can the application depend?
This is an example of the output of the requirements gathering exercise:
RTO and RPO by Application Criticality for Example Organization Co:
| Application criticality | % of Apps | Example apps | Zone outage | Region outage |
|---|---|---|---|---|
| Tier 1
(most important) |
5% | Typically global or external customer-facing applications, such as real-time payments and eCommerce storefronts. | RTO Zero
RPO Zero |
RTO Zero
RPO Zero |
| Tier 2 | 35% | Typically regional applications or important internal applications, such as CRM or ERP. | RTO 15mins
RPO 15mins |
RTO 1hr
RPO 1hr |
| Tier 3
(least important) |
60% | Typically team or departmental applications, such as back office, leave booking, internal travel, accounting, and HR. | RTO 1hr
RPO 1hr |
RTO 12hrs
RPO 12hrs |
Step 2: Capability mapping to available products
The second step is to understand the resilience capabilities of Google Cloud products that your applications will be using. Most companies review the relevant product information and then add guidance on how to modify their architectures to accommodate any gaps between the product capabilities and their resilience requirements. This section covers some common areas and recommendations around data and application limitations in this space.
As mentioned previously, Google's DR-enabled products broadly cater for two types of outage scopes: regional and zonal. Partial outages should be planned for the same way as a full outage when it comes to DR. This gives an initial high level matrix of which products are suitable for each scenario by default:
Google Cloud Product General Capabilities
(see Appendix for specific product capabilities)
| All Google Cloud products | Regional Google Cloud products with automatic replication across zones | Multi-regional or global Google Cloud products with automatic replication across regions | |
|---|---|---|---|
| Failure of a component within a zone | Covered* | Covered | Covered |
| Zone outage | Not covered | Covered | Covered |
| Region outage | Not covered | Not covered | Covered |
* All Google Cloud products are resilient to component failure, except in specific cases noted in product documentation. These are typically scenarios where the product offers direct access or static mapping to a piece of speciality hardware such as memory or Solid State Disks (SSD).
How RPO limits product choices
In most cloud deployments, data integrity is the most architecturally significant aspect to be considered for a service. At least some applications have an RPO requirement of zero, meaning there should be no data loss in the event of an outage. This typically requires data to be synchronously replicated to another zone or region. Synchronous replication has cost and latency tradeoffs, so while many Google Cloud products provide synchronous replication across zones, only a few provide it across regions. This cost and complexity tradeoff means that it's not unusual for different types of data within an application to have different RPO values.
For data with an RPO greater than zero, applications can take advantage of asynchronous replication. Asynchronous replication is acceptable when lost data can either be recreated easily, or can be recovered from a golden source of data if needed. It can also be a reasonable choice when a small amount of data loss is an acceptable tradeoff in the context of zonal and regional expected outage durations. It is also relevant that during a transient outage, data written to the affected location but not yet replicated to another location generally becomes available after the outage is resolved. This means that the risk of permanent data loss is lower than the risk of losing data access during an outage.
Key actions: Establish whether you definitely need RPO zero, and if so whether you can do this for a subset of your data - this dramatically increases the range of DR-enabled services available to you. In Google Cloud, achieving RPO zero means using predominantly regional products for your application, which by default are resilient to zone-scale, but not region-scale, outages.
How RTO limits product choices
One of the primary benefits of cloud computing is the ability to deploy infrastructure on demand; however, this isn't the same as instantaneous deployment. The RTO value for your application needs to accommodate the combined RTO of the Google Cloud products your application utilizes and any actions your engineers or SREs must take to restart your VMs or application components. An RTO measured in minutes means designing an application which recovers automatically from a disaster without human intervention, or with minimal steps such as pushing a button to failover. The cost and complexity of this kind of system historically has been very high, but Google Cloud products like load balancers and instance groups make this design both much more affordable and simpler. Therefore, you should consider automated failover and recovery for most applications. Be aware that designing a system for this kind of hot failover across regions is both complicated and expensive; only a very small fraction of critical services warrant this capability.
Most applications will have an RTO of between an hour and a day, which allows for a warm failover in a disaster scenario, with some components of the application running all the time in a standby mode--such as databases--while others are scaled out in the event of an actual disaster, such as web servers. For these applications, you should strongly consider automation for the scale-out events. Services with an RTO over a day are the lowest criticality and can often be recovered from a backup or recreated from scratch.
Key actions: Establish whether you definitely need an RTO of (near) zero for regional failover, and if so whether you can do this for a subset of your services. This changes the cost of running and maintaining your service.
Step 3: Develop your own reference architectures and guides
The final recommended step is building your own company-specific architecture patterns to help your teams standardize their approach to disaster recovery. Most Google Cloud customers produce a guide for their development teams that matches their individual business resilience expectations to the two major categories of outage scenarios on Google Cloud. This allows teams to easily categorize which DR-enabled products are suitable for each criticality level.
Create product guidelines
Looking again at the example RTO/RPO table from above, you have a hypothetical guide that lists which products would be allowed by default for each criticality tier. Note that where certain products have been identified as not suitable by default, you can always add your own replication and failover mechanisms to enable cross-zone or cross-region synchronization, but this exercise is beyond the scope of this article. The tables also link to more information about each product to help you understand their capabilities with respect to managing zone or region outages.
Sample Architecture Patterns for Example Organization Co -- Zone Outage Resilience
| Google Cloud Product | Does product meet zonal outage requirements for Example Organization (with appropriate product configuration) | ||
|---|---|---|---|
| Tier 1 | Tier 2 | Tier 3 | |
| Compute Engine | No | No | No |
| Dataflow | No | No | No |
| BigQuery | No | No | Yes |
| GKE | Yes | Yes | Yes |
| Cloud Storage | Yes | Yes | Yes |
| Cloud SQL | No | Yes | Yes |
| Spanner | Yes | Yes | Yes |
| Cloud Load Balancing | Yes | Yes | Yes |
This table is an example only based on hypothetical tiers shown above.
Sample Architecture Patterns for Example Organization Co -- Region Outage Resilience
| Google Cloud Product | Does product meet region outage requirements for Example Organization (with appropriate product configuration) | ||
|---|---|---|---|
| Tier 1 | Tier 2 | Tier 3 | |
| Compute Engine | Yes | Yes | Yes |
| Dataflow | No | No | No |
| BigQuery | No | No | Yes |
| GKE | Yes | Yes | Yes |
| Cloud Storage | No | No | No |
| Cloud SQL | No | Yes | Yes |
| Spanner | Yes | Yes | Yes |
| Cloud Load Balancing | Yes | Yes | Yes |
This table is an example only based on hypothetical tiers shown above.
To show how these products would be used, the following sections walk through some reference architectures for each of the hypothetical application criticality levels. These are deliberately high level descriptions to illustrate the key architectural decisions, and aren't representative of a complete solution design.
Example tier 3 architecture
| Application criticality | Zone outage | Region outage |
|---|---|---|
| Tier 3 (least important) |
RTO 12 hours RPO 24 hours |
RTO 28 days RPO 24 hours |
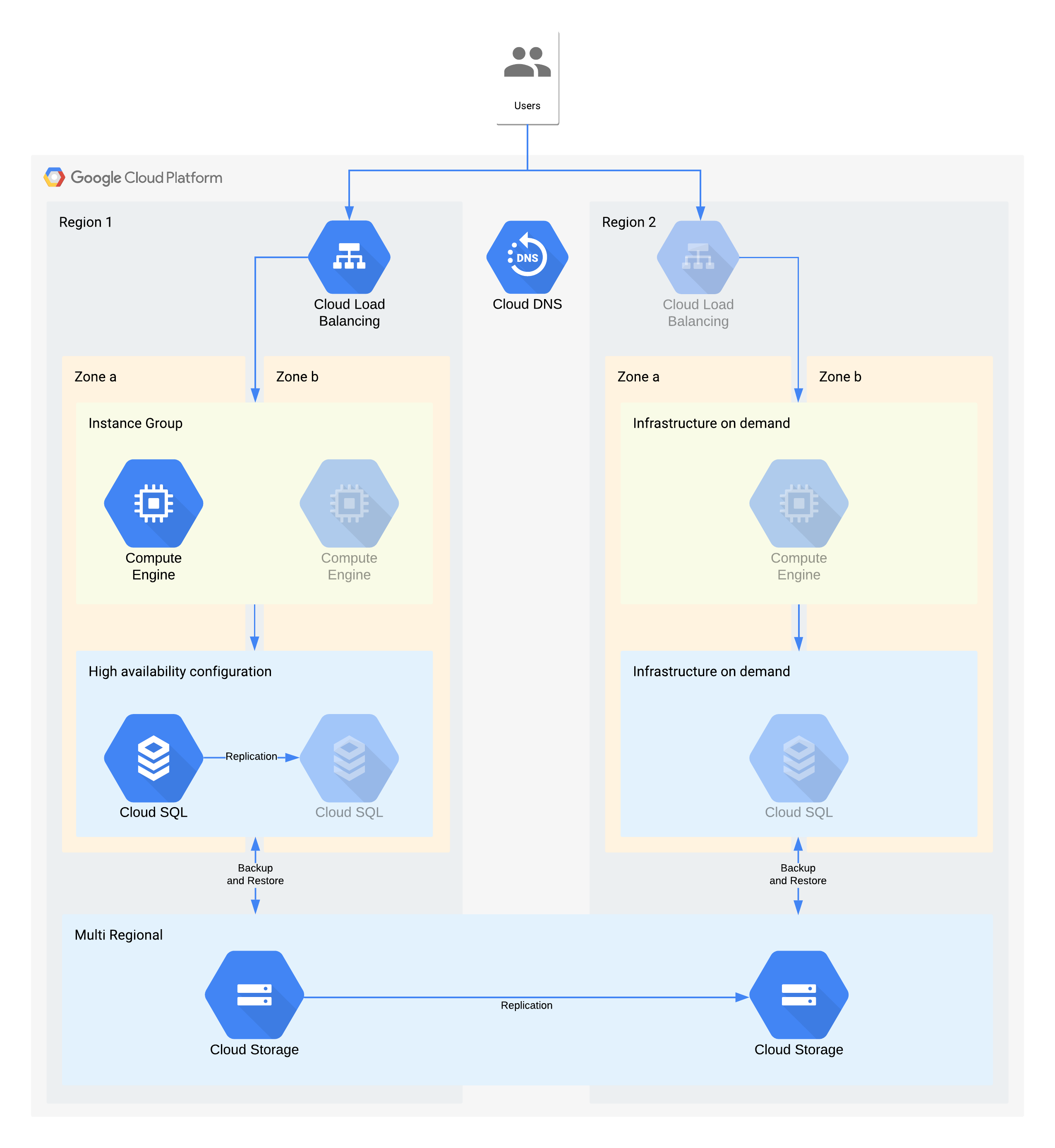
(Greyed-out icons indicate infrastructure to be enabled for recovery)
This architecture describes a traditional client/server application: internal users connect to an application running on a compute instance which is backed by a database for persistent storage.
It's important to note that this architecture supports better RTO and RPO values than required. However, you should also consider eliminating additional manual steps when they could prove costly or unreliable. For example, recovering a database from a nightly backup could support the RPO of 24 hours, but this would usually need a skilled individual such as a database administrator who might be unavailable, especially if multiple services were impacted at the same time. With Google Cloud's on demand infrastructure you are able to build this capability without making a major cost tradeoff, and so this architecture uses Cloud SQL HA rather than a manual backup/restore for zonal outages.
Key architectural decisions for zone outage - RTO of 12hrs and RPO of 24hrs:
- An internal load balancer is used to provide a scalable access point for users, which allows for automatic failover to another zone. Even though the RTO is 12 hours, manual changes to IP addresses or even DNS updates can take longer than expected.
- A regional managed instance group is configured with multiple zones but minimal resources. This optimizes for cost but still allows for virtual machines to be quickly scaled out in the backup zone.
- A high availability Cloud SQL configuration provides for automatic failover to another zone. Databases are significantly harder to recreate and restore compared to the Compute Engine virtual machines.
Key architectural decisions for region outage - RTO of 28 Days and RPO of 24 hours:
- A load balancer would be constructed in region 2 only in the event of a regional outage. Cloud DNS is used to provide an orchestrated but manual regional failover capability, since the infrastructure in region 2 would only be made available in the event of a region outage.
- A new managed instance group would be constructed only in the event of a region outage. This optimizes for cost and is unlikely to be invoked given the short length of most regional outages. Note that for simplicity the diagram doesn't show the associated tooling needed to redeploy, or the copying of the Compute Engine images needed.
- A new Cloud SQL instance would be recreated and the data restored from a backup. Again the risk of an extended outage to a region is extremely low so this is another cost optimization trade-off.
- Multi-regional Cloud Storage is used to store these backups. This provides automatic zone and regional resilience within the RTO and RPO.
Example tier 2 architecture
| Application criticality | Zone outage | Region outage |
|---|---|---|
| Tier 2 | RTO 4 hours RPO zero |
RTO 24 hours RPO 4 hours |
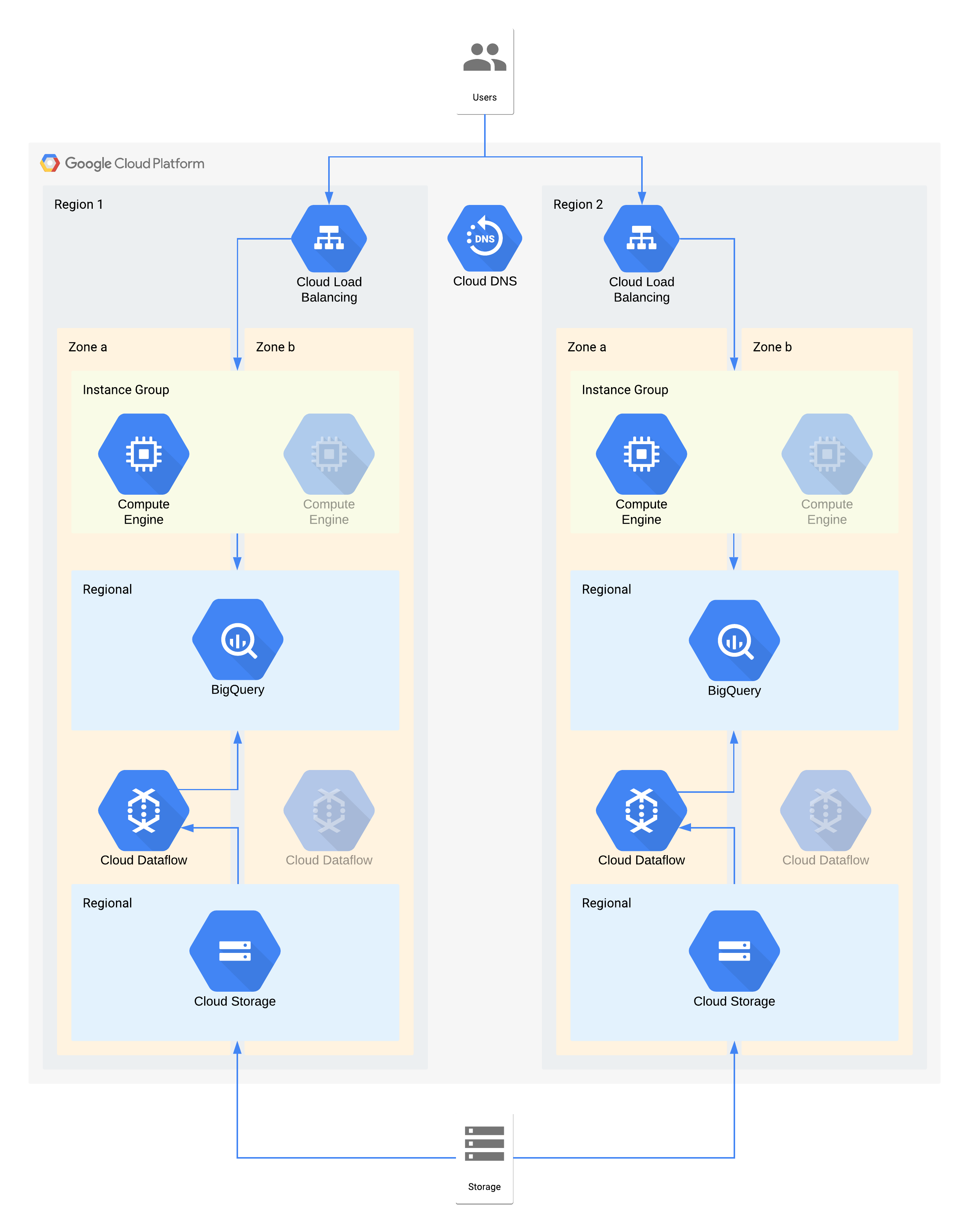
This architecture describes a data warehouse with internal users connecting to a compute instance visualization layer, and a data ingest and transformation layer which populates the backend data warehouse.
