Estás viendo la documentación de Apigee y Apigee Hybrid.
Consulta la documentación de Apigee Edge.
La política RaiseFault permite a los desarrolladores de API iniciar un flujo de errores, establecer variables de error en un mensaje de cuerpo de respuesta y configurar códigos de estado de respuesta adecuados. También puedes usar la política RaiseFault para configurar variables de flujo relacionadas con la falla, como fault.name, fault.type y fault.category. Debido a que estas variables son visibles en los datos de estadísticas y en los registros de acceso al router que se usan para la depuración, es importante identificar con precisión la falla.
Puedes usar la política RaiseFault para tratar condiciones específicas como errores, incluso si no se produjo un error real en otra política o en el servidor de backend del proxy de la API. Por ejemplo, si deseas que el proxy envíe un mensaje de error personalizado a la app cliente cada vez que el cuerpo de la respuesta del backend contenga la string unavailable, puedes invocar la política RaiseFault como se muestra en el siguiente fragmento de código:
<!-- /antipatterns/examples/raise-fault-conditions-1.xml --> <TargetEndpoint name="default"> ... <Response> <Step> <Name>RF-Service-Unavailable</Name> <Condition>(message.content Like "*unavailable*")</Condition> </Step> </Response> ...
El nombre de la política de aumento de errores se muestra como fault.name en Monitoring API y como x_apigee_fault_policy en los registros de acceso de Analytics y Router.
Esto ayuda a diagnosticar la causa del error con facilidad.
Antipatrón
Usa la política RaiseFault dentro de FaultRules después de que otra política haya arrojado un error
Considera el siguiente ejemplo, en el que una política de OAuthV2 en el flujo del proxy de API falló con un error InvalidAccessToken. Cuando ocurra una falla, Apigee establecerá fault.name como InvalidAccessToken, ingresará al flujo de error y ejecutará cualquier FaultRule definida. En la FaultRule, hay una política RaiseFault llamada RaiseFault que envía una respuesta de error personalizada cada vez que se produce un error InvalidAccessToken. Sin embargo, el uso de la política RaiseFault en una FaultRule significa que la variable fault.name se reemplaza y enmascara la verdadera causa de la falla.
<!-- /antipatterns/examples/raise-fault-conditions-2.xml --> <FaultRules> <FaultRule name="generic_raisefault"> <Step> <Name>RaiseFault</Name> <Condition>(fault.name equals "invalid_access_token") or (fault.name equals "InvalidAccessToken")</Condition> </Step> </FaultRule> </FaultRules>
Usa la política RaiseFault en una FaultRule en todas las condiciones
En el siguiente ejemplo, se ejecuta una política RaiseFault con el nombre RaiseFault si el fault.name no es RaiseFault:
<!-- /antipatterns/examples/raise-fault-conditions-3.xml --> <FaultRules> <FaultRule name="fault_rule"> .... <Step> <Name>RaiseFault</Name> <Condition>!(fault.name equals "RaiseFault")</Condition> </Step> </FaultRule> </FaultRules>
Al igual que en la primera situación, las variables de falla clave fault.name, fault.code y fault.policy se reemplazan por el nombre de la política de RaiseFault. Este comportamiento hace que sea casi imposible determinar qué política causó la falla sin acceder a un archivo de seguimiento que muestre el error o reproduzca el problema.
Usa la política RiseBit para mostrar una respuesta HTTP 2xx fuera del flujo de error.
En el siguiente ejemplo, una política RaiseFault llamada HandleOptionsRequest se ejecuta cuando el verbo de la solicitud es OPTIONS:
<!-- /antipatterns/examples/raise-fault-conditions-4.xml --> <PreFlow name="PreFlow"> <Request> … <Step> <Name>HandleOptionsRequest</Name> <Condition>(request.verb Equals "OPTIONS")</Condition> </Step> … </PreFlow>
La intención es mostrar la respuesta al cliente de la API de inmediato sin procesar otras políticas. Sin embargo, esto generará datos de estadísticas engañosos, ya que las variables de falla contendrán el nombre de la política RaiseFault, lo que hace que el proxy sea más difícil de depurar. La forma correcta de implementar el comportamiento deseado es usar flujos con condiciones especiales, como se describe en Agrega compatibilidad con CORS.
Impacto
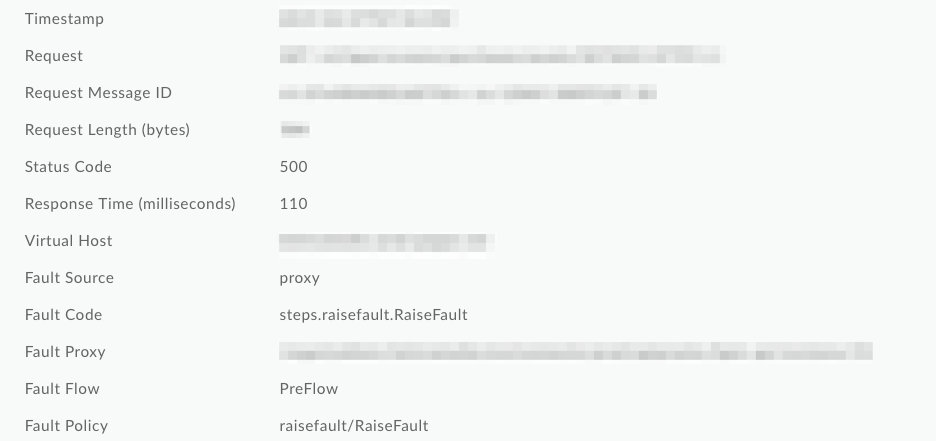
El uso de la política RaiseFault como se describió antes da como resultado que se reemplacen las variables de fallas clave con el nombre de la política RaiseFault, en lugar del nombre de la política de falla. En los registros de Analytics y NGINX Access, las variables x_apigee_fault_code y x_apigee_fault_policy se reemplazan. En la supervisión de la API, se reemplazan Fault Code y Fault Policy . Este comportamiento dificulta la solución de problemas y la determinación de la política que es la verdadera causa de la falla.
En la captura de pantalla que aparece a continuación de la Supervisión de API, puedes ver que la política de errores y código de fallas se sobrescribieron en valores genéricos de RaiseFault, lo que hace imposible determinar la causa raíz de un error en los registros:
Práctica recomendada
Cuando una política de Apigee genera una falla y deseas personalizar el mensaje de respuesta de error, usa las políticas de AssignMessage o JavaScript en lugar de la política RaiseFault .
Esta política RaiseFault debe usarse en un flujo sin errores. Es decir, solo usa RaiseFault para tratar una condición específica como un error, incluso si no se produce un error real en una política o en el servidor de backend del proxy de API. Por ejemplo, puedes usar la política de RaiseFault para indicar que faltan parámetros de entrada obligatorios o que tienen una sintaxis incorrecta.
También puedes usar RaiseFault en una regla de falla si deseas detectar un error durante el procesamiento de una falla. Por ejemplo, tu controlador de fallas podría causar un error que desees que indique con RaiseFault.