このドキュメントでは、Google Cloudで R を使用して大規模なデータ サイエンスを始める方法について説明します。このチュートリアルは、R および Jupyter ノートブックの使用経験があり、SQL に関して精通している方を対象としています。
このドキュメントでは、Vertex AI Workbench インスタンスと BigQuery を使用した探索的データ分析に重点を置いて説明します。説明で使用するコードは、GitHub 上の Jupyter ノートブックにあります。
概要
R は、統計モデルで最も広く使用されるプログラミング言語の 1 つです。R には、データ サイエンティストと機械学習(ML)の専門家が参加する大規模で活発なコミュニティがあります。Comprehensive R Archive Network(CRAN)のオープンソース リポジトリには 20,000 を超えるパッケージがあり、R には、あらゆる統計的データ分析アプリケーション、ML、可視化のためのツールが用意されています。構文の豊富さと、データと ML ライブラリが包括的であるという理由から、R はこの 20 年で着実に成長してきています。
データ サイエンティストは、R を使用してどのように自身のスキルセットを活かせるか、データ サイエンティスト向けのスケーラブルなフルマネージド型クラウド サービスの利点をどのように活用できるかを知りたいことでしょう。
アーキテクチャ
このチュートリアルでは、Vertex AI Workbench インスタンスをデータ サイエンス環境として使用して、探索的データ分析(EDA)を実行します。このチュートリアルでは、Google のスケーラビリティと費用対効果に優れたサーバーレス クラウド データ ウェアハウスである BigQuery から抽出したデータに対して R を使用します。データの分析と処理が完了すると、変換されたデータは Cloud Storage に保存され、以降の ML タスクに使用されます。以下の図は、このフローを示しています。

データの例
このドキュメントのサンプルデータは、BigQuery のニューヨーク市タクシー乗車データセットです。この一般公開データセットには、ニューヨーク市で毎年行われる数百万件のタクシー乗車に関する情報が含まれています。このドキュメントでは、BigQuery の bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022 テーブルにある 2022 年のデータを使用します。
このドキュメントでは、EDA と、R および BigQuery を使用した可視化に重点を置きます。このドキュメントのステップでは、乗車に関するさまざまな要素に基づいて、タクシー運賃の金額(税金、手数料、その他の追加料金前の金額)を予測する ML 目標を設定します。実際のモデルの作成については、このドキュメントでは説明しません。
Vertex AI Workbench
Vertex AI Workbench は、統合された JupyterLab 環境を提供するサービスです。次の機能を備えています。
- ワンクリック デプロイ。ワンクリックで、最新の機械学習フレームワークとデータ サイエンス フレームワークを使用して事前構成された JupyterLab インスタンスを起動できます。
- オンデマンドのスケーリング。小規模なマシン構成(たとえば、このドキュメントに示す 4 つの vCPU と 16 GB の RAM)から開始できます。データのサイズが 1 台のマシンで扱うには過大になった場合は、CPU、RAM、GPU を追加することでスケールアップできます。
- Google Cloud インテグレーション。Vertex AI Workbench インスタンスは、BigQuery などの Google Cloud サービスと統合されています。この統合により、データの取り込みから前処理、探索を容易に行うことができます。
- 従量課金。最低料金や事前の契約はありません。詳細については、Vertex AI Workbench の料金をご覧ください。また、ノートブックで使用する Google Cloud リソース(BigQuery や Cloud Storage など)の料金も発生します。
Vertex AI Workbench インスタンス ノートブックは、Deep Learning VM Image で実行されます。このドキュメントでは、R 4.3 を搭載した Vertex AI Workbench インスタンスの作成をサポートしています。
R を使用して BigQuery を操作する
BigQuery ではインフラストラクチャ管理が不要なため、有意な分析情報の発見に集中できます。BigQuery の豊富な SQL 分析機能を使用して、大量のデータを大規模に分析し、ML 用のデータセットを準備できます。
R を使用して BigQuery データをクエリするには、オープンソースの R ライブラリである bigrquery を使用します。bigrquery パッケージは、BigQuery の上に次の抽象化レベルを設定します。
- 低レベル API には、基盤となる BigQuery REST API の上にシンラッパーが用意されています。
- DBI インターフェースは、低レベル API をラップし、BigQuery を他のデータベース システムと同じように操作できるようにします。これは、BigQuery で SQL クエリを行う場合や、100 MB 未満のアップロードを行う場合に最も有用なレイヤです。
- dbplyr インターフェースを使用すると、BigQuery テーブルを、メモリ内データフレームと同様に処理できます。これは、SQL の作成を回避しつつ、dbplyr による自動書き込みを設定する場合に最も有用なレイヤです。
このドキュメントでは、DBI や dbplyr を必要としない bigrquery の低レベル API を使用します。
目標
- R をサポートする Vertex AI Workbench インスタンスを作成する。
- bigrquery R ライブラリを使用して、BigQuery のデータをクエリおよび分析する。
- Cloud Storage で ML 用のデータを準備し、保存する。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
- BigQuery
- Vertex AI Workbench instances. You are also charged for resources used within notebooks, including compute resources, BigQuery, and API requests.
