Este documento descreve várias arquiteturas que oferecem alta disponibilidade (HA) para implementações do PostgreSQL no Google Cloud. A HA é a medida da capacidade de recuperação do sistema em resposta a falhas da infraestrutura subjacente. Neste documento, a HA refere-se à disponibilidade de clusters do PostgreSQL numa única região da nuvem ou entre várias regiões, consoante a arquitetura de HA.
Este documento destina-se a administradores de bases de dados, arquitetos de nuvem e engenheiros de DevOps que querem saber como aumentar a fiabilidade da camada de dados do PostgreSQL melhorando o tempo de atividade geral do sistema. Este documento aborda conceitos relevantes para a execução do PostgreSQL no Compute Engine. O documento não aborda a utilização de bases de dados geridas, como o Cloud SQL para PostgreSQL e o AlloyDB para PostgreSQL.
Se um sistema ou uma aplicação exigir um estado persistente para processar pedidos ou transações, a camada de persistência de dados (o nível de dados) tem de estar disponível para processar com êxito os pedidos de consultas ou mutações de dados. O tempo de inatividade na camada de dados impede que o sistema ou a aplicação execute as tarefas necessárias.
Consoante os objetivos ao nível do serviço (SLOs) do seu sistema, pode precisar de uma arquitetura que ofereça um nível de disponibilidade mais elevado. Existem várias formas de alcançar a HA, mas, em geral, aprovisiona uma infraestrutura redundante que pode tornar rapidamente acessível à sua aplicação.
Este documento aborda os seguintes tópicos:
- Definição dos termos relacionados com os conceitos da base de dados de HA.
- Opções para topologias PostgreSQL de HA.
- Informações contextuais para consideração de cada opção de arquitetura.
Terminologia
Os seguintes termos e conceitos são padrão da indústria e são úteis para compreender fins que vão além do âmbito deste documento.
- replicação
-
O processo através do qual as transações de escrita (
INSERT,UPDATEouDELETE) e as alterações ao esquema (linguagem de definição de dados (DDL)) são captadas, registadas e, em seguida, aplicadas em série a todos os nós de réplica da base de dados a jusante na arquitetura. - nó principal
- O nó que fornece uma leitura com o estado mais atualizado dos dados persistentes. Todas as escritas na base de dados têm de ser direcionadas para um nó principal.
- nó de réplica (secundário)
- Uma cópia online do nó da base de dados principal. As alterações são replicadas de forma síncrona ou assíncrona para os nós de réplica a partir do nó principal. Pode ler a partir de nós de réplica, tendo em atenção que os dados podem sofrer um ligeiro atraso devido ao intervalo de tempo da replicação.
- intervalo de tempo da replicação
- Uma medição, no número de sequência do registo (LSN), no ID da transação ou na hora. O intervalo de tempo da replicação expressa a diferença entre o momento em que as operações de alteração são aplicadas à réplica e o momento em que são aplicadas ao nó principal.
- arquivagem contínua
- Uma cópia de segurança incremental em que a base de dados guarda continuamente transações sequenciais num ficheiro.
- Registo de escrita antecipada (WAL)
- Um registo de escrita antecipada (WAL) é um ficheiro de registo que regista as alterações aos ficheiros de dados antes de as alterações serem efetivamente feitas aos ficheiros. Em caso de falha do servidor, o WAL é uma forma padrão de ajudar a garantir a integridade dos dados e a durabilidade das suas gravações.
- Registo WAL
- Um registo de uma transação que foi aplicada à base de dados. Um registo WAL é formatado e armazenado como uma série de registos que descrevem alterações ao nível da página do ficheiro de dados.
- Número de sequência do registo (LSN)
- As transações criam registos WAL que são anexados ao ficheiro WAL. A posição onde ocorre a inserção é denominada número de sequência do registo (LSN). É um número inteiro de 64 bits, representado como dois números hexadecimais separados por uma barra (XXXXXXXX/YYZZZZZZ). O "Z" representa a posição de desvio no ficheiro WAL.
- ficheiros de segmentos
- Ficheiros que contêm o maior número possível de registos WAL, consoante o tamanho do ficheiro que configurar. Os ficheiros de segmentos têm nomes de ficheiros que aumentam monotonicamente e um tamanho de ficheiro predefinido de 16 MB.
- replicação síncrona
-
Uma forma de replicação em que o servidor principal aguarda que a réplica
confirme que os dados foram escritos no registo de transações da réplica antes de
confirmar uma confirmação ao cliente. Quando executa a replicação de streaming, pode usar a opção
synchronous_commitdo PostgreSQL, que ajuda a garantir a consistência entre o servidor principal e a réplica. - replicação assíncrona
- Uma forma de replicação em que o servidor principal não aguarda que a réplica confirme que a transação foi recebida com êxito antes de confirmar uma confirmação ao cliente. A replicação assíncrona tem uma latência inferior em comparação com a replicação síncrona. No entanto, se o nó principal falhar e as respetivas transações comprometidas não forem transferidas para a réplica, existe a possibilidade de perda de dados. A replicação assíncrona é o modo de replicação predefinido no PostgreSQL, quer use o envio de registos baseado em ficheiros ou a replicação de streaming.
- Envio de registos com base em ficheiros
- Um método de replicação no PostgreSQL que transfere os ficheiros de segmento WAL do servidor de base de dados principal para a réplica. O serviço principal funciona no modo de arquivo contínuo, enquanto cada serviço de espera funciona no modo de recuperação contínua para ler os ficheiros WAL. Este tipo de replicação é assíncrono.
- replicação de streaming
- Um método de replicação em que a réplica se liga ao principal e recebe continuamente uma sequência contínua de alterações. Uma vez que as atualizações chegam através de um fluxo, este método mantém a réplica mais atualizada em relação à base de dados principal quando comparado com a replicação de envio de registos. Embora a replicação seja assíncrona por predefinição, pode configurar a replicação síncrona em alternativa.
- replicação de streaming física
- Um método de replicação que transporta as alterações para a réplica. Este método usa os registos WAL que contêm as alterações físicas aos dados sob a forma de endereços de blocos de disco e alterações byte a byte.
