データ コンシューマのユースケースに確実に対応するには、データメッシュ内のデータ プロダクトが慎重に設計、構築されていることが重要です。データ プロダクトの設計は、データ コンシューマがそのプロダクトを使用する方法と、データ コンシューマにそのプロダクトを公開する方法を定義することから始まります。データメッシュ内のデータ プロダクトは、データストア(ドメイン データ ウェアハウスやデータレイクなど)上に構築されます。データメッシュでデータ プロダクトを作成する場合、このプロセスで考慮すべきいくつかの重要な要素があります。 このドキュメントでは、それらの考慮事項について説明します。
このドキュメントは、 Google Cloudでデータメッシュを実装する方法を説明するシリーズの一部です。ここでは、データメッシュ内のアーキテクチャと機能、および Google Cloudで最新の分散データメッシュを構築するで説明するコンセプトをお読みになり、理解されていることを前提としています。
このシリーズは、次のパートから構成されています。
- データメッシュ内のアーキテクチャと機能
- データメッシュ用のセルフサービス データ プラットフォームを設計する
- データメッシュでデータ プロダクトを構築する(このドキュメント)
- データ メッシュでデータ プロダクトを検出して使用する
ドメイン データ ウェアハウスからデータ プロダクトを作成する場合は、データ プロデューサーがそれらのプロダクトの分析(消費)インターフェースを慎重に設計することをおすすめします。これらの消費インターフェースは、データ品質と運用パラメータに関する一連の保証に加え、プロダクト サポート モデルとプロダクト ドキュメントです。消費インターフェースを変更する場合は、通常、データ プロデューサーとおそらく複数のデータ コンシューマの両方が消費プロセスとアプリケーションを変更する必要があるため、消費インターフェースの変更のコストが高くなります。データ コンシューマは、データ プロデューサーとは別の組織部門に存在している可能性が高いため、変更の調整が困難になることがあります。
以降のセクションでは、ドメイン ウェアハウスの作成、消費インターフェースの定義、これらのインターフェースをデータ コンシューマに公開する際に考慮すべき事項に関する背景情報を説明します。
ドメイン データ ウェアハウスを作成する
スタンドアロン データ ウェアハウスの構築と、データ プロデューサー チームがデータ プロダクトの作成に使用するドメイン データ ウェアハウスの構築には、根本的な違いはありません。この 2 つの唯一の違いは、後者が消費インターフェースを介してデータのサブセットを公開することです。
多くのデータ ウェアハウスでは、運用データソースから取り込まれた元データに、エンリッチメントとデータ品質検証(キュレーション)のプロセスが実行されます。Dataplex Universal Catalog が管理するデータレイクでは通常、キュレートされたデータは、指定されたキュレートされたゾーンに保存されます。キュレーションが完了すると、データのサブセットは、いくつかの種類のインターフェースを介して、外部からドメインへの消費に対応可能である必要があります。このような消費インターフェースを定義するには、データメッシュ アプローチを初めて取り入れるドメインチームに一連のツールを提供する必要があります。これらのツールを使用すると、データ プロデューサーはセルフサービスで新しいデータ プロダクトを作成できます。おすすめの方法については、セルフサービス データ プラットフォームを設計するをご覧ください。
