En este documento se describen varias arquitecturas que proporcionan alta disponibilidad para las implementaciones de PostgreSQL en Google Cloud. La alta disponibilidad es la medida de la resiliencia del sistema en respuesta a un fallo de la infraestructura subyacente. En este documento, la alta disponibilidad hace referencia a la disponibilidad de los clústeres de PostgreSQL en una sola región de la nube o en varias regiones, según la arquitectura de alta disponibilidad.
Este documento está dirigido a administradores de bases de datos, arquitectos de soluciones en la nube e ingenieros de DevOps que quieran saber cómo aumentar la fiabilidad de la capa de datos de PostgreSQL mejorando el tiempo de actividad general del sistema. En este documento se explican los conceptos relevantes para ejecutar PostgreSQL en Compute Engine. En este documento no se explica cómo usar bases de datos gestionadas, como Cloud SQL para PostgreSQL y AlloyDB para PostgreSQL.
Si un sistema o una aplicación requieren un estado persistente para gestionar solicitudes o transacciones, la capa de persistencia de datos (la capa de datos) debe estar disponible para gestionar correctamente las solicitudes de consultas o mutaciones de datos. El tiempo de inactividad en la capa de datos impide que el sistema o la aplicación realicen las tareas necesarias.
En función de los objetivos de nivel de servicio de tu sistema, es posible que necesites una arquitectura que proporcione un mayor nivel de disponibilidad. Hay más de una forma de conseguir la alta disponibilidad, pero, en general, se aprovisiona una infraestructura redundante a la que se puede acceder rápidamente desde la aplicación.
En este documento se tratan los siguientes temas:
- Definición de términos relacionados con los conceptos de bases de datos de alta disponibilidad.
- Opciones de topologías de PostgreSQL con alta disponibilidad.
- Información contextual para tener en cuenta cada opción de arquitectura.
Terminología
Los siguientes términos y conceptos son estándar en el sector y resultan útiles para comprender aspectos que van más allá del ámbito de este documento.
- replication
-
Proceso por el que las transacciones de escritura (
INSERT,UPDATEoDELETE) y los cambios de esquema (lenguaje de definición de datos [DDL]) se capturan, se registran y, a continuación, se aplican de forma fiable y secuencial a todos los nodos de réplica de la base de datos de nivel inferior de la arquitectura. - nodo principal
- El nodo que proporciona una lectura con el estado más actualizado de los datos persistentes. Todas las escrituras de la base de datos deben dirigirse a un nodo principal.
- nodo de réplica (secundario)
- Una copia online del nodo de la base de datos principal. Los cambios se replican de forma síncrona o asíncrona en los nodos de réplica desde el nodo principal. Puedes leer datos de los nodos de réplica sabiendo que los datos pueden retrasarse ligeramente debido a la latencia de replicación.
- retraso de replicación
- Una medición en número de secuencia de registro (LSN), ID de transacción o tiempo. El retraso de la réplica expresa la diferencia entre el momento en que se aplican las operaciones de cambio a la réplica y el momento en que se aplican al nodo principal.
- archivado continuo
- Copia de seguridad incremental en la que la base de datos guarda continuamente transacciones secuenciales en un archivo.
- Registro de escritura previa (WAL)
- Un registro de escritura anticipada (WAL) es un archivo de registro que registra los cambios en los archivos de datos antes de que se apliquen a los archivos. En caso de que se produzca un fallo en el servidor, WAL es una forma estándar de ayudar a garantizar la integridad y la durabilidad de los datos de tus escrituras.
- Registro WAL
- Registro de una transacción que se ha aplicado a la base de datos. Un registro WAL se formatea y se almacena como una serie de registros que describen los cambios a nivel de página del archivo de datos.
- Número de secuencia de registro (LSN)
- Las transacciones crean registros WAL que se añaden al archivo WAL. La posición en la que se produce la inserción se denomina número de secuencia de registro (LSN). Es un entero de 64 bits representado como dos números hexadecimales separados por una barra (XXXXXXXX/YYZZZZZZ). La "Z" representa la posición de desplazamiento en el archivo WAL.
- archivos de segmento
- Archivos que contienen tantos registros WAL como sea posible, en función del tamaño de archivo que configures. Los archivos de segmento tienen nombres de archivo que aumentan de forma monótona y un tamaño de archivo predeterminado de 16 MB.
- replicación síncrona
-
Forma de replicación en la que el servidor principal espera a que la réplica
confirme que los datos se han escrito en el registro de transacciones de la réplica
antes de confirmar una confirmación al cliente. Cuando ejecutas la replicación de streaming, puedes usar la opción
synchronous_commitde PostgreSQL, que te ayuda a asegurar la coherencia entre tu servidor principal y la réplica. - replicación asíncrona
- Tipo de replicación en el que el servidor principal no espera a que la réplica confirme que la transacción se ha recibido correctamente antes de confirmar una confirmación al cliente. La replicación asíncrona tiene una latencia menor que la replicación síncrona. Sin embargo, si el principal falla y sus transacciones confirmadas no se transfieren a la réplica, existe la posibilidad de que se pierdan datos. La replicación asíncrona es el modo de replicación predeterminado en PostgreSQL, ya sea mediante el envío de registros basado en archivos o la replicación de streaming.
- Envío de registros basado en archivos
- Método de replicación de PostgreSQL que transfiere los archivos de segmento WAL del servidor de base de datos principal a la réplica. El principal funciona en modo de archivado continuo, mientras que cada servicio de espera funciona en modo de recuperación continua para leer los archivos WAL. Este tipo de replicación es asíncrono.
- replicación en streaming
- Método de replicación en el que la réplica se conecta a la principal y recibe continuamente una secuencia de cambios. Como las actualizaciones llegan a través de un flujo, este método mantiene la réplica más actualizada con la principal en comparación con la replicación de envío de registros. Aunque la replicación es asíncrona de forma predeterminada, también puedes configurar la replicación síncrona.
- replicación física en streaming
- Método de replicación que transporta los cambios a la réplica. Este método usa los registros WAL que contienen los cambios de datos físicos en forma de direcciones de bloques de disco y cambios byte a byte.
- replicación lógica en streaming
- Método de replicación que captura los cambios en función de su identidad de replicación (clave principal), lo que permite tener más control sobre cómo se replican los datos en comparación con la replicación física. Debido a las restricciones de la replicación lógica de PostgreSQL, la replicación lógica de streaming requiere una configuración especial para la alta disponibilidad. En esta guía se habla de la replicación física estándar y no de la replicación lógica.