- replicação de streaming lógica
- Um método de replicação que capta as alterações com base na respetiva identidade de replicação (chave primária), o que permite um maior controlo sobre a forma como os dados são replicados em comparação com a replicação física. Devido a restrições na replicação lógica do PostgreSQL, a replicação de streaming lógico requer uma configuração especial para uma configuração de HA. Este guia aborda a replicação física padrão e não aborda a replicação lógica.
- tempo de atividade
- A percentagem de tempo em que um recurso está a funcionar e é capaz de fornecer uma resposta a um pedido.
- deteção de falhas
- O processo de identificação de que ocorreu uma falha de infraestrutura.
- ativação pós-falha
- O processo de promoção da infraestrutura de reserva ou em espera (neste caso, o nó de réplica) para se tornar a infraestrutura principal. Durante a comutação por falha, o nó de réplica torna-se o nó principal.
- comutação
- O processo de execução de uma comutação por falha manual num sistema de produção. Uma comutação testa se o sistema está a funcionar bem ou retira o nó principal atual do cluster para manutenção.
- objetivo de tempo de recuperação (OTR)
- A duração decorrida em tempo real para a conclusão do processo de comutação por falha da camada de dados. O RTO depende do tempo aceitável do ponto de vista empresarial.
- objetivo de ponto de recuperação (OPR)
- A quantidade de perda de dados (em tempo real decorrido) que o nível de dados vai suportar como resultado da comutação por falha. O RPO depende da quantidade de perda de dados que é aceitável do ponto de vista empresarial.
- alternativo
- O processo de reposição do nó principal anterior após a condição que causou uma comutação por falha ser corrigida.
- autorreparação
- A capacidade de um sistema resolver problemas sem ações externas por parte de um operador humano.
- partição de rede
- Uma condição em que dois nós numa arquitetura, por exemplo, os nós principal e de réplica, não conseguem comunicar entre si através da rede.
- cérebro dividido
- Uma condição que ocorre quando dois nós acreditam simultaneamente que são o nó principal.
- grupo de nós
- Um conjunto de recursos de computação que fornecem um serviço. Neste documento, esse serviço é a camada de persistência de dados.
- nó de testemunha ou quórum
- Um recurso de computação separado que ajuda um grupo de nós a determinar o que fazer quando ocorre uma condição de divisão de cérebro.
- eleição primária ou de líder
- O processo através do qual um grupo de nós com reconhecimento de pares, incluindo nós de testemunho, determina qual deve ser o nó principal.
Quando deve considerar uma arquitetura de HA
As arquiteturas de HA oferecem maior proteção contra o tempo de inatividade da camada de dados quando comparadas com configurações de base de dados de nó único. Para selecionar a melhor opção para o seu exemplo de utilização empresarial, tem de compreender a sua tolerância a tempo de inatividade e as respetivas compensações das várias arquiteturas.
Use uma arquitetura de AD quando quiser oferecer um tempo de atividade da camada de dados aumentado para cumprir os requisitos de fiabilidade das suas cargas de trabalho e serviços. Se o seu ambiente tolerar alguma indisponibilidade, uma arquitetura de HA pode introduzir custos e complexidade desnecessários. Por exemplo, os ambientes de desenvolvimento ou de teste raramente precisam de uma disponibilidade de nível elevado da base de dados.
Considere os seus requisitos de HA
Seguem-se várias perguntas para ajudar a decidir que opção de HA do PostgreSQL é melhor para a sua empresa:
- Que nível de disponibilidade espera alcançar? Precisa de uma opção que permita que o seu serviço continue a funcionar durante apenas uma zona ou uma falha regional completa? Algumas opções de HA estão limitadas a uma região, enquanto outras podem ser multirregionais.
- Que serviços ou clientes dependem do seu nível de dados e qual é o custo para a sua empresa se houver tempo de inatividade no nível de persistência de dados? Se um serviço se destinar apenas a clientes internos que requerem uma utilização ocasional do sistema, é provável que tenha requisitos de disponibilidade mais baixos do que um serviço virado para o cliente final que serve os clientes continuamente.
- Qual é o seu orçamento operacional? O custo é uma consideração importante: para fornecer HA, é provável que os custos de infraestrutura e armazenamento aumentem.
- Quão automatizado tem de ser o processo e com que rapidez tem de fazer a comutação por falha? (Qual é o seu RTO?) As opções de HA variam consoante a rapidez com que o sistema pode fazer failover e ficar disponível para os clientes.
- Pode perder dados como resultado da comutação por falha? (Qual é o seu RPO?) Devido à natureza distribuída das topologias de HA, existe uma relação de compromisso entre a latência de confirmação e o risco de perda de dados devido a uma falha.
Como funciona a HA
Esta secção descreve a replicação de streaming e streaming síncrono que estão na base das arquiteturas de HA do PostgreSQL.
Replicação de streaming
A replicação de streaming é uma abordagem de replicação na qual a réplica se liga à base de dados principal e recebe continuamente um fluxo de registos WAL. Em comparação com a replicação de envio de registos, a replicação de streaming permite que a réplica se mantenha mais atualizada com a principal. O PostgreSQL oferece replicação de streaming incorporada a partir da versão 9. Muitas soluções de HA do PostgreSQL usam a replicação de streaming incorporada para fornecer o mecanismo para que vários nós de réplica do PostgreSQL sejam mantidos sincronizados com o nó principal. Várias destas opções são abordadas na secção Arquiteturas de HA do PostgreSQL mais adiante neste documento.
Cada nó de réplica requer recursos de computação e armazenamento dedicados. A infraestrutura do nó de réplica é independente da principal. Pode usar nós de réplica como hot standbys para publicar consultas de clientes só de leitura. Esta abordagem permite o equilíbrio de carga de consultas de leitura apenas na base de dados principal e numa ou mais réplicas.
Por predefinição, a replicação de streaming é assíncrona. O servidor principal não aguarda uma confirmação de uma réplica antes de confirmar uma confirmação de transação ao cliente. Se um servidor principal sofrer uma falha depois de confirmar a transação, mas antes de uma réplica receber a transação, a replicação assíncrona pode resultar numa perda de dados. Se a réplica for promovida para se tornar uma nova principal, essa transação não está presente.
Replicação de streaming síncrona
Pode configurar a replicação de streaming como síncrona escolhendo uma ou mais réplicas para serem uma réplica de reserva síncrona. Se configurar a sua arquitetura para a replicação síncrona, o servidor principal não confirma a confirmação de uma transação até que a réplica reconheça a persistência da transação. A replicação de streaming síncrona oferece maior durabilidade em troca de uma latência de transação mais elevada.
