データメッシュで、セルフサービスのデータ プラットフォームを使用すると、ユーザーはデータ プロダクトを自律的に構築、共有、使用できるようになり、データから価値を生み出すことができます。 これらのメリットを最大限に実現するには、このドキュメントで説明する機能をセルフサービス データ プラットフォームに搭載することをおすすめします。
このドキュメントは、 Google Cloudでデータメッシュを実装する方法を説明するシリーズの一部です。ここでは、 Google Cloudで最新の分散データメッシュを構築するとデータメッシュ内のアーキテクチャと機能で説明するコンセプトをお読みになり、理解されていることを前提としています。
このシリーズは、次のパートから構成されています。
- データメッシュ内のアーキテクチャと機能
- データメッシュ用のセルフサービス データ プラットフォームを設計する(このドキュメント)
- データメッシュでデータ プロダクトを構築する
- データ メッシュでデータ プロダクトを検出して使用する
データ プラットフォーム チームは通常、このドキュメントで説明するように、一元管理されるセルフサービス データ プラットフォームを作成します。このチームは、ドメインチーム(データ プロデューサーとデータ コンシューマの両方)がデータ プロダクトの作成と使用の両方に使用できるソリューションとコンポーネントを構築します。ドメインチームは、データメッシュの機能部分を表しています。これらのコンポーネントを構築することで、データ プラットフォーム チームは開発をスムーズに行うことができ、安全で相互運用可能なデータ プロダクトを構築、デプロイ、維持する際の複雑さが軽減されます。
最終的に、データ プラットフォーム チームはドメインチームの作業の迅速化を可能にする必要があります。ニーズを満たすための限定されたツールセットをチームに提供することで、ドメインチームの効率を高めます。これらのツールを提供することで、データ プラットフォーム チームは、これらのツールを自ら構築して提供する負担からドメインチームを解放します。ツールの選択はさまざまなニーズに応じてカスタマイズ可能でなければならず、データドメイン チームへの柔軟性のない対応を行わせるべきではありません。
データ プラットフォーム チームは、データ パイプライン オーケストレーターや、継続的インテグレーション / 継続的デプロイ(CI / CD)システムのカスタム ソリューションの構築に重点を置くべきではありません。CI / CD システムなどのソリューションは、Cloud Build などのマネージド クラウド サービスとして直ちに利用を開始できます。マネージド クラウド サービスを使用すると、データ プラットフォーム チームの運用オーバーヘッドが削減され、プラットフォームのユーザーとしてのデータドメイン チームの特定のニーズに注力できます。運用オーバーヘッドが削減されるため、データ プラットフォーム チームはデータドメイン チームの特定のニーズに対応することにより多くの時間を割くことができます。
アーキテクチャ
次の図は、セルフサービス データ プラットフォームのアーキテクチャ コンポーネントを示しています。この図は、データメッシュ全体でデータ プロダクトを開発して使用するチームを、これらのコンポーネントがどのようにサポートするかも示しています。

上の図に示すように、セルフサービス データ プラットフォームには次のものが用意されています。
プラットフォーム ソリューション: これらのソリューションは、 Google Cloud のプロジェクトとリソースをプロビジョニングするための組み立て可能なコンポーネントで構成されます。これらのコンポーネントは、ユーザーが特定の要件を満たすために異なる組み合わせを選択して組み立てます。プラットフォームのユーザーは、コンポーネントを直接操作するのではなく、プラットフォーム ソリューションを操作して、特定の目標を達成できます。データドメイン チームは、データ プロダクトの開発と使用に時間がかかる一般的な問題と軋轢のある領域を解決するプラットフォーム ソリューションを設計する必要があります。