Some individual components of this architecture do not directly support the RPO required for their tier. However, because of how they are used together, the overall service does meet the RPO. In this case, because Dataflow is a zonal product, follow the recommendations for high availability design. to help prevent data loss during an outage. However, the Cloud Storage layer is the golden source of this data and supports an RPO of zero. As a result, you can re-ingest any lost data into BigQuery by using zone b in the event of an outage in zone a.
Key architectural decisions for zone outage - RTO of 4hrs and RPO of zero:
- A load balancer is used to provide a scalable access point for users, which allows for automatic failover to another zone. Even though the RTO is 4 hours, manual changes to IP addresses or even DNS updates can take longer than expected.
- A regional managed instance group for the data visualization compute layer is configured with multiple zones but minimal resources. This optimizes for cost but still allows for virtual machines to be quickly scaled out.
- Regional Cloud Storage is used as a staging layer for the initial ingest of data, providing automatic zone resilience.
- Dataflow is used to extract data from Cloud Storage and transform it before loading it into BigQuery. In the event of a zone outage this is a stateless process that can be restarted in another zone.
- BigQuery provides the data warehouse backend for the data visualization front end. In the event of a zone outage, any data lost would be re-ingested from Cloud Storage.
Key architectural decisions for region outage - RTO of 24hrs and RPO of 4 hours:
- A load balancer in each region is used to provide a scalable access point for users. Cloud DNS is used to provide an orchestrated but manual regional failover capability, since the infrastructure in region 2 would only be made available in the event of a region outage.
- A regional managed instance group for the data visualization compute layer is configured with multiple zones but minimal resources. This isn't accessible until the load balancer is reconfigured but doesn't require manual intervention otherwise.
- Regional Cloud Storage is used as a staging layer for the initial ingest of data. This is being loaded at the same time into both regions to meet the RPO requirements.
- Dataflow is used to extract data from Cloud Storage and transform it before loading it into BigQuery. In the event of a region outage this would populate BigQuery with the latest data from Cloud Storage.
- BigQuery provides the data warehouse backend. Under normal operations this would be intermittently refreshed. In the event of a region outage the latest data would be re-ingested via Dataflow from Cloud Storage.
Example tier 1 architecture
| Application criticality | Zone outage | Region outage |
|---|---|---|
| Tier 1 (most important) |
RTO zero RPO zero |
RTO 4 hours RPO 1 hour |
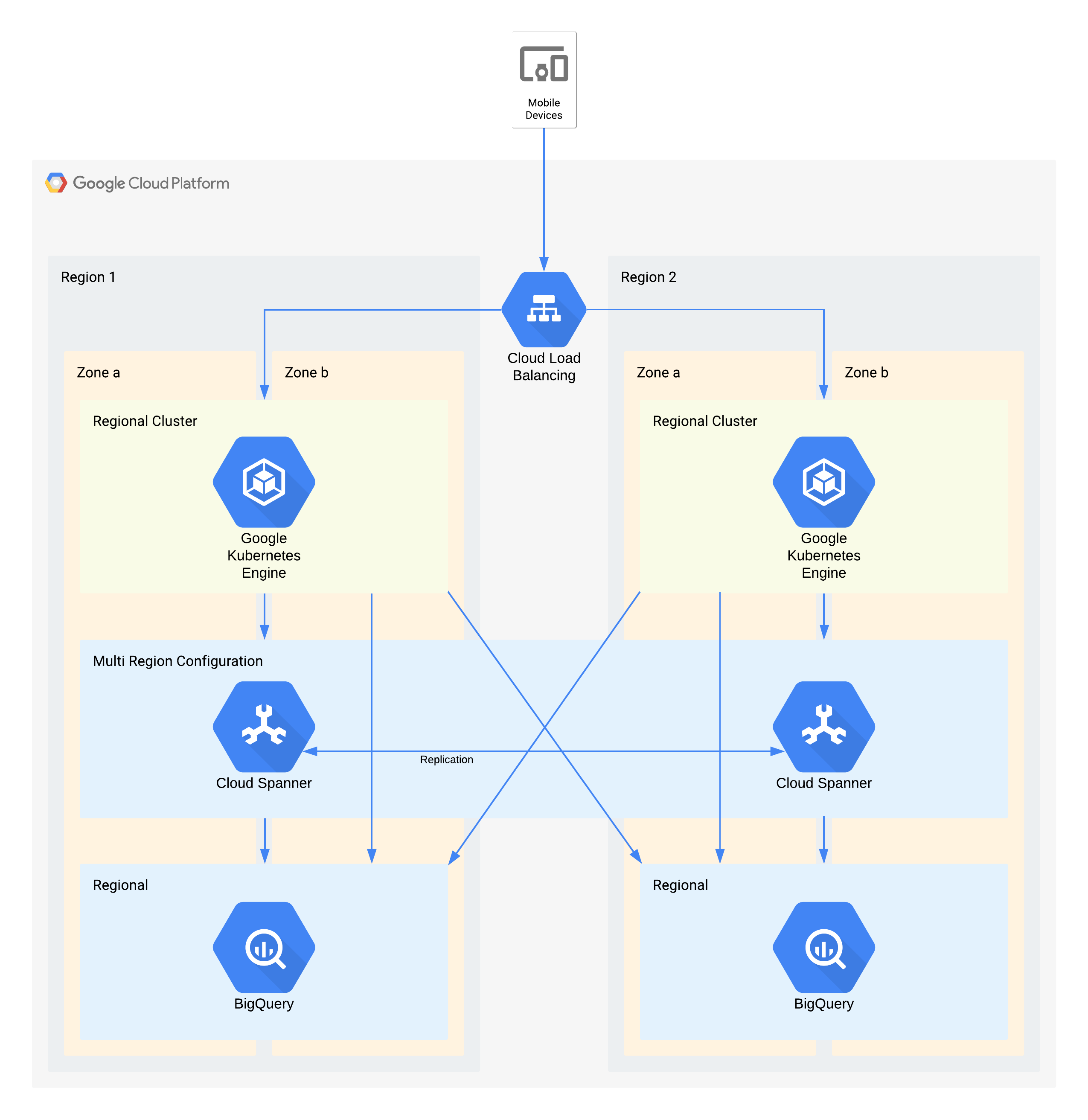
This architecture describes a mobile app backend infrastructure with external users connecting to a set of microservices running in GKE. Spanner provides the backend data storage layer for real time data, and historical data is streamed to a BigQuery data lake in each region.
Again, some individual components of this architecture do not directly support the RPO required for their tier, but because of how they are used together the overall service does. In this case BigQuery is being used for analytic queries. Each region is fed simultaneously from Spanner.
Key architectural decisions for zone outage - RTO of zero and RPO of zero:
- A load balancer is used to provide a scalable access point for users, which allows for automatic failover to another zone.
- A regional GKE cluster is used for the application layer which is configured with multiple zones. This accomplishes the RTO of zero within each region.
- Multi-region Spanner is used as a data persistence layer, providing automatic zone data resilience and transaction consistency.
- BigQuery provides the analytics capability for the application. Each region is independently fed data from Spanner, and independently accessed by the application.
Key architectural decisions for region outage - RTO of 4 hrs and RPO of 1 hr:
- A load balancer is used to provide a scalable access point for users, which allows for automatic failover to another region.
- A regional GKE cluster is used for the application layer which is configured with multiple zones. In the event of a region outage, the cluster in the alternate region automatically scales to take on the additional processing load.
- Multi-region Spanner is used as a data persistence layer, providing automatic regional data resilience and transaction consistency. This is the key component in achieving the cross region RPO of 1 hour.
- BigQuery provides the analytics capability for the application. Each region is independently fed data from Spanner, and independently accessed by the application. This architecture compensates for the BigQuery component allowing it to match the overall application requirements.
Appendix: Product reference
This section describes the architecture and DR capabilities of Google Cloud products that are most commonly used in customer applications and that can be easily leveraged to achieve your DR requirements.
Common themes
Many Google Cloud products offer regional or multi-regional configurations. Regional products are resilient to zone outages, and multi-region and global products are resilient to region outages. In general, this means that during an outage, your application experiences minimal disruption. Google achieves these outcomes through a few common architectural approaches, which mirror the architectural guidance above.
Redundant deployment: The application backends and data storage are deployed across multiple zones within a region and multiple regions within a multi-region location. For more information about region-specific considerations, see Geography and regions.
Data replication: Products use either synchronous or asynchronous replication across the redundant locations.
Synchronous replication means that when your application makes an API call to create or modify data stored by the product, it receives a successful response only once the product has written the data to multiple locations. Synchronous replication ensures that you do not lose access to any of your data during a Google Cloud infrastructure outage because all of your data is available in one of the available backend locations.
Although this technique provides maximum data protection, it can have tradeoffs in terms of latency and performance. Multi-region products using synchronous replication experience this tradeoff most significantly -- typically on the order of 10s or 100s of milliseconds of added latency.
Asynchronous replication means that when your application makes an API call to create or modify data stored by the product, it receives a successful response once the product has written the data to a single location. Subsequent to your write request, the product replicates your data to additional locations.
This technique provides lower latency and higher throughput at the API than synchronous replication, but at the expense of data protection. If the location in which you have written data suffers an outage before replication is complete, you lose access to that data until the location outage is resolved.
Handling outages with load balancing: Google Cloud uses software load balancing to route requests to the appropriate application backends. Compared to other approaches like DNS load balancing, this approach reduces the system response time to an outage. When a Google Cloud location outage occurs, the load balancer quickly detects that the backend deployed in that location has become "unhealthy" and directs all requests to a backend in an alternate location. This enables the product to continue serving your application's requests during a location outage. When the location outage is resolved, the load balancer detects the availability of the product backends in that location, and resumes sending traffic there.
Access Context Manager
Access Context Manager lets enterprises configure access levels that map to a policy that's defined on request attributes. Policies are mirrored regionally.
In the case of a zonal outage, requests to unavailable zones are automatically and transparently served from other available zones in the region.
In the case of regional outage, policy calculations from the affected region are unavailable until the region becomes available again.
Access Transparency
Access Transparency lets Google Cloud organization administrators define fine-grained, attribute-based access control for projects and resources in Google Cloud. Occasionally, Google must access customer data for administrative purposes. When we access customer data, Access Transparency provides access logs to affected Google Cloud customers. These Access Transparency logs help ensure Google's commitment to data security and transparency in data handling.
Access Transparency is resilient against zonal and regional outages. If a zonal or regional outage happens, Access Transparency continues to process administrative access logs in another zone or region.
AlloyDB for PostgreSQL
AlloyDB for PostgreSQL is a fully managed, PostgreSQL-compatible database service. AlloyDB for PostgreSQL offers high availability in a region through its primary instance's redundant nodes that are located in two different zones of the region. The primary instance maintains regional availability by triggering an automatic failover to the standby zone if the active zone encounters an issue. Regional storage guarantees data durability in the event of a single-zone loss.
As a further method of disaster recovery, AlloyDB for PostgreSQL uses cross-region replication to provide disaster recovery capabilities by asynchronously replicating your primary cluster's data into secondary clusters that are located in separate Google Cloud regions.
Zonal outage: During normal operation, only one of the two nodes of a high-availability primary instance is active, and it serves all data writes. This active node stores the data in the cluster's separate, regional storage layer.
AlloyDB for PostgreSQL automatically detects zone-level failures and triggers a failover to restore database availability. During failover, AlloyDB for PostgreSQL starts the database on the standby node, which is already provisioned in a different zone. New database connections automatically get routed to this zone.
From the perspective of a client application, a zonal outage resembles a temporary interruption of network connectivity. After the failover completes, a client can reconnect to the instance at the same address, using the same credentials, with no loss of data.
Regional Outage: Cross-region replication uses asynchronous replication, which allows the primary instance to commit transactions before they are committed on replicas. The time difference between when a transaction is committed on the primary instance and when it is committed on the replica is known as replication lag. The time difference between when the primary generates the write-ahead log (WAL) and when the WAL reaches the replica is known as flush lag. Replication lag and flush lag depend on database instance configuration and on the user-generated workload.
In the event of a regional outage, you can promote secondary clusters in a different region to a writeable, standalone primary cluster. This promoted cluster no longer replicates the data from the original primary cluster that it was formerly associated with. Due to flush lag, some data loss might occur because there could be transactions on the original primary that were not propagated to the secondary cluster.
Cross-region replication RPO is affected by both the CPU utilization of the primary cluster, and physical distance between the primary cluster's region and the secondary cluster's region. To optimize RPO, we recommend testing your workload with a configuration that includes a replica to establish a safe transactions per second (TPS) limit, which is the highest sustained TPS that doesn't accumulate flush lag. If your workload exceeds the safe TPS limit, flush lag accumulates, which can affect RPO. To limit network lag, pick region pairs within the same continent.
For more information about monitoring network lag and other AlloyDB for PostgreSQL metrics, see Monitor instances.
Anti Money Laundering AI
Anti Money Laundering AI (AML AI) provides an API to help global financial institutions more effectively and efficiently detect money laundering. Anti Money Laundering AI is a regional offering, meaning customers can choose the region, but not the zones that make up a region. Data and traffic are automatically load balanced across zones within a region. The operations (for example, to create a pipeline or run a prediction) are automatically scaled in the background and are load balanced across zones as necessary.