- Tiempo de actividad
- Porcentaje del tiempo que un recurso está operativo y puede enviar una respuesta a una solicitud.
- detección de fallos
- Proceso para identificar que se ha producido un fallo en la infraestructura.
- failover
- Proceso de promoción de la infraestructura de copia de seguridad o de espera (en este caso, el nodo de réplica) para que se convierta en la infraestructura principal. Durante la conmutación por error, el nodo de réplica se convierte en el nodo principal.
- cambio
- El proceso de ejecutar una conmutación por error manual en un sistema de producción. Una conmutación por error comprueba que el sistema funciona correctamente o retira el nodo principal actual del clúster para realizar tareas de mantenimiento.
- objetivo de tiempo de recuperación (RTO)
- Tiempo real transcurrido para que se complete el proceso de conmutación por error de la capa de datos. El RTO depende del tiempo que se considere aceptable desde el punto de vista de la empresa.
- objetivo de punto de recuperación (RPO)
- La cantidad de pérdida de datos (en tiempo real transcurrido) que puede soportar el nivel de datos como resultado de una conmutación por error. El RPO depende de la cantidad de datos que se pueden perder desde el punto de vista de la empresa.
- fallback
- Proceso de restauración del nodo principal anterior una vez que se ha solucionado la condición que ha provocado una conmutación por error.
- Autorreparación
- Capacidad de un sistema para resolver problemas sin que un operador humano tenga que realizar acciones externas.
- partición de red
- Condición en la que dos nodos de una arquitectura (por ejemplo, los nodos principal y de réplica) no pueden comunicarse entre sí a través de la red.
- cerebro dividido
- Condición que se produce cuando dos nodos creen simultáneamente que son el nodo principal.
- grupo de nodos
- Un conjunto de recursos de computación que proporcionan un servicio. En este documento, ese servicio es el nivel de persistencia de datos.
- Nodo testigo o de quórum
- Un recurso de computación independiente que ayuda a un grupo de nodos a determinar qué hacer cuando se produce una condición de cerebro dividido.
- elecciones primarias o de líderes
- Proceso por el que un grupo de nodos con reconocimiento entre pares, incluidos los nodos de testigo, determina qué nodo debe ser el nodo principal.
Cuándo plantearse una arquitectura de alta disponibilidad
Las arquitecturas de alta disponibilidad ofrecen una mayor protección contra el tiempo de inactividad de la capa de datos en comparación con las configuraciones de bases de datos de un solo nodo. Para seleccionar la mejor opción para tu caso práctico empresarial, debes conocer tu tolerancia a los tiempos de inactividad y las ventajas e inconvenientes de las distintas arquitecturas.
Usa una arquitectura de alta disponibilidad cuando quieras aumentar el tiempo de actividad de la capa de datos para cumplir los requisitos de fiabilidad de tus cargas de trabajo y servicios. Si tu entorno tolera cierto tiempo de inactividad, una arquitectura de alta disponibilidad puede introducir costes y complejidad innecesarios. Por ejemplo, los entornos de desarrollo o de prueba no suelen necesitar una alta disponibilidad de nivel de base de datos.
Ten en cuenta tus requisitos de alta disponibilidad
A continuación, se incluyen varias preguntas que te ayudarán a decidir qué opción de alta disponibilidad de PostgreSQL es la más adecuada para tu empresa:
- ¿Qué nivel de disponibilidad quieres conseguir? ¿Necesitas una opción que permita que tu servicio siga funcionando durante un fallo de una sola zona o de toda la región? Algunas opciones de alta disponibilidad se limitan a una región, mientras que otras pueden abarcar varias regiones.
- ¿Qué servicios o clientes dependen de tu nivel de datos y cuál es el coste para tu empresa si hay un tiempo de inactividad en el nivel de persistencia de datos? Si un servicio solo está dirigido a clientes internos que requieren un uso ocasional del sistema, es probable que tenga requisitos de disponibilidad más bajos que un servicio orientado al cliente final que atiende a los clientes de forma continua.
- ¿Cuál es tu presupuesto operativo? El coste es un factor importante: para proporcionar alta disponibilidad, es probable que aumenten los costes de infraestructura y almacenamiento.
- ¿Hasta qué punto debe automatizarse el proceso y con qué rapidez debe producirse la conmutación por error? ¿Cuál es tu RTO? Las opciones de alta disponibilidad varían en función de la rapidez con la que el sistema puede conmutar por error y estar disponible para los clientes.
- ¿Puedes permitirte perder datos como consecuencia de la conmutación por error? (¿Cuál es tu RPO?) Debido a la naturaleza distribuida de las topologías de alta disponibilidad, existe un equilibrio entre la latencia de confirmación y el riesgo de pérdida de datos debido a un fallo.
Cómo funciona la alta disponibilidad
En esta sección se describe la replicación de streaming y la replicación de streaming síncrona en las que se basan las arquitecturas de alta disponibilidad de PostgreSQL.
Replicación en streaming
La replicación continua es un método de replicación en el que la réplica se conecta a la principal y recibe continuamente un flujo de registros WAL. En comparación con la replicación de envío de registros, la replicación de streaming permite que la réplica esté más actualizada con la principal. PostgreSQL ofrece replicación de streaming integrada a partir de la versión 9. Muchas soluciones de alta disponibilidad de PostgreSQL usan la replicación de streaming integrada para proporcionar el mecanismo que permite que varios nodos de réplica de PostgreSQL se mantengan sincronizados con el principal. Varias de estas opciones se describen en la sección Arquitecturas de alta disponibilidad de PostgreSQL, que aparece más adelante en este documento.
Cada nodo de réplica requiere recursos de computación y almacenamiento específicos. La infraestructura del nodo de réplica es independiente de la del principal. Puedes usar nodos de réplica como copias de seguridad activas para responder a consultas de clientes de solo lectura. Este enfoque permite equilibrar la carga de las consultas de solo lectura entre la réplica principal y una o varias réplicas.
La replicación de streaming es asíncrona de forma predeterminada. El primario no espera la confirmación de una réplica antes de confirmar la confirmación de una transacción al cliente. Si una principal sufre un fallo después de confirmar la transacción, pero antes de que una réplica la reciba, la replicación asíncrona puede provocar una pérdida de datos. Si la réplica se convierte en una nueva principal, no se producirá ninguna transacción de este tipo.
Replicación en streaming síncrona
Puedes configurar la réplica de streaming como síncrona eligiendo una o varias réplicas para que sean de espera síncronas. Si configuras tu arquitectura para la replicación síncrona, el nodo principal no confirma una confirmación de transacción hasta que el nodo de réplica reconoce la persistencia de la transacción. La replicación de streaming síncrona proporciona una mayor durabilidad a cambio de una mayor latencia de las transacciones.