たとえば、データメッシュにオンボーディングを行うデータドメイン チームは、Infrastructure as Code(IaC)テンプレートを使用できます。IaC テンプレートを使用すると、標準の Identity and Access Management(IAM)権限、ネットワーク、セキュリティ ポリシー、およびデータ プロダクト開発用に有効化された関連 Google CloudAPIs を使用して、Google Cloud プロジェクトをすばやく作成できます。各ソリューションに、「開始方法」のガイダンスやコードサンプルなどのドキュメントを用意することをおすすめします。データ プラットフォーム ソリューションとそれらのコンポーネントは、デフォルトで安全であり、コンプライアンスを遵守する必要があります。
共通サービス: これらのサービスは、データ プロダクトの検出、管理、共有を可能にし、オブザーバビリティをもたらします。これらのサービスは、データ プロダクトに対するデータ利用者の信頼を促進するものであり、データ プロデューサーがデータ製品の問題に対してアラートを送信できる効果的な方法です。
データ プラットフォーム ソリューションと一般的なサービスには、次のようなものがあります。
- 基本的なデータ プロダクト開発ワークスペース環境を設定するための IaC テンプレート。これには以下のものが含まれます。
- IAM
- ロギングとモニタリング
- ネットワーキング
- セキュリティとコンプライアンスのガードレール
- 課金アトリビューションのためのリソースのタグ付け
- データ プロダクトの保存、変換、公開
- データ プロダクトの登録、カタログ化、メタデータのタグ付け
- 組織のセキュリティ ガードレールとベスト プラクティスに従う IaC テンプレート。 Google Cloud リソースを既存のデータ プロダクト開発ワークスペースにデプロイする際に使用できます。
- 新しいプロジェクトをブートストラップするために使用できる、または既存のプロジェクトのリファレンスとして使用できるアプリケーションとデータ パイプラインのテンプレート。このようなテンプレートの例を以下に示します。
- 共通のライブラリとフレームワークの使用
- プラットフォームのロギング、モニタリング、オブザーバビリティ ツールとの統合
- ツールの構築とテスト
- 構成管理
- デプロイのためのパッケージ化と CI / CD パイプライン
- 認証情報の認証、デプロイ、管理
- データ プロダクトのオブザーバビリティとガバナンスを提供するための一般的なサービス。次のようなものがあります。
- データ プロダクトの全体的な状態を表示する稼働時間チェック。
- データ プロダクトに関する有用なインジケーターを提供するカスタム指標。
- 一元管理を担うチームによる運用サポート。データ コンシューマ チームが、使用するデータ プロダクトの変更に関する通知を受け取れるようにします。
- データ プロダクトのパフォーマンスを表示するデータ スコアカード。
- データ プロダクトを検出するためのメタデータ カタログ。
- データメッシュ全体にグローバルに適用できる、一元的に定義された一連のコンピューティング ポリシー。
- ドメインチーム間でのデータ共有を促進するデータ マーケットプレイス。
IaC テンプレートを使用してプラットフォーム コンポーネントとソリューションを作成するでは、データ プロダクトを公開してデプロイするための IaC テンプレートの利点について説明しています。共通サービスを提供するでは、データ プラットフォーム チームによって構築および管理される共通のインフラストラクチャ コンポーネントをドメインチームに提供することが有用な理由について説明します。
IaC テンプレートを使用してプラットフォーム コンポーネントとソリューションを作成する