Zonal outage: AML AI stores data for its resources regionally, replicated in a synchronous manner. When a long-running operation finishes successfully, the resources can be relied on regardless of zonal failures. Processing is also replicated across zones, but this replication aims at load balancing and not high availability, so a zonal failure during an operation can result in an operation failure. If that happens, retrying the operation can address the issue. During a zonal outage, processing times might be affected.
Regional outage: Customers choose the Google Cloud region they want to create their AML AI resources in. Data is never replicated across regions. Customer traffic is never be routed to a different region by AML AI. In the case of a regional failure, AML AI will become available again as soon as the outage is resolved.
API keys
API keys provides a scalable API key resource management for a project. API keys is a global service, meaning that keys are visible and accessible from any Google Cloud location. Its data and metadata are stored redundantly across multiple zones and regions.
API keys is resilient to both zonal and regional outages. In the case of zonal outage or regional outage, API keys continues to serve requests from another zone in the same or different region.
For more information about API keys, see API keys API overview.
Apigee
Apigee provides a secure, scalable, and reliable platform for developing and managing APIs. Apigee offers both single-region and multi-region deployments.
Zonal outage: Customer runtime data is replicated across multiple availability zones. Therefore, a single-zone outage does not impact Apigee.
Regional Outage: For single-region Apigee instances, if a region goes down, Apigee instances are unavailable in that region and can't be restored to different regions. For multi-region Apigee instances, the data is replicated across all of the regions asynchronously. Therefore, failure of one region doesn't reduce traffic entirely. However, you might not be able to access uncommitted data in the failed region. You can divert the traffic away from unhealthy regions. To achieve automatic traffic failover, you can configure network routing using managed instance groups (MIGs).
AutoML Translation
AutoML Translation is a machine translation service that allows you import your own data (sentence pairs) to train custom models for your domain-specific needs.
Zonal outage: AutoML Translation has active compute servers in multiple zones and regions. It also supports synchronous data replication across zones within regions. These features help AutoML Translation achieve instantaneous failover without any data loss for zonal failures, and without requiring any customer input or adjustments.
Regional outage: In the case of a regional failure, AutoML Translation is not available.
AutoML Vision
AutoML Vision is part of Vertex AI. It offers a unified framework to create datasets, import data, train models, and serve models for online prediction and batch prediction.
AutoML Vision is a regional offering. Customers can choose which region they want to launch a job from, but they can't choose the specific zones within that region. The service automatically load-balances workloads across different zones within the region.
Zonal outage: AutoML Vision stores metadata for the jobs regionally, and writes synchronously across zones within the region. The jobs are launched in a specific zone, as selected by Cloud Load Balancing.
AutoML Vision training jobs: A zonal outage causes any running jobs to fail, and the job status updates to failed. If a job fails, retry it immediately. The new job is routed to an available zone.
AutoML Vision batch prediction jobs: Batch prediction is built on top of Vertex AI Batch prediction. When a zonal outage occurs, the service automatically retries the job by routing it to available zones. If multiple retries fail, the job status updates to failed. Subsequent user requests to run the job are routed to an available zone.
Regional outage: Customers choose the Google Cloud region they want to run their jobs in. Data is never replicated across regions. In a regional failure, AutoML Vision service is unavailable in that region. It becomes available again when the outage resolves. To run their jobs, we recommend that customers use multiple regions. In case a regional outage occurs, direct jobs to a different available region.
Batch
Batch is a fully managed service to queue, schedule, and execute batch jobs on Google Cloud. Batch settings are defined at the region level. Customers must choose a region to submit their batch jobs, not a zone in a region. When a job is submitted, Batch synchronously writes customer data to multiple zones. However, customers can specify the zones where Batch VMs run jobs.
Zonal Failure: When a single zone fails, the tasks running in that zone also fail. If tasks have retry settings, Batch automatically fails over those tasks to other active zones in the same region. The automatic failover is subject to availability of resources in active zones in the same region. Jobs that require zonal resources (like VMs, GPUs, or zonal persistent disks) that are only available in the failed zone are queued until the failed zone recovers or until the queueing timeouts of the jobs are reached. When possible, we recommend that customers let Batch choose zonal resources to run their jobs. Doing so helps ensure that the jobs are resilient to a zonal outage.
Regional Failure: In case of a regional failure, the service control plane is unavailable in the region. The service doesn't replicate data or redirect requests across regions. We recommend that customers use multiple regions to run their jobs and redirect jobs to a different region if a region fails.
Chrome Enterprise Premium threat and data protection
Chrome Enterprise Premium threat and data protection is part of the Chrome Enterprise Premium solution. It extends Chrome with a variety of security features, including malware and phishing protection, Data Loss Prevention (DLP), URL filtering rules and security reporting.
Chrome Enterprise Premium admins can opt-in to storing customer core contents that violate DLP or malware policies into Google Workspace rule log events and/or into Cloud Storage for future investigation. Google Workspace rule log events are powered by a multi-regional Spanner database. Chrome Enterprise Premium can take up to several hours to detect policy violations. During this time, any unprocessed data is subject to data loss from a zonal or regional outage. Once a violation is detected, the contents that violate your policies are written to Google Workspace rule log events and/or to Cloud Storage.
Zonal and Regional outage: Because Chrome Enterprise Premium threat and data protection are multi-zonal and multi-regional, it can survive a complete, unplanned loss of a zone or a region without a loss in availability. It provides this level of reliability by redirecting traffic to its service on other active zones or regions. However, because it can take Chrome Enterprise Premium threat and data protection several hours to detect DLP and malware violations, any unprocessed data in a specific zone or region is subject to loss from a zonal or regional outage.
BigQuery
BigQuery is a serverless, highly scalable, and cost-effective cloud data warehouse designed for business agility. BigQuery supports the following location types for user datasets:
- A region: a specific geographical location, such as Iowa (
us-central1) or Montréal (northamerica-northeast1). - A multi-region: a large geographic area that contains two or more geographic
places, such as the United States (
US) or Europe (EU).
In either case, data is stored redundantly in two zones within a single region within the selected location. Data written to BigQuery is synchronously written to both the primary and secondary zones. This protects against unavailability of a single zone within the region, but not against a regional outage.
Binary Authorization
Binary Authorization is a software supply chain security product for GKE and Cloud Run.
All Binary Authorization policies are replicated across multiple zones within every region. Replication helps Binary Authorization policy read operations recover from failures of other regions. Replication also makes read operations tolerant of zonal failures within each region.
Binary Authorization enforcement operations are resilient against zonal outages, but they are not resilient against regional outages. Enforcement operations run in the same region as the GKE cluster or Cloud Run job that's making the request. Therefore, in the event of a regional outage, there is nothing running to make Binary Authorization enforcement requests.
Certificate Manager
Certificate Manager lets you acquire and manage Transport Layer Security (TLS) certificates for use with different types of Cloud Load Balancing.
In the case of a zonal outage, regional and global Certificate Manager are resilient to zonal failures because jobs and databases are redundant across multiple zones within a region. In the case of a regional outage, global Certificate Manager is resilient to regional failures because jobs and databases are redundant across multiple regions. Regional Certificate Manager is a regional product, so it cannot withstand a regional failure.
Cloud Intrusion Detection System
Cloud Intrusion Detection System (Cloud IDS) is a zonal service that provides zonally-scoped IDS Endpoints, which process the traffic of VMs in one specific zone, and thus isn't tolerant of zonal or regional outages.
Zonal outage: Cloud IDS is tied to VM instances. If a customer plans to mitigate zonal outages by deploying VMs in multiple zones (manually or via Regional Managed Instance Groups), they will need to deploy Cloud IDS Endpoints in those zones as well.
Regional Outage: Cloud IDS is a regional product. It doesn't provide any cross-regional functionality. A regional failure will take down all Cloud IDS functionality in all zones in that region.
Google Security Operations SIEM
Google Security Operations SIEM (which is part of Google Security Operations) is a fully managed service that helps security teams detect, investigate, and respond to threats.
Google Security Operations SIEM has regional and multi-regional offerings.
In regional offerings, data and traffic are automatically load-balanced across zones within the chosen region, and data is stored redundantly across availability zones within the region.
Multi-regions are geo-redundant. That redundancy provides a broader set of protections than regional storage. It also helps to ensure that the service continues to function even if a full region is lost.
The majority of data ingestion paths replicate customer data synchronously across multiple locations. When data is replicated asynchronously, there is a time window (a recovery point objective, or RPO) during which the data isn't yet replicated across several locations. This is the case when ingesting with feeds in multi-regional deployments. After the RPO, the data is available in multiple locations.
Zonal outage:
Regional deployments: Requests are served from any zone within the region. Data is synchronously replicated across multiple zones. In case of a full-zone outage, the remaining zones continue to serve traffic and continue to process the data. Redundant provisioning and automated scaling for Google Security Operations SIEM helps to ensure that the service remains operational in the remaining zones during these load shifts.
Multi-regional deployments: Zonal outages are equivalent to regional outages.
Regional outage:
Regional deployments: Google Security Operations SIEM stores all customer data within a single region and traffic is never routed across regions. In the event of a regional outage, Google Security Operations SIEM is unavailable in the region until the outage is resolved.
Multi-regional deployments (without feeds): Requests are served from any region of the multi-regional deployment. Data is synchronously replicated across multiple regions. In case of a full-region outage, the remaining regions continue to serve traffic and continue to process the data. Redundant provisioning and automated scaling for Google Security Operations SIEM helps ensure that the service remains operational in the remaining regions during these load shifts.
Multi-regional deployments (with feeds): Requests are served from any region of the multi-regional deployment. Data is replicated asynchronously across multiple regions with the provided RPO. In case of a full-region outage, only data stored after the RPO is available in the remaining regions. Data within the RPO window might not be replicated.
Cloud Asset Inventory
Cloud Asset Inventory is a high-performance, resilient, global service that maintains a repository of Google Cloud resource and policy metadata. Cloud Asset Inventory provides search and analysis tools that help you track deployed assets across organizations, folders, and projects.
In the case of a zone outage, Cloud Asset Inventory continues to serve requests from another zone in the same or different region.
In the case of a regional outage, Cloud Asset Inventory continues to serve requests from other regions.
Bigtable
Bigtable is a fully managed high performance NoSQL database service for large analytical and operational workloads.
Bigtable replication overview
Bigtable offers a flexible and fully configurable replication feature, which you can use to increase the availability and durability of your data by copying it to clusters in multiple regions or multiple zones within the same region. Bigtable can also provide automatic failover for your requests when you use replication.
When using multi-zonal or multi-regional configurations with multi-cluster routing, in the case of a zonal or regional outage, Bigtable automatically reroutes traffic and serves requests from the nearest available cluster. Because Bigtable replication is asynchronous and eventually consistent, very recent changes to data in the location of the outage might be unavailable if they have not been replicated yet to other locations.
Performance considerations
When CPU resource demands exceed available node capacity, Bigtable always prioritizes serving incoming requests ahead of replication traffic.
For more information about how to use Bigtable replication with your workload, see Cloud Bigtable replication overview and examples of replication settings.
Bigtable nodes are used both for serving incoming requests and for performing replication of data from other clusters. In addition to maintaining sufficient node counts per cluster, you must also ensure that your applications use proper schema design to avoid hotspots, which can cause excessive or imbalanced CPU usage and increased replication latency.
For more information about designing your application schema to maximize Bigtable performance and efficiency, see Schema design best practices.
Monitoring
Bigtable provides several ways to visually monitor the replication latency of your instances and clusters using the charts for replication available in the Google Cloud console.
You can also programmatically monitor Bigtable replication metrics using the Cloud Monitoring API.
Certificate Authority Service
Certificate Authority Service (CA Service) lets customers simplify, automate, and customize the deployment, management, and security of private certificate authorities (CA) and to resiliently issue certificates at scale.
Zonal outage: CA Service is resilient to zonal failures because its control plane is redundant across multiple zones within a region. If there is a zonal outage, CA Service continues to serve requests from another zone in the same region without interruption. Because data is replicated synchronously there is no data loss or corruption.
Regional outage: CA Service is a regional product, so it cannot withstand a regional failure. If you require resilience to regional failures, create issuing CAs in two different regions. Create the primary issuing CA in the region where you need certificates. Create a fallback CA in a different region. Use the fallback when the primary subordinate CA's region has an outage. If needed, both CAs can chain up to the same root CA.
Cloud Billing
The Cloud Billing API allows developers to manage billing for their Google Cloud projects programmatically. The Cloud Billing API is designed as a global system with updates synchronously written to multiple zones and regions.
Zonal or regional failure: The Cloud Billing API will automatically fail over to another zone or region. Individual requests may fail, but a retry policy should allow subsequent attempts to succeed.
Cloud Build
Cloud Build is a service that executes your builds on Google Cloud.
Cloud Build is composed of regionally isolated instances that synchronously replicate data across zones within the region. We recommend that you use specific Google Cloud regions instead of the global region, and ensure that the resources your build uses (including log buckets, Artifact Registry repositories, and so on) are aligned with the region that your build runs in.
In the case of a zonal outage, control plane operations are unaffected. However, currently executing builds within the failing zone will be delayed or permanently lost. Newly triggered builds will automatically be distributed to the remaining functioning zones.
In the case of a regional failure, the control plane will be offline, and currently executing builds will be delayed or permanently lost. Triggers, worker pools, and build data are never replicated across regions. We recommend that you prepare triggers and worker pools in multiple regions to make mitigation of an outage easier.
Cloud CDN
Cloud CDN distributes and caches content across many locations on Google's network to reduce serving latency for clients. Cached content is served on a best-effort basis -- when a request cannot be served by the Cloud CDN cache, the request is forwarded to origin servers, such as backend VMs or Cloud Storage buckets, where the original content is stored.
When a zone or a region fails, caches in the affected locations are unavailable. Inbound requests are routed to available Google edge locations and caches. If these alternate caches cannot serve the request they will forward the request to an available origin server. Provided that server can serve the request with up-to-date data, there will be no loss of content. An increased rate of cache misses will cause the origin servers to experience higher than normal traffic volumes as the caches are filled. Subsequent requests are be served from the caches unaffected by the zone or region outage.
For more information about Cloud CDN and cache behavior, see the Cloud CDN documentation.
Cloud Composer
Cloud Composer is a managed workflow orchestration service that lets you create, schedule, monitor, and manage workflows that span across clouds and on-premises data centers. Cloud Composer environments are built on the Apache Airflow open source project.
Cloud Composer API availability isn't affected by zonal unavailability. During a zonal outage, you retain access to the Cloud Composer API, including the ability to create new Cloud Composer environments.
A Cloud Composer environment has a GKE cluster as a part of its architecture. During a zonal outage, workflows on the cluster might be disrupted:
- In Cloud Composer 1, the environment's cluster is a zonal resource, thus a zonal outage might make the cluster unavailable. Workflows that are executing at the time of the outage might be stopped before completion.
