このドキュメントでは、VM 上の AlloyDB Omni のパフォーマンス結果を解釈する方法について説明します。このドキュメントは、PostgreSQL に精通していることを前提としています。
別の変数を変更しながらスループットの推移をグラフにすると、通常、スループットはリソースが枯渇するポイントに達するまで増加します。
次の図は、一般的なスループット スケーリング グラフを示しています。クライアントの数が増えると、すべてのリソースが使い果たされるまでワークロードとスループットが増加します。
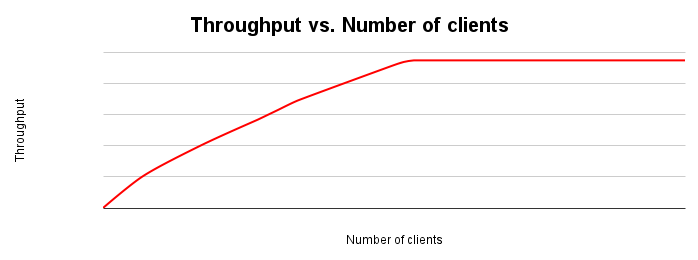
システムの負荷が 2 倍になると、スループットも 2 倍になるはずです。実際には、リソースの競合が発生し、スループットの増加が抑制されます。ある時点で、リソースの枯渇や競合により、スループットが横ばいになるか、さらに低下する可能性があります。スループットを重視して最適化する場合、このポイントを特定することが重要です。スループットを改善するためにアプリケーションまたはデータベース システムをチューニングする場所を特定できます。
スループットが安定または低下する一般的な理由は次のとおりです。
- データベース サーバーの CPU リソースの枯渇
- クライアントで CPU リソースが枯渇し、データベース サーバーに処理が送信されなくなった
- データベース ロックの競合
- データが Postgres バッファプールのサイズを超えた場合の I/O 待ち時間
- ストレージ エンジンの使用による I/O 待ち時間
- クライアントにデータを返す際のネットワーク帯域幅のボトルネック
レイテンシとスループットは反比例します。レイテンシが増加すると、スループットは低下します。これは直感的にわかるでしょう。ボトルネックが発生すると、オペレーションに時間がかかり、システムが 1 秒間に実行するオペレーション数が減ります。
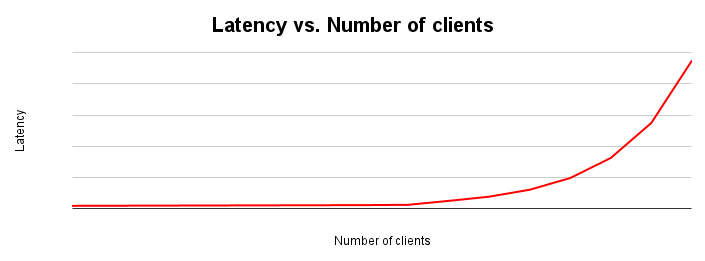
レイテンシ スケーリングのグラフは、システムに負荷がかかるとレイテンシがどのように変化するかを示しています。レイテンシは、リソース競合により摩擦が発生するまで比較的一定に保たれます。この曲線の屈曲点は、通常、スループット スケーリング グラフのスループット曲線の平坦化に対応しています。
レイテンシを評価するもう 1 つの便利な方法は、ヒストグラムを使用する方法です。この表現では、レイテンシをバケットにグループ化し、各バケットに含まれるリクエストの数をカウントします。
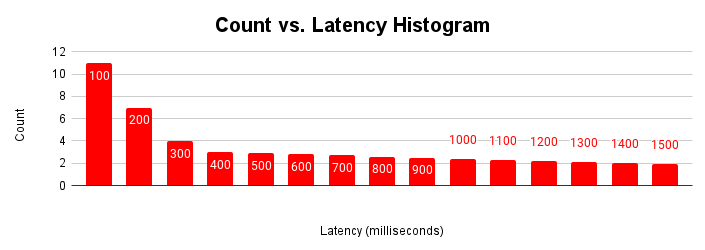
このレイテンシのヒストグラムは、ほとんどのリクエストが 100 ミリ秒未満で、100 ミリ秒を超えるレイテンシがあることを示しています。レイテンシの長いリクエストの原因を把握すると、アプリケーション パフォーマンスの変化を説明できます。レイテンシの増加の長い尾の原因は、一般的なレイテンシ スケーリング グラフに表示されるレイテンシの増加と、スループット グラフの平坦化に対応しています。
レイテンシ ヒストグラムが最も役立つのは、アプリケーションに複数のモダリティがある場合です。モダリティとは、通常の動作条件のセットです。たとえば、ほとんどの場合、アプリケーションはバッファ キャッシュ内のページにアクセスしています。ほとんどの場合、アプリケーションは既存の行を更新しますが、複数のモードがある場合があります。アプリケーションがストレージからページを取得している場合、新しい行を挿入している場合、ロック競合が発生している場合などです。
アプリケーションが時間の経過とともにこれらの異なる動作モードに遭遇すると、レイテンシ ヒストグラムにこれらの複数のモダリティが表示されます。
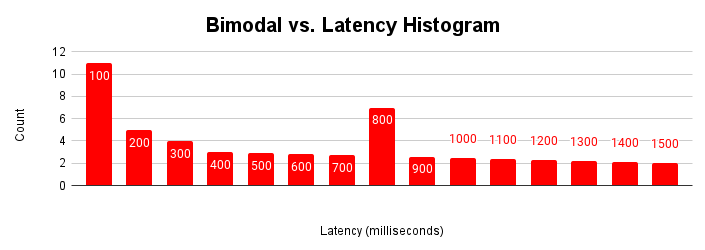
この図は、ほとんどのリクエストが 100 ミリ秒未満で処理されるが、401 ~ 500 ミリ秒かかるリクエストのクラスタもある、典型的なバイモダル ヒストグラムを示しています。この 2 番目のモダリティの原因を理解すると、アプリケーションのパフォーマンスを改善できます。モダリティは 2 つ以上でもかまいません。
2 つ目のモダリティは、通常のデータベース オペレーション、異種インフラストラクチャとトポロジ、またはアプリケーションの動作が原因である可能性があります。考慮すべき例を次に示します。
- ほとんどのデータアクセスは PostgreSQL バッファプールから行われますが、一部はストレージから行われます。
- 一部のクライアントとデータベース サーバー間のネットワーク レイテンシの違い
- 入力や時刻に応じて異なるオペレーションを実行するアプリケーション ロジック
- 散発的なロック競合
- クライアント アクティビティの急増