データ プラットフォーム チームの目標は、セルフサービス データ プラットフォームをセットアップして、データからより多くの価値を引き出すことです。これらのプラットフォームを構築するために、検証済みの安全かつセルフサービス可能なインフラストラクチャ テンプレートを作成し、ドメインチームに提供します。ドメインチームは、これらのテンプレートを使用してデータ開発環境とデータ使用環境をデプロイします。IaC テンプレートは、データ プラットフォーム チームがこの目標を達成し、スケーリングを可能にすることを支援します。検証済みの信頼できる IaC テンプレートを使用すると、ドメインチームが既存の CI / CD パイプラインを再利用できるため、リソース デプロイ プロセスが簡素化されます。このアプローチにより、ドメインチームは直ちにデータメッシュの使用を開始し、データメッシュ内で生産性を高めることができます。
IaC テンプレートは IaC ツールを使用して作成できます。Cloud Config Connector、Pulumi、Chef、Ansible などの IaC ツールがありますが、このドキュメントでは、Terraform ベースの IaC ツールの例を示します。Terraform は、データ プラットフォーム チームがGoogle Cloud リソース用の組み立て可能なプラットフォーム コンポーネントやソリューションを効率的に作成できるようにする、オープンソースの IaC ツールです。データ プラットフォーム チームは Terraform を使用して選択された最終状態を指定するコードを記述し、その状態を実現する方法をツールに認識させます。この宣言型アプローチにより、データ プラットフォーム チームはインフラストラクチャ リソースを環境間でのデプロイ用の不変のアーティファクトとして扱うことができます。また、デプロイされたリソースとソース管理で宣言されたコードとの間に生じる不整合(構成のずれと呼ばれます)のリスクを軽減することもできます。インフラストラクチャのアドホックと手動の変更によって発生する構成のずれにより、本番環境への IaC コンポーネントの安全な繰り返しのデプロイが妨げられます。
組み立て可能なプラットフォーム コンポーネントの一般的な IaC テンプレートには、BigQuery データセット、Cloud Storage バケット、Cloud SQL データベースなどのリソースをデプロイするための Terraform モジュールの使用が含まれます。Terraform モジュールをエンドツーエンドのソリューションと組み合わせて、完全な Google Cloud プロジェクト(組み立て可能なモジュールを使用してデプロイされる、関連するリソースなど)をデプロイできます。Terraform モジュールの例については、 Google Cloudの Terraform ブループリントをご覧ください。
各 Terraform モジュールは、組織で使用するセキュリティ ガードレールとコンプライアンス ポリシーをデフォルトで満たす必要があります。これらのガードレールとポリシーはコードとして表現し、 Google Cloudのポリシー検証ツールなどの自動化されたコンプライアンス検証ツールを使用して自動化することもできます。
組織は、本番環境への変更の昇格に使用するものと同じ自動コンプライアンス ガードレールを使用して、プラットフォームが提供する Terraform モジュールを継続的にテストする必要があります。
Terraform の経験がほとんどないドメインチームが IaC コンポーネントとソリューションを検出、使用できるように、サービス カタログなどのサービスを使用することをおすすめします。重要なカスタマイズ要件を持つユーザーは、既存のソリューションで使用されているものと同じ組み立て可能な Terraform テンプレートから独自のデプロイ ソリューションを作成できるようにする必要があります。
Terraform を使用する場合は、Terraform の使用に関するベスト プラクティスで概説されている Google Cloudのベスト プラクティスに従うことをおすすめします。
Terraform を使用してプラットフォーム コンポーネントを作成する方法を説明するために、以降のセクションでは、Terraform を使用して消費インターフェースを公開し、データ プロダクトを使用する例について説明します。