La opción de configuración
synchronous_commit
también le permite configurar los siguientes niveles de durabilidad de réplica progresiva para la transacción:
local: las réplicas de espera síncronas no participan en la confirmación de la confirmación. El nodo principal confirma las confirmaciones de transacciones después de que los registros de WAL se escriban y se vacíen en su disco local. Las confirmaciones de transacciones en la réplica principal no implican réplicas de espera. Las transacciones pueden perderse si se produce algún error en el primario.on[predeterminado]: las réplicas de espera síncronas escriben las transacciones confirmadas en su WAL antes de enviar la confirmación a la principal. Si se usa la configuraciónon, la transacción solo se puede perder si se producen errores de almacenamiento simultáneos en la réplica principal y en todas las réplicas de espera síncronas. Como las réplicas solo envían una confirmación después de escribir registros WAL, los clientes que consulten la réplica no verán los cambios hasta que los registros WAL correspondientes se apliquen a la base de datos de la réplica.remote_write: las réplicas en espera síncronas confirman la recepción del registro WAL a nivel del SO, pero no garantizan que el registro WAL se haya escrito en el disco. Comoremote_writeno garantiza que se haya escrito el WAL, la transacción puede perderse si se produce un error tanto en la principal como en la secundaria antes de que se escriban los registros.remote_writetiene una durabilidad inferior a la opciónon.remote_apply: las réplicas de espera síncronas confirman la recepción de la transacción y la aplicación correcta a la base de datos antes de confirmar la confirmación de la transacción al cliente. Si usas la configuraciónremote_apply, te aseguras de que la transacción se conserve en la réplica y de que los resultados de las consultas del cliente incluyan inmediatamente los efectos de la transacción.remote_applyofrece mayor durabilidad y coherencia en comparación cononyremote_write.
La opción de configuración synchronous_commit funciona con la opción de configuración synchronous_standby_names, que especifica la lista de servidores de reserva que participan en el proceso de replicación síncrona. Si no se especifica ningún nombre de réplica en espera síncrona, las confirmaciones de transacciones no esperan a la replicación.
Arquitecturas de alta disponibilidad de PostgreSQL
En el nivel más básico, la alta disponibilidad de la capa de datos consta de lo siguiente:
- Un mecanismo para identificar si se produce un fallo en el nodo principal.
- Proceso para llevar a cabo una conmutación por error en la que el nodo de réplica se convierte en un nodo principal.
- Un proceso para cambiar el enrutamiento de consultas de forma que las solicitudes de la aplicación lleguen al nuevo nodo principal.
- Opcionalmente, un método para volver a la arquitectura original mediante nodos primarios y de réplica previos a la conmutación por error con sus capacidades originales.
En las siguientes secciones se ofrece una descripción general de las siguientes arquitecturas de alta disponibilidad:
- Plantilla de Patroni
- Extensión y servicio pg_auto_failover
- Grupos de instancias gestionados con estado y discos persistentes regionales
Estas soluciones de alta disponibilidad minimizan el tiempo de inactividad si se produce una interrupción de la infraestructura o de la zona. Cuando elijas entre estas opciones, equilibra la latencia de confirmación y la durabilidad según las necesidades de tu empresa.
Un aspecto fundamental de una arquitectura de alta disponibilidad es el tiempo y el esfuerzo manual que se requieren para preparar un nuevo entorno de espera para la conmutación por error o la restauración posteriores. De lo contrario, el sistema solo puede resistir un fallo y el servicio no tiene protección frente a una infracción del SLA. Te recomendamos que selecciones una arquitectura de alta disponibilidad que pueda realizar conmutaciones por error o conmutaciones manuales con la infraestructura de producción.
Alta disponibilidad con la plantilla de Patroni
Patroni es una plantilla de software de código abierto (con licencia MIT) madura y con mantenimiento activo que te proporciona las herramientas para configurar, desplegar y operar una arquitectura de alta disponibilidad de PostgreSQL. Patroni proporciona un estado de clúster compartido y una configuración de arquitectura que se conserva en un almacén de configuración distribuido (DCS). Entre las opciones para implementar un DCS se incluyen las siguientes: etcd, Consul, Apache ZooKeeper o Kubernetes. En el siguiente diagrama se muestran los componentes principales de un clúster de Patroni.
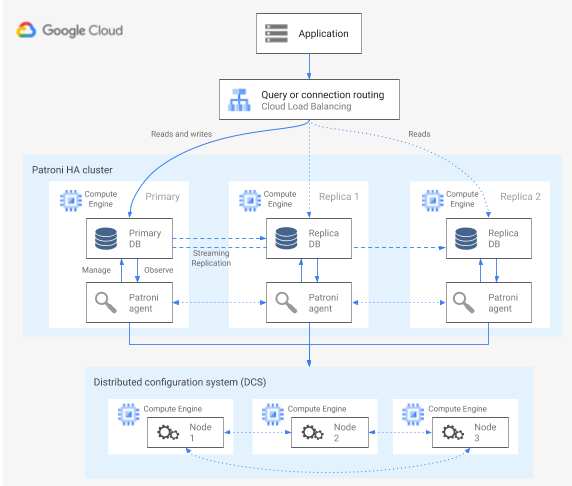
Imagen 1. Diagrama de los componentes principales de un clúster de Patroni.
En la figura 1, los balanceadores de carga están delante de los nodos de PostgreSQL, y los agentes de DCS y Patroni operan en los nodos de PostgreSQL.
Patroni ejecuta un proceso de agente en cada nodo de PostgreSQL. El proceso del agente gestiona el proceso de PostgreSQL y la configuración del nodo de datos. El agente de Patroni se coordina con otros nodos a través del DCS. El proceso del agente de Patroni también expone una API REST que puedes consultar para determinar el estado y la configuración del servicio PostgreSQL de cada nodo.
Para afirmar su rol de miembro del clúster, el nodo principal actualiza periódicamente la clave de líder en el DCS. La clave de líder incluye un tiempo de vida (TTL). Si el TTL caduca sin que se produzca una actualización, la clave de líder se elimina del DCS y se inicia la elección del líder para seleccionar un nuevo primario del grupo de candidatos.
En el siguiente diagrama se muestra un clúster correcto en el que el nodo A actualiza correctamente el bloqueo de líder.