- Cloud Storage
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Google Cloud コンソールで [ワークベンチ] ページに移動します。
[インスタンス] タブで、 [新規作成] をクリックします。
[新しいインスタンス] ウィンドウで、[作成] をクリックします。このチュートリアルでは、すべてのデフォルト値をそのまま使用します。
Vertex AI Workbench インスタンスの起動には 2~3 分かかることがあります。準備が整うと、インスタンスが [ノートブック インスタンス] ペインに自動的に表示され、インスタンス名の横に [JupyterLab を開く] リンクが表示されます。数分経っても [JupyterLab を開く] リンクがリストに表示されない場合は、ページを更新します。
インスタンスのリストで [JupyterLab を開く] をクリックします。これにより、ブラウザの別のタブで JupyterLab 環境が開きます。
JupyterLab 環境で [New Launcher] をクリックし、[Launcher] タブで [Terminal] をクリックします。
ターミナル ペインで、R をインストールします。
conda create -n r conda activate r conda install -c r r-essentials r-base=4.3.2インストール中に、続行を求めるメッセージが表示されるたびに「
y」と入力します。インストールが完了するまでに数分かかることがあります。インストールが完了すると、出力は次のようになります。done Executing transaction: done ® jupyter@instance-INSTANCE_NUMBER:~$ここで、INSTANCE_NUMBER は Vertex AI Workbench インスタンスに割り当てられた一意の数値です。
ターミナルでコマンドの実行が完了したら、ブラウザページを更新し、[ New Launcher] をクリックしてランチャーを開きます。
[Launcher] タブには、ノートブックまたはコンソールで R を起動したり、R ファイルを作成するためのオプションが表示されます。
[Terminal] タブをクリックし、vertex-ai-samples GitHub リポジトリのクローンを作成します。
git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.gitコマンドが完了すると、JupyterLab 環境のファイル ブラウザ ペインに
vertex-ai-samplesフォルダが表示されます。ファイル ブラウザで、
vertex-ai-samples>notebooks>community>exploratory_data_analysisを開きます。eda_with_r_and_bigquery.ipynbノートブックが表示されます。ファイル ブラウザで、