A opção de configuração synchronous_commit também permite configurar os seguintes níveis de durabilidade de réplicas progressivas para a transação:
local: as réplicas em espera síncronas não estão envolvidas na confirmação da confirmação. O nó principal confirma as confirmações de transações depois de os registos WAL serem escritos e descarregados para o respetivo disco local. Os commits de transações no servidor principal não envolvem réplicas em espera. As transações podem ser perdidas se ocorrer alguma falha no dispositivo principal.on[predefinição]: as réplicas em espera síncronas escrevem as transações comprometidas no respetivo WAL antes de enviarem a confirmação à principal. A utilização da configuraçãoongarante que a transação só pode ser perdida se a réplica principal e todas as réplicas em espera síncronas sofrerem falhas de armazenamento simultâneas. Uma vez que as réplicas só enviam uma confirmação depois de escreverem registos WAL, os clientes que consultam a réplica não veem alterações até que os registos WAL respetivos sejam aplicados à base de dados da réplica.remote_write: as réplicas de standby síncronas confirmam a receção do registo WAL ao nível do SO, mas não garantem que o registo WAL foi escrito no disco. Uma vez queremote_writenão garante que a WAL foi escrita, a transação pode ser perdida se ocorrer uma falha no registo principal e secundário antes de os registos serem escritos.remote_writetem uma durabilidade inferior à opçãoon.remote_apply: as réplicas em espera síncronas confirmam a receção da transação e a aplicação bem-sucedida à base de dados antes de confirmarem a confirmação da transação ao cliente. A utilização da configuraçãoremote_applygarante que a transação é mantida na réplica e que os resultados da consulta do cliente incluem imediatamente os efeitos da transação.remote_applyoferece maior durabilidade e consistência em comparação comoneremote_write.
A opção de configuração synchronous_commit funciona com a opção de configuração synchronous_standby_names que especifica a lista de servidores em espera que participam no processo de replicação síncrona. Se não forem especificados nomes de espera síncronos, as confirmações de transações não aguardam a replicação.
Arquiteturas de HA do PostgreSQL
Ao nível mais básico, a HA da camada de dados consiste no seguinte:
- Um mecanismo para identificar se ocorre uma falha no nó principal.
- Um processo para realizar uma comutação por falha em que o nó da réplica é promovido a nó principal.
- Um processo para alterar o encaminhamento de consultas de modo que os pedidos da aplicação cheguem ao novo nó principal.
- Opcionalmente, um método para reverter para a arquitetura original através de nós primários e de réplica pré-failover nas respetivas capacidades originais.
As secções seguintes oferecem uma vista geral das seguintes arquiteturas de HA:
- O modelo Patroni
- Extensão e serviço pg_auto_failover
- MIGs com estado e disco persistente regional
Estas soluções de HA minimizam o tempo de inatividade se houver uma interrupção da infraestrutura ou zonal. Quando escolher entre estas opções, equilibre a latência de confirmação e a durabilidade de acordo com as necessidades da sua empresa.
Um aspeto crítico de uma arquitetura de HA é o tempo e o esforço manual necessários para preparar um novo ambiente de espera para uma comutação por falha ou uma alternativa subsequente. Caso contrário, o sistema só pode suportar uma falha e o serviço não tem proteção contra uma violação do SLA. Recomendamos que selecione uma arquitetura de HA que possa realizar comutações por falha manuais ou comutações com a infraestrutura de produção.
HA using the Patroni template
O Patroni é um modelo de software de código aberto (licenciado pela MIT) maduro e com manutenção ativa que lhe oferece as ferramentas para configurar, implementar e operar uma arquitetura de alta disponibilidade do PostgreSQL. O Patroni fornece um estado de cluster partilhado e uma configuração de arquitetura que é mantida numa loja de configuração distribuída (DCS). As opções para implementar um DCS incluem: etcd, Consul, Apache ZooKeeper ou Kubernetes. O diagrama seguinte mostra os principais componentes de um cluster do Patroni.
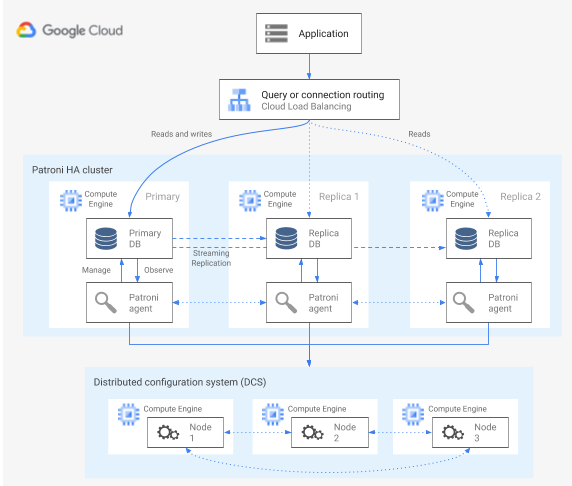
Figura 1. Diagrama dos principais componentes de um cluster do Patroni.
Na figura 1, os balanceadores de carga estão à frente dos nós do PostgreSQL, e os agentes DCS e Patroni operam nos nós do PostgreSQL.
O Patroni executa um processo de agente em cada nó do PostgreSQL. O processo do agente gere o processo do PostgreSQL e a configuração do nó de dados. O agente Patroni coordena-se com outros nós através do DCS. O processo do agente Patroni também expõe uma API REST que pode consultar para determinar o estado de funcionamento do serviço PostgreSQL e a configuração de cada nó.
Para afirmar a respetiva função de membro do cluster, o nó principal atualiza regularmente a chave principal no DCS. A chave principal inclui um tempo de vida (TTL). Se o TTL expirar sem uma atualização, a chave principal é removida do DCS e a eleição de líder começa a selecionar um novo principal do conjunto de candidatos.
O diagrama seguinte mostra um cluster em bom estado de funcionamento no qual o nó A atualiza com êxito o bloqueio do líder.