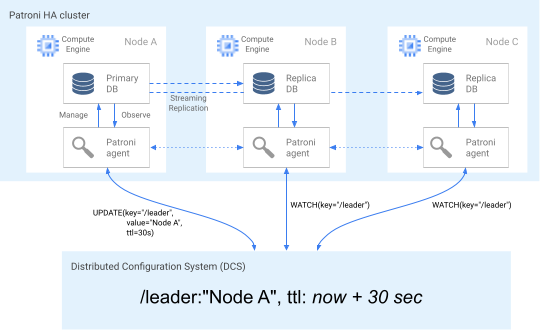
Imagen 2. Diagrama de un clúster en buen estado.
En la figura 2 se muestra un clúster correcto: los nodos B y C observan mientras el nodo A actualiza correctamente la clave de líder.
Detección de fallos
El agente de Patroni comunica continuamente su estado actualizando su clave en el DCS. Al mismo tiempo, el agente valida el estado de PostgreSQL. Si detecta un problema, aísla el nodo cerrándose o lo degrada a réplica. Como se muestra en el siguiente diagrama, si el nodo dañado es el principal, su clave de líder en el DCS caduca y se produce una nueva elección de líder.
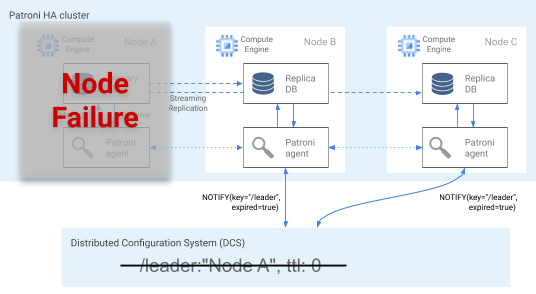
Imagen 3. Diagrama de un clúster deteriorado.
En la figura 3 se muestra un clúster dañado: un nodo principal inactivo no ha actualizado recientemente su clave de líder en el DCS y se ha notificado a las réplicas que no son líderes que la clave de líder ha caducado.
En los hosts Linux, Patroni también ejecuta un vigilante a nivel de SO en los nodos principales. Este monitor escucha los mensajes de mantenimiento activos del proceso del agente de Patroni. Si el proceso deja de responder y no se envía el keep alive, el watchdog reinicia el host. El watchdog ayuda a evitar una situación de cerebro dividido en la que el nodo de PostgreSQL sigue actuando como principal, pero la clave de líder del DCS ha caducado debido a un fallo del agente y se ha elegido otro principal (líder).
Proceso de conmutación por error
Si el bloqueo del líder caduca en el DCS, los nodos de réplica candidatos inician una elección de líder. Cuando una réplica detecta que falta un bloqueo de líder, comprueba su posición de replicación en comparación con las otras réplicas. Cada réplica usa la API REST para obtener las posiciones del registro WAL de los demás nodos de réplica, tal como se muestra en el siguiente diagrama.
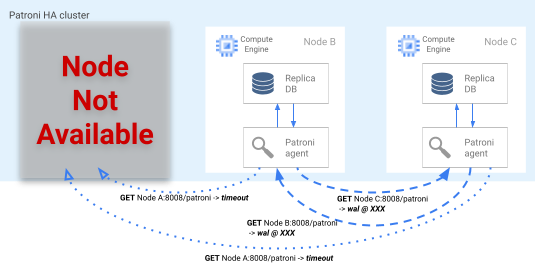
Imagen 4. Diagrama del proceso de conmutación por error de Patroni.
En la figura 4 se muestran las consultas de posición del registro WAL y los resultados correspondientes de los nodos de réplica activos. El nodo A no está disponible y los nodos B y C, que están en buen estado, devuelven la misma posición de WAL entre sí.
El nodo más actualizado (o los nodos, si están en la misma posición) intenta adquirir simultáneamente el bloqueo de líder en el DCS. Sin embargo, solo un nodo puede crear la clave de líder en el DCS. El primer nodo que cree correctamente la clave de líder es el ganador de la elección de líder, como se muestra en el siguiente diagrama. También puedes designar candidatos de conmutación por error preferidos
configurando la etiqueta failover_priority
en los archivos de configuración.
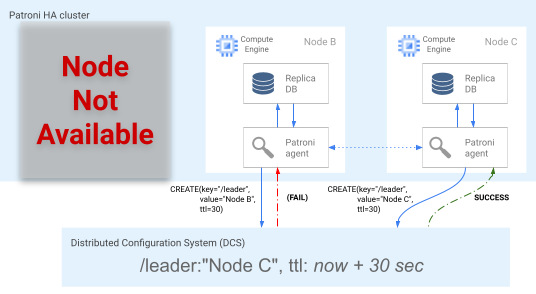
Imagen 5. Diagrama de la carrera de líderes.
En la figura 5 se muestra una carrera de líderes: dos candidatos a líder intentan obtener el bloqueo de líder, pero solo uno de los dos nodos, el nodo C, consigue definir la clave de líder y gana la carrera.
Cuando gana la elección del líder, la réplica se convierte en la nueva principal. A partir del momento en que la réplica se convierte en principal, la nueva principal actualiza la clave de líder en el DCS para conservar el bloqueo de líder, y los demás nodos actúan como réplicas.
Patroni también proporciona la patronictlherramienta de control
que te permite ejecutar cambios para probar el proceso de conmutación por error de los nodos.
Esta herramienta ayuda a los operadores a probar sus configuraciones de alta disponibilidad en producción.
Enrutamiento de consultas
El proceso del agente de Patroni que se ejecuta en cada nodo expone los endpoints de la API REST, que revelan el rol del nodo actual: principal o réplica.
| Endpoint REST | Código de retorno HTTP si es primario | Código de retorno HTTP si es una réplica |
|---|---|---|
/primary |
200 |
503 |
/replica |
503 |
200 |
Como las comprobaciones del estado pertinentes cambian sus respuestas si un nodo concreto cambia su rol, una comprobación del estado del balanceador de carga puede usar estos endpoints para informar sobre el enrutamiento del tráfico de los nodos primario y de réplica. El proyecto Patroni proporciona configuraciones de plantilla para un balanceador de carga como HAProxy. El balanceador de carga de red de paso a través interno puede usar estas mismas comprobaciones del estado para ofrecer funciones similares.
Proceso alternativo
Si se produce un fallo en un nodo, el clúster se queda en un estado degradado. El proceso de respaldo de Patroni ayuda a restaurar un clúster de alta disponibilidad a un estado correcto después de una conmutación por error. El proceso de fallback gestiona la vuelta del clúster a su estado original inicializando automáticamente el nodo afectado como réplica del clúster.