eda_with_r_and_bigquery.ipynbノートブックを開きます。このノートブックでは、R と BigQuery を使用した探索的データ分析について説明します。このドキュメントの残りの部分では、ノートブックで作業し、Jupyter ノートブック内に表示されるコードを実行します。
ノートブックで使用している R のバージョンを確認します。
version出力の
version.stringフィールドに、前のセクションでインストールしたR version 4.3.2が表示されます。現在のセッションでまだ使用できない場合は、必要な R パッケージを確認してインストールします
# List the necessary packages needed_packages <- c("dplyr", "ggplot2", "bigrquery") # Check if packages are installed installed_packages <- .packages(all.available = TRUE) missing_packages <- needed_packages[!(needed_packages %in% installed_packages)] # If any packages are missing, install them if (length(missing_packages) > 0) { install.packages(missing_packages) }必要なパッケージを読み込みます。
# Load the required packages lapply(needed_packages, library, character.only = TRUE)帯域外認証を使用して
bigrqueryを認証します。bq_auth(use_oob = True)このノートブックで使用するプロジェクトの名前を設定します。
[YOUR-PROJECT-ID]は、プロジェクトの名前に置き換えます。# Set the project ID PROJECT_ID <- "[YOUR-PROJECT-ID]"出力データを保存する Cloud Storage バケットの名前を設定します。
[YOUR-BUCKET-NAME]は、グローバルに一意の名前に置き換えます。BUCKET_NAME <- "[YOUR-BUCKET-NAME]"ノートブックで後で生成されるプロットのデフォルトの高さと幅を設定します。
options(repr.plot.height = 9, repr.plot.width = 16)乗車データのサンプルについて、予測子の候補とターゲット予測変数をいくつか抽出する BigQuery SQL ステートメントを作成します。次のクエリは、分析のために読み込まれているフィールド内の外れ値や意味のない値を除外します。