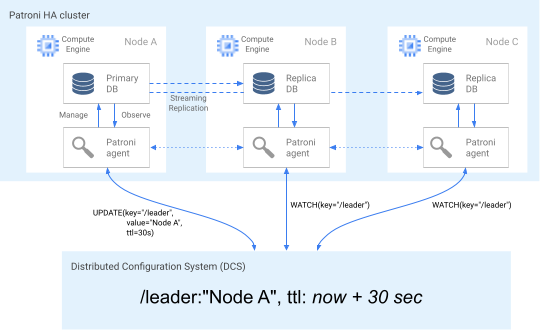
Figura 2. Diagrama de um cluster saudável.
A Figura 2 mostra um cluster saudável: o nó B e o nó C observam enquanto o nó A atualiza com êxito a chave principal.
Deteção de falhas
O agente Patroni comunica continuamente o respetivo estado atualizando a respetiva chave no DCS. Ao mesmo tempo, o agente valida o estado de funcionamento do PostgreSQL. Se o agente detetar um problema, isola o nó desligando-se ou rebaixa o nó para uma réplica. Conforme mostrado no diagrama seguinte, se o nó danificado for o principal, a respetiva chave principal no DCS expira e ocorre uma nova eleição de líder.
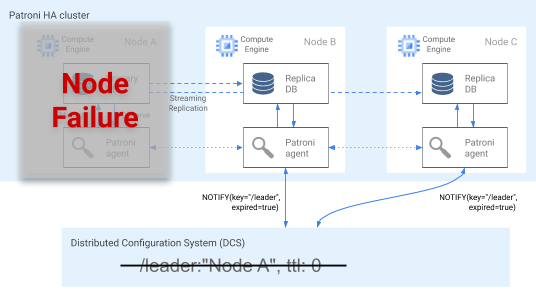
Figura 3. Diagrama de um cluster danificado.
A Figura 3 mostra um cluster danificado: um nó principal inativo não atualizou recentemente a respetiva chave principal no DCS e as réplicas não principais são notificadas de que a chave principal expirou.
Em anfitriões Linux, o Patroni também executa um monitor de temporizador ao nível do SO em nós principais. Este watchdog escuta mensagens de keep-alive do processo do agente Patroni. Se o processo deixar de responder e o sinal de manutenção não for enviado, o watchdog reinicia o anfitrião. O watchdog ajuda a evitar uma condição de split brain em que o nó do PostgreSQL continua a funcionar como o principal, mas a chave principal no DCS expirou devido a uma falha do agente, e foi eleito um principal (líder) diferente.
Processo de comutação por falha
Se o bloqueio do líder expirar no DCS, os nós de réplica candidatos iniciam uma eleição de líder. Quando uma réplica deteta um bloqueio de líder em falta, verifica a respetiva posição de replicação em comparação com as outras réplicas. Cada réplica usa a API REST para obter as posições do registo WAL dos outros nós de réplica, conforme mostrado no diagrama seguinte.
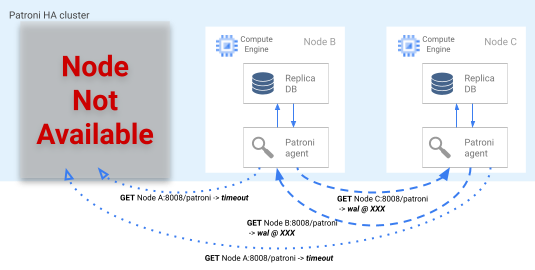
Figura 4. Diagrama do processo de comutação por falha do Patroni.
A Figura 4 mostra as consultas de posição do registo WAL e os respetivos resultados dos nós de réplica ativos. O nó A não está disponível e os nós B e C em bom estado devolvem a mesma posição WAL uns aos outros.
O nó mais atualizado (ou os nós, se estiverem na mesma posição) tenta adquirir simultaneamente o bloqueio de líder no DCS. No entanto, apenas um nó pode criar a chave principal no DCS. O primeiro nó a criar com êxito a chave principal é o vencedor da corrida de líderes, conforme mostrado no diagrama seguinte. Em alternativa, pode designar candidatos de alternativa preferenciais
definindo a etiqueta
failover_priority
nos ficheiros de configuração.
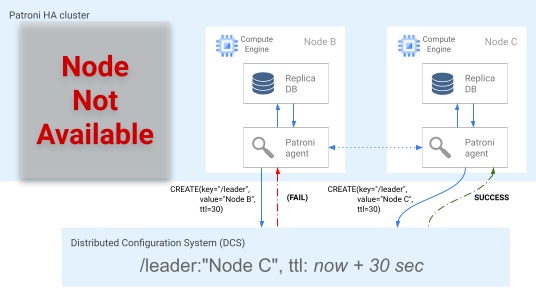
Figura 5. Diagrama da corrida de líderes.
A Figura 5 mostra uma corrida de líder: dois candidatos a líder tentam obter o bloqueio de líder, mas apenas um dos dois nós, o nó C, define com êxito a chave de líder e ganha a corrida.
Após ganhar a eleição de líder, a réplica promove-se a si própria para ser a nova primária. A partir do momento em que a réplica se promove a si própria, o novo nó principal atualiza a chave principal no DCS para manter o bloqueio principal, e os outros nós funcionam como réplicas.
O Patroni também fornece a patronictlferramenta de controlo que lhe permite executar comutações para testar o processo de comutação por falha nodal.
Esta ferramenta ajuda os operadores a testarem as respetivas configurações de HA em produção.
Encaminhamento de consultas
O processo do agente Patroni executado em cada nó expõe pontos finais da API REST que revelam a função do nó atual: principal ou réplica.
| Ponto final REST | Código de retorno HTTP se for principal | Código de retorno HTTP se for uma réplica |
|---|---|---|
/primary |
200 |
503 |
/replica |
503 |
200 |
Uma vez que as verificações de saúde relevantes alteram as respetivas respostas se um nó específico alterar a respetiva função, uma verificação de saúde do equilibrador de carga pode usar estes pontos finais para informar o encaminhamento de tráfego do nó principal e de réplica. O projeto Patroni fornece configurações de modelos para um balanceador de carga, como o HAProxy. O balanceador de carga de encaminhamento interno pode usar estas mesmas verificações de funcionamento para oferecer capacidades semelhantes.
Processo alternativo
Se houver uma falha no nó, o cluster fica num estado degradado. O processo de alternativa do Patroni ajuda a restaurar um cluster de HA para um estado saudável após uma comutação por falha. O processo de alternativa gere o regresso do cluster ao seu estado original inicializando automaticamente o nó afetado como uma réplica do cluster.
Por exemplo, um nó pode ser reiniciado devido a uma falha no sistema operativo ou na infraestrutura subjacente. Se o nó for o principal e demorar mais tempo do que o TTL da chave principal a reiniciar, é acionada uma eleição de líder, e é selecionado e promovido um novo nó principal. Quando o processo primário do Patroni obsoleto é iniciado, este deteta que não tem o bloqueio do líder, rebaixa-se automaticamente para uma réplica e junta-se ao cluster nessa capacidade.
Se ocorrer uma falha de nó irrecuperável, como uma falha zonal improvável, tem de iniciar um novo nó. Um operador de base de dados pode iniciar manualmente um novo nó ou pode usar um grupo de instâncias gerido (MIG) regional com estado com uma contagem mínima de nós para automatizar o processo. Depois de o novo nó ser criado, o Patroni deteta que o novo nó faz parte de um cluster existente e inicializa automaticamente o nó como uma réplica.
HA com a extensão e o serviço pg_auto_failover
pg_auto_failover é uma extensão do PostgreSQL de código aberto (licença do PostgreSQL) em desenvolvimento ativo. O pg_auto_failover configura uma arquitetura de HA ao expandir as capacidades existentes do PostgreSQL. O pg_auto_failover não tem dependências além do PostgreSQL.
Para usar a extensão pg_auto_failover com uma arquitetura de HA, precisa de, pelo menos, três nós, cada um a executar o PostgreSQL com a extensão ativada. Qualquer um dos nós pode falhar sem afetar o tempo de atividade do grupo de bases de dados. Uma coleção de nós geridos pelo pg_auto_failover é denominada formação. O diagrama seguinte mostra uma arquitetura pg_auto_failover.
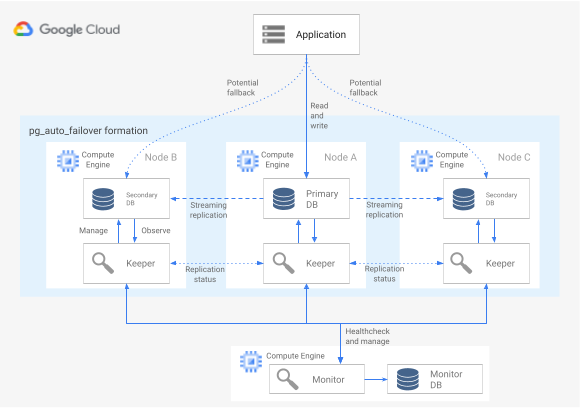
Figura 6. Diagrama de uma arquitetura pg_auto_failover.
A Figura 6 mostra uma arquitetura pg_auto_failover que consiste em dois componentes principais: o serviço de monitorização e o agente Keeper. O Keeper e o Monitor estão contidos na extensão pg_auto_failover.
Serviço de monitorização
O serviço de monitorização pg_auto_failover é implementado como uma extensão do PostgreSQL; quando o serviço cria um nó de monitorização, inicia uma instância do PostgreSQL com a extensão pg_auto_failover ativada. O Monitor mantém o estado global para a formação, obtém o estado de verificação de integridade dos nós de dados PostgreSQL membros e orquestra o grupo através das regras estabelecidas por uma máquina de estados finitos (MEF). De acordo com as regras da FSM para transições de estado, o Monitor comunica instruções aos nós do grupo para ações como promover, rebaixar e alterações de configuração.
Agente do Keeper
Em cada nó de dados do pg_auto_failover, a extensão inicia um processo de agente do Keeper. Este processo do Keeper observa e gere o serviço PostgreSQL. O Keeper envia atualizações de estado para o nó Monitor e recebe e executa ações que o Monitor envia em resposta.
Por predefinição, o pg_auto_failover configura todos os nós de dados secundários do grupo como réplicas síncronas. O número de réplicas síncronas necessárias para uma confirmação baseia-se na configuração number_sync_standby que define no monitor.
Deteção de falhas
Os agentes do Keeper nos nós de dados primários e secundários ligam-se periodicamente ao nó do monitor para comunicar o respetivo estado atual e verificar se existem ações a executar. O nó Monitor também se liga aos nós de dados para fazer uma verificação do estado de funcionamento executando as chamadas da API do protocolo PostgreSQL (libpq), imitando a aplicação cliente do PostgreSQL pg_isready(). Se nenhuma destas ações for bem-sucedida após um período de tempo (30 segundos por predefinição), o nó Monitor determina que ocorreu uma falha do nó de dados. Pode alterar as definições de configuração do PostgreSQL para personalizar a sincronização do monitor e o número de novas tentativas. Para mais informações, consulte o artigo Failover e tolerância a falhas.
Se ocorrer uma falha de nó único, uma das seguintes afirmações é verdadeira:
- Se o nó de dados não saudável for um nó principal, o Monitor inicia uma comutação por falha.
- Se o nó de dados não saudável for secundário, o Monitor desativa a replicação síncrona para o nó não saudável.
- Se o nó com falhas for o nó Monitor, a comutação por falha automática não é possível. Para evitar este único ponto de falha, tem de garantir que a monitorização e a recuperação de desastres corretas estão em vigor.
O diagrama seguinte mostra os cenários de falha e os estados de resultado da formação descritos na lista anterior.
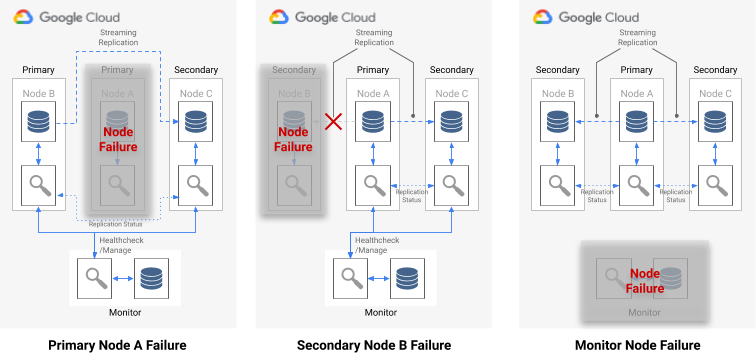
Figura 7. Diagrama dos cenários de falha do pg_auto_failover.
Processo de comutação por falha
Cada nó da base de dados no grupo tem as seguintes opções de configuração que determinam o processo de comutação por falha:
replication_quorum: uma opção booleana. Sereplication_quorumestiver definido comotrue, o nó é considerado um potencial candidato a comutação por falhacandidate_priority: um valor inteiro de 0 a 100.candidate_prioritytem um valor predefinido de 50 que pode alterar para afetar a prioridade de alternativa. Os nós são priorizados como potenciais candidatos a comutação por falha com base no valorcandidate_priority. Os nós que têm um valor decandidate_prioritymais elevado têm uma prioridade mais elevada. O processo de comutação por falha requer que, pelo menos, dois nós tenham uma prioridade de candidato diferente de zero em qualquer formação do pg_auto_failover.
Se ocorrer uma falha no nó principal, os nós secundários são considerados para promoção a principal se tiverem replicação síncrona ativa e se forem membros do replication_quorum.
Os nós secundários são considerados para promoção de acordo com os seguintes critérios progressivos:
- Nós com a prioridade de candidato mais elevada
- Em espera com a posição do registo WAL mais avançada publicada no monitor
- Seleção aleatória como desempate final
Um candidato de alternativa é um candidato em atraso quando não publicou a posição LSN mais avançada no WAL. Neste cenário, o pg_auto_failover orquestra um passo intermédio no mecanismo de comutação por falha: o candidato atrasado obtém os bytes WAL em falta de um nó de reserva que tem a posição LSN mais avançada. Em seguida, o nó de espera é promovido. O Postgres permite esta operação porque a replicação em cascata permite que qualquer standby atue como o nó a montante para outro standby.
Encaminhamento de consultas
O pg_auto_failure não oferece capacidades de encaminhamento de consultas do lado do servidor.
Em alternativa, o pg_auto_failover baseia-se no encaminhamento de consultas do lado do cliente que usa o
controlador do cliente oficial do PostgreSQL
libpq.
Quando define o URI de ligação, o controlador pode aceitar vários anfitriões na respetiva palavra-chave host.
A biblioteca de cliente que a sua aplicação usa tem de envolver o libpq ou implementar a capacidade de fornecer vários anfitriões para que a arquitetura suporte uma comutação por falha totalmente automática.
Processos de alternativa e comutação
Quando o processo do Keeper reinicia um nó com falhas ou inicia um novo nó de substituição, o processo verifica o nó do monitor para determinar a ação seguinte a realizar. Se um nó reiniciado que falhou era anteriormente o nó principal e o Monitor já tiver escolhido um novo nó principal de acordo com o processo de comutação por falha, o Keeper reinicializa este nó principal obsoleto como uma réplica secundária.
O pg_auto_failure fornece a ferramenta pg_autoctl, que lhe permite executar comutações
para testar o processo de comutação por falha do nó. Além de permitir que os operadores testem as respetivas configurações de HA em produção, a ferramenta ajuda a restaurar um cluster de HA para um estado de funcionamento após uma comutação por falha.
HA com MIGs com estado e disco persistente regional
Esta secção descreve uma abordagem de HA que usa os seguintes Google Cloud componentes:
- disco persistente regional. Quando usa discos persistentes regionais, os dados são replicados de forma síncrona entre duas zonas numa região, pelo que não precisa de usar a replicação de streaming. No entanto, a HA está limitada a exatamente duas zonas numa região.
- Grupos de instâncias geridas com estado. Um par de MIGs com estado é usado como parte de um plano de controlo para manter um nó do PostgreSQL primário em execução. Quando o MIG com estado inicia uma nova instância, pode anexar o disco persistente regional existente. Num determinado momento, apenas um dos MIGs tem uma instância em execução.
- Cloud Storage. Um objeto num contentor do Cloud Storage contém uma configuração que indica qual dos dois MIGs está a executar o nó da base de dados principal e em que MIG deve ser criada uma instância de comutação por falha.
- Verificações de funcionamento e autorreparação de GIGs. A verificação de funcionamento monitoriza o estado de funcionamento da instância. Se o nó em execução ficar em mau estado, a verificação de funcionamento inicia o processo de autocura.
- Registo. Quando a autocorreção para o nó principal, é registada uma entrada no registo. As entradas do registo pertinentes são exportadas para um tópico de sink do Pub/Sub através de um filtro.
- Funções do Cloud Run orientadas por eventos. A mensagem do Pub/Sub aciona as funções do Cloud Run. As funções do Cloud Run usam a configuração no Cloud Storage para determinar que ações realizar para cada MIG com estado.
- Balanceador de carga de rede de encaminhamento interno. O balanceador de carga fornece o encaminhamento para a instância em execução no grupo. Isto garante que uma alteração do endereço IP da instância causada pela recriação da instância é abstraída do cliente.
O diagrama seguinte mostra um exemplo de HA com MIGs com estado e discos persistentes regionais:

Figura 8. Diagrama de uma HA que usa MIGs com estado e discos persistentes regionais.
A Figura 8 mostra um nó principal em bom estado a publicar tráfego de clientes. Os clientes estabelecem ligação ao endereço IP estático do Network Load Balancer de encaminhamento interno. O balanceador de carga encaminha os pedidos do cliente para a VM que está a ser executada como parte do GIG. Os volumes de dados são armazenados em discos persistentes regionais montados.
Para implementar esta abordagem, crie uma imagem de VM com o PostgreSQL que seja iniciada na inicialização para ser usada como o modelo de instância do MIG. Também tem de configurar uma verificação de funcionamento baseada em HTTP (como o HAProxy ou o pgDoctor) no nó. Uma verificação de estado baseada em HTTP ajuda a garantir que o equilibrador de carga e o grupo de instâncias podem determinar o estado do nó do PostgreSQL.
Disco persistente regional
Para aprovisionar um dispositivo de armazenamento de blocos que forneça replicação de dados síncrona entre duas zonas numa região, pode usar a opção de armazenamento de disco persistente regional do Compute Engine. Um disco persistente regional pode fornecer um bloco de construção fundamental para implementar uma opção de HA do PostgreSQL que não dependa da replicação de streaming incorporada do PostgreSQL.
Se a instância de VM do nó principal ficar indisponível devido a uma falha de infraestrutura ou a uma interrupção zonal, pode forçar a ligação do disco persistente regional a uma instância de VM na sua zona de cópia de segurança na mesma região.
Para anexar o disco persistente regional a uma instância de VM na sua zona de cópia de segurança, pode fazer uma das seguintes ações:
- Mantenha uma instância de VM em espera fria na zona de cópia de segurança. Uma instância de VM em espera a frio é uma instância de VM parada que não tem um disco persistente regional montado, mas é uma instância de VM idêntica à instância de VM do nó principal. Se ocorrer uma falha, a VM em modo de espera a frio é iniciada e o disco persistente regional é montado nela. A instância de espera a frio e a instância do nó principal têm os mesmos dados.
- Crie um par de MIGs com estado através do mesmo modelo de instância. Os MIGs fornecem verificações de funcionamento e funcionam como parte do plano de controlo. Se o nó principal falhar, é criada uma instância de comutação por falha no MIG de destino de forma declarativa. O MIG de destino está definido no objeto do Cloud Storage. É usada uma configuração por instância para anexar o disco persistente regional.
Se a indisponibilidade do serviço de dados for identificada rapidamente, a operação de associação forçada é normalmente concluída em menos de um minuto, pelo que é possível alcançar um RTO medido em minutos.
Se a sua empresa puder tolerar o tempo de inatividade adicional necessário para detetar e comunicar uma indisponibilidade, e para realizar a comutação por falha manualmente, não precisa de automatizar o processo de associação forçada. Se a sua tolerância de RTO for inferior, pode automatizar o processo de deteção e comutação por falha. Em alternativa, o Cloud SQL para PostgreSQL também oferece uma implementação totalmente gerida desta abordagem de HA.
Deteção de falhas e processo de comutação por falha
A abordagem de HA usa as capacidades de recuperação automática dos grupos de instâncias para monitorizar o estado de funcionamento dos nós através de uma verificação de funcionamento. Se houver uma verificação de funcionamento com falha, a instância existente é considerada não saudável e é interrompida. Esta paragem inicia o processo de comutação por falha através do Logging, do Pub/Sub e da função de funções do Cloud Run acionada.
Para cumprir o requisito de que esta VM tem sempre o disco regional montado, uma das duas MIGs é configurada pelas funções do Cloud Run para criar uma instância numa das duas zonas onde o disco persistente regional está disponível. Em caso de falha de um nó, a instância de substituição é iniciada, de acordo com o estado persistente no Cloud Storage, na zona alternativa.

Figura 9. Diagrama de uma falha zonal num MIG.
Na figura 9, o antigo nó principal na zona A sofreu uma falha e as funções do Cloud Run configuraram o MIG B para iniciar uma nova instância principal na zona B. O mecanismo de deteção de falhas é configurado automaticamente para monitorizar o estado do novo nó principal.
Encaminhamento de consultas
O balanceador de carga de rede de passagem interno encaminha os clientes para a instância que está a executar o serviço PostgreSQL. O balanceador de carga usa a mesma verificação de funcionamento que o grupo de instâncias para determinar se a instância está disponível para publicar consultas. Se o nó estiver indisponível porque está a ser recriado, as ligações falham. Depois de a instância voltar a estar operacional, as verificações de funcionamento começam a ser aprovadas e as novas ligações são encaminhadas para o nó disponível. Não existem nós só de leitura nesta configuração porque existe apenas um nó em execução.
Processo alternativo
Se o nó da base de dados estiver a falhar numa verificação de estado devido a um problema de hardware subjacente, o nó é recriado numa instância subjacente diferente. Nesse momento, a arquitetura é devolvida ao estado original sem passos adicionais. No entanto, se ocorrer uma falha zonal, a configuração continua a ser executada num estado degradado até a primeira zona ser recuperada. Embora seja altamente improvável, se existirem falhas simultâneas nas duas zonas configuradas para a replicação de discos persistentes regional e o MIG com estado, não é possível recuperar a instância do PostgreSQL. A base de dados fica indisponível para processar pedidos durante a interrupção.
Comparação entre as opções de HA
As tabelas seguintes oferecem uma comparação das opções de HA disponíveis a partir do Patroni, do pg_auto_failover e dos MIGs com estado com discos persistentes regionais.
Configuração e arquitetura
| Patroni | pg_auto_failover | MIGs com estado com discos persistentes regionais |
|---|---|---|
|
Requer uma arquitetura de HA, configuração de DCS e monitorização e alertas. A configuração do agente nos nós de dados é relativamente simples. |
Não requer dependências externas além do PostgreSQL. Requer um nó dedicado como monitor. O nó de monitorização requer HA e DR para garantir que não é um único ponto de falha (SPOF). | Arquitetura que consiste exclusivamente em Google Cloud serviços. Só executa um nó de base de dados ativo de cada vez. |
Configurabilidade de alta disponibilidade
| Patroni | pg_auto_failover | MIGs com estado com discos persistentes regionais |
|---|---|---|
| Extremamente configurável: suporta a replicação síncrona e assíncrona, e permite-lhe especificar que nós devem ser síncronos e assíncronos. Inclui a gestão automática dos nós síncronos. Permite várias configurações de HA de zonas e multirregionais. O DCS tem de ser acessível. | Semelhante ao Patroni: muito configurável. No entanto, uma vez que o monitor só está disponível como uma única instância, qualquer tipo de configuração tem de considerar o acesso a este nó. | Limitado a duas zonas numa única região com replicação síncrona. |
Capacidade de processar a partição de rede
| Patroni | pg_auto_failover | MIGs com estado com discos persistentes regionais |
|---|---|---|
| A auto-restrição, juntamente com um monitor ao nível do SO, oferece proteção contra cérebro dividido. Qualquer falha na ligação ao DCS faz com que o principal se rebaixe a uma réplica e acione uma ativação pós-falha para garantir a durabilidade em vez da disponibilidade. | Usa uma combinação de verificações de estado do principal para o monitor e para a réplica para detetar uma partição de rede e rebaixa-se, se necessário. | Não aplicável: só existe um nó PostgreSQL ativo de cada vez, pelo que não existe uma partição de rede. |