消費インターフェースを公開する
データ プロダクトの消費インターフェースとは、他のチームが自分のデータ プロダクトを発見して使用できるように、データ ドメインチームが提供するデータ品質と運用パラメータに関する一連の保証です。各消費インターフェースには、プロダクトのサポートモデルとプロダクト ドキュメントも含まれています。データメッシュでデータ プロダクトを構築するで説明しているように、データ プロダクトでは、API やストリームなど、さまざまなタイプの消費インターフェースを使用できます。最も一般的な消費インターフェースは、BigQuery の承認済みデータセット、承認済みビュー、または承認済み関数です。このインターフェースは読み取り専用の仮想テーブルを公開します。これは、データメッシュへのクエリとして表現されます。このインターフェースでは、基盤となるデータに直接アクセスするための読み取り権限が付与されません。
Google は、基盤となる承認済みデータセットに対する権限をチームに付与せずに、承認済みビューを作成するための Terraform モジュールの例を示しています。この Terraform モジュールの次のコードは、dataset_id 承認済みビューに対するこれらの IAM 権限を付与します。
module "add_authorization" {
source = "terraform-google-modules/bigquery/google//modules/authorization"
version = "~> 4.1"
dataset_id = module.dataset.bigquery_dataset.dataset_id
project_id = module.dataset.bigquery_dataset.project
roles = [
{
role = "roles/bigquery.dataEditor"
group_by_email = "ops@mycompany.com"
}
]
authorized_views = [
{
project_id = "view_project"
dataset_id = "view_dataset"
table_id = "view_id"
}
]
authorized_datasets = [
{
project_id = "auth_dataset_project"
dataset_id = "auth_dataset"
}
]
}
複数のビューへのアクセス権をユーザーに付与する必要がある場合、承認済みビューごとにアクセス権を付与することは、多くの時間を要しメンテナンスもより困難になります。複数の承認済みビューを作成する代わりに、承認済みデータセットを使用して、承認済みデータセット内で作成されたビューを自動的に承認できます。
データ プロダクトを使用する
ほとんどの分析のユースケースでは、消費パターンは、データが使用されているアプリケーションによって決定されます。一元管理された消費環境の主な用途は、消費中のアプリケーション内でデータが使用される前のデータ探索です。データメッシュでプロダクトを検出して使用するで説明したように、SQL は、データ プロダクトをクエリするのに最も頻繁に使用される方法です。このため、データ プラットフォームでは、データ コンシューマがデータを探索するための SQL アプリケーションを提供する必要があります。
分析のユースケースによっては、Terraform を使用してデータ コンシューマ用の消費環境をデプロイできます。たとえば、データ サイエンスはデータ コンシューマの一般的なユースケースです。Terraform を使用すると、Vertex AI のユーザー管理ノートブックをデプロイし、データ サイエンス開発環境として使用できます。データ コンシューマは、データ サイエンス ノートブックで認証情報を使用してデータメッシュにログインし、アクセス可能なデータを探索して、このデータに基づいて ML モデルを開発できます。
Terraform を使用して Google Cloudにノートブック環境をデプロイして保護する方法については、企業で生成 AI モデルと ML モデルを構築してデプロイするをご覧ください。