- In Cloud Composer 2, the environment's cluster is a regional resource. However, workflows that are executed on nodes in the zones that are affected by a zonal outage might be stopped before completion.
In both versions of Cloud Composer, a zonal outage might cause partially executed workflows to stop executing, including any external actions that the workflow was configured by you to accomplish. Depending on the workflow, this can cause inconsistencies externally, such as if the workflow stops in the middle of a multi-step execution to modify external data stores. Therefore, you should consider the recovery process when you design your Airflow workflow, including how to detect partially unexecuted workflow states and repair any partial data changes.
In Cloud Composer 1, during a zone outage, you can choose to start a new Cloud Composer environment in another zone. Because Airflow keeps the state of your workflows in its metadata database, transferring this information to a new Cloud Composer environment can take additional steps and preparation.
In Cloud Composer 2, you can address zonal outages by setting up disaster recovery with environment snapshots in advance. During a zone outage, you can switch to another environment by transferring the state of your workflows with an environment snapshot. Only Cloud Composer 2 supports disaster recovery with environment snapshots.
Cloud Data Fusion
Cloud Data Fusion is a fully managed enterprise data integration service for quickly building and managing data pipelines. It provides three editions.
Zonal outages impact Developer edition instances.
Regional outages impact Basic and Enterprise edition instances.
To control access to resources, you might design and run pipelines in separate environments. This separation lets you design a pipeline once, and then run it in multiple environments. You can recover pipelines in both environments. For more information, see Back up and restore instance data.
The following advice applies to both regional and zonal outages.
Outages in the pipeline design environment
In the design environment, save pipeline drafts in case of an outage. Depending on specific RTO and RPO requirements, you can use the saved drafts to restore the pipeline in a different Cloud Data Fusion instance during an outage.
Outages in the pipeline execution environment
In the execution environment, you start the pipeline internally with Cloud Data Fusion triggers or schedules, or externally with orchestration tools, such as Cloud Composer. To be able to recover runtime configurations of pipelines, back up the pipelines and configurations, such as plugins and schedules. In an outage, you can use the backup to replicate an instance in an unaffected region or zone.
Another way to prepare for outages is to have multiple instances across the regions with the same configuration and pipeline set. If you use external orchestration, running pipelines can be load balanced automatically between instances. Take special care to ensure that there are no resources (such as data sources or orchestration tools) tied to a single region and used by all instances, as this could become a central point of failure in an outage. For example, you can have multiple instances in different regions and use Cloud Load Balancing and Cloud DNS to direct the pipeline run requests to an instance that isn't affected by an outage (see the example tier one and tier three architectures).
Outages for other Google Cloud data services in the pipeline
Your instance might use other Google Cloud services as data sources or pipeline execution environments, such as Dataproc, Cloud Storage, or BigQuery. Those services can be in different regions. When cross-regional execution is required, a failure in either region leads to an outage. In this scenario, you follow the standard disaster recovery steps, keeping in mind that cross-regional setup with critical services in different regions is less resilient.
Cloud Deploy
Cloud Deploy provides continuous delivery of workloads into runtime services such as GKE and Cloud Run. The service is composed of regional instances that synchronously replicate data across zones within the region.
Zonal outage: Control plane operations are unaffected. However, Cloud Build builds (for example, render or deploy operations) that are running when a zone fails are delayed or permanently lost. During an outage, the Cloud Deploy resource that triggered the build (a release or rollout) displays a failure status that indicates the underlying operation failed. You can re-create the resource to start a new build in the remaining functioning zones. For example, create a new rollout by redeploying the release to a target.
Regional outage: Control plane operations are unavailable, as is data from Cloud Deploy, until the region is restored. To help make it easier to restore service in the event of a regional outage, we recommend that you store your delivery pipeline and target definitions in source control. You can use these configuration files to re-create your Cloud Deploy pipelines in a functioning region. During an outage, data about existing releases is lost. Create a new release to continue deploying software to your targets.
Cloud DNS
Cloud DNS is a high-performance, resilient, global Domain Name System (DNS) service that publishes your domain names to the global DNS in a cost-effective way.
In the case of a zonal outage, Cloud DNS continues to serve requests from another zone in the same or different region without interruption. Updates to Cloud DNS records are synchronously replicated across zones within the region where they are received. Therefore, there is no data loss.
In the case of a regional outage, Cloud DNS continues to serve requests from other regions. It is possible that very recent updates to Cloud DNS records will be unavailable because updates are first processed in a single region before being asynchronously replicated to other regions.
Cloud Healthcare API
Cloud Healthcare API, a service for storing and managing healthcare data, is built to provide high availability and offers protection against zonal and regional failures, depending on a chosen configuration.
Regional configuration: in its default configuration, Cloud Healthcare API offers protection against zonal failure. Service is deployed in three zones across one region, with data also triplicated across different zones within the region. In case of a zonal failure, affecting either service layer or data layer, the remaining zones take over without interruption. With regional configuration, if a whole region where service is located experiences an outage, service will be unavailable until the region comes back online. In the unforeseen event of a physical destruction of a whole region, data stored in that region will be lost.
Multi-regional configuration: in its multiregional configuration, Cloud Healthcare API is deployed in three zones belonging to three different regions. Data is also replicated across three regions. This guards against loss of service in case of a whole-region outage, since the remaining regions would automatically take over. Structured data, such as FHIR, is synchronously replicated across multiple regions, so it's protected against data loss in case of a whole-region outage. Data that is stored in Cloud Storage buckets, such as DICOM and Dictation or large HL7v2/FHIR objects, is asynchronously replicated across multiple regions.
Cloud Identity
Cloud Identity services are distributed across multiple regions and use dynamic load balancing. Cloud Identity does not allow users to select a resource scope. If a particular zone or region experiences an outage, traffic is automatically distributed to other zones or regions.
Persistent data is mirrored in multiple regions with synchronous replication in most cases. For performance reasons, a few systems, such as caches or changes affecting large numbers of entities, are asynchronously replicated across regions. If the primary region in which the most current data is stored experiences an outage, Cloud Identity serves stale data from another location until the primary region becomes available.
Cloud Interconnect
Cloud Interconnect offers customers RFC 1918 access to Google Cloud networks from their on-premises data centers, over physical cables connected to Google peering edge.
Cloud Interconnect provides customers with a 99.9% SLA if they provision connections to two EADs (Edge Availability Domains) in a metropolitan area. A 99.99% SLA is available if the customer provisions connections in two EADs in two metropolitan areas to two regions with Global Routing. See Topology for non-critical applications overview and Topology for production-level applications overview for more information.
Cloud Interconnect is compute-zone independent and provides high availability in the form of EADs. In the event of an EAD failure, the BGP session to that EAD breaks and traffic fails over to the other EAD.
In the event of a regional failure, BGP sessions to that region break and traffic fails over to the resources in the working region. This applies when Global Routing is enabled.
Cloud Key Management Service
Cloud Key Management Service (Cloud KMS) provides scalable and highly-durable cryptographic key resource management. Cloud KMS stores all of its data and metadata in Spanner databases which provide high data durability and availability with synchronous replication.
Cloud KMS resources can be created in a single region, multiple regions, or globally.
In the case of zonal outage, Cloud KMS continues to serve requests from another zone in the same or different region without interruption. Because data is replicated synchronously, there is no data loss or corruption. When the zone outage is resolved, full redundancy is restored.
In the case of a regional outage, regional resources in that region are offline until the region becomes available again. Note that even within a region, at least 3 replicas are maintained in separate zones. When higher availability is required, resources should be stored in a multi-region or global configuration. Multi-region and global configurations are designed to stay available through a regional outage by geo-redundantly storing and serving data in more than one region.
Cloud External Key Manager (Cloud EKM)
Cloud External Key Manager is integrated with Cloud Key Management Service to let you control and access external keys through supported third-party partners. You can use these external keys to encrypt data at rest to use for other Google Cloud services that support customer-managed encryption keys (CMEK) integration.
Zonal outage: Cloud External Key Manager is resilient to zonal outages because of the redundancy that's provided by multiple zones in a region. If a zonal outage occurs, traffic is rerouted to other zones within the region. While traffic is rerouting, you might see an increase in errors, but the service is still available.
Regional outage: Cloud External Key Manager isn't available during a regional outage in the affected region. There is no failover mechanism that redirects requests across regions. We recommend that customers use multiple regions to run their jobs.
Cloud External Key Manager doesn't store any customer data persistently. Thus, there's no data loss during a regional outage within the Cloud External Key Manager system. However, Cloud External Key Manager depends on the availability of other services, like Cloud Key Management Service and external third party vendors. If those systems fail during a regional outage, you could lose data. The RPO/RTO of these systems are outside the scope of Cloud External Key Manager commitments.
Cloud Load Balancing
Cloud Load Balancing is a fully distributed, software-defined managed service. With Cloud Load Balancing, a single anycast IP address can serve as the frontend for backends in regions around the world. It isn't hardware-based, so you don't need to manage a physical load-balancing infrastructure. Load balancers are a critical component of most highly available applications.
Cloud Load Balancing offers both regional and global load balancers. It also provides cross-region load balancing, including automatic multi-region failover, which moves traffic to failover backends if your primary backends become unhealthy.
The global load balancers are resilient to both zonal and regional outages. The regional load balancers are resilient to zonal outages but are affected by outages in their region. However, in either case, it is important to understand that the resilience of your overall application depends not just on which type of load balancer you deploy, but also on the redundancy of your backends.
For more information about Cloud Load Balancing and its features, see Cloud Load Balancing overview.
Cloud Logging
Cloud Logging consists of two main parts: the Logs Router and Cloud Logging storage.
The Logs Router handles streaming log events and directs the logs to Cloud Storage, Pub/Sub, BigQuery, or Cloud Logging storage.
Cloud Logging storage is a service for storing, querying, and managing compliance for logs. It supports many users and workflows including development, compliance, troubleshooting, and proactive alerting.
Logs Router & incoming logs: During a zonal outage, the Cloud Logging API routes logs to other zones in the region. Normally, logs being routed by the Logs Router to Cloud Logging, BigQuery, or Pub/Sub are written to their end destination as soon as possible, while logs sent to Cloud Storage are buffered and written in batches hourly.
Log Entries: In the event of a zonal or regional outage, log entries that have been buffered in the affected zone or region and not written to the export destination become inaccessible. Logs-based metrics are also calculated in the Logs Router and subject to the same constraints. Once delivered to the selected log export location, logs are replicated according to the destination service. Logs that are exported to Cloud Logging storage are synchronously replicated across two zones in a region. For the replication behavior of other destination types, see the relevant section in this article. Note that logs exported to Cloud Storage are batched and written every hour. Therefore we recommend using Cloud Logging storage, BigQuery, or Pub/Sub to minimize the amount of data impacted by an outage.
Log Metadata: Metadata such as sink and exclusion configuration is stored globally but cached regionally so in the event of an outage, the regional Log Router instances would operate. Single region outages have no impact outside of the region.
Cloud Monitoring
Cloud Monitoring consists of a variety of interconnected features, such as dashboards (both built-in and user-defined), alerting, and uptime monitoring.
All Cloud Monitoring configuration, including dashboards, uptime checks, and alert policies, are globally defined. All changes to them are replicated synchronously to multiple regions. Therefore, during both zonal and regional outages, successful configuration changes are durable. In addition, although transient read and write failures can occur when a zone or region initially fails, Cloud Monitoring reroutes requests towards available zones and regions. In this situation you may retry configuration changes with exponential backoff.
When writing metrics for a specific resource, Cloud Monitoring first identifies the region in which the resource resides. It then writes three independent replicas of the metric data within the region. The overall regional metric write is returned as successful as soon as one of the three writes succeeds. The three replicas are not guaranteed to be in different zones within the region.
Zonal: During a zonal outage, metric writes and reads are completely unavailable for resources in the affected zone. Effectively, Cloud Monitoring acts like the affected zone doesn't exist.
Regional: During a regional outage, metric writes and reads are completely unavailable for resources in the affected region. Effectively, Cloud Monitoring acts like the affected region doesn't exist.
Cloud NAT
Cloud NAT (network address translation) is a distributed, software-defined managed service that lets certain resources without external IP addresses create outbound connections to the internet. It's not based on proxy VMs or appliances. Instead, Cloud NAT configures the Andromeda software that powers your Virtual Private Cloud network so that it provides source network address translation (source NAT or SNAT) for VMs without external IP addresses. Cloud NAT also provides destination network address translation (destination NAT or DNAT) for established inbound response packets.
For more information on the functionality of Cloud NAT, see the documentation.
Zonal outage: Cloud NAT is resilient to zonal failures because the control plane and network data plane are redundant across multiple zones within a region.
Regional outage: Cloud NAT is a regional product, so it cannot withstand a regional failure.
Cloud Router
Cloud Router is a fully distributed and managed Google Cloud service that uses the Border Gateway Protocol (BGP) to advertise IP address ranges. It programs dynamic routes based on the BGP advertisements that it receives from a peer. Instead of a physical device or appliance, each Cloud Router consists of software tasks that act as BGP speakers and responders.
In the case of a zonal outage, Cloud Router with a high availability (HA) configuration is resilient to zonal failures. In that case, one interface might lose connectivity, but traffic is redirected to the other interface through dynamic routing using BGP.
In the case of a regional outage, Cloud Router is a regional product, so it cannot withstand a regional failure. If customers have enabled global routing mode, routing between the failed region and other regions might be affected.
Cloud Run
Cloud Run is a stateless computing environment where customers can run their containerized code on Google's infrastructure. Cloud Run is a regional offering, meaning customers can choose the region but not the zones that make up a region. Data and traffic are automatically load balanced across zones within a region. Container instances are automatically scaled to meet incoming traffic and are load balanced across zones as necessary. Each zone maintains a scheduler that provides this autoscaling per-zone. It's also aware of the load other zones are receiving and will provision extra capacity in-zone to allow for any zonal failures.
If you use Cloud Run GPUs, you have the option to turn off zonal redundancy for the service, and instead use best-effort reliability in case of a zonal outage, at a lower cost. For details, see GPU zonal redundancy options.
Zonal outage: Cloud Run stores metadata as well as the deployed container. This data is stored regionally and written in a synchronous manner. The Cloud Run Admin API only returns the API call once the data has been committed to a quorum within a region. Since data is regionally stored, data plane operations are not affected by zonal failures either. Traffic will be routed to other zones in the event of a zonal failure.
Regional outage: Customers choose the Google Cloud region they want to create their Cloud Run service in. Data is never replicated across regions. Customer traffic will never be routed to a different region by Cloud Run. In the case of a regional failure, Cloud Run will become available again as soon as the outage is resolved. Customers are encouraged to deploy to multiple regions and use Cloud Load Balancing to achieve higher availability if desired.
Cloud Shell
Cloud Shell provides Google Cloud users access to single user Compute Engine instances that are preconfigured for onboarding, education, development, and operator tasks.
Cloud Shell isn't suitable for running application workloads and is instead intended for interactive development and educational use cases. It has per-user runtime quota limits, it is automatically shut down after a short period of inactivity, and the instance is only accessible to the assigned user.
