Está a ver a documentação do Apigee e do Apigee Hybrid.
Veja a documentação do
Apigee Edge.
A política RaiseFault permite que os programadores de APIs iniciem um fluxo de erros, definam variáveis de erro
numa mensagem do corpo da resposta e definam códigos de estado de resposta adequados. Também pode usar a política RaiseFault
para definir variáveis de fluxo relativas à falha, como fault.name, fault.type
e fault.category. Uma vez que estas variáveis são visíveis nos dados de estatísticas e nos registos de acesso do router usados para depuração, é importante identificar a falha com precisão.
Pode usar a política RaiseFault para tratar condições específicas como erros, mesmo que não tenha ocorrido um erro real noutra política ou no servidor de back-end do proxy de API. Por exemplo, se quiser que o proxy envie uma mensagem de erro personalizada para a app cliente sempre que o corpo da resposta de back-end contiver a string unavailable, pode invocar a política RaiseFault, conforme mostrado no fragmento de código abaixo:
<!-- /antipatterns/examples/raise-fault-conditions-1.xml --> <TargetEndpoint name="default"> ... <Response> <Step> <Name>RF-Service-Unavailable</Name> <Condition>(message.content Like "*unavailable*")</Condition> </Step> </Response> ...
O nome da política RaiseFault é visível como fault.name em
Monitorização de APIs e como x_apigee_fault_policy nos registos de acesso do Analytics e do Router.
Isto ajuda a diagnosticar facilmente a causa do erro.
Antipattern
Usar a política RaiseFault em FaultRules depois de outra política já ter gerado um erro
Considere o exemplo abaixo, em que uma política OAuthV2 no fluxo do proxy de API falhou com um erro InvalidAccessToken. Em caso de falha, o Apigee define fault.name como InvalidAccessToken, entra no fluxo de erros e executa quaisquer FaultRules definidas. Na FaultRule, existe uma política RaiseFault denominada
RaiseFault que envia uma resposta de erro personalizada sempre que ocorre um erro InvalidAccessToken. No entanto, a utilização da política RaiseFault numa FaultRule significa que a variável fault.name
é substituída e oculta a verdadeira causa da falha.
<!-- /antipatterns/examples/raise-fault-conditions-2.xml --> <FaultRules> <FaultRule name="generic_raisefault"> <Step> <Name>RaiseFault</Name> <Condition>(fault.name equals "invalid_access_token") or (fault.name equals "InvalidAccessToken")</Condition> </Step> </FaultRule> </FaultRules>
Usar a política RaiseFault numa FaultRule em todas as condições
No exemplo abaixo, é executada uma política RaiseFault denominada RaiseFault se o elemento fault.name
não for RaiseFault:
<!-- /antipatterns/examples/raise-fault-conditions-3.xml --> <FaultRules> <FaultRule name="fault_rule"> .... <Step> <Name>RaiseFault</Name> <Condition>!(fault.name equals "RaiseFault")</Condition> </Step> </FaultRule> </FaultRules>
Tal como no primeiro cenário, as variáveis de falha principais fault.name, fault.code,
e fault.policy são substituídas pelo nome da política RaiseFault. Este comportamento torna quase impossível determinar que política causou realmente a falha sem aceder a um ficheiro de rastreio que mostre a falha ou reproduzir o problema.
Usar a política RaiseFault para devolver uma resposta HTTP 2xx fora do fluxo de erros.
No exemplo abaixo, uma política RaiseFault denominada HandleOptionsRequest é executada quando
o verbo de pedido é OPTIONS:
<!-- /antipatterns/examples/raise-fault-conditions-4.xml --> <PreFlow name="PreFlow"> <Request> … <Step> <Name>HandleOptionsRequest</Name> <Condition>(request.verb Equals "OPTIONS")</Condition> </Step> … </PreFlow>
A intenção é devolver a resposta ao cliente da API imediatamente sem processar outras políticas. No entanto, isto vai gerar dados de estatísticas enganadores, porque as variáveis de falha vão conter o nome da política RaiseFault, o que dificulta a depuração do proxy. A forma correta de implementar o comportamento desejado é usar fluxos com condições especiais, conforme descrito em Adicionar suporte do CORS.
Impacto
A utilização da política RaiseFault, conforme descrito acima, resulta na substituição das variáveis de falha principais pelo nome da política RaiseFault, em vez do nome da política com falhas. Nos registos de acesso do Analytics e do NGINX,
as variáveis x_apigee_fault_code e x_apigee_fault_policy
são substituídas. Na API Monitoring, os campos Fault Code
e Fault Policy são substituídos. Este comportamento dificulta a resolução de problemas e a determinação da política que é a verdadeira causa da falha.
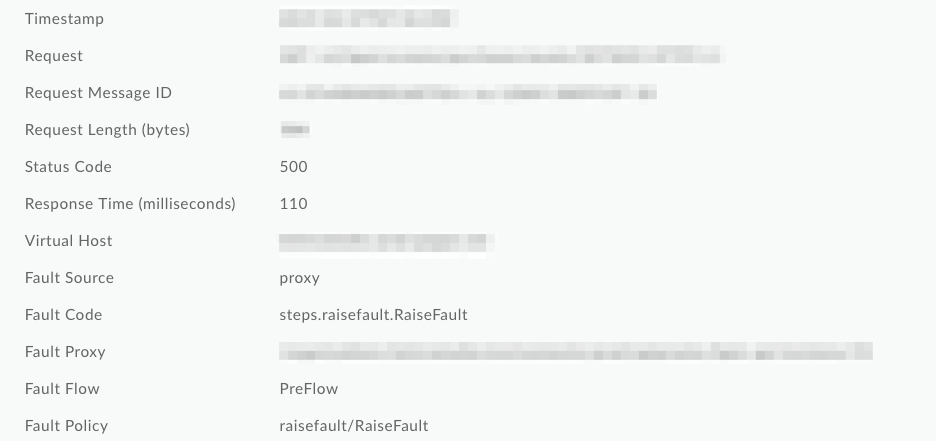
Na captura de ecrã abaixo da Monitorização de APIs,
pode ver que o código de falha e a política de falhas foram substituídos por valores RaiseFault
genéricos, o que torna impossível determinar a causa principal da falha a partir dos registos:
Prática recomendada
Quando uma política do Apigee gera uma falha e quer personalizar a mensagem de resposta de erro, use as políticas AssignMessage ou JavaScript em vez da política RaiseFault.
A política RaiseFault deve ser usada num fluxo sem erros. Ou seja, use RaiseFault apenas para tratar uma condição específica como um erro, mesmo que não tenha ocorrido um erro real numa política ou no servidor de back-end do proxy de API. Por exemplo, pode usar a política RaiseFault para sinalizar que faltam parâmetros de entrada obrigatórios ou que têm uma sintaxe incorreta.
Também pode usar o elemento RaiseFault numa regra de falha se quiser detetar um erro durante o processamento de uma falha. Por exemplo, o próprio controlador de falhas pode causar um erro que quer sinalizar através de RaiseFault.