This document describes how to interpret the performance results in AlloyDB Omni on a VM. This document assumes that you're familiar with PostgreSQL.
When you graph throughput over time as another variable is modified, typically you see throughput increase until the throughput reaches a point of resource exhaustion.
The following figure shows a typical throughput scaling graph. As the number of clients increases, the workload and throughput increases until all the resources are exhausted.
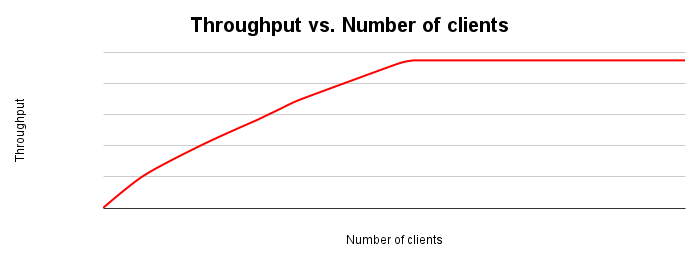
Ideally, as you double the load on the system, throughput should also double. In practice there will be contention on resources that leads to smaller throughput increases. At some point resource exhaustion or contention will cause throughput to flatten out or even decrease. If you are optimizing for throughput, this is a key point to identify as it drives your efforts into where to tune the application or database system to improve throughput.
Typical reasons for throughput to level off or drop include the following:
- CPU resource exhaustion on the database server
- CPU resource exhaustion on the client so the database server is not being sent more work
- Database lock contention
- I/O wait time when data exceeds the size of the Postgres buffer pool
- I/O wait time due to storage engine utilization
- Network bandwidth bottlenecks returning data to the client
Latency and throughput are inversely proportional. As latency increases, throughput decreases. Intuitively this makes sense. As a bottleneck begins to materialize, operations start to take longer and the system performs fewer operations per second.
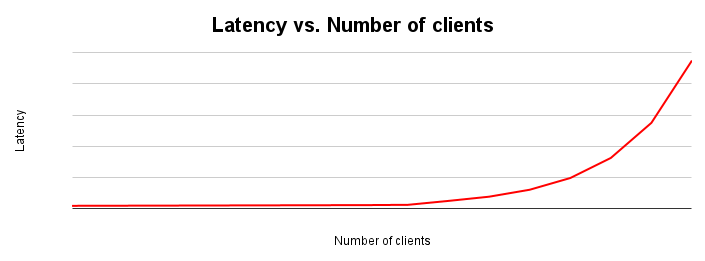
The latency scaling graph shows how latency changes as the load placed on a system increases. Latency stays relatively constant until friction occurs due to resource contention. The inflection point of this curve generally corresponds to the flattening of the throughput curve in the throughtput scaling graph.
Another useful way to evaluate latency is as a histogram. In this representation, we group latencies into buckets and count how many requests fall into each bucket.
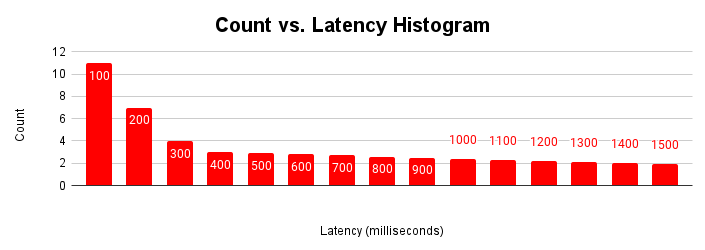
This latency histogram shows most requests are under 100 milliseconds, and latencies longer than 100 milliseconds. Understanding the cause of the requests with longer latencies tail can help explain the application performance variations seen. The causes of the long tail of increased latencies correspond to the increased latencies seen in the typical latency scaling graph and the flattening of the throughput graph.
Where the latency histogram is most useful is when there are multiple modalities in an application. A modality is a normal set of operating conditions. For example, most of the time the application is accessing pages that are in buffer cache. Most of the time, the application is updating existing rows, however, there might be multiple modes. Some of the time, the application is retrieving pages from storage, inserting new rows, or is experiencing lock contention.
When an application encounters these different modes of operation over time, the latency histogram shows these multiple modalities.
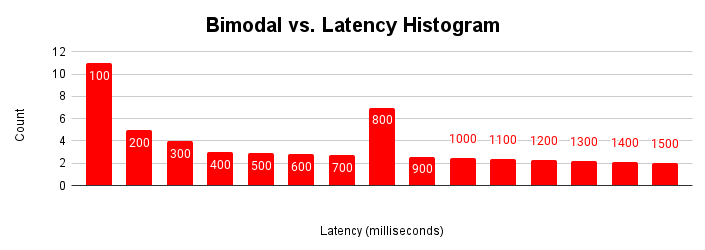
This figure shows a typical bimodal histogram where most of the requests are serviced in under 100 milliseconds, but there is another cluster of requests that take 401-500 milliseconds. Understanding the cause of this second modality can help improve the performance of your application. There can be more than two modalities as well.
The second modality might be due to normal database operations, heterogeneous infrastructure and topology or application behavior. Some examples to consider are the following:
- Most data accesses are from the PostgreSQL buffer pool, but some come from storage
- Differences in network latencies for some clients to the database server
- Application logic that performs different operations depending on input or time of day
- Sporadic lock contention
- Spikes in client activity