Por ejemplo, un nodo puede reiniciarse debido a un fallo en el sistema operativo o en la infraestructura subyacente. Si el nodo es el principal y tarda más que el TTL de la clave de líder en reiniciarse, se activa una elección de líder y se selecciona y se asciende un nuevo nodo principal. Cuando se inicia el proceso principal de Patroni obsoleto, detecta que no tiene el bloqueo de líder, se degrada automáticamente a réplica y se une al clúster con esa capacidad.
Si se produce un error irrecuperable en un nodo, como un error de zona poco probable, debes iniciar un nuevo nodo. Un operador de base de datos puede iniciar manualmente un nuevo nodo o puedes usar un grupo de instancias gestionado (MIG) regional con estado con un número mínimo de nodos para automatizar el proceso. Una vez creado el nuevo nodo, Patroni detecta que forma parte de un clúster y lo inicializa automáticamente como réplica.
Alta disponibilidad con la extensión y el servicio pg_auto_failover
pg_auto_failover es una extensión de PostgreSQL de código abierto (licencia de PostgreSQL) que se desarrolla activamente. pg_auto_failover configura una arquitectura de alta disponibilidad ampliando las funciones de PostgreSQL. pg_auto_failover no tiene ninguna dependencia aparte de PostgreSQL.
Para usar la extensión pg_auto_failover con una arquitectura de alta disponibilidad, necesitas al menos tres nodos, cada uno de ellos con PostgreSQL y la extensión habilitada. Cualquiera de los nodos puede fallar sin que esto afecte al tiempo de actividad del grupo de bases de datos. Un conjunto de nodos gestionados por pg_auto_failover se denomina formación. En el siguiente diagrama se muestra una arquitectura de pg_auto_failover.
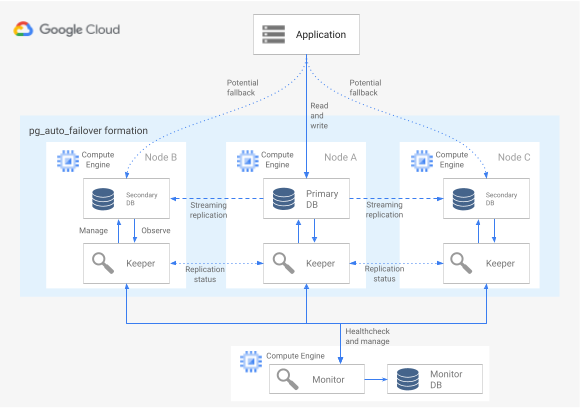
Imagen 6. Diagrama de una arquitectura de pg_auto_failover.
En la figura 6 se muestra una arquitectura de pg_auto_failover que consta de dos componentes principales: el servicio Monitor y el agente Keeper. Tanto Keeper como Monitor se incluyen en la extensión pg_auto_failover.
Servicio de monitorización
El servicio Monitor de pg_auto_failover se implementa como una extensión de PostgreSQL. Cuando el servicio crea un nodo Monitor, inicia una instancia de PostgreSQL con la extensión pg_auto_failover habilitada. El monitor mantiene el estado global de la formación, obtiene el estado de comprobación del estado de los nodos de datos de PostgreSQL miembros y coordina el grupo mediante las reglas establecidas por una máquina de estados finitos (MEF). De acuerdo con las reglas de la MEF para las transiciones de estado, el monitor comunica instrucciones a los nodos del grupo para acciones como ascender, descender y cambios de configuración.
Agente de Keeper
En cada nodo de datos de pg_auto_failover, la extensión inicia un proceso de agente de Keeper. Este proceso de Keeper observa y gestiona el servicio PostgreSQL. El Keeper envía actualizaciones de estado al nodo Monitor y recibe y ejecuta acciones que el Monitor envía en respuesta.
De forma predeterminada, pg_auto_failover configura todos los nodos de datos secundarios del grupo como réplicas síncronas. El número de réplicas síncronas necesarias para una confirmación se basa en la configuración de number_sync_standby que hayas definido en el monitor.
Detección de fallos
Los agentes de Keeper de los nodos de datos primario y secundario se conectan periódicamente al nodo Monitor para comunicar su estado actual y comprobar si hay alguna acción que ejecutar. El nodo de monitor también se conecta a los nodos de datos para realizar una comprobación del estado ejecutando las llamadas a la API del protocolo PostgreSQL (libpq), imitando la aplicación cliente de PostgreSQL pg_isready(). Si ninguna de estas acciones se completa correctamente tras un periodo de tiempo (30 segundos de forma predeterminada), el nodo Monitor determina que se ha producido un error en el nodo de datos. Puedes cambiar la configuración de PostgreSQL para personalizar los tiempos de monitorización y el número de reintentos. Para obtener más información, consulta Conmutación por error y tolerancia a fallos.
Si se produce un fallo en un solo nodo, se cumple una de las siguientes condiciones:
- Si el nodo de datos en mal estado es primario, el monitor inicia una conmutación por error.
- Si el nodo de datos en mal estado es secundario, el monitor inhabilita la réplica síncrona del nodo en mal estado.
- Si el nodo que ha fallado es el nodo de monitorización, no se puede realizar una conmutación por error automática. Para evitar este único punto de fallo, debes asegurarte de que se hayan implementado las medidas de monitorización y recuperación ante desastres adecuadas.
En el siguiente diagrama se muestran los casos de fallo y los estados de resultado de formación que se describen en la lista anterior.
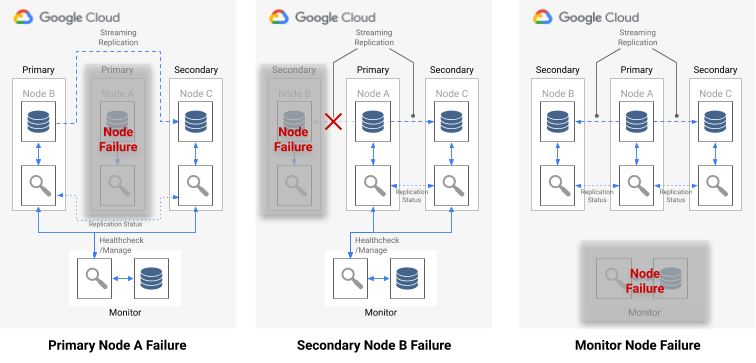
Imagen 7. Diagrama de los casos de error de pg_auto_failover.
Proceso de conmutación por error
Cada nodo de la base de datos del grupo tiene las siguientes opciones de configuración que determinan el proceso de conmutación por error:
replication_quorum: una opción booleana. Sireplication_quorumse define comotrue, el nodo se considera un posible candidato de conmutación por error.candidate_priority: un valor entero entre 0 y 100.candidate_prioritytiene un valor predeterminado de 50 que puedes cambiar para influir en la prioridad de conmutación por error. Los nodos se priorizan como posibles candidatos a conmutación por error en función del valor decandidate_priority. Los nodos que tienen un valor decandidate_prioritymás alto tienen una prioridad más alta. El proceso de conmutación por error requiere que al menos dos nodos tengan una prioridad de candidato distinta de cero en cualquier formación de pg_auto_failover.
Si se produce un error en el nodo principal, se tienen en cuenta los nodos secundarios para ascender a principales si tienen una replicación síncrona activa y si son miembros del replication_quorum.
Los nodos secundarios se tienen en cuenta para la promoción según los siguientes criterios progresivos:
- Nodos con la prioridad de candidato más alta
- En espera con la posición del registro WAL más avanzada publicada en el monitor
- Selección aleatoria como último recurso para deshacer el empate
Un candidato de conmutación por error es un candidato con retraso cuando no ha publicado la posición LSN más avanzada en el WAL. En este caso, pg_auto_failover coordina un paso intermedio en el mecanismo de conmutación por error: el candidato con retraso obtiene los bytes WAL que faltan de un nodo de espera que tiene la posición LSN más avanzada. A continuación, se asciende el nodo de reserva. Postgres permite esta operación porque la replicación en cascada permite que cualquier nodo de espera actúe como nodo upstream de otro nodo de espera.
Enrutamiento de consultas
pg_auto_failover no ofrece ninguna función de enrutamiento de consultas del lado del servidor.
En su lugar, pg_auto_failover se basa en el enrutamiento de consultas del lado del cliente que usa el controlador de cliente oficial de PostgreSQL, libpq.
Cuando defines el URI de conexión, el controlador puede aceptar varios hosts en su palabra clave host.
La biblioteca de cliente que usa tu aplicación debe envolver libpq o implementar la capacidad de proporcionar varios hosts para que la arquitectura admita una conmutación por error totalmente automatizada.
Procesos de conmutación por error y de conmutación
Cuando el proceso de Keeper reinicia un nodo fallido o inicia un nuevo nodo de sustitución, comprueba el nodo de monitorización para determinar la siguiente acción que debe realizar. Si un nodo reiniciado que ha fallado era anteriormente el principal y el monitor ya ha elegido un nuevo principal según el proceso de conmutación por error, Keeper reinicializa este principal obsoleto como réplica secundaria.
pg_auto_failover proporciona la herramienta pg_autoctl, que te permite ejecutar cambios para probar el proceso de conmutación por error de los nodos. Además de permitir que los operadores prueben sus configuraciones de alta disponibilidad en producción, la herramienta te ayuda a restaurar un clúster de alta disponibilidad a un estado correcto después de una conmutación por error.
Alta disponibilidad con grupos de instancias gestionados con estado y discos persistentes regionales
En esta sección se describe un enfoque de alta disponibilidad que utiliza los siguientes Google Cloud componentes:
- Disco persistente regional. Cuando usas discos persistentes regionales, los datos se replican de forma síncrona entre dos zonas de una región, por lo que no es necesario que uses la replicación de streaming. Sin embargo, la alta disponibilidad se limita a dos zonas en una región.
- Grupos de instancias gestionados con reconocimiento del estado. Se usan dos MIGs con estado como parte de un plano de control para mantener en funcionamiento un nodo de PostgreSQL principal. Cuando la MIG con estado inicia una nueva instancia, puede conectar el disco persistente regional que ya tiene. En un momento dado, solo una de las dos MIGs tendrá una instancia en ejecución.
- Cloud Storage. Un objeto de un segmento de Cloud Storage contiene una configuración que indica cuál de los dos MIGs está ejecutando el nodo de base de datos principal y en qué MIG se debe crear una instancia de failover.
- Comprobaciones del estado y reparación automática de grupos de instancias gestionados. La comprobación del estado monitoriza el estado de la instancia. Si el nodo en ejecución deja de estar en buen estado, la comprobación del estado inicia el proceso de recuperación automática.
- Logging Cuando la reparación automática detiene el nodo principal, se registra una entrada en el registro. Las entradas de registro pertinentes se exportan a un tema de sumidero de Pub/Sub mediante un filtro.
- Funciones de Cloud Run basadas en eventos. El mensaje de Pub/Sub activa las funciones de Cloud Run. Las funciones de Cloud Run usan la configuración de Cloud Storage para determinar qué acciones se deben llevar a cabo en cada MIG con estado.
- Balanceador de carga de red de paso a través interno. El balanceador de carga proporciona la ruta a la instancia en ejecución del grupo. De esta forma, se oculta al cliente el cambio de dirección IP de una instancia provocado por la recreación de la instancia.
En el siguiente diagrama se muestra un ejemplo de alta disponibilidad con MIGs con estado y discos persistentes regionales:

Imagen 8. Diagrama de una alta disponibilidad que usa grupos de instancias gestionados con reconocimiento del estado y discos persistentes regionales.
En la figura 8 se muestra un nodo principal en buen estado que sirve tráfico de clientes. Los clientes se conectan a la dirección IP estática del balanceador de carga de red de paso a través interno. El balanceador de carga enruta las solicitudes de los clientes a la VM que se ejecuta como parte del MIG. Los volúmenes de datos se almacenan en discos persistentes regionales montados.
Para implementar este enfoque, crea una imagen de VM con PostgreSQL que se inicie en la inicialización para usarla como plantilla de instancia del MIG. También debes configurar una comprobación del estado basada en HTTP (como HAProxy o pgDoctor) en el nodo. Una comprobación de estado basada en HTTP ayuda a asegurarse de que tanto el balanceador de carga como el grupo de instancias puedan determinar el estado del nodo de PostgreSQL.
Disco persistente regional
Para aprovisionar un dispositivo de almacenamiento en bloques que proporcione la replicación síncrona de datos entre dos zonas de una región, puedes usar la opción de almacenamiento disco persistente regional de Compute Engine. Un disco persistente regional puede proporcionarte un componente básico para implementar una opción de alta disponibilidad de PostgreSQL que no dependa de la replicación de streaming integrada de PostgreSQL.
Si la instancia de máquina virtual de tu nodo principal deja de estar disponible debido a un fallo de la infraestructura o a una interrupción zonal, puedes forzar que el disco persistente regional se conecte a una instancia de máquina virtual de tu zona de backup en la misma región.
Para adjuntar el disco persistente regional a una instancia de VM de tu zona de copia de seguridad, puedes hacer lo siguiente:
- Mantener una instancia de máquina virtual de reserva inactiva en la zona de copia de seguridad. Una instancia de VM de espera pasiva es una instancia de VM detenida que no tiene montado un disco persistente regional, pero es idéntica a la instancia de VM del nodo principal. Si se produce un fallo, se inicia la máquina virtual de espera inactiva y se monta el disco persistente regional. La instancia de espera pasiva y la instancia del nodo principal tienen los mismos datos.
- Crea un par de MIGs con estado mediante la misma plantilla de instancia. Los MIGs proporcionan comprobaciones de estado y forman parte del plano de control. Si el nodo principal falla, se crea una instancia de conmutación por error en el MIG de destino de forma declarativa. El MIG de destino se define en el objeto de Cloud Storage. Se usa una configuración por instancia para conectar el disco persistente regional.
Si la interrupción del servicio de datos se identifica rápidamente, la operación de conexión forzada suele completarse en menos de un minuto, por lo que se puede alcanzar un tiempo de recuperación medido en minutos.
Si tu empresa puede tolerar el tiempo de inactividad adicional necesario para detectar y comunicar una interrupción, y para realizar la conmutación por error manualmente, no es necesario que automatices el proceso de asociación forzada. Si tu tolerancia de RTO es menor, puedes automatizar el proceso de detección y conmutación por error. También puedes usar Cloud SQL para PostgreSQL, que proporciona una implementación totalmente gestionada de este enfoque de alta disponibilidad.
Proceso de detección de errores y conmutación por error
El enfoque de alta disponibilidad usa las funciones de reparación automática de los grupos de instancias para monitorizar el estado de los nodos mediante una comprobación del estado. Si se produce un error en la comprobación del estado, la instancia se considera que no está en buen estado y se detiene. Esta parada inicia el proceso de conmutación por error mediante Logging, Pub/Sub y la función de Cloud Run functions activada.
Para cumplir el requisito de que esta VM siempre tenga montado el disco regional, las funciones de Cloud Run configurarán una de las dos MIGs para crear una instancia en una de las dos zonas en las que esté disponible el disco persistente regional. Si falla un nodo, se inicia la instancia de sustitución en la zona alternativa según el estado conservado en Cloud Storage.

Imagen 9. Diagrama de un fallo por zonas en un MIG.
En la figura 9, el antiguo nodo principal de la zona A ha fallado y las funciones de Cloud Run han configurado el MIG B para lanzar una nueva instancia principal en la zona B. El mecanismo de detección de errores se configura automáticamente para monitorizar el estado del nuevo nodo principal.
Enrutamiento de consultas
El balanceador de carga de red de paso a través interno dirige a los clientes a la instancia que ejecuta el servicio PostgreSQL. El balanceador de carga usa la misma comprobación del estado que el grupo de instancias para determinar si la instancia está disponible para responder a las consultas. Si el nodo no está disponible porque se está recreando, las conexiones fallarán. Cuando la instancia vuelva a estar activa, las comprobaciones del estado empezarán a dar resultados positivos y las nuevas conexiones se dirigirán al nodo disponible. No hay nodos de solo lectura en esta configuración porque solo hay un nodo en ejecución.
Proceso alternativo
Si el nodo de la base de datos no supera una comprobación del estado debido a un problema de hardware subyacente, se vuelve a crear en otra instancia subyacente. En ese momento, la arquitectura vuelve a su estado original sin ningún paso adicional. Sin embargo, si se produce un fallo zonal, la configuración seguirá ejecutándose en un estado degradado hasta que se recupere la primera zona. Aunque es muy poco probable, si se producen fallos simultáneos en ambas zonas configuradas para la replicación de Persistent Disk regional y la MIG con estado, la instancia de PostgreSQL no podrá recuperarse y la base de datos no estará disponible para atender solicitudes durante la interrupción.
Comparación entre las opciones de alta disponibilidad
En las siguientes tablas se comparan las opciones de alta disponibilidad disponibles en Patroni, pg_auto_failover y los grupos de instancias gestionados con estado con discos persistentes regionales.
Configuración y arquitectura
| Patroni | pg_auto_failover | Grupos de instancias gestionados con estado con discos persistentes regionales |
|---|---|---|
|
Requiere una arquitectura de alta disponibilidad, una configuración de DCS, y monitorización y alertas. La configuración de agentes en nodos de datos es relativamente sencilla. |
No requiere ninguna dependencia externa aparte de PostgreSQL. Requiere un nodo dedicado como monitor. El nodo de monitorización requiere alta disponibilidad y recuperación ante desastres para asegurarse de que no sea un punto único de fallo (SPOF). | Arquitectura que consta exclusivamente de servicios Google Cloud. Solo se ejecuta un nodo de base de datos activo a la vez. |
Configurabilidad de alta disponibilidad
| Patroni | pg_auto_failover | Grupos de instancias gestionados con estado con discos persistentes regionales |
|---|---|---|
| Es extremadamente configurable: admite la replicación síncrona y asíncrona, y te permite especificar qué nodos deben ser síncronos y asíncronos. Incluye la gestión automática de los nodos síncronos. Permite configuraciones de alta disponibilidad multizona y multirregión. Se debe poder acceder al DCS. | Similar a Patroni: muy configurable. Sin embargo, como el monitor solo está disponible como una sola instancia, cualquier tipo de configuración debe tener en cuenta el acceso a este nodo. | Limitado a dos zonas de una sola región con replicación síncrona. |
Capacidad para gestionar particiones de red
| Patroni | pg_auto_failover | Grupos de instancias gestionados con estado con discos persistentes regionales |
|---|---|---|
| El aislamiento automático junto con un monitor a nivel de SO proporciona protección contra el cerebro dividido. Si no se puede conectar al DCS, el primario se degradará a réplica y se activará una conmutación por error para garantizar la durabilidad en lugar de la disponibilidad. | Usa una combinación de comprobaciones de estado de la instancia principal a la de monitorización y a la de réplica para detectar una partición de red y se degrada si es necesario. | No aplicable: solo hay un nodo de PostgreSQL activo a la vez, por lo que no hay partición de red. |
Coste
| Patroni | pg_auto_failover | Grupos de instancias gestionados con estado con discos persistentes regionales |
|---|---|---|
| El coste es elevado porque depende del DCS que elijas y del número de réplicas de PostgreSQL. La arquitectura de Patroni no añade costes significativos. Sin embargo, el gasto total se ve afectado por la infraestructura subyacente, que usa varias instancias de proceso para PostgreSQL y DCS. Como usa varias réplicas y un clúster de DCS independiente, esta opción puede ser la más cara. | Coste medio, ya que implica ejecutar un nodo de monitorización y al menos tres nodos de PostgreSQL (uno principal y dos réplicas). | Bajo coste, ya que solo se ejecuta un nodo de PostgreSQL en un momento dado. Solo pagas por una instancia de proceso. |
Configuración del cliente
| Patroni | pg_auto_failover | Grupos de instancias gestionados con estado con discos persistentes regionales |
|---|---|---|
| Es transparente para el cliente porque se conecta a un balanceador de carga. | Requiere que la biblioteca de cliente admita varias definiciones de host en la configuración porque no se puede poner fácilmente delante de un balanceador de carga. | Es transparente para el cliente porque se conecta a un balanceador de carga. |
Escalabilidad
| Patroni | pg_auto_failover | Grupos de instancias gestionados con estado con discos persistentes regionales |
|---|---|---|
| Gran flexibilidad a la hora de configurar las ventajas y desventajas de la escalabilidad y la disponibilidad. Para escalar las lecturas, puedes añadir más réplicas. | Similar a Patroni: se puede escalar la lectura añadiendo más réplicas. | Escalabilidad limitada, ya que solo se puede tener un nodo PostgreSQL activo a la vez. |
Automatización de la inicialización de nodos de PostgreSQL y la gestión de la configuración
| Patroni | pg_auto_failover | Grupos de instancias gestionados con estado con discos persistentes regionales |
|---|---|---|
Proporciona herramientas para gestionar la configuración de PostgreSQL (patronictl
edit-config) e inicializa automáticamente los nodos nuevos o reiniciados del clúster. Puedes inicializar nodos con
pg_basebackup u otras herramientas, como barman.
|
Inicializa los nodos automáticamente, pero solo se puede usar pg_basebackup al inicializar un nuevo nodo de réplica.
La gestión de la configuración se limita a las configuraciones relacionadas con pg_auto_failover.
|
Los grupos de instancias con estado y disco compartido eliminan la necesidad de inicializar los nodos de PostgreSQL. Como solo se ejecuta un nodo, la gestión de la configuración se realiza en un solo nodo. |
Personalización y variedad de funciones
| Patroni | pg_auto_failover | Grupos de instancias gestionados con estado con discos persistentes regionales |
|---|---|---|
|
Proporciona una interfaz de enlace para permitir que se llamen acciones definibles por el usuario en pasos clave, como en la degradación o en la promoción. Configurabilidad con muchas funciones, como la compatibilidad con diferentes tipos de DCS, diferentes formas de inicializar réplicas y diferentes formas de proporcionar la configuración de PostgreSQL. Te permite configurar clústeres de espera que admiten clústeres de réplicas en cascada para facilitar la migración entre clústeres. |
Limitado porque es un proyecto relativamente nuevo. | No aplicable |
Madurez
| Patroni | pg_auto_failover | Grupos de instancias gestionados con estado con discos persistentes regionales |
|---|---|---|
| Project está disponible desde el 2015 y lo usan en producción grandes empresas como Zalando y GitLab. | Proyecto relativamente nuevo anunciado a principios del 2019. | Compuesto íntegramente por productos Google Cloud disponibles de forma general. |
Prácticas recomendadas de mantenimiento y monitorización
Mantener y monitorizar tu clúster de alta disponibilidad de PostgreSQL es fundamental para garantizar la alta disponibilidad, la integridad de los datos y un rendimiento óptimo. En las siguientes secciones se ofrecen algunas prácticas recomendadas para monitorizar y mantener un clúster de alta disponibilidad de PostgreSQL.
Realizar pruebas periódicas de copias de seguridad y recuperación
Crea copias de seguridad de tus bases de datos PostgreSQL con regularidad y prueba el proceso de recuperación. De esta forma, se asegura la integridad de los datos y se minimiza el tiempo de inactividad en caso de interrupción. Prueba tu proceso de recuperación para validar tus copias de seguridad e identificar posibles problemas antes de que se produzca una interrupción.
Monitorizar servidores PostgreSQL y el desfase de replicación
Monitoriza tus servidores PostgreSQL para comprobar que están en funcionamiento. Monitoriza el retraso de replicación entre los nodos principal y de réplica. Una latencia excesiva puede provocar incoherencias en los datos y aumentar la pérdida de datos en caso de conmutación por error. Configura alertas para detectar aumentos significativos de la latencia e investiga la causa raíz rápidamente.
Las vistas pg_stat_replication y pg_replication_slots pueden ayudarte a monitorizar el retraso de la replicación.
Implementar el grupo de conexiones
La agrupación de conexiones puede ayudarte a gestionar las conexiones de bases de datos de forma eficiente. La agrupación de conexiones ayuda a reducir la sobrecarga de establecer nuevas conexiones, lo que mejora el rendimiento de las aplicaciones y la estabilidad del servidor de bases de datos. Herramientas como PGBouncer y Pgpool-II pueden proporcionar un pool de conexiones para PostgreSQL.
Implementar una monitorización exhaustiva
Para obtener información valiosa sobre tus clústeres de alta disponibilidad de PostgreSQL, establece sistemas de monitorización sólidos de la siguiente manera:
- Monitoriza métricas clave de PostgreSQL y del sistema, como la utilización de la CPU, el uso de memoria, la E/S de disco, la actividad de red y las conexiones activas.
- Recoge registros de PostgreSQL, incluidos los registros del servidor, los registros WAL y los registros de autovacuum, para realizar análisis detallados y solucionar problemas.
- Usa herramientas de monitorización y paneles de control para visualizar métricas y registros y así identificar problemas rápidamente.
- Integra métricas y registros con sistemas de alertas para recibir notificaciones proactivas de posibles problemas.
Para obtener más información sobre cómo monitorizar una instancia de Compute Engine, consulta la información general de Cloud Monitoring.
Siguientes pasos
- Consulta información sobre la configuración de alta disponibilidad de Cloud SQL.
- Consulta más información sobre las opciones de alta disponibilidad con discos persistentes regionales.
- Consulta información sobre Patroni.
- Consulta información sobre pg_auto_failover.
- Para ver más arquitecturas de referencia, diagramas y prácticas recomendadas, consulta el centro de arquitectura de Cloud.
Colaboradores
Autor: Alex Cârciu | Arquitecto de soluciones