共通サービスを提供する
データ プラットフォーム チームは、セルフサービスの IaC コンポーネントとソリューションに加えて、複数のデータドメイン チームが使用する共通の共有プラットフォーム サービスの構築と運用も担当することになる場合があります。共有プラットフォーム サービスの一般的な例としては、ビジネス インテリジェンス可視化ツールや Kafka クラスタなど、自己ホスト型のサードパーティ ソフトウェアがあります。 Google Cloudでは、データ プラットフォーム チームがデータドメイン チームに代わって Dataplex Universal Catalog シンクや Cloud Logging シンクなどのリソースを管理する場合があります。データドメイン チームのリソースを管理することで、データ プラットフォーム チームは組織全体で一元化されたポリシー管理と監査の実施を促進できます。
以降のセクションでは、Dataplex Universal Catalog を使用して Google Cloudのデータメッシュ内で一元管理とガバナンスを行う方法と、データメッシュにデータ オブザーバビリティ機能を実装する方法について説明します。
データ ガバナンスのための Dataplex Universal Catalog
Dataplex Universal Catalog は、組織全体にわたり存在するデータメッシュ内の独立したデータドメインの構築に役立つデータ管理プラットフォームを提供します。Dataplex Universal Catalog を使用すると、ドメイン全体のデータのガバナンスとモニタリングを一元管理できます。
Dataplex Universal Catalog を使用すると、組織はデータ(サポートされるデータソース)と関連するアーティファクト(コード、ノートブック、ログなど)を、データドメインを表す Dataplex Universal Catalog レイクに論理的に編成できます。次の図では、セールス ドメインが Dataplex Universal Catalog を使用してデータ品質の指標やログなどのアセットを Dataplex Universal Catalog ゾーンに整理しています。
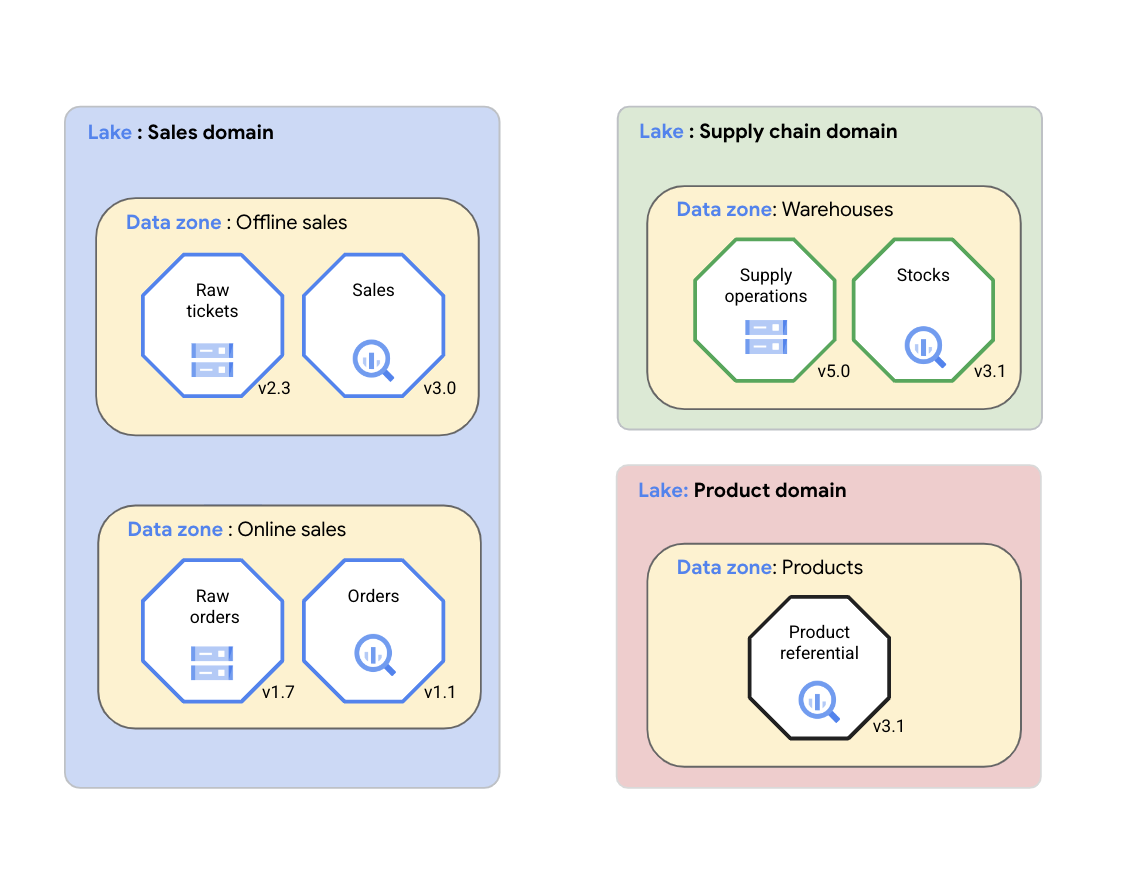
上の図に示すように、Dataplex Universal Catalog を使用すると、次のアセット間でドメインデータを管理できます。
- Dataplex Universal Catalog を使用すると、データドメイン チームは Dataplex Universal Catalog レイクと呼ばれる論理グループでデータアセットを一貫して管理できます。データドメイン チームは、データを物理的に移動する、または単一のストレージ システムに保存することなく、同じ Dataplex Universal Catalog レイク内で Dataplex Universal Catalog アセットを整理できます。Dataplex Universal Catalog アセットは、Dataplex Universal Catalog レイクを含むGoogle Cloud プロジェクト以外の、複数の Google Cloud プロジェクトに保存されている Cloud Storage バケットと BigQuery データセットを参照できます。Dataplex Universal Catalog アセットは、構造化、非構造化できます。または、分析データレイクやデータ ウェアハウスに保存することもできます。この図には、セールス ドメイン、サプライ チェーン ドメイン、プロダクト ドメインのデータレイクがあります。