sql_query_template <- " SELECT TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes, passenger_count, ROUND(trip_distance, 1) AS trip_distance_miles, rate_code, /* Mapping from rate code to type from description column in BigQuery table schema */ (CASE WHEN rate_code = '1.0' THEN 'Standard rate' WHEN rate_code = '2.0' THEN 'JFK' WHEN rate_code = '3.0' THEN 'Newark' WHEN rate_code = '4.0' THEN 'Nassau or Westchester' WHEN rate_code = '5.0' THEN 'Negotiated fare' WHEN rate_code = '6.0' THEN 'Group ride' /* Several NULL AND some '99.0' values go here */ ELSE 'Unknown' END) AS rate_type, fare_amount, CAST(ABS(FARM_FINGERPRINT( CONCAT( CAST(trip_distance AS STRING), CAST(fare_amount AS STRING) ) )) AS STRING) AS key FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` /* Filter out some outlier or hard to understand values */ WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) LIMIT %s "key列は、trip_distanceとfare_amount列の連結された値に基づいて生成された行識別子です。クエリを実行し、データフレームのようなメモリ内 tibble として同じデータを取得します。
sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) taxi_trip_data <- bq_table_download( bq_project_query( PROJECT_ID, query = sql_query ) )取得した結果を表示します。
head(taxi_trip_data)出力は、次の画像のような表になります。
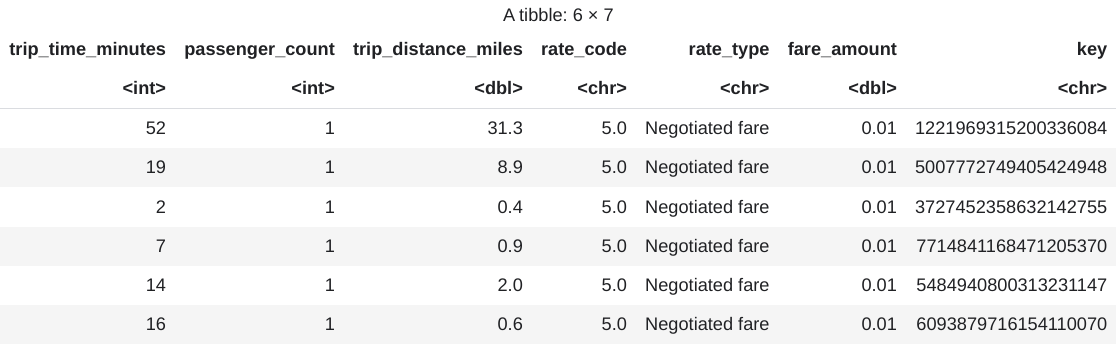
