En este documento se describen dos arquitecturas de referencia que le ayudarán a crear una plataforma de aprendizaje federado en Google Cloud con Google Kubernetes Engine (GKE). Las arquitecturas de referencia y los recursos asociados que se describen en este documento admiten lo siguiente:
- Aprendizaje federado entre silos
- Aprendizaje federado multidispositivo, basado en la arquitectura entre silos
Este documento está dirigido a arquitectos de soluciones en la nube e ingenieros de IA y aprendizaje automático que quieran implementar casos prácticos de aprendizaje federado enGoogle Cloud. También está dirigido a los responsables de la toma de decisiones que estén evaluando si implementar el aprendizaje federado en Google Cloud.
Arquitectura
En los diagramas de esta sección se muestran una arquitectura entre silos y una arquitectura entre dispositivos para el aprendizaje federado. Para obtener información sobre las diferentes aplicaciones de estas arquitecturas, consulta Casos prácticos.
Arquitectura entre silos
En el siguiente diagrama se muestra una arquitectura que admite el aprendizaje federado entre silos:

El diagrama anterior muestra un ejemplo simplificado de una arquitectura entre silos. En el diagrama, todos los recursos están en el mismo proyecto de una organización. Google Cloud Estos recursos incluyen el modelo de cliente local, el modelo de cliente global y sus cargas de trabajo de aprendizaje federado asociadas.
Esta arquitectura de referencia se puede modificar para admitir varias configuraciones de silos de datos. Los miembros del consorcio pueden alojar sus silos de datos de las siguientes formas:
- En Google Cloud, en la misma Google Cloud organización y en el mismo Google Cloud proyecto.
- En Google Cloud, en la misma Google Cloud organización, en diferentesGoogle Cloud proyectos.
- En Google Cloud, en diferentes Google Cloud organizaciones.
- En entornos privados, on-premise o en otras nubes públicas.
Para que los miembros participantes puedan colaborar, deben establecer canales de comunicación seguros entre sus entornos. Para obtener más información sobre el papel de los miembros participantes en el aprendizaje federado, cómo colaboran y qué comparten entre sí, consulta los casos prácticos.
La arquitectura incluye los siguientes componentes:
- Una red de nube privada virtual (VPC) y una subred.
- Un clúster de GKE privado que te ayuda a hacer lo siguiente:
- Aísla los nodos del clúster de Internet.
- Limita la exposición de los nodos y el plano de control de tu clúster a Internet creando un clúster de GKE privado con redes autorizadas.
- Usa nodos de clúster protegidos que utilicen una imagen de sistema operativo reforzada.
- Habilita Dataplane V2 para optimizar la red de Kubernetes.
- Grupos de nodos de GKE dedicados: crea un grupo de nodos dedicado para alojar exclusivamente aplicaciones y recursos de los arrendatarios. Los nodos tienen taints para asegurarse de que solo se programen cargas de trabajo de inquilinos en los nodos de inquilino. El resto de los recursos del clúster se alojan en el grupo de nodos principal.
Cifrado de datos (habilitado de forma predeterminada):
- Datos en reposo.
- Datos en tránsito.
- Secretos de clúster en la capa de aplicación.
Encriptación de datos en uso mediante la habilitación opcional de nodos confidenciales de Google Kubernetes Engine.
Reglas de cortafuegos de VPC, que aplican lo siguiente:
- Reglas de referencia que se aplican a todos los nodos del clúster.
- Reglas adicionales que solo se aplican a los nodos del grupo de nodos del arrendatario. Estas reglas de cortafuegos limitan el tráfico entrante y saliente de los nodos de los arrendatarios.
Cloud NAT para permitir la salida a Internet.
Registros de Cloud DNS para habilitar el acceso privado de Google, de forma que las aplicaciones del clúster puedan acceder a las APIs de Google sin pasar por Internet.
Cuentas de servicio que son las siguientes:
- Una cuenta de servicio específica para los nodos del grupo de nodos del arrendatario.
- Una cuenta de servicio específica para que las aplicaciones del arrendatario la usen con la federación de identidades de cargas de trabajo.
Se admite el uso de Grupos de Google para el control de acceso basado en roles (RBAC) de Kubernetes.
Un repositorio de Git para almacenar descriptores de configuración.
Un repositorio de Artifact Registry para almacenar imágenes de contenedor.
Config Sync y Policy Controller para implementar la configuración y las políticas.
Pasarelas de Cloud Service Mesh para permitir de forma selectiva el tráfico de entrada y salida del clúster.
Segmentos de Cloud Storage para almacenar los pesos de los modelos globales y locales.
Acceso a otras APIs de Google. Google Cloud Por ejemplo, una carga de trabajo de entrenamiento puede necesitar acceder a datos de entrenamiento almacenados en Cloud Storage, BigQuery o Cloud SQL.
Arquitectura multidispositivo
En el siguiente diagrama se muestra una arquitectura que admite el aprendizaje federado entre dispositivos:
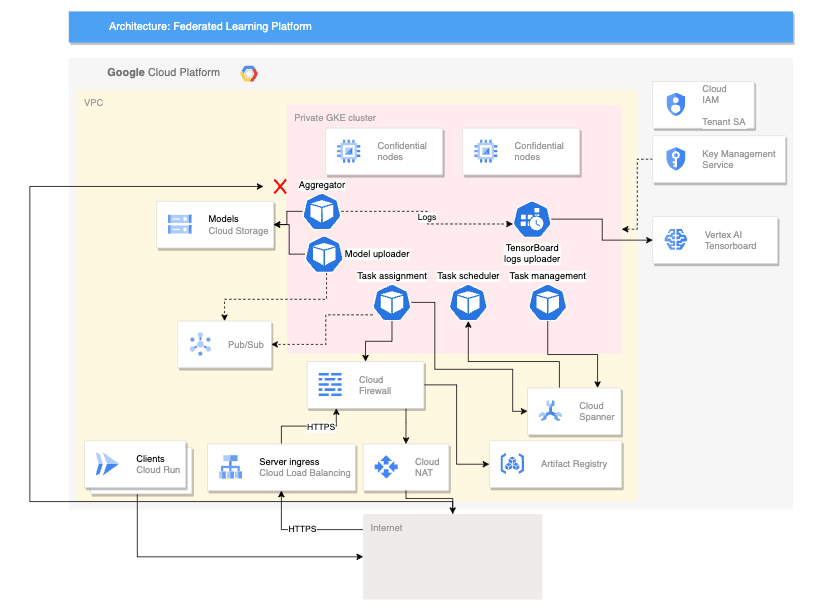
La arquitectura multidispositivo anterior se basa en la arquitectura entre silos y añade los siguientes componentes:
- Un servicio de Cloud Run que simula dispositivos que se conectan al servidor
- Un Servicio de Autoridades de Certificación que crea certificados privados para que se ejecuten el servidor y los clientes
- Un Vertex AI TensorBoard para visualizar el resultado del entrenamiento
- Un segmento de Cloud Storage para almacenar el modelo consolidado
- El clúster privado de GKE que usa nodos confidenciales como su pool principal para proteger los datos en uso
La arquitectura multidispositivo usa componentes del proyecto de software libre Federated Compute Platform (FCP). Este proyecto incluye lo siguiente:
- Código de cliente para comunicarse con un servidor y ejecutar tareas en los dispositivos.
- Protocolo de comunicación cliente-servidor.
- Puntos de conexión con TensorFlow Federated para facilitar la definición de tus computaciones federadas
Los componentes de FCP que se muestran en el diagrama anterior se pueden desplegar como un conjunto de microservicios. Estos componentes hacen lo siguiente:
- Agregador: este trabajo lee los gradientes de los dispositivos y calcula el resultado agregado con privacidad diferencial.
- Recogedor: este trabajo se ejecuta periódicamente para consultar las tareas activas y los gradientes cifrados. Esta información determina cuándo empieza la agregación.
- Uploader de modelos: este trabajo escucha eventos y publica resultados para que los dispositivos puedan descargar modelos actualizados.
- Asignación de tareas: este servicio de frontend distribuye tareas de entrenamiento a los dispositivos.
- Gestión de tareas: este trabajo gestiona tareas.
- Programador de tareas: este trabajo se ejecuta periódicamente o se activa por eventos específicos.
Productos usados
Las arquitecturas de referencia de ambos casos prácticos de aprendizaje federado usan los siguientes Google Cloud componentes:
- Google Cloud Engine de Kubernetes (GKE): GKE proporciona la plataforma básica para el aprendizaje federado.
- TensorFlow Federated (TFF): TFF proporciona un framework de código abierto para el aprendizaje automático y otros cálculos con datos descentralizados.
GKE también ofrece las siguientes funciones a tu plataforma de aprendizaje federado:
- Alojar el coordinador del aprendizaje federado: el coordinador del aprendizaje federado se encarga de gestionar el proceso de aprendizaje federado. Esta gestión incluye tareas como distribuir el modelo global a los participantes, agregar las actualizaciones de los participantes y actualizar el modelo global. GKE se puede usar para alojar el coordinador de aprendizaje federado de forma escalable y con alta disponibilidad.
- Alojar participantes del aprendizaje federado: los participantes del aprendizaje federado se encargan de entrenar el modelo global con sus datos locales. GKE se puede usar para alojar a los participantes del aprendizaje federado de forma segura y aislada. Este método puede ayudar a asegurar que los datos de los participantes se mantengan a nivel local.
- Proporcionar un canal de comunicación seguro y escalable: los participantes del aprendizaje federado deben poder comunicarse con el coordinador del aprendizaje federado de forma segura y escalable. GKE se puede usar para proporcionar un canal de comunicación seguro y escalable entre los participantes y el coordinador.
- Gestionar el ciclo de vida de las implementaciones de aprendizaje federado: GKE se puede usar para gestionar el ciclo de vida de las implementaciones de aprendizaje federado. Esta gestión incluye tareas como el aprovisionamiento de recursos, el despliegue de la plataforma de aprendizaje federado y la monitorización del rendimiento de la plataforma de aprendizaje federado.
Además de estas ventajas, GKE también ofrece una serie de funciones que pueden ser útiles para las implementaciones de aprendizaje federado, como las siguientes:
- Clústeres regionales: GKE te permite crear clústeres regionales, lo que te ayuda a mejorar el rendimiento de las implementaciones de aprendizaje federado al reducir la latencia entre los participantes y el coordinador.
- Políticas de red: GKE te permite crear políticas de red, lo que ayuda a mejorar la seguridad de las implementaciones de aprendizaje federado controlando el flujo de tráfico entre los participantes y el coordinador.
- Balanceo de carga: GKE ofrece varias opciones de balanceo de carga, lo que ayuda a mejorar la escalabilidad de las implementaciones de aprendizaje federado distribuyendo el tráfico entre los participantes y el coordinador.
TFF ofrece las siguientes funciones para facilitar la implementación de casos prácticos de aprendizaje federado:
- La capacidad de expresar de forma declarativa los cálculos federados, que son un conjunto de pasos de procesamiento que se ejecutan en un servidor y en un conjunto de clientes. Estos cálculos se pueden implementar en diversos entornos de ejecución.
- Los agregadores personalizados se pueden crear con el código abierto de TFF.
- Compatibilidad con varios algoritmos de aprendizaje federado, incluidos los siguientes:
- Promedio federado:
algoritmo que calcula la media de los parámetros del modelo de los clientes participantes. Es especialmente adecuada para casos prácticos en los que los datos son relativamente homogéneos y el modelo no es demasiado complejo. Estos son algunos casos prácticos habituales:
- Recomendaciones personalizadas: una empresa puede usar la media federada para entrenar un modelo que recomiende productos a los usuarios en función de su historial de compras.
- Detección de fraudes: un consorcio de bancos puede usar la media federada para entrenar un modelo que detecte transacciones fraudulentas.
- Diagnóstico médico: un grupo de hospitales puede usar la media federada para entrenar un modelo que diagnostique el cáncer.
- Descenso de gradiente estocástico federado (FedSGD): algoritmo que usa el descenso de gradiente estocástico para actualizar los parámetros del modelo. Es ideal para casos prácticos en los que los datos son heterogéneos y el modelo es complejo. Estos son algunos casos prácticos habituales:
- Procesamiento del lenguaje natural: una empresa puede usar FedSGD para entrenar un modelo que mejore la precisión del reconocimiento de voz.
- Reconocimiento de imágenes: una empresa puede usar FedSGD para entrenar un modelo que pueda identificar objetos en imágenes.
- Mantenimiento predictivo: una empresa puede usar FedSGD para entrenar un modelo que prediga cuándo es probable que falle una máquina.
- Federated Adam:
Algoritmo que usa el optimizador Adam para actualizar los parámetros del modelo.
Estos son algunos casos prácticos habituales:
- Sistemas de recomendación: una empresa puede usar el algoritmo Adam federado para entrenar un modelo que recomiende productos a los usuarios en función de su historial de compras.
- Clasificación: una empresa puede usar Adam federado para entrenar un modelo que clasifique los resultados de búsqueda.
- Predicción del porcentaje de clics: una empresa puede usar Adam federado para entrenar un modelo que prediga la probabilidad de que un usuario haga clic en un anuncio.
- Promedio federado:
algoritmo que calcula la media de los parámetros del modelo de los clientes participantes. Es especialmente adecuada para casos prácticos en los que los datos son relativamente homogéneos y el modelo no es demasiado complejo. Estos son algunos casos prácticos habituales:
Casos prácticos
En esta sección se describen los casos prácticos en los que las arquitecturas entre silos y entre dispositivos son opciones adecuadas para tu plataforma de aprendizaje federado.
El aprendizaje federado es un ajuste de aprendizaje automático en el que muchos clientes entrenan un modelo de forma colaborativa. Este proceso lo dirige un coordinador central y los datos de entrenamiento siguen descentralizados.
En el paradigma del aprendizaje federado, los clientes descargan un modelo global y lo mejoran entrenándolo localmente con sus datos. A continuación, cada cliente envía las actualizaciones del modelo calculadas al servidor central, donde se agregan y se genera una nueva iteración del modelo global. En estas arquitecturas de referencia, las cargas de trabajo de entrenamiento de modelos se ejecutan en GKE.
El aprendizaje federado cumple el principio de privacidad de minimización de datos, ya que restringe los datos que se recogen en cada fase del cálculo, limita el acceso a los datos y los trata y descarta lo antes posible. Además, la configuración del problema del aprendizaje federado es compatible con otras técnicas de protección de la privacidad, como el uso de la privacidad diferencial (DP) para mejorar la anonimización del modelo y asegurarse de que el modelo final no memorice los datos de usuarios concretos.
En función del caso práctico, entrenar modelos con aprendizaje federado puede aportar ventajas adicionales:
- Cumplimiento: en algunos casos, las normativas pueden restringir la forma en que se pueden usar o compartir los datos. El aprendizaje federado se puede usar para cumplir estas normativas.
- Eficiencia de la comunicación: en algunos casos, es más eficiente entrenar un modelo con datos distribuidos que centralizar los datos. Por ejemplo, los conjuntos de datos con los que se debe entrenar el modelo son demasiado grandes para moverlos de forma centralizada.
- Permite acceder a los datos: el aprendizaje federado permite a las organizaciones mantener los datos de entrenamiento descentralizados en silos de datos por usuario o por organización.
- Mayor precisión del modelo: al entrenar con datos de usuarios reales (sin dejar de proteger la privacidad) en lugar de con datos sintéticos (a veces denominados datos proxy), se suele conseguir una mayor precisión del modelo.
Hay diferentes tipos de aprendizaje federado, que se caracterizan por el origen de los datos y el lugar donde se realizan los cálculos locales. Las arquitecturas de este documento se centran en dos tipos de aprendizaje federado: entre silos y entre dispositivos. Otros tipos de aprendizaje federado quedan fuera del ámbito de este documento.
El aprendizaje federado se clasifica en función de cómo se particionan los conjuntos de datos, que pueden ser de las siguientes formas:
- Aprendizaje federado horizontal (HFL): conjuntos de datos con las mismas características (columnas), pero con muestras (filas) diferentes. Por ejemplo, varios hospitales pueden tener registros de pacientes con los mismos parámetros médicos, pero con diferentes poblaciones de pacientes.
- Aprendizaje federado vertical (VFL): conjuntos de datos con las mismas muestras (filas), pero con diferentes características (columnas). Por ejemplo, un banco y una empresa de comercio electrónico pueden tener datos de clientes con personas que coincidan, pero con información financiera y de compra diferente.
- Aprendizaje por transferencia federado (FTL): superposición parcial de muestras y características entre los conjuntos de datos. Por ejemplo, dos hospitales pueden tener registros de pacientes con algunos individuos que se solapan y algunos parámetros médicos compartidos, pero también características únicas en cada conjunto de datos.
En la computación federada entre silos, los miembros participantes son organizaciones o empresas. En la práctica, el número de miembros suele ser pequeño (por ejemplo, menos de cien). El cálculo entre silos se suele usar en situaciones en las que las organizaciones participantes tienen conjuntos de datos diferentes, pero quieren entrenar un modelo compartido o analizar resultados agregados sin compartir sus datos sin procesar entre sí. Por ejemplo, los miembros participantes pueden tener sus entornos en diferentes Google Cloud organizaciones Google Cloud , como cuando representan a diferentes entidades jurídicas, o en la mismaGoogle Cloud organizaciónGoogle Cloud , como cuando representan a diferentes departamentos de la misma entidad jurídica.
Es posible que los miembros participantes no puedan considerar las cargas de trabajo de los demás como entidades de confianza. Por ejemplo, es posible que un miembro participante no tenga acceso al código fuente de una carga de trabajo de entrenamiento que reciba de un tercero, como el coordinador. Como no pueden acceder a este código fuente, el miembro participante no puede asegurarse de que la carga de trabajo sea totalmente fiable.
Para evitar que una carga de trabajo no fiable acceda a tus datos o recursos sin autorización, te recomendamos que hagas lo siguiente:
- Despliega cargas de trabajo que no sean de confianza en un entorno aislado.
- Concede a las cargas de trabajo no fiables solo los derechos de acceso y permisos estrictamente necesarios para completar las rondas de entrenamiento asignadas a la carga de trabajo.
Para ayudarte a aislar las cargas de trabajo que no sean de confianza, estas arquitecturas de referencia implementan controles de seguridad, como la configuración de espacios de nombres de Kubernetes aislados, donde cada espacio de nombres tiene un grupo de nodos de GKE dedicado. De forma predeterminada, se prohíbe la comunicación entre espacios de nombres y el tráfico entrante y saliente de clústeres, a menos que anules este ajuste de forma explícita.
A continuación, se muestran algunos ejemplos de casos prácticos del aprendizaje federado entre silos:
- Detección de fraudes: el aprendizaje federado se puede usar para entrenar un modelo de detección de fraudes con datos distribuidos en varias organizaciones. Por ejemplo, un consorcio de bancos podría usar el aprendizaje federado para entrenar un modelo que detecte transacciones fraudulentas.
- Diagnóstico médico: el aprendizaje federado se puede usar para entrenar un modelo de diagnóstico médico con datos distribuidos en varios hospitales. Por ejemplo, un grupo de hospitales podría usar el aprendizaje federado para entrenar un modelo que diagnostique el cáncer.
El aprendizaje federado entre dispositivos es un tipo de computación federada en el que los miembros participantes son dispositivos de usuario final, como teléfonos móviles, vehículos o dispositivos del Internet de las cosas. El número de miembros puede llegar a millones o incluso decenas de millones.
El proceso del aprendizaje federado entre dispositivos es similar al del aprendizaje federado entre silos. Sin embargo, también requiere que adaptes la arquitectura de referencia para tener en cuenta algunos de los factores adicionales que debes considerar cuando trabajas con miles o millones de dispositivos. Debes implementar cargas de trabajo administrativas para gestionar las situaciones que se dan en los casos prácticos de aprendizaje federado entre dispositivos. Por ejemplo, la necesidad de coordinar un subconjunto de clientes que participarán en la ronda de entrenamiento. La arquitectura multidispositivo proporciona esta función al permitirte implementar los servicios de FCP. Estos servicios tienen cargas de trabajo que tienen puntos de conexión con TFF. TFF se usa para escribir el código que gestiona esta coordinación.
Estos son algunos ejemplos de casos prácticos del aprendizaje federado entre dispositivos:
- Recomendaciones personalizadas: puedes usar el aprendizaje federado multidispositivo para entrenar un modelo de recomendaciones personalizadas con datos distribuidos en varios dispositivos. Por ejemplo, una empresa podría usar el aprendizaje federado para entrenar un modelo que recomiende productos a los usuarios en función de su historial de compras.
- Procesamiento del lenguaje natural: el aprendizaje federado se puede usar para entrenar un modelo de procesamiento del lenguaje natural con datos distribuidos en varios dispositivos. Por ejemplo, una empresa podría usar el aprendizaje federado para entrenar un modelo que mejore la precisión del reconocimiento de voz.
- Predecir las necesidades de mantenimiento de los vehículos: el aprendizaje federado se puede usar para entrenar un modelo que prediga cuándo es probable que un vehículo necesite mantenimiento. Este modelo se podría entrenar con datos recogidos de varios vehículos. Este enfoque permite que el modelo aprenda de las experiencias de todos los vehículos sin poner en riesgo la privacidad de ninguno de ellos.
En la siguiente tabla se resumen las características de las arquitecturas entre silos y entre dispositivos, y se muestra cómo categorizar el tipo de escenario de aprendizaje federado que se aplica a tu caso práctico.
| Función | Computaciones federadas entre silos | Computaciones federadas multidispositivo |
|---|---|---|
| Tamaño de la población | Suele ser pequeña (por ejemplo, menos de cien dispositivos) | Escalable a miles, millones o cientos de millones de dispositivos |
| Miembros participantes | Organizaciones o empresas | Dispositivos móviles, dispositivos perimetrales y vehículos |
| Partición de datos más habitual | HFL, VFL y FTL | HFL |
| Sensibilidad de los datos | Datos sensibles que los participantes no quieren compartir entre sí en formato sin procesar | Datos demasiado sensibles para compartirlos con un servidor central |
| Disponibilidad de los datos | Los participantes casi siempre están disponibles | Solo una parte de los participantes están disponibles en un momento dado |
| Ejemplos de casos prácticos | Detección de fraudes, diagnóstico médico y previsión financiera | Monitorización de la actividad física, reconocimiento de voz y clasificación de imágenes |
Factores del diseño
En esta sección se ofrecen directrices para ayudarte a usar esta arquitectura de referencia y desarrollar una o varias arquitecturas que cumplan tus requisitos específicos de seguridad, fiabilidad, eficiencia operativa, coste y rendimiento.
Consideraciones sobre el diseño de la arquitectura entre silos
Para implementar una arquitectura de aprendizaje federado entre silos enGoogle Cloud, debes cumplir los siguientes requisitos mínimos, que se explican con más detalle en las secciones siguientes:
- Crea un consorcio de aprendizaje federado.
- Determina el modelo de colaboración que va a implementar el consorcio de aprendizaje federado.
- Determina las responsabilidades de las organizaciones participantes.
Además de estos requisitos previos, el propietario de la federación debe llevar a cabo otras acciones que no se incluyen en este documento, como las siguientes:
- Gestionar el consorcio de aprendizaje federado.
- Diseña e implementa un modelo de colaboración.
- Prepara, gestiona y opera los datos de entrenamiento del modelo y el modelo que el propietario de la federación quiere entrenar.
- Crea, contenedoriza y orquesta flujos de trabajo de aprendizaje federado.
- Desplegar y gestionar cargas de trabajo de aprendizaje federado.
- Configura los canales de comunicación para que las organizaciones participantes transfieran datos de forma segura.
Crear un consorcio de aprendizaje federado
Un consorcio de aprendizaje federado es el grupo de organizaciones que participa en un esfuerzo de aprendizaje federado entre silos. Las organizaciones del consorcio solo comparten los parámetros de los modelos de aprendizaje automático, y puedes cifrar estos parámetros para aumentar la privacidad. Si el consorcio de aprendizaje federado lo permite, las organizaciones también pueden agregar datos que no contengan información personal identificable (IPI).
Determinar un modelo de colaboración para el consorcio de aprendizaje federado
El consorcio de aprendizaje federado puede implementar diferentes modelos de colaboración, como los siguientes:
- Un modelo centralizado que consta de una sola organización coordinadora, denominada propietario de la federación u orquestador, y un conjunto de organizaciones participantes o propietarios de los datos.
- Un modelo descentralizado que consta de organizaciones que se coordinan como un grupo.
- Un modelo heterogéneo que consta de un consorcio de diversas organizaciones participantes, cada una de las cuales aporta recursos diferentes al consorcio.
En este documento se da por supuesto que el modelo de colaboración es un modelo centralizado.
Determinar las responsabilidades de las organizaciones participantes
Después de elegir un modelo de colaboración para el consorcio de aprendizaje federado, el propietario de la federación debe determinar las responsabilidades de las organizaciones participantes.
El propietario de la federación también debe hacer lo siguiente cuando empiece a crear un consorcio de aprendizaje federado:
- Coordinar el esfuerzo de aprendizaje federado.
- Diseñar e implementar el modelo de aprendizaje automático global y los modelos de aprendizaje automático que se compartirán con las organizaciones participantes.
- Define las rondas de aprendizaje federado, es decir, el enfoque de la iteración del proceso de entrenamiento del aprendizaje automático.
- Selecciona las organizaciones participantes que contribuyen a cualquier ronda de aprendizaje federado. Esta selección se denomina cohorte.
- Diseñar e implementar un procedimiento de verificación de la pertenencia al consorcio para las organizaciones participantes.
- Actualiza el modelo de aprendizaje automático global y los modelos de aprendizaje automático que quieras compartir con las organizaciones participantes.
- Proporcionar a las organizaciones participantes las herramientas para validar que el consorcio de aprendizaje federado cumple sus requisitos de privacidad, seguridad y normativas.
- Proporcionar a las organizaciones participantes canales de comunicación seguros y cifrados.
- Proporcionar a las organizaciones participantes todos los datos agregados no confidenciales necesarios para completar cada ronda de aprendizaje federado.
Las organizaciones participantes tienen las siguientes responsabilidades:
- Proporcionar y mantener un entorno seguro y aislado (un silo). El silo es el lugar donde las organizaciones participantes almacenan sus propios datos y donde se implementa el entrenamiento del modelo de aprendizaje automático. Las organizaciones participantes no comparten sus datos con otras organizaciones.
- Entrenar los modelos proporcionados por el propietario de la federación usando su propia infraestructura informática y sus propios datos locales.
- Compartir los resultados del entrenamiento del modelo con el propietario de la federación en forma de datos agregados, después de eliminar cualquier IPI.
El propietario de la federación y las organizaciones participantes pueden usar Cloud Storage para compartir modelos actualizados y resultados de entrenamiento.
El propietario de la federación y las organizaciones participantes refinan el entrenamiento del modelo de aprendizaje automático hasta que el modelo cumpla sus requisitos.
Implementar el aprendizaje federado en Google Cloud
Una vez que se haya creado el consorcio de aprendizaje federado y se haya determinado cómo colaborará, recomendamos que las organizaciones participantes hagan lo siguiente:
- Aprovisionar y configurar la infraestructura necesaria para el consorcio de aprendizaje federado.
- Implementa el modelo de colaboración.
- Inicia el proceso de aprendizaje federado.
Aprovisionar y configurar la infraestructura del consorcio de aprendizaje federado
Al aprovisionar y configurar la infraestructura del consorcio de aprendizaje federado, el propietario de la federación es el responsable de crear y distribuir las cargas de trabajo que entrenan los modelos de aprendizaje automático federado a las organizaciones participantes. Como un tercero (el propietario de la federación) ha creado y proporcionado las cargas de trabajo, las organizaciones participantes deben tomar precauciones al implementar esas cargas de trabajo en sus entornos de tiempo de ejecución.
Las organizaciones participantes deben configurar sus entornos de acuerdo con sus prácticas recomendadas de seguridad individuales y aplicar controles que limiten el alcance y los permisos concedidos a cada carga de trabajo. Además de seguir sus prácticas recomendadas de seguridad individuales, recomendamos que el propietario de la federación y las organizaciones participantes tengan en cuenta los vectores de amenazas específicos del aprendizaje federado.
Implementar el modelo de colaboración
Una vez que se haya preparado la infraestructura del consorcio de aprendizaje federado, el propietario de la federación diseñará e implementará los mecanismos que permitan a las organizaciones participantes interactuar entre sí. Este enfoque sigue el modelo de colaboración que el propietario de la federación ha elegido para el consorcio de aprendizaje federado.
Iniciar el aprendizaje federado
Después de implementar el modelo de colaboración, el propietario de la federación implementa el modelo de aprendizaje automático global para entrenar y los modelos de aprendizaje automático que se van a compartir con la organización participante. Cuando esos modelos de aprendizaje automático estén listos, el propietario de la federación iniciará la primera ronda del proceso de aprendizaje federado.
En cada ronda del proceso de aprendizaje federado, el propietario de la federación hace lo siguiente:
- Distribuye los modelos de aprendizaje automático para compartirlos con las organizaciones participantes.
- Espera a que las organizaciones participantes proporcionen los resultados del entrenamiento de los modelos de aprendizaje automático que haya compartido el propietario de la federación.
- Recoge y procesa los resultados de la formación que han obtenido las organizaciones participantes.
- Actualiza el modelo de aprendizaje automático global cuando recibe resultados de entrenamiento adecuados de las organizaciones participantes.
- Actualiza los modelos de aprendizaje automático para compartirlos con los demás miembros del consorcio cuando proceda.
- Prepara los datos de entrenamiento para la siguiente ronda de aprendizaje federado.
- Inicia la siguiente ronda de aprendizaje federado.
Seguridad, privacidad y cumplimiento
En esta sección se describen los factores que debes tener en cuenta al usar esta arquitectura de referencia para diseñar y crear una plataforma de aprendizaje federado enGoogle Cloud. Estas directrices se aplican a ambas arquitecturas descritas en este documento.
Las cargas de trabajo de aprendizaje federado que implementes en tus entornos pueden exponer tu empresa, tus datos, tus modelos de aprendizaje federado y tu infraestructura a amenazas que podrían afectar a tu negocio.
Para ayudarte a aumentar la seguridad de tus entornos de aprendizaje federado, estas arquitecturas de referencia configuran controles de seguridad de GKE que se centran en la infraestructura de tus entornos. Es posible que estos controles no sean suficientes para protegerte frente a las amenazas específicas de tus cargas de trabajo y casos prácticos de aprendizaje federado. Dada la especificidad de cada carga de trabajo y caso práctico de aprendizaje federado, los controles de seguridad destinados a proteger tu implementación de aprendizaje federado quedan fuera del ámbito de este documento. Para obtener más información y ejemplos sobre estas amenazas, consulta el artículo Consideraciones de seguridad del aprendizaje federado.
Controles de seguridad de GKE
En esta sección se describen los controles que se aplican con estas arquitecturas para proteger tu clúster de GKE.
Seguridad mejorada de los clústeres de GKE
Estas arquitecturas de referencia te ayudan a crear un clúster de GKE que implemente los siguientes ajustes de seguridad:
- Limita la exposición de los nodos y el plano de control de tu clúster a Internet creando un clúster de GKE privado con redes autorizadas.
- Usa nodos protegidos que utilicen una imagen de nodo reforzada con el tiempo de ejecución
containerd. - Mayor aislamiento de las cargas de trabajo de los clientes mediante GKE Sandbox.
- Encriptar los datos en reposo de forma predeterminada.
- Cifrar los datos en tránsito de forma predeterminada.
- Encripta los secretos del clúster en la capa de aplicación.
- También puedes encriptar los datos en uso habilitando los nodos confidenciales de Google Kubernetes Engine.
Para obtener más información sobre la configuración de seguridad de GKE, consulta los artículos Refuerza la seguridad de tu clúster y Acerca del panel de control de postura de seguridad.
Reglas de cortafuegos de VPC
Las reglas de cortafuegos de nube privada virtual (VPC) determinan qué tráfico se permite hacia o desde las VMs de Compute Engine. Estas reglas le permiten filtrar el tráfico con una granularidad de máquina virtual, en función de los atributos de capa 4.
Crea un clúster de GKE con las reglas de cortafuegos predeterminadas del clúster de GKE. Estas reglas de cortafuegos permiten la comunicación entre los nodos del clúster y el plano de control de GKE, así como entre los nodos y los pods del clúster.
Aplica reglas de cortafuegos adicionales a los nodos del grupo de nodos del arrendatario. Estas reglas de cortafuegos restringen el tráfico de salida de los nodos del arrendatario. Este enfoque puede aumentar el aislamiento de los nodos de los clientes. De forma predeterminada, se deniega todo el tráfico de salida de los nodos de inquilino. Cualquier salida necesaria debe configurarse explícitamente. Por ejemplo, puedes crear reglas de firewall para permitir el tráfico saliente de los nodos del arrendatario al plano de control de GKE y a las APIs de Google mediante Acceso privado de Google. Las reglas de cortafuegos se dirigen a los nodos de arrendatario mediante la cuenta de servicio del pool de nodos de arrendatario.
Espacios de nombres
Los espacios de nombres te permiten proporcionar un ámbito para los recursos relacionados de un clúster, como pods, servicios y controladores de réplica. Al usar espacios de nombres, puedes delegar la responsabilidad de administración de los recursos relacionados como una unidad. Por lo tanto, los espacios de nombres son fundamentales para la mayoría de los patrones de seguridad.
Los espacios de nombres son una función importante para el aislamiento del plano de control. Sin embargo, no proporcionan aislamiento de nodos, aislamiento de planos de datos ni aislamiento de redes.
Una práctica habitual es crear espacios de nombres para cada aplicación. Por ejemplo, puedes crear el espacio de nombres myapp-frontend para el componente de interfaz de usuario de una aplicación.
Estas arquitecturas de referencia te ayudan a crear un espacio de nombres específico para alojar las aplicaciones de terceros. El espacio de nombres y sus recursos se tratan como un arrendatario en tu clúster. Puedes aplicar políticas y controles al espacio de nombres para limitar el ámbito de los recursos del espacio de nombres.
Políticas de red
Las políticas de red aplican flujos de tráfico de red de capa 4 mediante reglas de cortafuegos a nivel de pod. Las políticas de red se limitan a un espacio de nombres.
En las arquitecturas de referencia que se describen en este documento, se aplican políticas de red al espacio de nombres del arrendatario que aloja las aplicaciones de terceros. De forma predeterminada, la política de red deniega todo el tráfico hacia y desde los pods del espacio de nombres. El tráfico necesario debe añadirse explícitamente a una lista de permitidas. Por ejemplo, las políticas de red de estas arquitecturas de referencia permiten explícitamente el tráfico a los servicios de clúster necesarios, como el DNS interno del clúster y el plano de control de Cloud Service Mesh.
Config Sync
Config Sync mantiene tus clústeres de GKE sincronizados con las configuraciones almacenadas en un repositorio de Git. El repositorio de Git actúa como la única fuente de información veraz para la configuración y las políticas de tu clúster. Config Sync es declarativo. Comprueba continuamente el estado de los clústeres y aplica el estado declarado en el archivo de configuración para implementar las políticas, lo que ayuda a evitar el desfase en las configuraciones.
Instala Config Sync en tu clúster de GKE. Configuras Config Sync para sincronizar las configuraciones y las políticas de los clústeres desde un repositorio de origen en la nube. Los recursos sincronizados incluyen lo siguiente:
- Configuración de Cloud Service Mesh a nivel de clúster
- Políticas de seguridad a nivel de clúster
- Configuración y política a nivel de espacio de nombres de inquilino, incluidas políticas de red, cuentas de servicio, reglas de control de acceso basado en roles y configuración de Cloud Service Mesh
Policy Controller
Policy Controller es un controlador dinámico de admisión de Kubernetes que aplica políticas basadas en CustomResourceDefinition (CRD) que ejecuta Open Policy Agent (OPA).
Los controladores de admisión son complementos de Kubernetes que interceptan las solicitudes al servidor de la API de Kubernetes antes de que se conserve un objeto, pero después de que la solicitud se haya autenticado y autorizado. Puedes usar controladores de admisión para limitar el uso de un clúster.
Instalas Policy Controller en tu clúster de GKE. Estas arquitecturas de referencia incluyen políticas de ejemplo para ayudar a proteger tu clúster. Las políticas se aplican automáticamente a tu clúster mediante Config Sync. Aplica las siguientes políticas:
- Políticas seleccionadas para ayudar a reforzar la seguridad de los pods. Por ejemplo, puedes aplicar políticas que impidan que los pods ejecuten contenedores con privilegios y que requieran un sistema de archivos raíz de solo lectura.
- Políticas de la biblioteca de plantillas de Policy Controller. Por ejemplo, aplicas una política que no permite servicios de tipo NodePort.
Cloud Service Mesh
Cloud Service Mesh es una malla de servicios que te ayuda a simplificar la gestión de las comunicaciones seguras entre servicios. Estas arquitecturas de referencia configuran Cloud Service Mesh para que haga lo siguiente:
- Inyecta automáticamente proxies de sidecar.
- Aplica la comunicación mTLS entre los servicios de la malla.
- Limita el tráfico de salida de la malla solo a los hosts conocidos.
- Limita el tráfico entrante solo de determinados clientes.
- Te permite configurar políticas de seguridad de red basadas en la identidad del servicio en lugar de en la dirección IP de los peers de la red.
- Limita la comunicación autorizada entre los servicios de la malla. Por ejemplo, las aplicaciones del espacio de nombres del arrendatario solo pueden comunicarse con aplicaciones del mismo espacio de nombres o con un conjunto de hosts externos conocidos.
- Encaminan todo el tráfico entrante y saliente a través de las puertas de enlace de la malla, donde puedes aplicar más controles de tráfico.
- Admite la comunicación segura entre clústeres.
Intolerancias y afinidades de nodos
Las marcas de nodos y la afinidad de nodos son mecanismos de Kubernetes que te permiten influir en cómo se programan los pods en los nodos del clúster.
Los nodos contaminados repelen los pods. Kubernetes no programará un pod en un nodo con intolerancias a menos que el pod tenga una tolerancia para la intolerancia. Puedes usar taints de nodos para reservar nodos y que solo los usen determinadas cargas de trabajo o inquilinos. Las taints y las tolerancias se suelen usar en clústeres multiarrendatario. Para obtener más información, consulta la documentación sobre nodos dedicados con taints y tolerancias.
La afinidad de nodos te permite restringir los pods a nodos con etiquetas concretas. Si un pod tiene un requisito de afinidad de nodo, Kubernetes no programa el pod en un nodo a menos que el nodo tenga una etiqueta que coincida con el requisito de afinidad. Puedes usar la afinidad de nodos para asegurarte de que los pods se programen en los nodos adecuados.
Puedes usar las intolerancias y la afinidad de nodos conjuntamente para asegurarte de que los pods de la carga de trabajo del arrendatario se programen exclusivamente en los nodos reservados para el arrendatario.
Estas arquitecturas de referencia te ayudan a controlar la programación de las aplicaciones de los inquilinos de las siguientes formas:
- Crear un grupo de nodos de GKE dedicado al arrendatario. Cada nodo del pool tiene un taint relacionado con el nombre del arrendatario.
- Aplicar automáticamente la tolerancia y la afinidad de nodos adecuadas a cualquier pod que tenga como destino el espacio de nombres del arrendatario. Aplica la tolerancia y la afinidad mediante mutaciones de PolicyController.
Mínimos privilegios
Es una práctica recomendada de seguridad adoptar el principio de privilegio mínimo en tusGoogle Cloud proyectos y recursos, como los clústeres de GKE. Con este enfoque, las aplicaciones que se ejecutan en tu clúster, así como los desarrolladores y operadores que lo usan, solo tienen el conjunto mínimo de permisos necesarios.
Estas arquitecturas de referencia te ayudan a usar cuentas de servicio con el menor número de privilegios posible de las siguientes formas:
- Cada grupo de nodos de GKE recibe su propia cuenta de servicio. Por ejemplo, los nodos del grupo de nodos del arrendatario usan una cuenta de servicio dedicada a esos nodos. Las cuentas de servicio de los nodos se configuran con los permisos mínimos necesarios.
- El clúster usa Workload Identity Federation for GKE para asociar cuentas de servicio de Kubernetes con cuentas de servicio de Google. De esta forma, se puede conceder a las aplicaciones de inquilino acceso limitado a las APIs de Google necesarias sin descargar ni almacenar una clave de cuenta de servicio. Por ejemplo, puedes conceder a la cuenta de servicio permisos para leer datos de un segmento de Cloud Storage.
Estas arquitecturas de referencia te ayudan a restringir el acceso a los recursos del clúster de las siguientes formas:
- Crea un rol de control de acceso basado en roles (RBAC) de Kubernetes de ejemplo con permisos limitados para gestionar aplicaciones. Puedes conceder este rol a los usuarios y grupos que gestionen las aplicaciones en el espacio de nombres del arrendatario. Al aplicar este rol limitado de usuarios y grupos, esos usuarios solo tienen permisos para modificar los recursos de la aplicación en el espacio de nombres del arrendatario. No tienen permisos para modificar recursos a nivel de clúster ni configuraciones de seguridad sensibles, como las políticas de Cloud Service Mesh.
Autorización binaria
La autorización binaria te permite aplicar las políticas que definas sobre las imágenes de contenedor que se despliegan en tu entorno de GKE. La autorización binaria solo permite desplegar imágenes de contenedor que cumplan las políticas que hayas definido. No permite desplegar ninguna otra imagen de contenedor.
En esta arquitectura de referencia, la autorización binaria está habilitada con su configuración predeterminada. Para inspeccionar la configuración predeterminada de Autorización binaria, consulta Exportar el archivo YAML de la política.
Para obtener más información sobre cómo configurar las políticas, consulta las siguientes guías específicas:
- Google Cloud CLI
- Google Cloud console
- API REST
- El recurso de Terraform
google_binary_authorization_policy
Verificación de la atestación entre organizaciones
Puedes usar la autorización binaria para verificar las atestaciones generadas por un firmante externo. Por ejemplo, en un caso práctico de aprendizaje federado entre silos, puedes verificar las certificaciones que haya creado otra organización participante.
Para verificar las atestaciones que ha creado un tercero, haz lo siguiente:
- Recibe las claves públicas que el tercero ha usado para crear las certificaciones que necesitas verificar.
- Crea los encargados de la atestación para verificar las atestaciones.
- Añade las claves públicas que has recibido del tercero a los verificadores que has creado.
Para obtener más información sobre cómo crear attestors, consulta las siguientes guías específicas:
- Google Cloud CLI
- Google Cloud console
- la API REST
- el recurso de Terraform
google_binary_authorization_attestor
Consideraciones de seguridad del aprendizaje federado
A pesar de su estricto modelo de intercambio de datos, el aprendizaje federado no es intrínsecamente seguro frente a todos los ataques dirigidos, por lo que debes tener en cuenta estos riesgos al implementar cualquiera de las arquitecturas descritas en este documento. También existe el riesgo de que se filtre información no intencionada sobre los modelos de aprendizaje automático o los datos de entrenamiento de los modelos. Por ejemplo, un atacante podría poner en peligro intencionadamente el modelo de aprendizaje automático global o las rondas del proceso de aprendizaje federado, o bien podría ejecutar un ataque de tiempo (un tipo de ataque de canal lateral) para obtener información sobre el tamaño de los conjuntos de datos de entrenamiento.
Las amenazas más habituales contra una implementación de aprendizaje federado son las siguientes:
- Memorización intencionada o no intencionada de datos de entrenamiento. Tu implementación de aprendizaje federado o un atacante pueden almacenar datos de forma intencionada o no intencionada de maneras que dificulten el trabajo con ellos. Un atacante podría obtener información sobre el modelo de aprendizaje automático global o sobre las rondas anteriores del aprendizaje federado mediante la ingeniería inversa de los datos almacenados.
- Extraer información de las actualizaciones del modelo de aprendizaje automático global. Durante el proceso de aprendizaje federado, un atacante podría aplicar ingeniería inversa a las actualizaciones del modelo de aprendizaje automático global que el propietario de la federación recoge de las organizaciones y los dispositivos participantes.
- El propietario de la federación podría poner en peligro las rondas. Un propietario de una federación vulnerada podría controlar un silo o un dispositivo no autorizado e iniciar una ronda de aprendizaje federado. Al final de la ronda, el propietario de la federación vulnerada podría obtener información sobre las actualizaciones que recoge de las organizaciones y los dispositivos participantes legítimos comparando esas actualizaciones con la que ha producido el silo no autorizado.
- Las organizaciones y los dispositivos participantes pueden poner en peligro el modelo de aprendizaje automático global. Durante el proceso de aprendizaje federado, un atacante puede intentar afectar de forma malintencionada al rendimiento, la calidad o la integridad del modelo de aprendizaje automático global produciendo actualizaciones falsas o irrelevantes.
Para mitigar el impacto de las amenazas descritas en esta sección, te recomendamos que sigas estas prácticas recomendadas:
- Ajusta el modelo para reducir al mínimo la memorización de los datos de entrenamiento.
- Implementa mecanismos que protejan la privacidad.
- Audita periódicamente el modelo de aprendizaje automático global, los modelos de aprendizaje automático que quieras compartir, los datos de entrenamiento y la infraestructura que hayas implementado para alcanzar tus objetivos de aprendizaje federado.
- Implementa un algoritmo de agregación segura para procesar los resultados del entrenamiento que producen las organizaciones participantes.
- Generar y distribuir de forma segura claves de cifrado de datos mediante una infraestructura de clave pública.
- Implementa la infraestructura en una plataforma de Confidential Computing.
Los propietarios de federaciones también deben seguir estos pasos adicionales:
- Verificar la identidad de cada organización participante y la integridad de cada silo en el caso de las arquitecturas entre silos, así como la identidad y la integridad de cada dispositivo en el caso de las arquitecturas entre dispositivos.
- Limitar el alcance de las actualizaciones del modelo de AA global que pueden producir las organizaciones y los dispositivos participantes.
Fiabilidad
En esta sección se describen los factores de diseño que debes tener en cuenta al usar cualquiera de las arquitecturas de referencia de este documento para diseñar y crear una plataforma de aprendizaje federado en Google Cloud.
Cuando diseñes tu arquitectura de aprendizaje federado en Google Cloud, te recomendamos que sigas las directrices de esta sección para mejorar la disponibilidad y la escalabilidad de la carga de trabajo, así como para que tu arquitectura sea resistente a las interrupciones y los desastres.
GKE GKE admite varios tipos de clústeres que puedes adaptar a los requisitos de disponibilidad de tus cargas de trabajo y a tu presupuesto. Por ejemplo, puedes crear clústeres regionales que distribuyan el plano de control y los nodos en varias zonas de una región, o clústeres zonales que tengan el plano de control y los nodos en una sola zona. Tanto las arquitecturas de referencia entre silos como las multidispositivo se basan en clústeres de GKE regionales. Para obtener más información sobre los aspectos que debes tener en cuenta al crear clústeres de GKE, consulta las opciones de configuración de clústeres.
En función del tipo de clúster y de cómo se distribuyen el plano de control y los nodos del clúster entre regiones y zonas, GKE ofrece diferentes funciones de recuperación ante desastres para proteger tus cargas de trabajo frente a interrupciones zonales y regionales. Para obtener más información sobre las funciones de recuperación tras desastres de GKE, consulta el artículo Diseño de la recuperación tras desastres para interrupciones de la infraestructura en la nube: Google Kubernetes Engine.
Google Cloud Load Balancing: GKE admite varias formas de balancear la carga del tráfico a tus cargas de trabajo. Las implementaciones de GKE de las APIs Kubernetes Gateway y Kubernetes Service te permiten aprovisionar y configurar automáticamente Cloud Load Balancing para exponer de forma segura y fiable las cargas de trabajo que se ejecutan en tus clústeres de GKE.
En estas arquitecturas de referencia, todo el tráfico de entrada y salida pasa por las pasarelas de Cloud Service Mesh. Estas pasarelas te permiten controlar de forma precisa cómo fluye el tráfico dentro y fuera de tus clústeres de GKE.
Retos de fiabilidad del aprendizaje federado entre dispositivos
El aprendizaje federado entre dispositivos plantea varios problemas de fiabilidad que no se dan en los casos de aprendizaje federado entre silos. Entre ellas, se incluyen las siguientes:
- Conectividad del dispositivo poco fiable o intermitente
- Almacenamiento limitado en el dispositivo
- Computación y memoria limitadas
Una conectividad poco fiable puede provocar problemas como los siguientes:
- Actualizaciones obsoletas y divergencia del modelo: cuando los dispositivos tienen una conectividad intermitente, sus actualizaciones del modelo local pueden quedar obsoletas y representar información desactualizada en comparación con el estado actual del modelo global. Agregar actualizaciones obsoletas puede provocar una divergencia del modelo, en la que el modelo global se desvía de la solución óptima debido a incoherencias en el proceso de entrenamiento.
- Contribuciones desequilibradas y modelos sesgados: la comunicación intermitente puede provocar una distribución desigual de las contribuciones de los dispositivos participantes. Los dispositivos con una conectividad deficiente pueden enviar menos actualizaciones, lo que provoca una representación desequilibrada de la distribución de los datos subyacentes. Este desequilibrio puede sesgar el modelo global hacia los datos de los dispositivos con conexiones más fiables.
- Aumento de la sobrecarga de comunicación y del consumo de energía: la comunicación intermitente puede provocar un aumento de la sobrecarga de comunicación, ya que es posible que los dispositivos tengan que volver a enviar actualizaciones perdidas o dañadas. Este problema también puede aumentar el consumo de energía de los dispositivos, especialmente en aquellos con una duración de batería limitada, ya que es posible que tengan que mantener conexiones activas durante más tiempo para asegurar que las actualizaciones se transmitan correctamente.
Para mitigar algunos de los efectos causados por la comunicación intermitente, las arquitecturas de referencia de este documento se pueden usar con FCP.
Una arquitectura de sistema que ejecute el protocolo FCP se puede diseñar para cumplir los siguientes requisitos:
- Gestiona las rondas de larga duración.
- Habilita la ejecución especulativa (las rondas pueden empezar antes de que se reúna el número de clientes necesario, ya que se espera que se unan más pronto).
- Permite que los dispositivos elijan en qué tareas quieren participar. Este enfoque puede habilitar funciones como el muestreo sin reemplazo, que es una estrategia de muestreo en la que cada unidad de muestreo de una población solo tiene una oportunidad de ser seleccionada. Este enfoque ayuda a mitigar las contribuciones desequilibradas y los modelos sesgados.
- Extensible para técnicas de anonimización como la privacidad diferencial (DP) y la agregación de confianza (TAG).
Para ayudar a mitigar las limitaciones de almacenamiento y de computación de los dispositivos, puedes usar las siguientes técnicas:
- Entender cuál es la capacidad máxima disponible para ejecutar el cálculo de aprendizaje federado
- Saber cuántos datos se pueden almacenar en un momento determinado
- Diseñar el código de aprendizaje federado del lado del cliente para que funcione con la capacidad de cálculo y la RAM disponibles en los clientes
- Entender las consecuencias de quedarse sin espacio de almacenamiento e implementar un proceso para gestionar esta situación
Optimización de costes
En esta sección se ofrecen directrices para optimizar el coste de crear y ejecutar la plataforma de aprendizaje federado en Google Cloud que establezcas mediante esta arquitectura de referencia. Estas directrices se aplican a las dos arquitecturas que se describen en este documento.
Ejecutar cargas de trabajo en GKE puede ayudarte a optimizar los costes de tu entorno aprovisionando y configurando tus clústeres según los requisitos de recursos de tus cargas de trabajo. También habilita funciones que reconfiguran dinámicamente tus clústeres y nodos de clúster, como el escalado automático de nodos de clúster y pods, y el ajuste del tamaño de tus clústeres.
Para obtener más información sobre cómo optimizar el coste de tus entornos de GKE, consulta el artículo Prácticas recomendadas para ejecutar aplicaciones de Kubernetes de coste optimizado en GKE.
Eficiencia operativa
En esta sección se describen los factores que debes tener en cuenta para optimizar la eficiencia al usar esta arquitectura de referencia para crear y ejecutar una plataforma de aprendizaje federado en Google Cloud. Estas directrices se aplican a las dos arquitecturas que se describen en este documento.
Para aumentar la automatización y la monitorización de tu arquitectura de aprendizaje federado, te recomendamos que adoptes los principios de MLOps, que son los principios de DevOps en el contexto de los sistemas de aprendizaje automático. Practicar MLOps significa defender la automatización y la monitorización en todas las fases de la creación de sistemas de aprendizaje automático, como la integración, las pruebas, el lanzamiento, el despliegue y la gestión de la infraestructura. Para obtener más información sobre las operaciones de aprendizaje automático, consulta MLOps: Continuous delivery and automation pipelines in machine learning (Operaciones de aprendizaje automático: entrega continua y automatización de las canalizaciones de aprendizaje automático).
Optimización del rendimiento
En esta sección se describen los factores que debe tener en cuenta para optimizar el rendimiento de sus cargas de trabajo cuando utilice esta arquitectura de referencia para crear y ejecutar una plataforma de aprendizaje federado en Google Cloud. Estas directrices se aplican a las dos arquitecturas que se describen en este documento.
GKE admite varias funciones para ajustar y escalar automáticamente y manualmente tu entorno de GKE con el fin de satisfacer las demandas de tus cargas de trabajo y ayudarte a evitar el aprovisionamiento excesivo de recursos. Por ejemplo, puedes usar Recommender para generar estadísticas y recomendaciones que te ayuden a optimizar el uso de los recursos de GKE.
Cuando pienses en cómo escalar tu entorno de GKE, te recomendamos que diseñes planes a corto, medio y largo plazo sobre cómo tienes previsto escalar tus entornos y cargas de trabajo. Por ejemplo, ¿cómo tienes previsto aumentar tu huella de GKE en unas semanas, meses o años? Tener un plan preparado te ayuda a sacar el máximo partido de las funciones de escalabilidad que ofrece GKE, optimizar tus entornos de GKE y reducir los costes. Para obtener más información sobre cómo planificar la escalabilidad de los clústeres y las cargas de trabajo, consulta Acerca de la escalabilidad de GKE.
Para aumentar el rendimiento de tus cargas de trabajo de aprendizaje automático, puedes adoptar las unidades de procesamiento de tensor de Cloud (TPUs de Cloud), aceleradores de IA diseñados por Google y optimizados para el entrenamiento y la inferencia de modelos de IA grandes.
Implementación
Para implementar las arquitecturas de referencia entre silos y entre dispositivos que se describen en este documento, consulta el repositorio de GitHub Aprendizaje federado en Google Cloud.
Siguientes pasos
- Descubre cómo puedes implementar tus algoritmos de aprendizaje federado en la plataforma TensorFlow Federated.
- Consulta información sobre los avances y los problemas abiertos en el aprendizaje federado.
- Consulta información sobre el aprendizaje federado en el blog de IA de Google.
- Descubre cómo Google mantiene la privacidad intacta cuando usa el aprendizaje federado con información agregada y anonimizada para mejorar los modelos de aprendizaje automático.
- Consulta el artículo Towards Federated learning at scale (Hacia el aprendizaje federado a gran escala).
- Descubre cómo puedes implementar un flujo de procesamiento de MLOps para gestionar el ciclo de vida de los modelos de aprendizaje automático.
- Para obtener una descripción general de los principios y las recomendaciones de arquitectura específicos de las cargas de trabajo de IA y aprendizaje automático en Google Cloud, consulta la sección Perspectiva de IA y aprendizaje automático del framework Well-Architected.
- Para ver más arquitecturas de referencia, diagramas y prácticas recomendadas, consulta el centro de arquitectura de Cloud.
Colaboradores
Autores:
- Grace Mollison | Responsable de soluciones
- Marco Ferrari | Arquitecto de soluciones en la nube
Otros colaboradores:
- Chloé Kiddon | Ingeniera de software y responsable
- Laurent Grangeau | Arquitecto de soluciones
- Lilian Felix | Cloud Engineer
- Christiane Peters | Arquitecta de seguridad en la nube