- Dataplex Universal Catalog ゾーンを使用すると、データドメイン チームはデータアセットを同じ Dataplex Universal Catalog レイク内の小さなサブグループに整理し、サブグループの重要な側面をキャプチャする構造を追加できます。たとえば、Dataplex Universal Catalog ゾーンを使用して、データ プロダクト内の関連するデータアセットをグループ化できます。データアセットを単一の Dataplex Universal Catalog ゾーンにグループ化することで、データドメイン チームは、単一のデータ プロダクトとして、ゾーン全体でアクセス ポリシーとデータ ガバナンス ポリシーを一貫して管理できます。この図には、オフライン販売、オンライン販売、サプライ チェーンの倉庫、プロダクトのデータゾーンがあります。
Dataplex Universal Catalog レイクとゾーンを使用すると、組織は分散データを統合し、ビジネス コンテキストに基づいて整理できます。この配置により、メタデータの管理、ガバナンス ポリシーの設定、データ品質のモニタリングなどのアクティビティの基盤が形成されます。このようなアクティビティにより、組織は分散データを大規模に(データメッシュなどで)管理できます。
データのオブザーバビリティ
各データドメインには、独自のモニタリングとアラートのメカニズムを実装する必要があります。その際には、標準化されたアプローチを使用することをおすすめします。各ドメインでは、サービス モニタリングのコンセプトで説明されているモニタリング手法を適用して、データドメインに必要な調整を加えることができます。オブザーバビリティは大きなトピックであるため、このドキュメントでは扱いません。このセクションでは、データメッシュの実装に役立つパターンについてのみ説明します。
複数のデータ コンシューマがあるプロダクトの場合は、プロダクトのステータスに関する情報を各コンシューマにタイムリーに提供することが、運用の負担になる可能性があります。一般に、手動で管理するメール配信などの基本ソリューションでは、エラーが発生しやすくなります。これは、計画された停止、今後のプロダクト リリース、非推奨化をユーザーに知らせるのに役立ちますが、リアルタイムの運用上の案内は提供しません。
一元管理されたサービスは、データメッシュ内のプロダクトの状態と品質をモニタリングするうえで重要な役割を果たします。オブザーバビリティ機能を実装することは、データメッシュの実装が成功するための前提条件ではありませんが、実装によりデータ プロデューサーとコンシューマの満足度が向上し、運用とサポートの全体的な費用を削減できます。次の図は、Cloud Monitoring に基づくデータメッシュ オブザーバビリティのアーキテクチャを示しています。

以降のセクションでは、この図に示されたコンポーネントについて説明します。
- データ プロダクトの全体的な状態を表示する稼働時間チェック。
- データ プロダクトに関する有用なインジケーターを提供するカスタム指標。
- 一元管理を担うデータ プラットフォーム チームによる運用サポート。データ コンシューマに、使用するデータ プロダクトの変更に関する通知を表示します。
- データ プロダクトのパフォーマンスを示すプロダクト スコアカードとダッシュボード。
稼働時間チェック
データ プロダクトでは、稼働時間チェックを実装するシンプルなカスタム アプリケーションを作成できます。これらのチェックは、プロダクトの全体的な状態を表す大まかな指標として使用できます。たとえば、データ プロダクト チームがプロダクトのデータ品質の急激な低下を発見した場合に、対象のプロダクトを異常としてマークできます。ニア リアルタイムの稼働時間チェックは、アップストリームのデータ プロダクトで常に利用できるデータを必要とするプロダクトを派生させたデータ コンシューマにとって、特に重要です。データ プロデューサーは、アップストリームの依存関係を確認することで、データ コンシューマにプロダクトの健全性を正確に示すために、稼働時間チェックを構築する必要があります。