結果には、次の列の乗車データが表示されます。
trip_time_minutes整数passenger_count整数trip_distance_miles倍精度rate_code文字rate_type文字fare_amount倍精度key文字
行数と各列のデータ型を表示します。
str(taxi_trip_data)出力は次のようになります。
tibble [10,000 x 7] (S3: tbl_df/tbl/data.frame) $ trip_time_minutes : int [1:10000] 52 19 2 7 14 16 1 2 2 6 ... $ passenger_count : int [1:10000] 1 1 1 1 1 1 1 1 3 1 ... $ trip_distance_miles: num [1:10000] 31.3 8.9 0.4 0.9 2 0.6 1.7 0.4 0.5 0.2 ... $ rate_code : chr [1:10000] "5.0" "5.0" "5.0" "5.0" ... $ rate_type : chr [1:10000] "Negotiated fare" "Negotiated fare" "Negotiated fare" "Negotiated fare" ... $ fare_amount : num [1:10000] 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 ... $ key : chr [1:10000] "1221969315200336084" 5007772749405424948" "3727452358632142755" "77714841168471205370" ...取得したデータの概要を表示します。
summary(taxi_trip_data)出力は次のようになります。
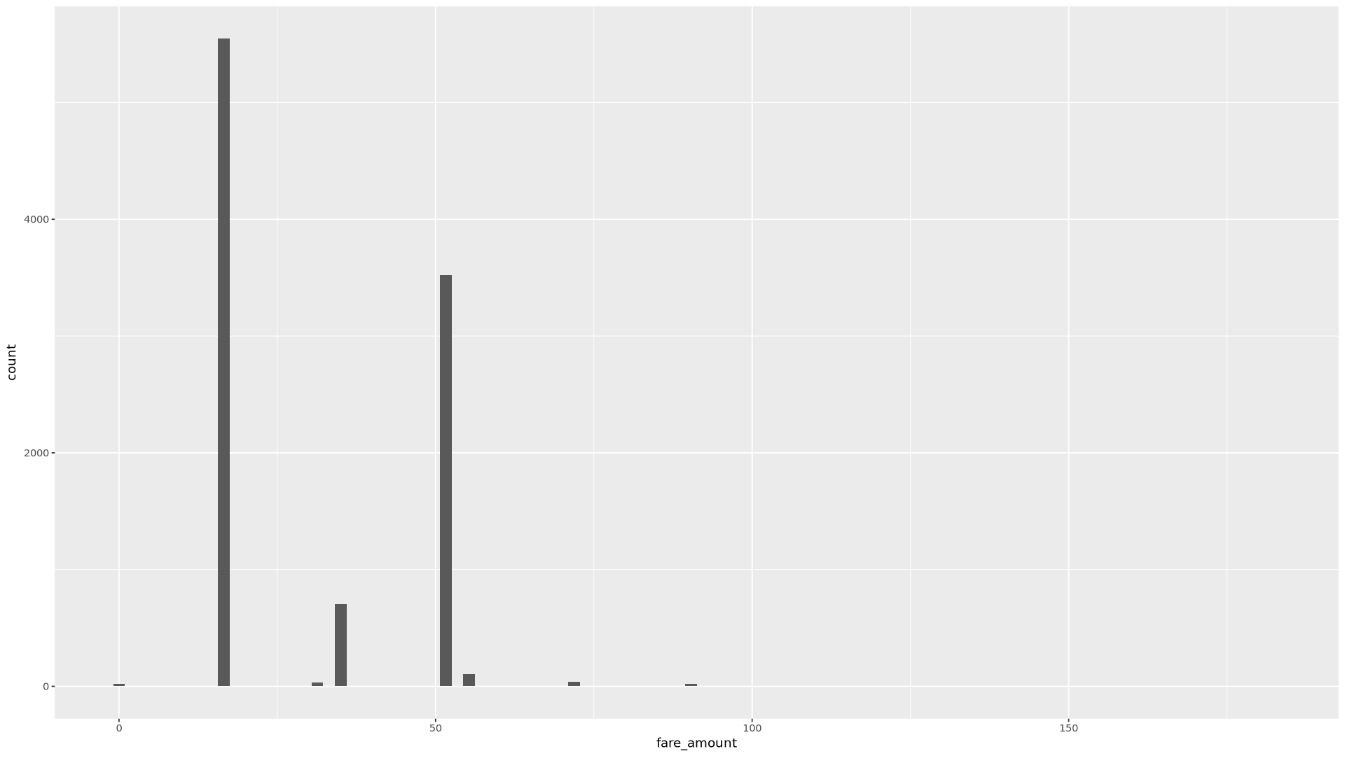
trip_time_minutes passenger_count trip_distance_miles rate_code Min. : 1.00 Min. :1.000 Min. : 0.000 Length:10000 1st Qu.: 20.00 1st Qu.:1.000 1st Qu.: 3.700 Class :character Median : 24.00 Median :1.000 Median : 4.800 Mode :character Mean : 30.32 Mean :1.465 Mean : 9.639 3rd Qu.: 39.00 3rd Qu.:2.000 3rd Qu.:17.600 Max. :120.00 Max. :9.000 Max. :43.700 rate_type fare_amount key Length:10000 Min. : 0.01 Length:10000 Class :character 1st Qu.: 16.50 Class :character Mode :character Median : 16.50 Mode :character Mean : 31.22 3rd Qu.: 52.00 Max. :182.50ヒストグラムを使用して