Custo
| Patroni | pg_auto_failover | MIGs com estado com discos persistentes regionais |
|---|---|---|
| Custo elevado, uma vez que depende do DCS que escolher e do número de réplicas do PostgreSQL. A arquitetura Patroni não adiciona custos significativos. No entanto, a despesa geral é afetada pela infraestrutura subjacente, que usa várias instâncias de computação para o PostgreSQL e o DCS. Uma vez que usa várias réplicas e um cluster DCS separado, esta opção pode ser a mais cara. | Custo médio, porque envolve a execução de um nó de monitorização e, pelo menos, três nós do PostgreSQL (um principal e duas réplicas). | Baixo custo porque apenas um nó do PostgreSQL está em execução ativa em qualquer momento. Só paga por uma única instância de computação. |
Configuração do cliente
| Patroni | pg_auto_failover | MIGs com estado com discos persistentes regionais |
|---|---|---|
| Transparente para o cliente porque se liga a um equilibrador de carga. | Requer que a biblioteca de cliente suporte várias definições de anfitrião na configuração, uma vez que não é facilmente apresentado com um equilibrador de carga. | Transparente para o cliente porque se liga a um equilibrador de carga. |
Escalabilidade
| Patroni | pg_auto_failover | MIGs com estado com discos persistentes regionais |
|---|---|---|
| Grande flexibilidade na configuração de compromissos de escalabilidade e disponibilidade. A expansão da leitura é possível adicionando mais réplicas. | Semelhante ao Patroni: a escalabilidade de leitura é possível adicionando mais réplicas. | Escalabilidade limitada devido à existência de apenas um nó PostgreSQL ativo de cada vez. |
Automatização da inicialização do nó do PostgreSQL, gestão da configuração
| Patroni | pg_auto_failover | MIGs com estado com discos persistentes regionais |
|---|---|---|
Fornece ferramentas para gerir a configuração do PostgreSQL (patronictl
edit-config) e inicializa automaticamente novos nós ou nós reiniciados no cluster. Pode inicializar nós com o comando
pg_basebackup ou outras ferramentas, como o barman.
|
Inicializa automaticamente os nós, mas está limitado à utilização de
pg_basebackup quando inicializa um novo nó de réplica.
A gestão de configuração está limitada a configurações relacionadas com o pg_auto_failover.
|
O grupo de instâncias com estado com disco partilhado elimina a necessidade de qualquer inicialização do nó do PostgreSQL. Uma vez que só existe um nó em execução, a gestão da configuração está num único nó. |
Personalização e variedade de funcionalidades
| Patroni | pg_auto_failover | MIGs com estado com discos persistentes regionais |
|---|---|---|
|
Fornece uma interface de gancho para permitir que as ações definíveis pelo utilizador sejam chamadas em passos importantes, como na despromoção ou na promoção. Configurabilidade rica em funcionalidades, como suporte para diferentes tipos de DCS, diferentes meios de inicializar réplicas e diferentes formas de fornecer configuração do PostgreSQL. Permite-lhe configurar clusters de espera que permitem que os clusters de réplicas em cascata facilitem a migração entre clusters. |
Limitado porque é um projeto relativamente novo. | Não aplicável. |
Maturidade
| Patroni | pg_auto_failover | MIGs com estado com discos persistentes regionais |
|---|---|---|
| O projeto está disponível desde 2015 e é usado na produção por grandes empresas, como a Zalando e a GitLab. | Projeto relativamente novo anunciado no início de 2019. | Composto inteiramente por Google Cloud produtos geralmente disponíveis. |
Práticas recomendadas para manutenção e monitorização
A manutenção e a monitorização do cluster de HA do PostgreSQL são cruciais para garantir a alta disponibilidade, a integridade dos dados e o desempenho ideal. As secções seguintes fornecem algumas práticas recomendadas para monitorizar e manter um cluster de HA do PostgreSQL.
Faça testes de recuperação e cópias de segurança regulares
Faça regularmente cópias de segurança das suas bases de dados PostgreSQL e teste o processo de recuperação. Isto ajuda a garantir a integridade dos dados e minimiza o tempo de inatividade em caso de uma interrupção. Teste o processo de recuperação para validar as cópias de segurança e identificar potenciais problemas antes de ocorrer uma indisponibilidade.
Monitorize servidores PostgreSQL e o atraso de replicação
Monitorize os seus servidores PostgreSQL para verificar se estão em execução. Monitorize o atraso de replicação entre os nós principal e de réplica. O atraso excessivo pode levar a inconsistências nos dados e a um aumento da perda de dados em caso de uma comutação por falha. Configure
alertas para aumentos significativos do atraso e investigue a causa principal imediatamente.
A utilização de vistas como pg_stat_replication e pg_replication_slots pode ajudar a monitorizar o intervalo de tempo da replicação.
Implemente o agrupamento de ligações
A partilha de ligações pode ajudar a gerir as ligações à base de dados de forma eficiente. A partilha de ligações ajuda a reduzir a sobrecarga do estabelecimento de novas ligações, o que melhora o desempenho da aplicação e a estabilidade do servidor de base de dados. As ferramentas como o PGBouncer e o Pgpool-II podem fornecer o agrupamento de ligações para o PostgreSQL.
Implemente uma monitorização abrangente
Para obter estatísticas sobre os seus clusters de HA do PostgreSQL, estabeleça sistemas de monitorização robustos da seguinte forma:
- Monitorize as principais métricas do PostgreSQL e do sistema, como a utilização da CPU, a utilização da memória, a E/S do disco, a atividade de rede e as ligações ativas.
- Recolha registos do PostgreSQL, incluindo registos do servidor, registos WAL e registos de limpeza automática, para análise detalhada e resolução de problemas.
- Use ferramentas de monitorização e painéis de controlo para visualizar métricas e registos para uma identificação rápida de problemas.
- Integre métricas e registos com sistemas de alerta para receber notificações proativas de potenciais problemas.
Para mais informações sobre a monitorização de uma instância do Compute Engine, consulte a vista geral do Cloud Monitoring.
O que se segue?
- Leia sobre a configuração de alta disponibilidade do Cloud SQL.
- Saiba mais sobre as opções de elevada disponibilidade que usam o disco persistente regional.
- Leia sobre a Patroni.
- Leia sobre o pg_auto_failover.
- Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.
Colaboradores
Autor: Alex Cârciu | Solutions Architect