また、データ プロダクトは、一元的に定義されたデータ ガバナンス要件を満たす必要があります。これらの要件は、データ品質、データの可用性、ライフサイクル管理に影響します。これらの要件によってデータ プロダクトに対するデータ コンシューマの信頼が築かれ、データ プロダクトの利用が促進されます。そのため、これらの要件を実装するメリットは、サポートする労力に見合う価値があります。
消費インターフェースを定義する
データ プロデューサーが、1 つまたは 2 つのインターフェースを定義するのではなく、複数のタイプのインターフェースを使用することをおすすめします。データ分析の各インターフェース タイプには長所と短所があり、すべてに優れた単一のインターフェースはありません。データ プロデューサーは、各インターフェース タイプの適合性を評価する際に、次の点を考慮する必要があります。
- 必要なデータ処理を実行できる能力。
- 現在および将来のデータ コンシューマ ユースケースをサポートするスケーラビリティ。
- データ コンシューマに必要なパフォーマンス。
- 開発とメンテナンスのコスト。
- インターフェースの実行にかかるコスト。
- 組織で使用している言語とツールによるサポート。
- ストレージとコンビューティングの分離のサポート。
たとえば、ペタバイト規模のデータセットに対して分析クエリを実行できることがビジネス要件である場合、実用的なインターフェースは BigQuery ビューのみです。ただし、準リアルタイムのストリーミング データを提供するという要件の場合は、Pub/Sub ベースのインターフェースのほうが適しています。
これらのインターフェースの多くでは、既存のデータをコピーまたは複製する必要はありません。ほとんどはインターフェースは、Google Cloud 分析ツールの重要な機能であるストレージとコンピューティングを分離することもできます。これらのインターフェースを介して公開されるデータのコンシューマは、利用可能なコンピューティング リソースを使用してデータを処理します。データ プロデューサーが追加のインフラストラクチャのプロビジョニングを行う必要はありません。
さまざまな消費インターフェースがあります。データメッシュで使用される最も一般的なインターフェースを以下に示します。これらのインターフェースについては、以降のセクションで説明します。
なお、このドキュメントに記載されているインターフェースのリストは、すべてを網羅しているわけではないことにご注意ください。消費インターフェースについては、BigQuery Sharing(旧 Analytics Hub)など、他にも考慮すべきオプションがあります。ただし、これらの他のインターフェースについてはこのドキュメントでは扱いません。
承認済みのビューと関数
可能な限り、承認済みビューおよび承認済み関数(テーブル値関数を含む)介してデータ プロダクトを公開する必要があります。承認済みデータセットを使用すると、複数のビューを自動的に承認できます。承認済みビューを使用すると、コンシューマによるビューの使用に影響することなく、ベーステーブルへの直接アクセスを回避し、基になるテーブルとクエリを最適化できます。このインターフェースのコンシューマは、SQL を使用してデータをクエリします。次の図は、承認済みデータセットを消費インターフェースとして使用する方法を示しています。
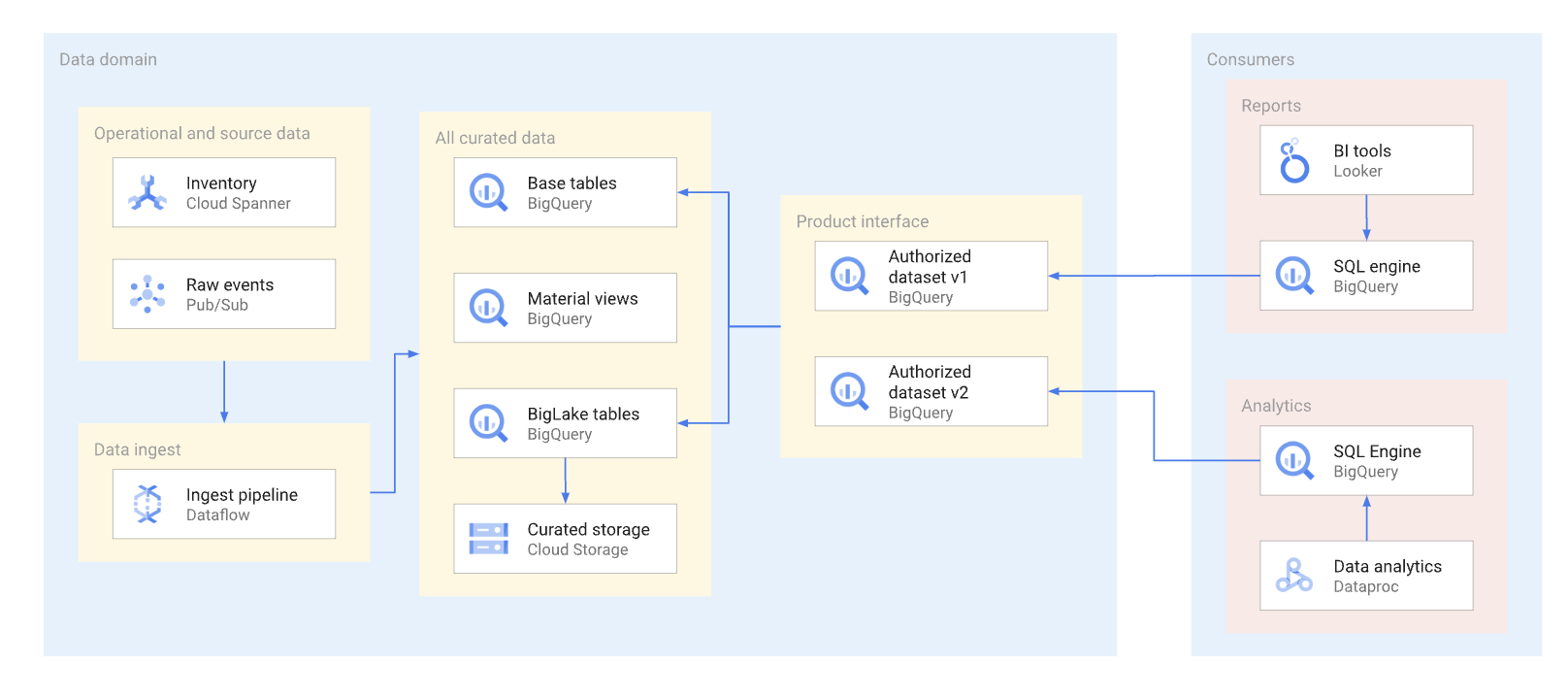
承認済みデータセットとビューを使用すると、インターフェースのバージョニングが簡単なります。次の図に示すように、データ プロデューサーが使用できる主なバージョニング アプローチは 2 つあります。
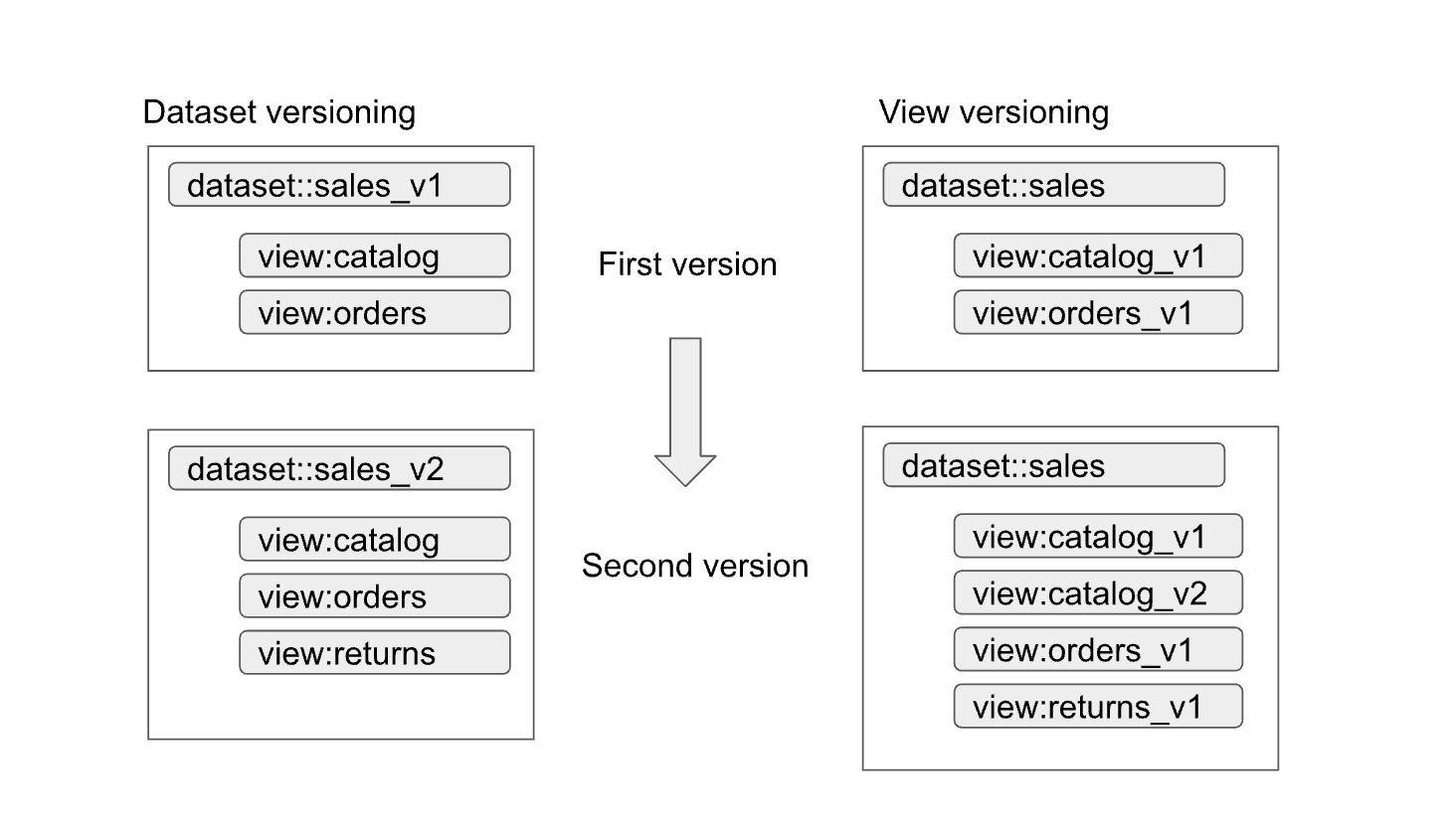
アプローチの概要は次のとおりです。
- データセットのバージョニング: このアプローチでは、データセット名をバージョニングします。
データセット内のビューと関数はバージョニングされません。バージョンに関係なく、ビューと関数には同じ名前を使用します。たとえば、販売データセットの最初のバージョンは、
catalogとordersの 2 つのビューを持つsales_v1という名前のデータセットで定義されています。2 番目のバージョンでは、販売データセットの名前がsales_v2に変更されました。このデータセット内の以前のビューは以前の名前を維持しますが、新しいスキーマが含まれています。2 番目のバージョンのデータセットでは、新しいビューが追加されたり、以前のビューが削除されたりすることもあります。 - ビューのバージョニング: このアプローチでは、データセット自体ではなく、データセット内のビューがバージョニングされます。たとえば、販売データセットでは、バージョンに関係なく
salesという名前が保持されます。ただし、データセット内のビューの名前は、ビューの新しいバージョン(catalog_v1、catalog_v2、orders_v1、orders_v2、orders_v3など)を反映するように変更されます。
組織に最適なバージョニングのアプローチは、組織のポリシーと、基になるデータの更新によって古くなったビューの数によって異なります。データセットのバージョニングは、プロダクトのメジャー アップデートが必要で、ほとんどのビューを変更する必要がある場合に最適です。ビューのバージョン管理により、異なるデータセットでは同じ名前のビューが少なくなりますが、データセット間の結合が正しく動作しているかどうかを確認する方法など、曖昧になる可能性があります。ハイブリッド アプローチは適切な妥協点になる可能性があります。ハイブリッド アプローチでは、単一のデータセット内で互換性のあるスキーマ変更が許可され、互換性のない変更では、新しいデータセットが必要になります。
BigLake テーブルに関する考慮事項
承認済みビューは、BigQuery テーブルだけでなく、BigLake テーブルでも作成できます。BigLake テーブルを使用すると、コンシューマは BigQuery SQL インターフェースを使用して Cloud Storage に保存されたデータをクエリできます。BigLake テーブルではきめ細かなアクセス制御がサポートされており、データ コンシューマが基盤となる Cloud Storage バケットに対する読み取り権限を持っている必要はありません。
データ プロデューサーは、BigLake テーブルについて次の点を考慮する必要があります。
- ファイル形式とデータ レイアウトの設計は、クエリのパフォーマンスに影響します。たとえば、Parquet や ORC などの列ベースの形式は、通常、JSON 形式や CSV 形式よりも分析クエリのパフォーマンスがはるかに優れています。
- Hive パーティション分割レイアウトを使用すると、パーティションをプルーニングして、パーティショニング列を使用するクエリを高速化できます。
- 設計段階では、ファイル数と、ファイルサイズに適したクエリ パフォーマンスも考慮する必要があります。
BigLake テーブルを使用するクエリがインターフェースのサービスレベル契約(SLA)要件を満たしておらず、調整できない場合は、次のアクションをおすすめします。
- データ コンシューマに対して公開する必要があるデータは、BigQuery ストレージに変換します。
- BigQuery テーブルを使用するように承認済みビューを再定義します。
一般に、このアプローチではデータ コンシューマが中断されることはなく、またクエリを変更する必要もありません。BigQuery ストレージのクエリは、BigLake テーブルでは不可能な手法を使用して最適化できます。たとえば、BigQuery ストレージでは、コンシューマはベーステーブルとは異なるパーティショニングとクラスタリングを持つマテリアライズド ビューをクエリでき、また BigQuery BI Engine を使用できます。
直接読み取り API
通常、データ プロデューサーがデータ コンシューマにベーステーブルへの直接読み取りアクセスを付与することはおすすめしませんが、パフォーマンスやコストなどの理由から、このようなアクセスを許可することは実用的である場合があります。そのような場合は、テーブル スキーマが安定しているようにするため、特に注意が必要です。
標準的なウェアハウス内のデータに直接アクセスする方法は 2 つあります。データ プロデューサーは、BigQuery Storage Read API、Cloud Storage JSON または XML API のいずれかを使用できます。次の図は、これらの API を使用する 2 つのコンシューマを表しています。1 つは機械学習(ML)のユースケースで、もう 1 つはデータ処理ジョブです。
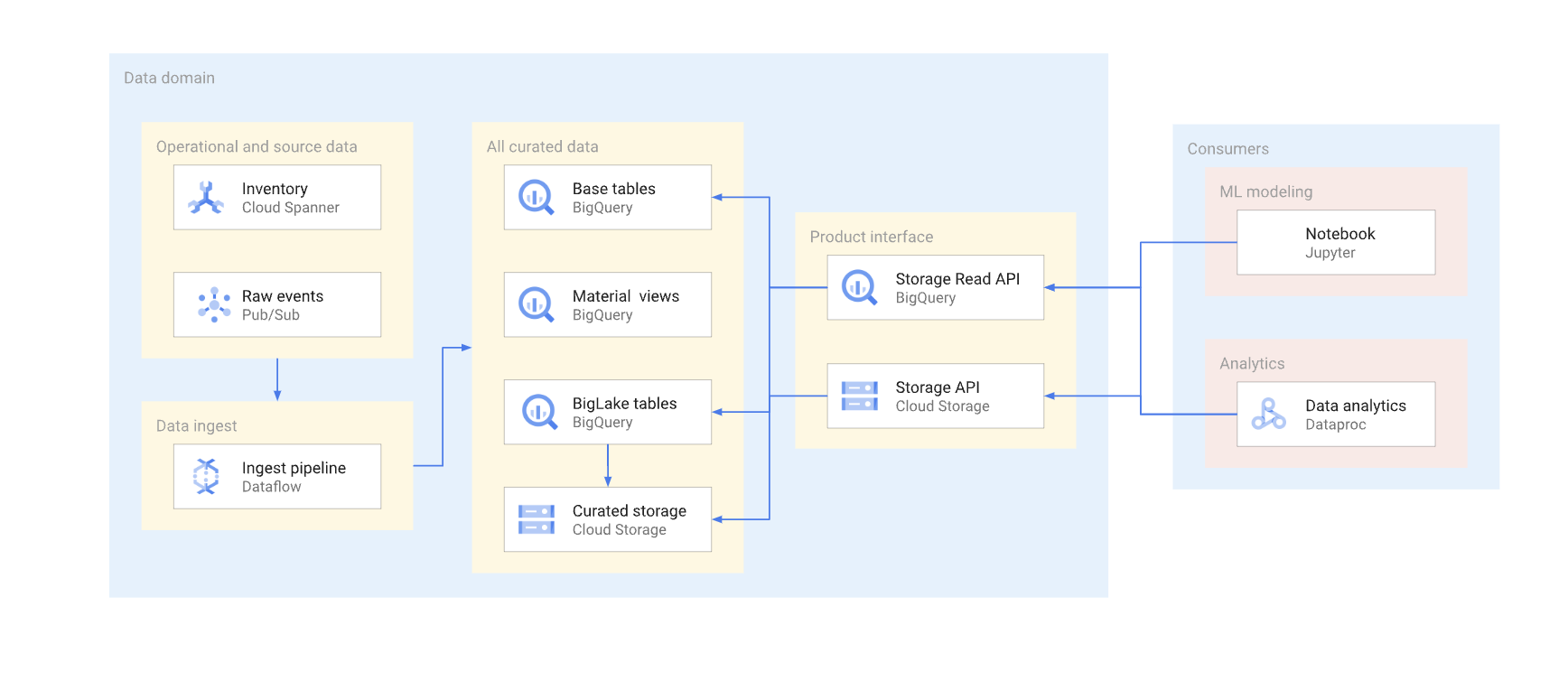
直接読み取りインターフェースのバージョニングは複雑です。通常、データ プロデューサーは別のスキーマを持つ別のテーブルを作成する必要があります。また、非推奨バージョンのすべてのデータ コンシューマが新しいバージョンに移行するまで、テーブルの 2 つのバージョンを維持する必要があります。コンシューマがテーブルの再構築と新しいスキーマへの切り替えを許容できる場合は、データの重複を回避できます。スキーマの変更に下位互換性がある場合は、ベーステーブルの移行を回避できます。たとえば、新しい列のみが追加され、これらの列のデータがすべての行でバックフィルされる場合は、ベーステーブルを移行する必要はありません。
Storage Read API と Cloud Storage API の違いの概要を以下で説明します。一般に、データ プロデューサーは可能な限り、分析アプリケーションとして BigQuery API を使用することをおすすめします。
Storage Read API: Storage Read API は、BigQuery テーブルのデータの読み取りと、BigLake テーブルの読み取りに使用できます。この API はフィルタリングときめ細かいアクセス制御をサポートしているため、安定したデータ分析や ML コンシューマに適したオプションです。
Cloud Storage API: データ プロデューサーが、特定の Cloud Storage バケットをデータ コンシューマと直接共有する必要がある場合があります。たとえば、データ プロデューサーは、データコンシューマがなんらかの理由で SQL インターフェースを使用できない場合、またはStorage Read API でサポートされていないデータ形式がバケットにある場合に、バケットを共有できます。
一般的に、データ プロデューサーがストレージ API を介した直接アクセスを許可することはおすすめしません。直接アクセスでは、フィルタリングやきめ細かいアクセス制御を行うことはできません。しかし、小規模で安定した(ギガバイトの)データセットに対する直接アクセスは有効な選択です。
バケットへの Pub/Sub アクセスを許可すると、データ コンシューマは簡単にデータをプロジェクトにコピーして処理できるようになります。一般に、回避できる場合はデータのコピーをおすすめしません。データのコピーが複数あると、ストレージ コストが増加し、メンテナンスとリネージのトラッキングのオーバーヘッドが増加します。
ストリームとしてのデータ
ドメインは、Pub/Sub トピックにストリーミング データをパブリッシュすることで、そのデータを公開できます。データを使用するサブスクライバーは、そのトピックに公開されたメッセージを使用するサブスクリプションを作成します。各サブスクライバーはデータを個別に受信、使用します。次の図は、そのようなデータ ストリームの例を示しています。
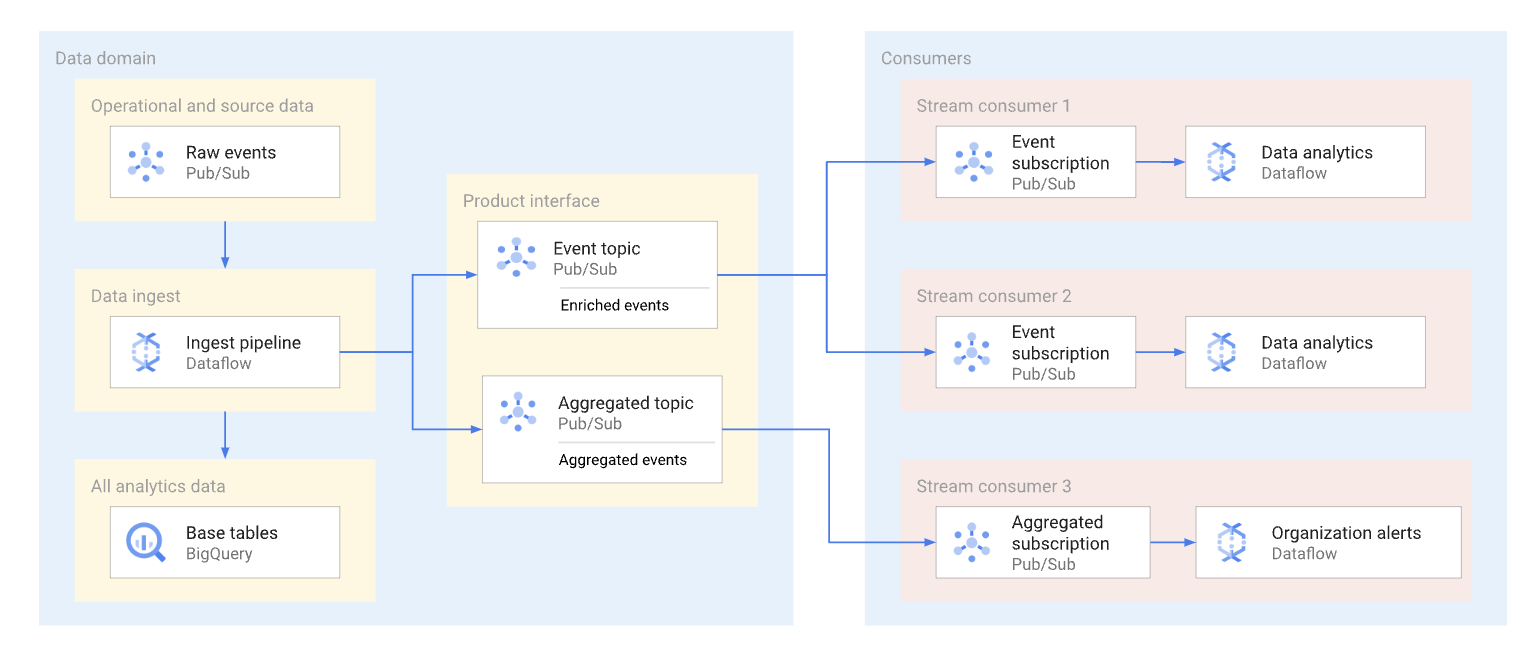
この図では、取り込みパイプラインが未加工のイベントを読み取り、拡張(キュレート)し、このキュレートされたデータを分析データストア(BigQuery ベーステーブル)に保存します。同時に、パイプラインは拡充されたイベントを専用トピックにパブリッシュします。このトピックは複数のサブスクライバーによって使用されます。各サブスクライバーは、これらのイベントをフィルタリングして、各自に関連するイベントのみを取得することがあります。また、パイプラインはイベント統計を集計して自身のトピックに公開し、別のデータ コンシューマが処理できるようにします。
Pub/Sub サブスクリプションのユースケースの例を次に示します。
- 拡充されたイベント(特定の顧客の注文に関するデータとともに顧客プロファイル情報全体を提供するなど)。
- 過去 15 分間の合計注文統計など、ほぼリアルタイムの集計通知。
- 注文数が前日の同じ期間と比べて 20% 減少した場合にアラートを生成するなど、ビジネスレベルのアラート。
- 特定の注文変更ステータスなどのデータ変更通知(変更データ キャプチャ通知のコンセプトと同様)。
データ プロデューサーが Pub/Sub メッセージに使用するデータ形式は、コストとメッセージの処理方法に影響します。データメッシュ アーキテクチャでの大量のストリームには、Avro または Protobuf 形式が適しています。データ プロデューサーがこれらの形式を使用する場合、Pub/Sub トピックにスキーマを割り当てることができます。スキーマにより、コンシューマは正しい形式のメッセージを受け取るようになります。
ストリーミング データ構造は常に変化する可能性があるため、このインターフェースのバージョニングでは、データ プロデューサーとデータ コンシューマの間での調整が必要になります。データ プロデューサーが取ることができる一般的なアプローチは次のとおりです。
- メッセージ構造が変更されるたびに、新しいトピックが作成されます。多くの場合、このトピックには明示的な Pub/Sub スキーマが含まれます。新しいインターフェースを必要とするデータ コンシューマは、新しいデータの使用を開始できます。メッセージ バージョンは、トピックの名前(
click_events_v1など)によって暗黙的に指定されます。メッセージ形式は厳密に型指定されます。同じトピック内のメッセージ間ではメッセージ形式に違いはありません。このアプローチのデメリットは、データ コンシューマが新しいサブスクリプションに切り替えられない可能性があることです。この場合、データ プロデューサーはしばらくの間、すべてのアクティブなトピックにイベントを公開し続ける必要があり、トピックをサブスクライブするデータ コンシューマはメッセージ フローのギャップに対処するか、重複を排除する必要があります。 - データは常に同じトピックにパブリッシュされます。ただし、メッセージの構造は変更される可能性があります。(ペイロードとは別に)Pub/Sub メッセージ属性はメッセージのバージョンを定義します(例:
v=1.0)。このアプローチにより、ギャップや重複に対処する必要がなくなります。ただし、すべてのデータ コンシューマが、新しいタイプのメッセージを受信できる状態である必要があります。このアプローチでは、データ プロデューサーも Pub/Sub トピック スキーマを使用できません。 - ハイブリッド アプローチ。メッセージ スキーマには、新しいフィールドに使用できる任意のデータ セクションを含めることができます。このアプローチでは、厳密に型指定されたデータを持つことと、頻繁で複雑なバージョン変更の間で、適切なバランスをとることができます。
データアクセス API
データ プロデューサーは、データ ウェアハウス内のベーステーブルに直接アクセスするためのカスタム API を構築できます。通常、これらのプロデューサーは、このカスタム API を REST または gRPC API として公開し、Cloud Run または Kubernetes クラスタにデプロイします。Apigee などの API ゲートウェイは、トラフィック スロットリングやキャッシュ レイヤなど、その他の追加機能も提供できます。これらの機能は、 Google Cloud 組織の外部のコンシューマにデータアクセス API を公開する際に役立ちます。データアクセス API の潜在的な候補は、レイテンシの影響を受けやすく、同時実行性に優れたクエリです。どちらのクエリも単一 API で比較的小さな結果を 1 つ返し、効果的にキャッシュできます。
データアクセス用のこのようなカスタム API の例を次に示します。
- テーブルまたはプロダクトの SLA 指標の組み合わせビュー。
- 特定のテーブルの上位 10 件の(キャッシュされている可能性がある)レコード。
- テーブル統計のデータセット(行の合計数、またはキー列内のデータ分布)。
アプリケーション API の構築に関する組織のガイドラインとガバナンスは、データ プロデューサーが作成するカスタム API にも適用されます。組織のガイドラインとガバナンスでは、ホスティング、モニタリング、アクセス制御、バージョニングなどの問題に対処する必要があります。
カスタム API のデメリットは、このインターフェースのホスティングに必要な追加のインフラストラクチャと、カスタム API のコーディングおよびメンテナンスをデータ プロデューサーが担当する点です。データ プロデューサーが、カスタム データアクセス API の作成を決定する前に、他のオプションを調べておくことをおすすめします。たとえば、データ プロデューサーは BigQuery BI Engine を使用してレスポンスのレイテンシを短縮し、同時実行性を高めることができます。
Looker Blocks
ビジネス インテリジェンス(BI)ツールで頻繁に使用される Looker などのプロダクトでは、BI ツール固有のウィジェットのセットを維持すると役立つことがあります。データ プロデューサー チームはドメインで使用されている基礎となるデータモデルを認識しているため、事前に構築された可視化セットの作成と維持に最適です。
Looker の場合、この可視化は一連の Looker Blocks(事前構築された LookML データモデル)になります。Looker Blocks は、コンシューマがホストするダッシュボードに簡単に組み込めます。
ML モデル
データドメインで作業するチームは、データを深く理解し、データに関する知識を持っているため、多くの場合、ドメインデータでトレーニングされる ML モデルを構築して維持するための適なチームです。これらの ML モデルは、次のようないくつかのインターフェースを介して公開できます。
- BigQuery ML モデルを専用のデータセットにデプロイし、BigQuery バッチ予測のためにデータ コンシューマと共有できます。
- BigQuery ML モデルは、Vertex AI にエクスポートしてオンライン予測に使用できます。
消費インターフェース用のデータ ロケーションに関する考慮事項
データ プロデューサーがデータ プロダクトの消費インターフェースを定義する際の重要な考慮事項は、データ ロケーションです。一般に、コストを最小限に抑えるために、データは保存されているリージョンと同じリージョンで処理する必要があります。このアプローチは、クロスリージョンのデータ下り(外向き)料金の防止に役立ちます。このアプローチではデータ消費のレイテンシも最小になります。このような理由から、通常、マルチリージョンの BigQuery ロケーションに保存されているデータは、データ プロダクトとして公開するのに最適です。
ただしパフォーマンス上の理由から、Cloud Storage に保存され、BigLake テーブルまたは直接読み取り API を介して公開されるデータは、リージョン バケットに保存する必要があります。
あるプロダクトで公開され、あるリージョンに配置されているデータを、別のリージョンの別のドメインのデータと結合する必要がある場合、データ コンシューマは次の制限を考慮する必要があります。
- BigQuery SQL を使用するクロスリージョン クエリはサポートされていません。データの主な利用方法が BigQuery SQL の場合、クエリ内のすべてのテーブルが同じロケーションに存在している必要があります。
- BigQuery の定額料金のコミットメントはリージョン別です。あるリージョンのプロジェクトで定額料金のコミットメントのみを使用しているものの、別のリージョンのデータ プロダクトにクエリを行う場合、オンデマンド料金が適用されます。
- データ コンシューマは、直接読み取り API を使用して別のリージョンからデータを読み取ることができます。ただし、クロスリージョンのネットワーク下り(外向き)料金が適用され、大規模なデータ転送ではデータ コンシューマにレイテンシが発生する可能性があります。
リージョン間でアクセス頻度が高いデータをそれらのリージョンにレプリケートすることで、プロダクト コンシューマによるクエリのコストとレイテンシを低減できます。たとえば、BigQuery のデータセットを他のリージョンにコピーできます。ただし、データは必要な場合にのみコピーしてください。データ プロデューサーは、データをコピーするときに、利用可能なプロダクト データのサブセットのみを複数のリージョンで利用できるようにすることをおすすめします。このアプローチは、レプリケーション レイテンシとコストを最小限に抑えるうえで役立ちます。このアプローチでは、明示的に呼び出されるデータ ロケーション リージョンと、複数のバージョンの消費インターフェースを用意する必要が生じる場合があります。たとえば BigQuery の承認済みビューは、sales_eu_v1 や sales_us_v1 などの名前で公開できます。
Pub/Sub トピックを使用するデータ ストリーム インターフェースでは、メッセージが保存されているリージョンとは異なるリージョンでメッセージを利用するために、追加のレプリケーション ロジックは必要ありません。ただし、この場合はクロスリージョンの下り(外向き)料金が適用されます。
データ コンシューマへの消費インターフェースの公開
このセクションでは、潜在的なコンシューマが消費インターフェースを検出可能にする方法について説明します。Data Catalog は、組織がデータ検出とメタデータ管理サービスを提供する際に使用できるフルマネージド サービスです。データ プロデューサーは、データ プロダクトの消費インターフェースを検索可能にして、適切なメタデータでアノテーションを付け、プロダクト コンシューマがセルフサービスでアクセスできるようにする必要があります。水
以降のセクションでは、各インターフェース タイプが Data Catalog エントリとしてどのように定義されるかについて説明します。
BigQuery ベースの SQL インターフェース
テクニカル メタデータ(完全修飾されたテーブル名やテーブル スキーマなど)は、Storage Read API で利用可能な承認済みビュー、BigLake ビュー、BigQuery テーブルに自動的に登録されます。データ プロデューサーが、データ プロダクト ドキュメントで、データ コンシューマを支援するための追加情報も提供することをおすすめします。 たとえば、ユーザーがエントリのプロダクト ドキュメントを見つけられるように、データ プロデューサーはエントリに適用されたタグの 1 つに URL を追加できます。プロデューサーは以下のものも提供できます。
- クエリフィルタで使用されるクラスタ化列のセット。
- 論理列挙型を持つフィールドの列挙値(型がフィールド記述の一部として指定されていない場合)。
- 他のテーブルとのサポートされる結合。
データ ストリーム
Pub/Sub トピックは Data Catalog に自動的に登録されます。ただしデータ プロデューサーは、データ プロダクトのドキュメントでスキーマを記述する必要があります。
Cloud Storage API
Data Catalog は、Cloud Storage ファイル エントリとそのスキーマの定義をサポートしています。データレイク ファイルセットが Dataplex Universal Catalog によって管理されている場合、そのファイルセットは Data Catalog に自動的に登録されます。Dataplex Universal Catalog に関連付けられていないファイルセットは、別の方法で追加されます。
その他のインターフェース
カスタム エントリを作成することで、Data Catalog から組み込みサポートがない他のインターフェースを追加できます。
次のステップ
- データメッシュ アーキテクチャのリファレンス実装を参照する。
- BigQuery の詳細を確認する。
- Dataplex について読む。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。