fare_amount値の分布を表示します。ggplot( data = taxi_trip_data, aes(x = fare_amount) ) + geom_histogram(bins = 100)結果のプロットは次の画像のグラフのようになります。
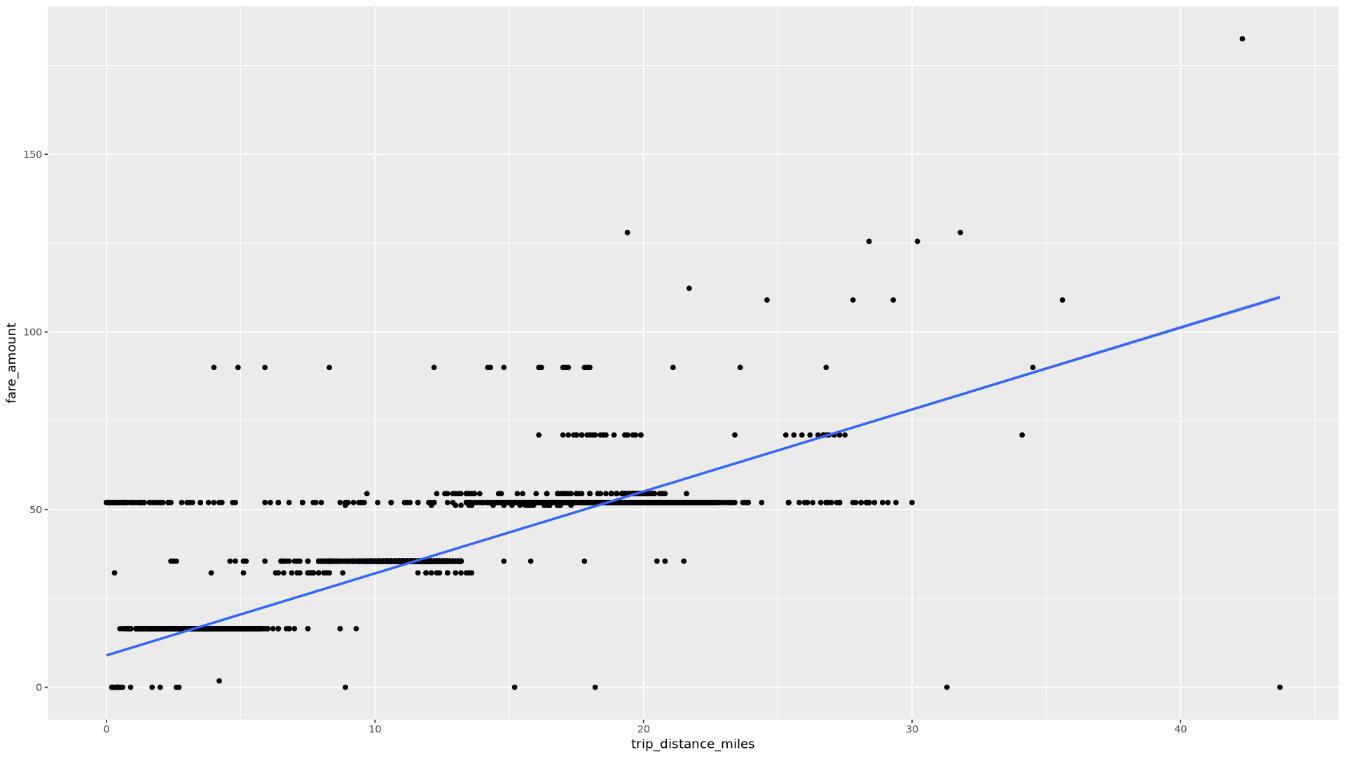
散布図を使用して
trip_distanceとfare_amountの関係を表示します。ggplot( data = taxi_trip_data, aes(x = trip_distance_miles, y = fare_amount) ) + geom_point() + geom_smooth(method = "lm")結果のプロットは次の画像のグラフのようになります。
ノートブックで、選択した列の各値に対する乗車回数と平均運賃額を検出する関数を作成します。
get_distinct_value_aggregates <- function(column) { query <- paste0( 'SELECT ', column, ', COUNT(1) AS num_trips, AVG(fare_amount) AS avg_fare_amount FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) GROUP BY 1 ' ) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }BigQuery のタイムスタンプ機能を使用して、定義された
trip_time_minutes列を使用して関数を呼び出します。df <- get_distinct_value_aggregates( 'TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes') ggplot( data = df, aes(x = trip_time_minutes, y = num_trips) ) + geom_line() ggplot( data = df, aes(x = trip_time_minutes, y = avg_fare_amount) ) + geom_line()ノートブックには 2 つのグラフが表示されます。最初のグラフは、乗車時間(分単位)ごとの乗車回数を示しています。2 つ目のグラフは、乗車時間別の乗車の平均運賃額を示しています。
最初の