The Compute Engine instances backing the service are zonal resources, so in the event of a zone outage, a user's Cloud Shell is unavailable.
Cloud Source Repositories
Cloud Source Repositories lets users create and manage private source code repositories. This product is designed with a global model, so you don't need to configure it for regional or zonal resiliency.
Instead, git push operations against Cloud Source Repositories synchronously
replicate the source repository update to multiple zones across multiple
regions. This means that the service is resilient to outages in any one region.
If a particular zone or region experiences an outage, traffic is automatically distributed to other zones or regions.
The feature to automatically mirror repositories from GitHub or Bitbucket can be affected by problems in those products. For example, mirroring is affected if GitHub or Bitbucket can't alert Cloud Source Repositories of new commits, or if Cloud Source Repositories can't retrieve content from the updated repository.
Spanner
Spanner is a scalable, highly-available, multi-version, synchronously replicated, and strongly consistent database with relational semantics.
Regional Spanner instances synchronously replicate data across three zones in a single region. A write to a regional Spanner instance is synchronously sent to all 3 replicas and acknowledged to the client after at least 2 replicas (majority quorum of 2 out of 3) have committed the write. This makes Spanner resilient to a zone failure by providing access to all the data, as the latest writes have been persisted and a majority quorum for writes can still be achieved with 2 replicas.
Spanner multi-regional instances include a write-quorum that synchronously replicates data across 5 zones located in three regions (two read-write replicas each in the default-leader region and another region; and one replica in the witness region). A write to a multi-regional Spanner instance is acknowledged after at least 3 replicas (majority quorum of 3 out of 5) have committed the write. In the event of a zone or region failure, Spanner has access to all the data (including latest writes) and serves read/write requests as the data is persisted in at least 3 zones across 2 regions at the time the write is acknowledged to the client.
See the Spanner instance documentation for more information about these configurations, and the replication documentation for more information about how Spanner replication works.
Cloud SQL
Cloud SQL is a fully managed relational database service for MySQL, PostgreSQL, and SQL Server. Cloud SQL uses managed Compute Engine virtual machines to run the database software. It offers a high availability configuration for regional redundancy, protecting the database from a zone outage. Cross-region replicas can be provisioned to protect the database from a region outage. Because the product also offers a zonal option, which is not resilient to a zone or region outage, you should be careful to select the high availability configuration, cross-region replicas, or both.
Zonal outage: The high availability option creates a primary and standby VM instance in two separate zones within one region. During normal operation, the primary VM instance serves all requests, writing database files to a Regional Persistent Disk, which is synchronously replicated to the primary and standby zones. If a zone outage affects the primary instance, Cloud SQL initiates a failover during which the Persistent Disk is attached to the standby VM and traffic is rerouted.
During this process, the database must be initialized, which includes processing any transactions written to the transaction log but not applied to the database. The number and type of unprocessed transactions can increase the RTO time. High recent writes can lead to a backlog of unprocessed transactions. The RTO time is most heavily impacted by (a) high recent write activity and (b) recent changes to database schemas.
Finally, when the zonal outage has been resolved, you can manually trigger a failback operation to resume serving in the primary zone.
For more details on the high availability option, see the Cloud SQL high availability documentation.
Regional outage: The cross-region replica option protects your database from regional outages by creating read replicas of your primary instance in other regions. The cross-region replication uses asynchronous replication, which allows the primary instance to commit transactions before they are committed on replicas. The time difference between when a transaction is committed on the primary instance and when it is committed on the replica is known as "replication lag" (which can be monitored). This metric reflects both transactions which have not been sent from the primary to replicas, as well as transactions that have been received but have not been processed by the replica. Transactions not sent to the replica would become unavailable during a regional outage. Transactions received but not processed by the replica impact the recovery time, as described below.
Cloud SQL recommends testing your workload with a configuration that includes a replica to establish a "safe transactions per second (TPS)" limit, which is the highest sustained TPS that doesn't accumulate replication lag. If your workload exceeds the safe TPS limit, replication lag accumulates, negatively affecting RPO and RTO values. As general guidance, avoid using small instance configurations (<2 vCPU cores, <100GB disks, or PD-HDD), which are susceptible to replication lag.
In the event of a regional outage, you must decide whether to manually promote a read replica. This is a manual operation because promotion can cause a split brain scenario in which the promoted replica accepts new transactions despite having lagged the primary instance at the time of the promotion. This can cause problems when the regional outage is resolved and you must reconcile the transactions that were never propagated from the primary to replica instances. If this is problematic for your needs, you may consider a cross-region synchronous replication database product like Spanner.
Once triggered by the user, the promotion process follows steps similar to the activation of a standby instance in the high availability configuration. In that process, the read replica must process the transaction log which drives the total recovery time. Because there is no built-in load balancer involved in the replica promotion, manually redirect applications to the promoted primary.
For more details on the cross-region replica option, see the Cloud SQL cross-region replica documentation.
For more information about Cloud SQL DR, see the following:
- Cloud SQL for MySQL database disaster recovery
- Cloud SQL for PostgreSQL database disaster recovery
- Cloud SQL for SQL Server database disaster recovery
Cloud Storage
Cloud Storage provides globally unified, scalable, and highly durable object storage. Cloud Storage buckets can be created in one of three different location types: in a single region, in a dual-region, or in a multi-region within a continent. With regional buckets, objects are stored redundantly across availability zones in a single region. Dual-region and multi-region buckets, on the other hand, are geo-redundant. This means that after newly written data is replicated to at least one remote region, objects are stored redundantly across regions. This approach gives data in dual-region and multi-region buckets a broader set of protections than can be achieved with regional storage.
Regional buckets are designed to be resilient in case of an outage in a single availability zone. If a zone experiences an outage, objects in the unavailable zone are automatically and transparently served from elsewhere in the region. Data and metadata are stored redundantly across zones, starting with the initial write. No writes are lost if a zone becomes unavailable. In the case of a regional outage, regional buckets in that region are offline until the region becomes available again.
If you need higher availability, you can store data in a dual-region or multi-region configuration. Dual-region and multi-region buckets are single buckets (no separate primary and secondary locations) but they store data and metadata redundantly across regions. In the case of a regional outage, service is not interrupted. You can think of dual-region and multi-region buckets as being active-active in that you can read and write workloads in more than one region simultaneously while the bucket remains strongly consistent. This can be especially attractive for customers who want to split their workload across the two regions as part of a disaster recovery architecture.
Dual-regions and multi-regions are strongly consistent because metadata is always written synchronously across regions. This approach allows the service to always determine what the latest version of an object is and where it can be served from, including from remote regions.
Data is replicated asynchronously. This means that there is an RPO time window where newly written objects start out protected as regional objects, with redundancy across availability zones within a single region. The service then replicates the objects within that RPO window to one or more remote regions to make them geo-redundant. After that replication is complete, data can be served automatically and transparently from another region in the case of a regional outage. Turbo replication is a premium feature available on a dual-region bucket to obtain a smaller RPO window, which targets 100% of newly written objects being replicated and made geo-redundant within 15 minutes.
RPO is an important consideration, because during a regional outage, data recently written to the affected region within the RPO window might not yet have been replicated to other regions. As a result, that data might not be accessible during the outage, and could be lost in the case of physical destruction of the data in the affected region.
Cloud Translation
Cloud Translation has active compute servers in multiple zones and regions. It also supports synchronous data replication across zones within regions. These features help Translation achieve instantaneous failover without any data loss for zonal failures, and without requiring any customer input or adjustments. In the case of a regional failure, Cloud Translation is not available.
Compute Engine
Compute Engine is one of Google Cloud's infrastructure-as-a-service options. It uses Google's worldwide infrastructure to offer virtual machines (and related services) to customers.
Compute Engine instances are zonal resources, so in the event of a zone outage instances are unavailable by default. Compute Engine does offer managed instance groups (MIGs) which can automatically scale up additional VMs from pre-configured instance templates, both within a single zone and across multiple zones within a region. MIGs are ideal for applications that require resilience to zone loss and are stateless, but require configuration and resource planning. Multiple regional MIGs can be used to achieve region outage resilience for stateless applications.
Applications that have stateful workloads can still use stateful MIGs, but extra care needs to be made in capacity planning since they do not scale horizontally. It's important in either scenario to correctly configure and test Compute Engine instance templates and MIGs ahead of time to ensure working failover capabilities to other zones. See the Develop your own reference architectures and guides section above for more information.
Sole-tenancy
Sole-tenancy lets you have exclusive access to a sole-tenant node, which is a physical Compute Engine server that is dedicated to hosting only your project's VMs.
Sole-tenant nodes, like Compute Engine instances, are zonal resources. In the unlikely event of a zonal outage, they are unavailable. To mitigate zonal failures, you can create a sole-tenant node in another zone. Given that certain workloads might benefit from sole-tenant nodes for licensing or CAPEX accounting purposes, you should plan a failover strategy in advance.
Recreating these resources in a different location might incur additional licensing costs or violate CAPEX accounting requirements. For general guidance, see Develop your own reference architectures and guides.
Sole-tenant nodes are zonal resources, and cannot withstand regional failures. To scale across zones, use regional MIGs.
Networking for Compute Engine
For information about high-availability setups for Interconnect connections, see the following documents:
You can provision external IP addresses in global or regional mode, which affects their availability in the case of a regional failure.
Cloud Load Balancing resilience
Load balancers are a critical component of most highly available applications. It is important to understand that the resilience of your overall application depends not just on the scope of the load balancer you choose (global or regional), but also on the redundancy of your backend services.
The following table summarizes load balancer resilience based on the load balancer's distribution or scope.
| Load balancer scope | Architecture | Resilient to zonal outage | Resilient to regional outage |
|---|---|---|---|
| Global | Each load balancer is distributed across all regions | ||
| Cross-region | Each load balancer is distributed across multiple regions | ||
| Regional | Each load balancer is distributed across multiple zones in the region | An outage in a given region affects the regional load balancers in that region |
For more information about choosing a load balancer, see the Cloud Load Balancing documentation.
Connectivity Tests
Connectivity Tests is a diagnostics tool that lets you check the connectivity between network endpoints. It analyzes your configuration and, in some cases, performs a live data plane analysis between the endpoints. An endpoint is a source or destination of network traffic, such as a VM, Google Kubernetes Engine (GKE) cluster, load balancer forwarding rule, or an IP address. Connectivity Tests is a diagnostic tool with no data plane components. It does not process or generate user traffic.
Zonal outage: Connectivity Tests resources are global. You can manage and view them in the event of a zonal outage. Connectivity Tests resources are the results of your configuration tests. These results might include the configuration data of zonal resources (for example, VM instances) in an affected zone. If there's an outage, the analysis results aren't accurate because the analysis is based on stale data from before the outage. Don't rely on it.
Regional outage: In a regional outage, you can still manage and view Connectivity Tests resources. Connectivity Tests resources might include configuration data of regional resources, like subnetworks, in an affected region. If there's an outage, the analysis results aren't accurate because the analysis is based on stale data from before the outage. Don't rely on it.
Container Registry
Container Registry provides a scalable hosted Docker Registry implementation that securely and privately stores Docker container images. Container Registry implements the HTTP Docker Registry API.
Container Registry is a global service that synchronously stores image metadata redundantly across multiple zones and regions by default. Container images are stored in Cloud Storage multi-regional buckets. With this storage strategy, Container Registry provides zonal outage resilience in all cases, and regional outage resilience for any data that has been asynchronously replicated to multiple regions by Cloud Storage.
Database Migration Service
Database Migration Service is a fully managed Google Cloud service to migrate databases from other cloud providers or from on-premises data centers to Google Cloud.
Database Migration Service is architected as a regional control plane. The control plane doesn't depend on an individual zone in a given region. During a zonal outage, you retain access to the Database Migration Service APIs, including the ability to create and manage migration jobs. During a regional outage, you lose access to Database Migration Service resources that belong to that region until the outage is resolved.
Database Migration Service depends on the availability of the source and destination databases that are used for the migration process. If a Database Migration Service source or destination database is unavailable, migrations stop making progress, but no customer core data or job data is lost. Migration jobs resume when the source and destination databases become available again.
For example, you can configure a destination Cloud SQL database with high-availability (HA) enabled to get a destination database that is resilient for zonal outages.
Database Migration Service migrations go through two phases:
- Full dump: Performs a full data copy from the source to the destination according to the migration job specification.
- Change data capture (CDC): Replicates incremental changes from the source to the destination.
Zonal outage: If a zonal failure occurs during either of these phases, you are still able to access and manage resources in Database Migration Service. Data migration is affected as follows:
- Full dump: Data migration fails; you need to restart the migration job once the destination database completes the failover operation.
- CDC: Data migration is paused. The migration job resumes automatically once the destination database completes the failover operation.
Regional outage: Database Migration Service doesn't support cross-regional resources, and therefore it's not resilient against regional failures.
Dataflow
Dataflow is Google Cloud's fully managed and serverless data processing service for streaming and batch pipelines. By default, a regional endpoint configures the Dataflow worker pool to use all available zones within the region. Zone selection is calculated for each worker at the time that the worker is created, optimizing for resource acquisition and use of unused reservations. In the default configuration for Dataflow jobs, intermediate data is stored by the Dataflow service, and the state of the job is stored in the backend. If a zone fails, Dataflow jobs can continue to run, because workers are re-created in other zones.
The following limitations apply:
- Regional placement is supported only for jobs using Streaming Engine or Dataflow Shuffle. Jobs that have opted out of Streaming Engine or Dataflow Shuffle can't use regional placement.
- Regional placement applies to VMs only. It doesn't apply to Streaming Engine and Dataflow Shuffle-related resources.
- VMs aren't replicated across multiple zones. If a VM becomes unavailable, its work items are considered lost and are reprocessed by another VM.
- If a region-wide stockout occurs, the Dataflow service can't create any more VMs.
Architecting Dataflow pipelines for high availability
You can run multiple streaming pipelines in parallel for high-availability data processing. For example, you can run two parallel streaming jobs in different regions. Running parallel pipelines provides geographical redundancy and fault tolerance for data processing. By considering the geographic availability of data sources and sinks, you can operate end-to-end pipelines in a highly available, multi-region configuration. For more information, see High availability and geographic redundancy in "Design Dataflow pipeline workflows."
In case of a zone or region outage, you can avoid data loss by reusing the same subscription to the Pub/Sub topic. To guarantee that records aren't lost during shuffle, Dataflow uses upstream backup, which means that the worker sending the records retries RPCs until it receives positive acknowledgement that the record has been received and that the side-effects of processing the record are committed to persistent storage downstream. Dataflow also continues to retry RPCs if the worker sending the records becomes unavailable. Retrying RPCs ensures that every record is delivered exactly once. For more information about the Dataflow exactly-once guarantee, see Exactly-once in Dataflow.
If the pipeline is using grouping or time-windowing, you can use the Seek functionality of Pub/Sub or Replay functionality of Kafka after a zonal or regional outage to reprocess data elements to arrive at the same calculation results. If the business logic used by the pipeline does not rely on data before the outage, the data loss of pipeline outputs can be minimized down to 0 elements. If the pipeline business logic does rely on data that was processed before the outage (for example, if long sliding windows are used, or if a global time window is storing ever-increasing counters), use Dataflow snapshots to save the state of the streaming pipeline and start a new version of your job without losing state.
Dataproc
Dataproc provides streaming and batch data processing capabilities. Dataproc is architected as a regional control plane that enables users to manage Dataproc clusters. The control plane does not depend on an individual zone in a given region. Therefore, during a zonal outage, you retain access to the Dataproc APIs, including the ability to create new clusters.
You can create Dataproc clusters on:
Dataproc clusters on Compute Engine
Because a Dataproc cluster on Compute Engine is a zonal resource, a zonal outage makes the cluster unavailable, or destroys the cluster. Dataproc does not automatically snapshot cluster status, so a zone outage could cause loss of data being processed. Dataproc does not persist user data within the service. Users can configure their pipelines to write results to many data stores; you should consider the architecture of the data store and choose a product that offers the required disaster resilience.
If a zone suffers an outage, you may choose to recreate a new instance of the cluster in another zone, either by selecting a different zone or using the Auto Placement feature in Dataproc to automatically select an available zone. Once the cluster is available, data processing can resume. You can also run a cluster with High Availability mode enabled, reducing the likelihood a partial zone outage will impact a master node and, therefore, the whole cluster.
Dataproc clusters on GKE
Dataproc clusters on GKE can be zonal or regional.
For more information about the architecture and the DR capabilities of zonal and regional GKE clusters, see the Google Kubernetes Engine section later in this document.
Datastream
Datastream is a serverless change data capture (CDC) and replication service that lets you synchronize data reliably, and with minimal latency. Datastream provides replication of data from operational databases into BigQuery and Cloud Storage. In addition, it offers streamlined integration with Dataflow templates to build custom workflows for loading data into a wide range of destinations, such as Cloud SQL and Spanner.
Zonal outage: Datastream is a multi-zonal service. It can withstand a complete, unplanned zonal outage without any loss of data or availability. If a zonal failure occurs, you can still access and manage your resources in Datastream.
Regional outage: In the case of a regional outage, Datastream becomes available again as soon as the outage is resolved.
Document AI
Document AI is a document understanding platform that takes unstructured data from documents and transforms it into structured data, making it easier to understand, analyze, and consume. Document AI is a regional offering. Customers can choose the region but not the zones within that region. Data and traffic are automatically load balanced across zones within a region. Servers are automatically scaled to meet incoming traffic and are load balanced across zones as necessary. Each zone maintains a scheduler that provides this autoscaling per zone. The scheduler is also aware of the load other zones are receiving and provisions extra capacity in-zone to allow for any zonal failures.
Zonal outage: Document AI stores user documents and processor version data. This data is stored regionally and written synchronously. Since data is regionally stored, data plane operations aren't affected by zonal failures. Traffic automatically routes to other zones in the event of a zonal failure, with a delay based on how long it takes dependent services, like Vertex AI, to recover.
Regional outage: Data is never replicated across regions. During a regional outage, Document AI will not failover. Customers choose the Google Cloud region in which they want to use Document AI. However, that customer traffic is never routed to another region.
Endpoint Verification
Endpoint Verification lets administrators and security operations professionals build an inventory of devices that access an organization's data. Endpoint Verification also provides critical device trust and security-based access control as a part of the Chrome Enterprise Premium solution.
Use Endpoint Verification when you want an overview of the security posture of your organization's laptop and desktop devices. When Endpoint Verification is paired with Chrome Enterprise Premium offerings, Endpoint Verification helps enforce fine-grained access control on your Google Cloud resources.
Endpoint Verification is available for Google Cloud, Cloud Identity, Google Workspace Business, and Google Workspace Enterprise.
Eventarc
Eventarc provides asynchronously delivered events from Google providers (first-party), user apps (second-party), and software as a service (third-party) using loosely-coupled services that react to state changes. It lets customers configure their destinations (for example, a Cloud Run instance or a 2nd gen Cloud Run function) to be triggered when an event occurs in an event provider service or the customer's code.
Zonal outage: Eventarc stores metadata related to triggers. This data is stored regionally and written synchronously. The Eventarc API that creates and manages triggers and channels only returns the API call when the data has been committed to a quorum within a region. Since data is regionally stored, data plane operations aren't affected by zonal failures. In the event of a zonal failure, traffic is automatically routed to other zones. Eventarc services for receiving and delivering second-party and third-party events are replicated across zones. These services are regionally distributed. Requests to unavailable zones are automatically served from available zones in the region.
Regional outage: Customers choose the Google Cloud region that they want to create their Eventarc triggers in. Data is never replicated across regions. Customer traffic is never routed by Eventarc to a different region. In the case of a regional failure, Eventarc becomes available again as soon as the outage is resolved. To achieve higher availability, customers are encouraged to deploy triggers to multiple regions if desired.
Note the following:
- Eventarc services for receiving and delivering first-party events are provided on a best-effort basis and are not covered by RTO/RPO.
- Eventarc event delivery for Google Kubernetes Engine services is provided on a best-effort basis and is not covered by RTO/RPO.
Filestore
The Basic and Zonal tiers are zonal resources. They are not tolerant to failure of the deployed zone or region.
Regional tier Filestore instances are regional resources. Filestore adopts the strict consistency policy required by NFS. When a client writes data, Filestore doesn't return an acknowledgment until the change is persisted and replicated in two zones so that subsequent reads return the correct data.
In the event of a zone failure, a Regional tier instance continues to serve data from other zones, and in the meantime accepts new writes. Both the read and write operations might have a degraded performance; the write operation might not be replicated. Encryption is not compromised because the key will be served from other zones.
We recommend that clients create external backups in case of further outages in other zones in the same region. The backup can be used to restore the instance to other regions.
Firestore
Firestore is a flexible, scalable database for mobile, web, and server development from Firebase and Google Cloud. Firestore offers automatic multi-region data replication, strong consistency guarantees, atomic batch operations, and ACID transactions.
Firestore offers both single region and multi-regional locations to customers. Traffic is automatically load-balanced across zones in a region.
Regional Firestore instances synchronously replicate data across at least three zones. In the case of zonal failure, writes can still be committed by the remaining two (or more) replicas, and committed data is persisted. Traffic automatically routes to other zones. A regional location offers lower costs, lower write latency, and co-location with other Google Cloud resources.
Firestore multi-regional instances synchronously replicate data across five zones in three regions (two serving regions and one witness region), and they are robust against zonal and regional failure. In case of zonal or regional failure, committed data is persisted. Traffic automatically routes to serving zones/regions, and commits are still served by at least three zones across the two regions remaining. Multi-regions maximize the availability and durability of databases.
Firewall Insights
Firewall Insights helps you understand and optimize your firewall rules. It provides insights, recommendations, and metrics about how your firewall rules are being used. Firewall Insights also uses machine learning to predict future firewall rules usage. Firewall Insights lets you make better decisions during firewall rule optimization. For example, Firewall Insights identifies rules that it classifies as overly permissive. You can use this information to make your firewall configuration stricter.
Zonal outage: Since Firewall Insights data are replicated across zones, it isn't affected by a zonal outage, and customer traffic is automatically routed to other zones.
Regional outage: Since Firewall Insights data are replicated across regions, it isn't affected by a regional outage, and customer traffic is automatically routed to other regions.
Fleet
Fleets let customers manage multiple Kubernetes clusters as a group, and allow platform administrators to use multi-cluster services. For example, fleets let administrators apply uniform policies across all clusters or set up Multi Cluster Ingress.
When you register a GKE cluster to a fleet, by default, the cluster has a regional membership in the same region. When you register a non-Google Cloud cluster to a fleet, you can pick any region or the global location. The best practice is to choose a region that's close to the cluster's physical location. This provides optimal latency when using Connect gateway to access the cluster.
In the case of a zonal outage, fleet functionalities are not affected unless the underlying cluster is zonal and becomes unavailable.
In the case of a regional outage, fleet functionalities fail statically for the in-region membership clusters. Mitigation of a regional outage requires deployment across multiple regions, as suggested by Architecting disaster recovery for cloud infrastructure outages.
Google Cloud Armor
Cloud Armor helps you protect your deployments and applications from multiple types of threats, including volumetric DDoS attacks and application attacks like cross-site scripting and SQL injection. Cloud Armor filters unwanted traffic at Google Cloud load balancers and prevents such traffic from entering your VPC and consuming resources. Some of these protections are automatic. Some require you to configure security policies and attach them to backend services or regions. Globally scoped Cloud Armor security policies are applied at global load balancers. Regionally scoped security policies are applied at regional load balancers.
Zonal outage: In case of a zonal outage, Google Cloud load balancers redirect your traffic to other zones where healthy backend instances are available. Cloud Armor protection is available immediately after the traffic failover because your Cloud Armor security policies are synchronously replicated to all zones in a region.
Regional outage: In case of regional outages, global Google Cloud load balancers redirect your traffic to other regions where healthy backend instances are available. Cloud Armor protection is available immediately after the traffic failover because your global Cloud Armor security policies are synchronously replicated to all regions. To be resilient against regional failures, you must configure Cloud Armor regional security policies for all your regions.
Google Kubernetes Engine
Google Kubernetes Engine (GKE) offers managed Kubernetes service by streamlining the deployment of containerized applications on Google Cloud. You can choose between regional or zonal cluster topologies.
- When creating a zonal cluster, GKE provisions one control plane machine in the chosen zone, as well as worker machines (nodes) within the same zone.
- For regional clusters, GKE provisions three control plane machines in three different zones within the chosen region. By default, nodes are also spanned across three zones, though you can choose to create a regional cluster with nodes provisioned only in one zone.
- Multi-zonal clusters are similar to zonal clusters as they include one master machine, but additionally offer the ability to span nodes across multiple zones.
Zonal outage: To avoid zonal outages, use regional clusters. The control plane and the nodes are distributed across three different zones within a region. A zone outage does not impact control plane and worker nodes deployed in the other two zones.
Regional outage: Mitigation of a regional outage requires deployment across multiple regions. Although currently not being offered as a built-in product capability, multi-region topology is an approach taken by several GKE customers today, and can be manually implemented. You can create multiple regional clusters to replicate your workloads across multiple regions, and control the traffic to these clusters using multi-cluster ingress.
HA VPN
HA VPN (high availability) is a resilient Cloud VPN offering that securely encrypts your traffic from your on-premises private cloud, other virtual private cloud, or other cloud service provider network to your Google Cloud Virtual Private Cloud (VPC).
HA VPN's gateways have two interfaces, each with an IP address from separate IP address pools, split both logically and physically across different PoPs and clusters, to ensure optimal redundancy.
Zonal outage: In the case of a zonal outage, one interface may lose connectivity, but traffic is redirected to the other interface via dynamic routing using Border Gateway Protocol (BGP).
Regional outage: In the case of a regional outage, both interfaces may lose connectivity for a brief period.
Identity and Access Management
Identity and Access Management (IAM) is responsible for all authorization decisions
for actions on cloud resources. IAM confirms that a policy grants
permission for each action (in the data plane), and it processes updates to those policies
through a SetPolicy call (in the control plane).
All IAM policies are replicated across multiple zones within every region, helping IAM data plane operations recover from failures of other regions and tolerant of zone failures within each region. The resilience of IAM data plane against zone failures and region failures enables multi-region and multi-zone architectures for high availability.
IAM control plane operations can depend on cross-region
replication. When SetPolicy calls succeed, the data has been written to
multiple regions, but propagation to other regions is eventually consistent.
The IAM control plane is resilient to single region failure.
Identity-Aware Proxy
Identity-Aware Proxy provides access to applications hosted on Google Cloud, on other clouds, and on-premises. IAP is regionally distributed, and requests to unavailable zones are automatically served from other available zones in the region.
Regional outages in IAP affect access to the applications hosted on the impacted region. We recommend that you deploy to multiple regions and use Cloud Load Balancing to achieve higher availability and resilience against regional outages.
Identity Platform
Identity Platform lets customers add customizable Google-grade identity and access management to their apps. Identity Platform is a global offering. Customers cannot choose the regions or zones in which their data is stored.
Zonal outage: During a zonal outage, Identity Platform fails over requests to the next closest cell. All data is saved on a global scale, so there's no data loss.
Regional outage: During a regional outage, Identity Platform requests to the unavailable region temporarily fail while Identity Platform removes traffic from the affected region. Once there's no more traffic to the affected region, a global server load-balancing service routes requests to the nearest available healthy region. All data is saved globally, so there's no data loss.
Knative serving
Knative serving is a global service that enables the customers to run serverless workloads on customer clusters. Its purpose is to ensure that Knative serving workloads are properly deployed on customer clusters and that the installation status of Knative serving is reflected in GKE Fleet API Feature resource. This service takes part only when installing or upgrading Knative serving resources on customer clusters. It isn't involved in executing cluster workloads. Customer clusters belonging to projects which have Knative serving enabled are distributed between replicas in multiple regions and zones-each cluster is monitored by one replica.
Zonal and regional outage: Clusters that are monitored by replicas that were hosted in a location undergoing an outage, are automatically redistributed between healthy replicas in other zones and regions. While this reassignment is in progress, there might be a short time when some clusters are not monitored by Knative serving. If during that time the user decides to enable Knative serving features on the cluster, the installation of Knative serving resources on the cluster will commence after the cluster reconnects with a healthy Knative serving service replica.
Looker (Google Cloud core)
Looker (Google Cloud core) is a business intelligence platform that provides simplified and streamlined provisioning, configuration, and management of a Looker instance from the Google Cloud console. Looker (Google Cloud core) lets users explore data, create dashboards, set up alerts, and share reports. In addition, Looker (Google Cloud core) offers an IDE for data modelers and rich embedding and API features for developers.
Looker (Google Cloud core) is composed of regionally isolated instances that synchronously replicate data across zones within the region. Ensure that the resources your instance uses, such as the data sources that Looker (Google Cloud core) connects to, are in the same region that your instance runs in.
Zonal outage: Looker (Google Cloud core) instances store metadata and their own deployed containers. The data is written synchronously across replicated instances. In a zonal outage, Looker (Google Cloud core) instances continue to serve from other available zones in the same region. Any transactions or API calls return after the data has been committed to a quorum within a region. If the replication fails, then the transaction is not committed and the user is notified about the failure. If more than one zone fails, the transactions also fail and the user is notified. Looker (Google Cloud core) stops any schedules or queries that are currently running. You have to reschedule or queue them again after resolving the failure.
Regional outage: Looker (Google Cloud core) instances within the affected region aren't available. Looker (Google Cloud core) stops any schedules or queries that are currently running. You have to reschedule or queue the queries again after resolving the failure. You can manually create new instances in a different region. You can also recover your instances using the process defined in Import or export data from a Looker (Google Cloud core) instance. We recommend that you set up a periodic data export process to copy the assets in advance, in the unlikely event of a regional outage.
Looker Studio
Looker Studio is a data visualization and business intelligence product. It enables customers to connect to their data stored in other systems, create reports and dashboards using that data, and share the reports and dashboards throughout their organization. Looker Studio is a global service and does not allow users to select a resource scope.
In the case of a zonal outage, Looker Studio continues to serve requests from another zone in the same region or in a different region without interruption. User assets are synchronously replicated across regions. Therefore, there is no data loss.
In the case of a regional outage, Looker Studio continues to serve requests from another region without interruption. User assets are synchronously replicated across regions. Therefore, there is no data loss.
Memorystore for Memcached
Memorystore for Memcached is Google Cloud's managed Memcached offering. Memorystore for Memcached lets customers create Memcached clusters that can be used as high-throughput, key-value databases for applications.
Memcached clusters are regional, with nodes distributed across all customer-specified zones. However, Memcached doesn't replicate any data across nodes. Therefore a zonal failure can result in loss of data, also described as a partial cache flush. Memcached instances will continue to operate, but they will have fewer nodes—the service won't start any new nodes during a zonal failure. Memcached nodes in unaffected zones will continue to serve traffic, although the zonal failure will result in a lower cache hit rate until the zone is recovered.
In the event of a regional failure, Memcached nodes don't serve traffic. In that case, data is lost, which results in a full cache flush. To mitigate a regional outage, you can implement an architecture that deploys the application and Memorystore for Memcached across multiple regions.
Memorystore for Redis
Memorystore for Redis is a fully managed Redis service for Google Cloud that can reduce the burden of managing complex Redis deployments. It currently offers 2 tiers: Basic Tier and Standard Tier. For Basic Tier, a zonal or regional outage will cause loss of data, also known as a full cache flush. For Standard Tier, a regional outage will cause loss of data. A zonal outage might cause partial data loss to Standard Tier instance due to its asynchronous replication.
Zonal outage: Standard Tier instances asynchronously replicate dataset operations from the dataset in the primary node to the replica node. When the outage occurs within the zone of the primary node, the replica node will be promoted to become the primary node. During the promotion, a failover occurs and the Redis client has to reconnect to the instance. After reconnecting, operations resume. For more information about high availability of Memorystore for Redis instances in the Standard Tier, refer to Memorystore for Redis high availability.
If you enable read replicas in your Standard Tier instance and you only have one replica, the read endpoint isn't available for the duration of a zonal outage. For more information about disaster recovery of read replicas, see Failure modes for read replicas.
Regional outage: Memorystore for Redis is a regional product, so a single instance cannot withstand a regional failure. You can schedule periodic tasks to export a Redis instance to a Cloud Storage bucket in a different region. When a regional outage occurs, you can restore the Redis instance in a different region from the dataset you have exported.
Multi-Cluster Service Discovery and Multi Cluster Ingress
GKE multi-cluster Services (MCS) consists of multiple components. The components include the Google Kubernetes Engine hub (which orchestrates multiple Google Kubernetes Engine clusters by using memberships), the clusters themselves, and GKE hub controllers (Multi Cluster Ingress, Multi-Cluster Service Discovery). The hub controllers orchestrate Compute Engine load balancer configuration by using backends on multiple clusters.
In the case of a zonal outage, Multi-Cluster Service Discovery continues to serve requests from another zone or region. In the case of a regional outage, Multi-Cluster Service Discovery does not fail over.
In the case of a zonal outage for Multi Cluster Ingress, if the config cluster is zonal and in scope of the failure, the user needs to manually fail over. The data plane is fail-static and will continue serving traffic until the user has failed over. To avoid the need for manual failover, use a regional cluster for the configuration cluster.
In the case of a regional outage, Multi Cluster Ingress does not fail over. Users must have a DR plan in place for manually failing over the configuration cluster. For more information, see Setting up Multi Cluster Ingress and Configuring multi-cluster Services.
For more information about GKE, see the "Google Kubernetes Engine" section in Architecting disaster recovery for cloud infrastructure outages.
Network Analyzer
Network Analyzer automatically monitors your VPC network configurations and detects misconfigurations and suboptimal configurations. It provides insights on network topology, firewall rules, routes, configuration dependencies, and connectivity to services and applications. It identifies network failures, provides root cause information, and suggests possible resolutions.
Network Analyzer runs continuously and triggers relevant analyses based on near real-time configuration updates in your network. If Network Analyzer detects a network failure, it tries to correlate the failure with recent configuration changes to identify root causes. Wherever possible, it provides recommendations to suggest details on how to fix the issues.
Network Analyzer is a diagnostic tool with no data plane components. It does not process or generate user traffic.
Zonal outage: Network Analyzer service is replicated globally, and its availability isn't affected by a zonal outage.
If insights from Network Analyzer contain configurations from a zone suffering an outage, it affects data quality. The network insights that refer to configurations in that zone become stale. Don't rely on any insights provided by Network Analyzer during outages.
Regional outage: Network Analyzer service is replicated globally, and its availability isn't affected by a regional outage.
If insights from Network Analyzer contain configurations from a region suffering an outage, it affects data quality. The network insights that refer to configurations in that region become stale. Don't rely on any insights provided by Network Analyzer during outages.
Network Topology
Network Topology is a visualization tool that shows the topology of your network infrastructure. The Infrastructure view shows Virtual Private Cloud (VPC) networks, hybrid connectivity to and from your on-premises networks, connectivity to Google-managed services, and the associated metrics.
Zonal outage: In case of a zonal outage, data for that zone won't appear in Network Topology. Data for other zones aren't affected.
Regional outage: In case of a regional outage, data for that region won't appear in Network Topology. Data for other regions aren't affected.
Performance Dashboard
Performance Dashboard gives you visibility into the performance of the entire Google Cloud network, as well as to the performance of your project's resources.
With these performance-monitoring capabilities, you can distinguish between a problem in your application and a problem in the underlying Google Cloud network. You can also investigate historical network performance problems. Performance Dashboard also exports data to Cloud Monitoring. You can use Monitoring to query the data and get access to additional information.
Zonal outage:
In case of a zonal outage, latency and packet loss data for traffic from the affected zone won't appear in Performance Dashboard. Latency and packet loss data for traffic from other zones isn't affected. When the outage ends, latency and packet loss data resumes.
Regional outage:
In case of a regional outage, latency and packet loss data for traffic from the affected region won't appear in Performance Dashboard. Latency and packet loss data for traffic from other regions isn't affected. When the outage ends, latency and packet loss data resumes.
Network Connectivity Center
Network Connectivity Center is a network connectivity management product that employs a hub-and-spoke architecture. With this architecture, a central management resource serves as a hub and each connectivity resource serves as a spoke. Hybrid spokes currently support HA VPN, Dedicated and Partner Interconnect, and SD-WAN router appliances from major third party vendors. With Network Connectivity Center hybrid spokes, enterprises can connect Google Cloud workloads and services to on-premise data centers, other clouds, and their branch offices through the global reach of the Google Cloud network.
Zonal outage: A Network Connectivity Center hybrid spoke with HA configuration is resilient to zonal failures because the control plane and network data plane are redundant across multiple zones within a region.
Regional outage: A Network Connectivity Center hybrid spoke is a regional resource, so it can't withstand a regional failure.
Network Service Tiers
Network Service Tiers lets you optimize connectivity between systems on the internet and your Google Cloud instances. It offers two distinct service tiers, the Premium Tier and the Standard Tier. With the Premium Tier, a globally announced anycast Premium Tier IP address can serve as the frontend for either regional or global backends. With the Standard Tier, a regionally announced Standard Tier IP address can serve as the frontend for regional backends. The overall resilience of an application is influenced by both the network service tier and the redundancy of the backends it associates with.
Zonal outage: Both the Premium Tier and the Standard Tier offer resilience against zonal outages when associated with regionally redundant backends. When a zonal outage occurs, the failover behavior for cases using regionally redundant backends is determined by the associated backends themselves. When associated with zonal backends, the service will become available again as soon as the outage is resolved.
Regional outage: The Premium Tier offers resilience against regional outages when it is associated with globally redundant backends. In the Standard tier, all traffic to the affected region will fail. Traffic to all other regions is unaffected. When a regional outage occurs, the failover behavior for cases using the Premium Tier with globally redundant backends is determined by the associated backends themselves. When using the Premium Tier with regional backends or the Standard Tier, the service will become available again as soon as the outage is resolved.
Organization Policy Service
Organization Policy Service provides centralized and programmatic control over your organization's Google Cloud resources. As the Organization Policy administrator, you can configure constraints across your entire resource hierarchy.
Zonal outage: All organization policies created by Organization Policy Service are replicated asynchronously across multiple zones within every region. Organization Policy data and control plane operations are tolerant of zone failures within each region.
Regional outage: All organization policies created by Organization Policy Service are replicated asynchronously across multiple regions. Organization Policy control plane operations are written to multiple regions and the propagation to other regions is consistent within minutes. The Organization Policy control plane is resilient to single region failure. The Organization Policy data plane operations can recover from failures in other regions and the resilience of the Organization Policy data plane against zone failures and region failures enables multi-region and multi-zone architectures for high availability.
Packet Mirroring
Packet Mirroring clones the traffic of specified instances in your Virtual Private Cloud (VPC) network and forwards the cloned data to instances behind a regional internal load balancer for examination. Packet Mirroring captures all traffic and packet data, including payloads and headers.
For more information about the functionality of Packet Mirroring, see the Packet Mirroring overview page.
Zonal outage: Configure the internal load balancer so there are instances in multiple zones. If a zonal outage occurs, Packet Mirroring diverts cloned packets to a healthy zone.
Regional outage: Packet Mirroring is a regional product. If there's a regional outage, packets in the affected region aren't cloned.
Persistent Disk
Persistent Disks are available in zonal and regional configurations.
Zonal Persistent Disks are hosted in a single zone. If the disk's zone is unavailable, the Persistent Disk is unavailable until the zone outage is resolved.
Regional Persistent Disks provide synchronous replication of data between two zones in a region. In the event of an outage in your virtual machine's zone, you can force attach a regional Persistent Disk to a VM instance in the disk's secondary zone. To perform this task, you must either start another VM instance in that zone or maintain a hot standby VM instance in that zone.
To asynchronously replicate data in a Persistent Disk across regions, you can use Persistent Disk Asynchronous Replication (PD Async Replication), which provides low RTO and RPO block storage replication for cross-region active-passive DR. In the unlikely event of a regional outage, PD Async Replication enables you to failover your data to a secondary region and restart your workload in that region.
Personalized Service Health
Personalized Service Health communicates service disruptions relevant to your Google Cloud projects. It provides multiple channels and processes to view or integrate disruptive events (incidents, planned maintenance) into your incident response process—including the following:
- A dashboard in Google Cloud console
- A service API
- Configurable alerts
- Logs generated and sent to Cloud Logging
Zonal outage: Data is served from a global database with no dependency on specific locations. If a zonal outage occurs, Service Health is able to serve requests and automatically reroute traffic to zones in the same region that still function. Service Health can return API calls successfully if it is able to retrieve event data from the Service Health database.
Regional outage: Data is served from a global database with no dependency on specific locations. If there is a regional outage, Service Health is still able to serve requests but may perform with reduced capacity. Regional failures in Logging locations might affect Service Health users consuming logs or cloud alerting notifications.
Private Service Connect
Private Service Connect is a capability of Google Cloud networking that lets consumers access managed services privately from inside their VPC network. Similarly, it allows managed service producers to host these services in their own separate VPC networks and offer a private connection to their consumers.
Private Service Connect endpoints for published services
A Private Service Connect endpoint connects to services in service producers VPC network using a Private Service Connect forwarding rule. The service producer provides a service using private connectivity to a service consumer, by exposing a single service attachment. Then the service consumer will be able to assign a virtual IP address from their VPC for such service.
Zonal outage: Private Service Connect traffic that comes from the VM traffic generated by consumer VPC client endpoints can still access exposed managed services on the service producer's internal VPC network. This access is possible because Private Service Connect traffic fails over to healthier service backends in a different zone.
Regional outage: Private Service Connect is a regional product. It isn't resilient to regional outages. Multi-regional managed services can achieve high availability during a regional outages by configuring Private Service Connect endpoints across multiple regions.
Private Service Connect endpoints for Google APIs
A Private Service Connect endpoint connects to Google APIs using a Private Service Connect forwarding rule. This forwarding rule lets customers use customized endpoint names with their internal IP addresses.
Zonal outage: Private Service Connect traffic from consumer VPC client endpoints can still access Google APIs because connectivity between the VM and the endpoint will automatically fail over to another functional zone in the same region. Requests that are already in-flight when an outage begins will depend on the client's TCP timeout and retry behavior for recover.
See Compute Engine recovery for more details.
Regional outage: Private Service Connect is a regional product. It isn't resilient to regional outages. Multi-regional managed services can achieve high availability during a regional outages by configuring Private Service Connect endpoints across multiple regions.
For more information about Private Service Connect, see the "Endpoints" section in Private Service Connect types.
Pub/Sub
Pub/Sub is a messaging service for application integration and stream analytics. Pub/Sub topics are global, meaning that they are visible and accessible from any Google Cloud location. However, any given message is stored in a single Google Cloud region, closest to the publisher and allowed by the resource location policy. Thus, a topic may have messages stored in different regions throughout Google Cloud. The Pub/Sub message storage policy can restrict the regions in which messages are stored.
Zonal outage: When a Pub/Sub message is published, it is synchronously written to storage in at least two zones within the region. Therefore, if a single zone becomes unavailable, there is no customer-visible impact.
Regional outage: During a region outage, messages stored within the affected region are inaccessible. Publishers and subscribers that would connect to the affected region, either via a regional endpoint or the global endpoint, aren't able to connect. Publishers and subscribers that connect to other regions can still connect, and messages available in other regions are delivered to network-nearest subscribers that have capacity.
If your application relies on message ordering, review the detailed recommendations from the Pub/Sub team. Message ordering guarantees are provided on a per-region basis, and can become disrupted if you use a global endpoint.
reCAPTCHA
reCAPTCHA is a global service that detects fraudulent activity, spam, and abuse. It does not require or allow configuration for regional or zonal resiliency. Updates to configuration metadata are asynchronously replicated to each region where reCAPTCHA runs.
In the case of a zonal outage, reCAPTCHA continues to serve requests from another zone in the same or different region without interruption.
In the case of a regional outage, reCAPTCHA continues to serve requests from another region without interruption.
Secret Manager
Secret Manager is a secrets and credential management product for Google Cloud. With Secret Manager, you can easily audit and restrict access to secrets, encrypt secrets at rest, and ensure that sensitive information is secured in Google Cloud.
Secret Manager resources are normally created with the automatic replication policy (recommended), which causes them to be replicated globally. If your organization has policies that do not allow global replication of secret data, Secret Manager resources can be created with user-managed replication policies, in which one or more regions are chosen for a secret to be replicated to.
Zonal outage: In the case of zonal outage, Secret Manager continues to serve requests from another zone in the same or different region without interruption. Within each region, Secret Manager always maintains at least 2 replicas in separate zones (in most regions, 3 replicas). When the zone outage is resolved, full redundancy is restored.
Regional outage: In the case of a regional outage, Secret Manager continues to serve requests from another region without interruption, assuming the data has been replicated to more than one region (either through automatic replication or through user-managed replication to more than one region). When the region outage is resolved, full redundancy is restored.
Security Command Center
Security Command Center is the global, real time risk management platform for Google Cloud. It consists of two main components: detectors and findings.
Detectors are affected by both regional and zonal outages, in different ways. During a regional outage, detectors can't generate new findings for regional resources because the resources they're supposed to be scanning aren't available.
During a zonal outage, detectors can take anywhere from several minutes to hours to resume normal operation. Security Command Center won't lose finding data. It also won't generate new finding data for unavailable resources. In the worst case scenario, Container Threat Detection agents may run out of buffer space while connecting to a healthy cell, which could lead to lost detections.
Findings are resilient to both regional and zonal outages because they're synchronously replicated across regions.
Sensitive Data Protection (including the DLP API)
Sensitive Data Protection provides sensitive data classification, profiling, de-identification, tokenization, and privacy risk analysis services. It works synchronously on the data that's sent in the request bodies, or asynchronously on the data that's already present in cloud storage systems. Sensitive Data Protection can be invoked through the global or region-specific endpoints.
Global endpoint: The service is designed to be resilient to both regional
and zonal failures. If the service is overloaded while a failure happens, data
sent to the hybridInspect
method of the service might be lost.
To create a failure-resistant architecture, include logic to examine the most
recent pre-failure finding that was produced by the hybridInspect method. In
case of an outage, the data that was sent to the method might be lost, but no
more than the last 10 minutes' worth before the failure event. If there are
findings fresher than 10 minutes before the outage started, it indicates the
data that resulted in that finding wasn't lost. In that case, there's no need to
replay the data that came before the finding timestamp, even if it's within the
10 minute interval.
Regional endpoint: Regional endpoints are not resilient to regional failures. If resiliency against a regional failure is required, consider failing over to other regions. The zonal failure characteristics are the same as above.
Service Usage
The Service Usage API is an infrastructure service of Google Cloud that lets you list and manage APIs and services in your Google Cloud projects. You can list and manage APIs and Services provided by Google, Google Cloud, and third-party producers. The Service Usage API is a global service and resilient to both zonal and regional outages. In the case of zonal outage or regional outage, the Service Usage API continues to serve requests from another zone across different regions.
For more information about Service Usage, see Service Usage Documentation.
Speech-to-Text
Speech-to-Text lets you convert speech audio to text by using machine learning techniques like neural network models. Audio is sent in real time from an application’s microphone, or it is processed as a batch of audio files.
Zonal outage:
Speech-to-Text API v1: During a zonal outage, Speech-to-Text API version 1 continues to serve requests from another zone in the same region without interruption. However, any jobs that are currently executing within the failing zone are lost. Users must retry the failed jobs, which will be routed to an available zone automatically.
Speech-to-Text API v2: During a zonal outage, Speech-to-Text API version 2 continues to serve requests from another zone in the same region. However, any jobs that are currently executing within the failing zone are lost. Users must retry the failed jobs, which will be routed to an available zone automatically. The Speech-to-Text API only returns the API call once the data has been committed to a quorum within a region. In some regions, AI accelerators (TPUs) are available only in one zone. In that case, an outage in that zone causes speech recognition to fail but there is no data loss.
Regional outage:
Speech-to-Text API v1: Speech-to-Text API version 1 is unaffected by regional failure because it is a global multi-region service. The service continues to serve requests from another region without interruption. However, jobs that are currently executing within the failing region are lost. Users must retry those failed jobs, which will be routed to an available region automatically.
Speech-to-Text API v2:
Multi-region Speech-to-Text API version 2, the service continues to serve requests from another zone in the same region without interruption.
Single-region Speech-to-Text API version 2, the service scopes the job execution to the requested region. Speech-to-Text API version 2 doesn't route traffic to a different region, and data is not replicated to a different region. During a regional failure, Speech-to-Text API version 2 is unavailable in that region. However, it becomes available again when the outage is resolved.
Storage Transfer Service
Storage Transfer Service manages data transfers from various cloud sources to Cloud Storage, as well as to, from, and between file systems.
The Storage Transfer Service API is a global resource.
Storage Transfer Service depends on the availability of the source and destination of a transfer. If a transfer source or destination is unavailable, transfers stop making progress. However, no customer core data or job data is lost. Transfers resume when the source and destination become available again.
You can use Storage Transfer Service with or without an agent, as follows:
Agentless transfers use regional workers to orchestrate transfer jobs.
Agent-based transfers use software agents that are installed on your infrastructure. Agent-based transfers rely on the availability of the transfer agents and on the ability of the agents to connect to the file system. When you're deciding where to install transfer agents, consider the availability of the file system. For example, if you're running transfer agents on multiple Compute Engine VMs to transfer data to an Enterprise-tier Filestore instance (a regional resource), you should consider locating the VMs in different zones within the Filestore instance's region.
If agents become unavailable, or if their connection to the file system is interrupted, transfers stop making progress, but no data is lost. If all agent processes are terminated, the transfer job is paused until new agents are added to the transfer's agent pool.
During an outage, the behavior of Storage Transfer Service is as follows:
Zonal outage: During a zonal outage, the Storage Transfer Service APIs remain available, and you can continue to create transfer jobs. Data continues to transfer.
Regional outage: During a regional outage, the Storage Transfer Service APIs remain available, and you can continue to create transfer jobs. If your transfer's workers are located in the affected region, data transfer stops until the region becomes available again and the transfer automatically resumes.
Vertex ML Metadata
Vertex ML Metadata lets you record the metadata and artifacts produced by your ML system and query that metadata to help analyze, debug, and audit the performance of your ML system or the artifacts that it produces.
Zonal outage: In the default configuration, Vertex ML Metadata offers protection against zonal failure. The service is deployed in multiple zones across each region, with data synchronously replicated across different zones within each region. In case of a zonal failure, the remaining zones take over with minimal interruption.
Regional outage: Vertex ML Metadata is a regionalized service. In the case of a regional outage, Vertex ML Metadata will not fail over to another region.
Vertex AI Batch prediction
Batch prediction lets users run batch prediction against AI/ML models on Google's infrastructure. Batch prediction is a regional offering. Customers can choose the region in which they run jobs, but not the specific zones within that region. The batch prediction service automatically load-balances the job across different zones within the chosen region.
Zonal outage: Batch prediction stores metadata for batch prediction jobs within a region. The data is written synchronously, across multiple zones within that region. In a zonal outage, batch prediction partially loses workers performing jobs, but automatically adds them back in other available zones. If multiple batch prediction retries fail, the UI lists the job status as failed in the UI and in the API call requests. Subsequent user requests to run the job are routed to available zones.
Regional outage: Customers choose the Google Cloud region in which they want to run their batch prediction jobs. Data is never replicated across regions. Batch prediction scopes the job execution to the requested region and never routes prediction requests to a different region. When a regional failure occurs, batch prediction is unavailable in that region. It becomes available again when the outage resolves. We recommend that customers use multiple regions to run their jobs. In case of a regional outage, direct jobs to a different available region.
Vertex AI Model Registry
Vertex AI Model Registry lets users streamline model management, governance, and the deployment of ML models in a central repository. Vertex AI Model Registry is a regional offering with high availability and offers protection against zonal outages.
Zonal outage: Vertex AI Model Registry offers protection against zonal outages. The service is deployed in three zones across each region, with data synchronously replicated across different zones within the region. If a zone fails, the remaining zones will take over with no data loss and minimum service interruption.
Regional outage: Vertex AI Model Registry is a regionalized service. If a region fails, Model Registry won't fail over.
Vertex AI Online prediction
Online prediction lets users deploy AI/ML models on Google Cloud. Online prediction is a regional offering. Customers can choose the region where they deploy their models, but not the specific zones within that region. The prediction service will automatically load-balance the workload across different zones within the selected region.
Zonal outage: Online prediction doesn't store any customer content. A zonal outage leads to failure of the current prediction request execution. Online prediction may or may not automatically retry the prediction request depending on which endpoint type is used, specifically, a public endpoint will retry automatically while the private endpoint will not. To help handle failures and for improved resilience, incorporate retry logic with exponential back off in your code.
Regional outage: Customers choose the Google Cloud region in which they want to run their AI/ML models and online prediction services. Data is never replicated across regions. Online prediction scopes the AI/ML model execution to the requested region and never routes prediction requests to a different region. When a regional failure occurs, online prediction service is unavailable in that region. It becomes available again when the outage is resolved. We recommend that customers use multiple regions to run their AI/ML models. In case of a regional outage, direct traffic to a different, available region.
Vertex AI Pipelines
Vertex AI Pipelines is a Vertex AI service that lets you automate, monitor, and govern your machine learning (ML) workflows in a serverless manner. Vertex AI Pipelines is built to provide high availability and it offers protection against zonal failures.
Zonal outage: In the default configuration, Vertex AI Pipelines offers protection against zonal failure. The service is deployed in multiple zones across each region, with data synchronously replicated across different zones within the region. In case of a zonal failure, the remaining zones take over with minimal interruption.
Regional outage: Vertex AI Pipelines is a regionalized service. In the case of a regional outage, Vertex AI Pipelines will not fail over to another region. If a regional outage occurs we recommend that you run your pipeline jobs in a backup region.
Vertex AI Search
Vertex AI Search is a customizable search solution with generative AI features and native enterprise compliance. Vertex AI Search is automatically deployed and replicated across multiple regions within Google Cloud. You can configure where data is stored by choosing a supported multi-region, such as: global, US, or EU.
Zonal and Regional outage: UserEvents uploaded to
Vertex AI Search might not be recoverable due to asynchronous
replication delay. Other data and services provided by
Vertex AI Search remain available due to automatic
failover and synchronous data replication.
Vertex AI Training
Vertex AI Training provides users the ability to run custom training jobs on Google's infrastructure. Vertex AI Training is a regional offering, meaning that customers can choose the region to run their training jobs. However, customers can't choose the specific zones within that region. The training service might automatically load-balance the job execution across different zones within the region.
Zonal outage: Vertex AI Training stores metadata for the custom training job. This data is stored regionally and written synchronously. The Vertex AI Training API call only returns once this metadata has been committed to a quorum within a region. The training job might run in a specific zone. A zonal outage leads to failure of the current job execution. If so, the service automatically retries the job by routing it to another zone. If multiple retries fail, the job status is updated to failed. Subsequent user requests to run the job are routed to an available zone.
Regional outage: Customers choose the Google Cloud region they want to run their training jobs in. Data is never replicated across regions. Vertex AI Training scopes the job execution to the requested region and never routes training jobs to a different region. In the case of a regional failure, Vertex AI Training service is unavailable in that region and becomes available again when the outage is resolved. We recommend that customers use multiple regions to run their jobs, and in case of a regional outage, to direct jobs to a different region that is available.
Virtual Private Cloud (VPC)
VPC is a global service that provides network connectivity to resources (VMs, for example). Failures, however, are zonal. In the event of a zonal failure, resources in that zone are unavailable. Similarly, if a region fails, only traffic to and from the failed region is affected. The connectivity of healthy regions is unaffected.
Zonal outage: If a VPC network covers multiple zones and a zone fails, the VPC network will still be healthy for healthy zones. Network traffic between resources in healthy zones will continue to work normally during the failure. A zonal failure only affects network traffic to and from resources in the failing zone. To mitigate the impact of zonal failures, we recommend that you don't create all resources in a single zone. Instead, when you create resources, spread them across zones.
Regional outage: If a VPC network covers multiple regions and a region fails, the VPC network will still be healthy for healthy regions. Network traffic between resources in healthy regions will continue to work normally during the failure. A regional failure only affects network traffic to and from resources in the failing region. To mitigate the impact of regional failures, we recommended that you spread resources across multiple regions.
VPC Service Controls
VPC Service Controls is a regional service. Using VPC Service Controls, enterprise security teams can define fine-grained perimeter controls and enforce that security posture across numerous Google Cloud services and projects. Customer policies are mirrored regionally.
Zonal outage: VPC Service Controls continues to serve requests from another zone in the same region without interruption.
Regional outage: APIs configured for VPC Service Controls policy enforcement on the affected region are unavailable until the region becomes available again. Customers are encouraged to deploy VPC Service Controls enforced services to multiple regions if higher availability is desired.
Workflows
Workflows is an orchestration product that lets Google Cloud customers:
- deploy and run workflows which connect other existing services using HTTP,
- automate processes, including waiting on HTTP responses with automatic retries for up to a year, and
- implement real-time processes with low-latency, event-driven executions.
A Workflows customer can deploy workflows that describe the business logic they want to perform, then run the workflows either directly with the API or with event-driven triggers (currently limited to Pub/Sub or Eventarc). The workflow being run can manipulate variables, make HTTP calls and store the results, or define callbacks and wait to be resumed by another service.
Zonal outage: Workflows source code is not affected by zonal outages. Workflows stores the source code of workflows, along with the variable values and HTTP responses received by workflows that are running. Source code is stored regionally and written synchronously: the control plane API only returns once this metadata has been committed to a quorum within a region. Variables and HTTP results are also stored regionally and written synchronously, at least every five seconds.
If a zone fails, workflows are automatically resumed based on the last stored data. However, any HTTP requests that haven't already received responses aren't automatically retried. Use retry policies for requests that can be safely retried as described in our documentation.
Regional outage: Workflows is a regionalized service; in the case of a regional outage, Workflows won't fail over. Customers are encouraged to deploy Workflows to multiple regions if higher availability is desired.
Cloud Service Mesh
Cloud Service Mesh lets you configure a managed service mesh spanning multiple GKE clusters. This documentation concerns only the managed Cloud Service Mesh, the in-cluster variant is self-hosted and regular platform guidelines should be followed.
Zonal outage: Mesh configuration, as it is stored in the GKE cluster, is resilient to zonal outages as long as the cluster is regional. Data that the product uses for internal bookkeeping is stored either regionally or globally, and isn't affected if a single zone is out of service. The control plane is run in the same region as the GKE cluster it supports (for zonal clusters it is the containing region), and isn't affected by outages within a single zone.
Regional outage: Cloud Service Mesh provides services to GKE clusters, which are either regional or zonal. In case of a regional outage, Cloud Service Mesh won't fail over. Neither would GKE. Customers are encouraged to deploy meshes constituting of GKE clusters covering different regions.
Service Directory
Service Directory is a platform for discovering, publishing, and connecting services. It provides real-time information, in a single place, about all your services. Service Directory lets you perform service inventory management at scale, whether you have a few service endpoints or thousands.
Service Directory resources are created regionally, matching the location parameter specified by the user.
Zonal outage: During a zonal outage, Service Directory continues to serve requests from another zone in the same or different region without interruption. Within each region, Service Directory always maintains multiple replicas. Once the zonal outage is resolved, full redundancy is restored.
Regional outage: Service Directory isn't resilient to regional outages.