データ コンシューマは、製品の稼働時間チェックをその処理に含めることができます。たとえば、データ プロダクトから提供されたデータに基づいてレポートを生成する composer ジョブでは、最初のステップとして、プロダクトのステータスが「実行中」であるかどうかを検証できます。稼働時間チェック アプリケーションでは、HTTP レスポンスのメッセージ本文に構造化ペイロードを返すことをおすすめします。この構造化ペイロードは、問題の有無、人が読める形式の問題の根本原因、そして可能であればサービスを復元する推定時間を示す必要があります。この構造化ペイロードでは、プロダクトの状態に関する、より詳細な情報も取得できます。たとえば、プロダクトとして公開された承認済みデータセット内の各ビューの健全性情報を含めることができます。
カスタム指標
データ プロダクトには、有用性を測定するためのさまざまなカスタム指標を用意できます。データ プロデューサー チームは、これらのカスタム指標を、指定されたドメイン固有の Google Cloud プロジェクトにパブリッシュできます。すべてのデータ プロダクトで統合されたモニタリング エクスペリエンスを実現するため、一元管理されたデータメッシュ モニタリング プロジェクトにドメイン固有のプロジェクトへのアクセス権を付与できます。
データ プロダクト消費インターフェースの種類ごとに、有用性を測定するためのさまざまな指標を指定できます。指標はビジネス ドメインに固有の場合もあります。たとえば、ビューまたは Storage Read API を介して公開される BigQuery テーブルの指標は次のようになります。
- 行数。
- データの鮮度(測定時間の秒数で表します)。
- データ品質スコア。
- 利用可能なデータ。この指標は、データがクエリ可能であることを示している可能性があります。あるいは、このドキュメントで前述した稼働時間チェックを使用する方法もあります。
これらの指標は、特定のプロダクトのサービスレベル指標(SLI)として表示できます。
データ ストリーム(Pub/Sub トピックとして実装)の場合、このリストは、トピックを通じて使用可能な標準の Pub/Sub 指標にできます。
一元管理を担うデータ プラットフォーム チームによる運用サポート
中央のデータ プラットフォーム チームは、カスタム ダッシュボードを公開して、データ コンシューマにさまざまな詳細を表示できます。データメッシュ内のプロダクトと、それらのプロダクトの稼働時間ステータスを一覧表示するシンプルなステータス ダッシュボードにより、複数のエンドユーザーの要求に対応できます。
一元管理を担うチームは、データ コンシューマに、使用するデータ プロダクトでのさまざまなイベントついて通知する通知配信ハブとしても機能できます。通常、このハブはアラート ポリシーを作成することで作成されます。この機能を一元化すると、各データ プロデューサー チームが行う必要がある作業を減らすことができます。これらのポリシーを作成するうえでデータドメインに関する知識は必要ないため、データ消費のボトルネックを回避できます。
データメッシュ モニタリングの理想的な最終状態は、データ プロダクトのタグ テンプレートが、プロダクトが利用可能になったときに、プロダクトがサポートする SLI とサービスレベル目標(SLO)を公開することです。一元管理を担うチームは、Monitoring API とサービスのモニタリングを使用して、対応するアラートを自動的にデプロイできます。
プロダクト スコアカード
中央ガバナンス契約の一部として、データメッシュの 4 つの機能でデータ プロダクトのスコアカードを作成するための条件を定義できます。これらのスコアカードは、データ プロダクトのパフォーマンスの客観的な測定値として使用できます。
スコアカードの計算に使用される変数の多くは、データ プロダクトが SLO を満たしている時間の割合です。有用な条件には、稼働率、データ品質スコアの平均、データの鮮度がしきい値を下回っているプロダクトの割合があります。Prometheus Query Language(PromQL)を使用してこれらの指標を自動的に計算するには、カスタム指標と、一元管理されたモニタリング プロジェクトでの稼働時間チェックの結果で十分です。
次のステップ
- BigQuery の詳細を確認する。
- Dataplex について読む。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。