ggplotコマンドの出力は次のようになります。これは、乗車時間(分単位)別の乗車回数を示しています。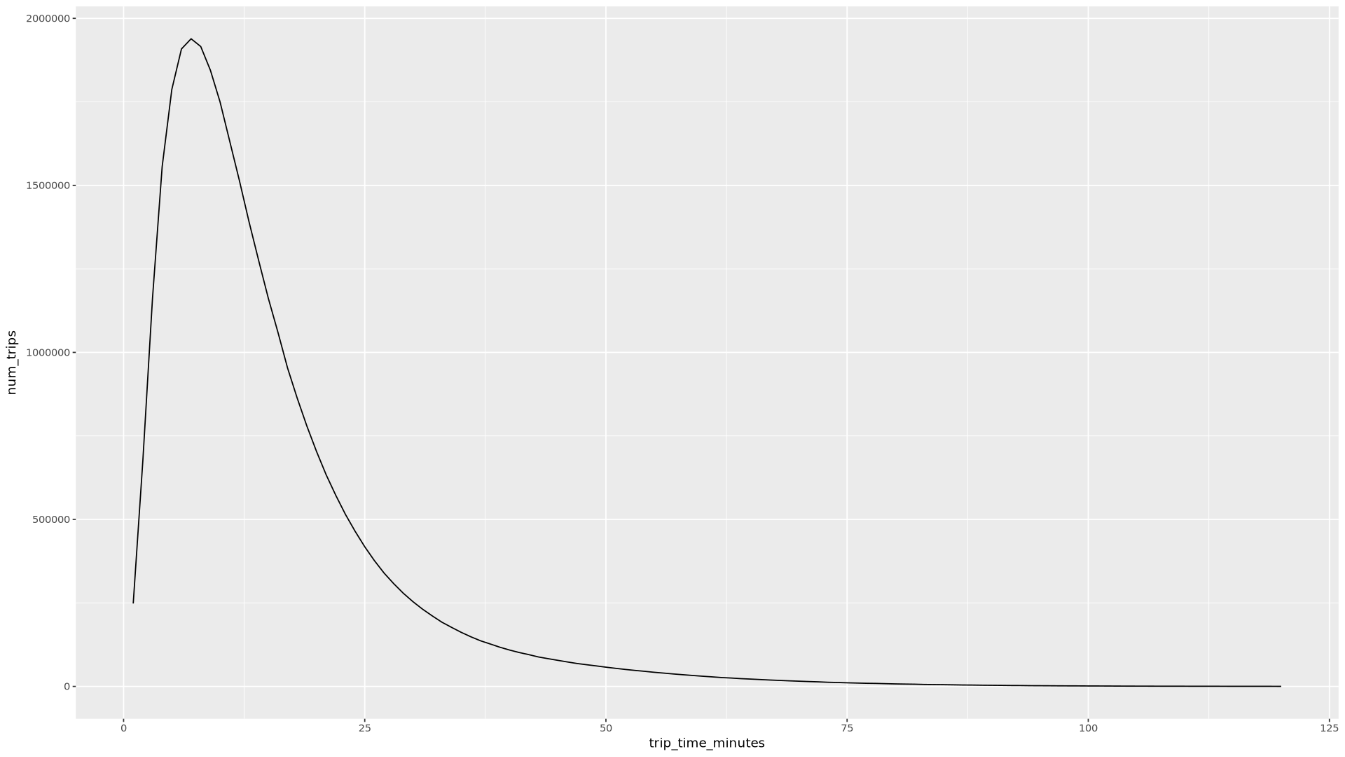
2 番目の
ggplotコマンドの出力は次のようになります。これは、乗車時間別の乗車の平均運賃額を示しています。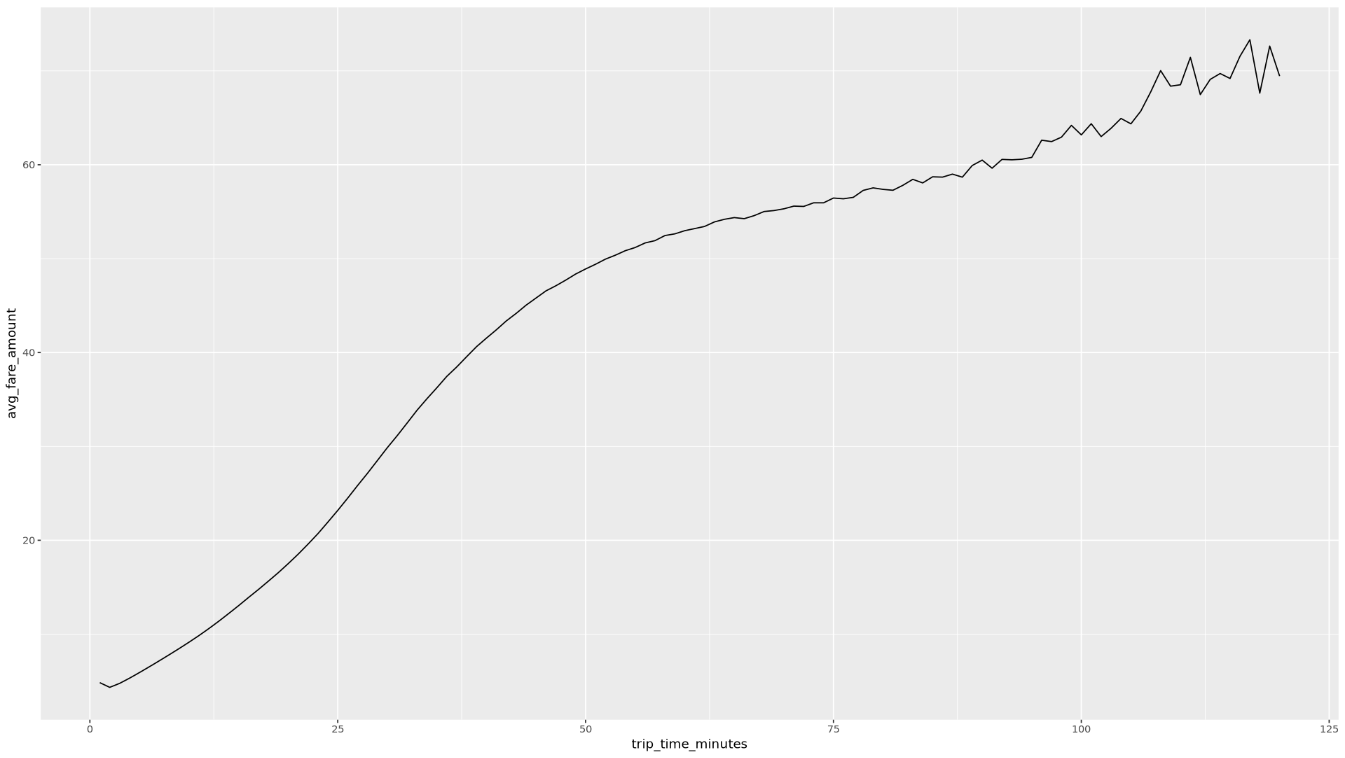
データ内の他のフィールドを使用した可視化の例については、ノートブックをご覧ください。
ノートブックで、BigQuery からトレーニング データと評価データを R に読み込みます。
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) # Split data into 75% training, 25% evaluation train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )各データセット内の観測数を確認します。
print(paste0("Training instances count: ", nrow(train_data))) print(paste0("Evaluation instances count: ", nrow(eval_data)))インスタンスの合計の約 75% をトレーニングに使用し、残りの約 25% を評価に使用します。
データをローカルの CSV ファイルに書き込みます。
# Write data frames to local CSV files, with headers dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = TRUE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = TRUE, sep = ",")システムに渡す
gsutilコマンドをラップして、CSV ファイルを Cloud Storage にアップロードします。# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)googleCloudStorageR ライブラリを使用して CSV ファイルを Cloud Storage にアップロードすることもできます。このライブラリは Cloud Storage JSON API を呼び出します。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- R ノートブックで BigQuery データを使用する方法の詳細について、bigrquery のドキュメントで確認する。
- ML のルールで ML エンジニアリングのベスト プラクティスについて学習する。
- Google Cloudの AI ワークロードと ML ワークロードに固有のアーキテクチャ原則と推奨事項の概要については、Well-Architected Framework の AI と ML の視点をご覧ください。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。
- Jason Davenport | デベロッパー アドボケイト
- Firat Tekiner | シニア プロダクト マネージャー
Vertex AI Workbench インスタンスを作成する
まず、このチュートリアルで使用できる Vertex AI Workbench インスタンスを作成します。
JupyterLab を開いて R をインストールする
ノートブックでチュートリアルを完了するには、JupyterLab 環境を開き、R をインストールして vertex-ai-samples GitHub リポジトリのクローンを作成し、ノートブックを開く必要があります。
ノートブックを開いて R を設定する
BigQuery からデータをクエリする
ノートブックのこのセクションでは、BigQuery SQL ステートメントを R に実行した結果を読み取り、データの事前確認を行います。
ggplot2 を使用してデータを可視化する
このノートブックのこのセクションでは、R の ggplot2 ライブラリを使用して、サンプル データセットの一部の変数について調べます。
BigQuery で R を使用してデータを処理する
大規模なデータセットを扱う場合は、BigQuery で可能な限り多くの分析(集計、フィルタリング、結合、列の計算など)を行ってから、結果を取得することをおすすめします。R でこれらのタスクを実行すると効率性が低下します。分析に BigQuery を使用すると、BigQuery のスケーラビリティとパフォーマンスを活用して、返された結果が R のメモリに収まるようにできます。
データを CSV ファイルとして Cloud Storage に保存する
次のタスクは、BigQuery から抽出したデータを CSV ファイルとして Cloud Storage に保存し、後続の ML タスクで使用できるようにすることです。
bigrquery を使用して、R から BigQuery にデータを書き込むこともできます。BigQuery への書き戻しは通常、前処理の完了後、またはさらなる分析に使用される結果の生成後に行われます。
クリーンアップ
このドキュメントで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、リソースを削除します。
プロジェクトの削除
課金を停止する最も簡単な方法は、作成したプロジェクトを削除することです。複数のアーキテクチャ、チュートリアル、クイックスタートを確認する計画がある場合は、プロジェクトを再利用すると割り当て上限を超えることはありません。
次のステップ
寄稿者
著者: Alok Pattani | デベロッパー アドボケイト
その他の寄稿者: