Ce document présente les systèmes SAP S/4HANA que vous pouvez déployer à l'aide de l'outil d'automatisation guidée du déploiement dans Workload Manager, ainsi que des considérations supplémentaires pour le déploiement. Pour en savoir plus, consultez l'architecture de référence de Google Cloudpour SAP S/4HANA.
Processus de déploiement de SAP S/4HANA
La liste suivante présente les différentes tâches effectuées par Workload Manager au cours du processus de déploiement:
- Active les API requises, si elles ne sont pas activées dans le projet.
- Configure et provisionne l'infrastructure requise pour le déploiement.
- Configure le système d'exploitation sur les VM.
- Installe SAP S/4HANA.
- Effectue une sauvegarde complète de la base de données SAP HANA dans un fichier.
- Configure le cluster d'OS Pacemaker pour la haute disponibilité SAP HANA, les équilibreurs de charge requis et les vérifications de l'état (HA uniquement)
- Active la réplication du système (HSR) SAP HANA pour la haute disponibilité.
- Configure le cluster d'OS Pacemaker pour la haute disponibilité de l'application SAP, les équilibreurs de charge requis et les vérifications de l'état.
- Installe l'application SAP sélectionnée.
- Démarre la base de données SAP HANA et l'application SAP installée.
- Installe les agents obligatoires suivants sur les VM :
- AgentGoogle Cloudpour SAP
- Agent hôte SAP
Le résultat d'un déploiement réussi est un système SAP S/4HANA vide ("greenfield"). Pour en savoir plus sur les étapes suivantes après un déploiement réussi, consultez la section Tâches post-déploiement pour SAP S/4HANA.
Déployer à l'aide de la console Google Cloud
Lorsque vous choisissez de déployer votre charge de travail à l'aide de la console Google Cloud , le Gestionnaire de charges de travail gère automatiquement le déploiement de bout en bout, y compris l'exécution des scripts Terraform et Ansible, ainsi que le provisionnement des ressources. Vous avez également accès à tous les fichiers sous-jacents utilisés pendant le processus de déploiement.
Workload Manager utilise Infrastructure Manager pour automatiser le processus de déploiement. Infrastructure Manager utilise Cloud Build pour initialiser Terraform et exécuter d'autres commandes Terraform. Cloud Build stocke ensuite les fichiers Terraform et le fichier d'état Terraform dans un bucket Cloud Storage.
Pour en savoir plus sur Infrastructure Manager, consultez la page Présentation d'Infrastructure Manager.
En plus des ressources Compute Engine requises pour votre charge de travail SAP, Terraform déploie une VM Ansible Runner qui a accès à d'autres ressources lors du déploiement. La VM Runner exécute automatiquement les scripts Ansible qui effectuent une configuration supplémentaire de l'infrastructure déployée, y compris la configuration de l'OS, la configuration du cluster HA et l'orchestration du processus d'installation de l'application SAP.
Architecture d'ensemble du déploiement de SAP S/4HANA
Cette section présente le système déployé lorsque vous déployez SAP S/4HANA à l'aide de l'outil Automatisation guidée du déploiement dans le gestionnaire de charges de travail. Notez que l'architecture exacte peut varier en fonction de la configuration et des paramètres que vous avez spécifiés, et que toutes les ressources déployées ne sont pas incluses dans les figures.
En plus de ces ressources, une VM Ansible Runner temporaire est également déployée dans la zone principale, qui a accès aux autres ressources du déploiement. La VM Ansible Runner exécute automatiquement les scripts Ansible qui effectuent une configuration supplémentaire de l'infrastructure déployée, y compris la configuration de l'OS, la configuration du cluster HA et l'orchestration du processus d'installation de l'application SAP.
Distribué avec haute disponibilité
La figure suivante montre un déploiement distribué à haute disponibilité, où les clusters Linux sont configurés sur plusieurs zones pour éviter les défaillances de composants dans une région donnée.
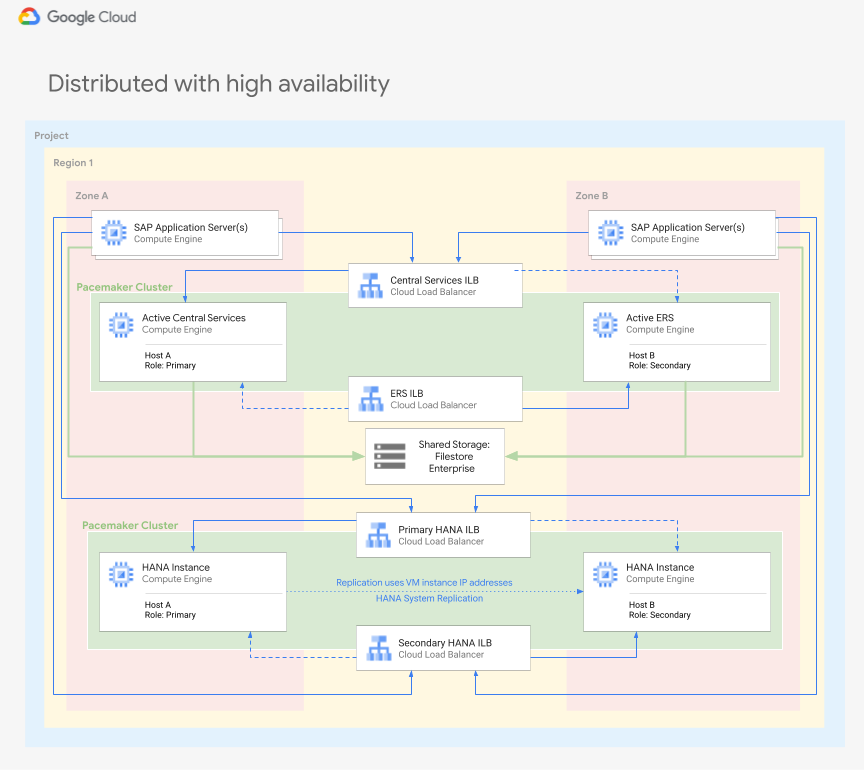
Architecture distribuée
La figure suivante montre l'architecture de SAP S/4HANA dans un déploiement distribué.
Mise en page des disques SAP HANA
Le schéma suivant illustre la mise en page de disque de la base de données SAP HANA, qui s'applique aux configurations distribuées et distribuées avec haute disponibilité.

Les disques décrits dans la mise en page de disque précédente sont montés directement dans le système d'exploitation dans le cadre des systèmes de fichiers SAP HANA requis. Ces disques ne sont pas utilisés dans les volumes logiques créés via LVM. Par exemple, la sortie ressemble à celle-ci lorsque vous exécutez la commande df -h:
example-vm:~ # df -h | grep /dev/sd
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 50G 4.3G 46G 9% /
/dev/sda2 20M 3.0M 17M 15% /boot/efi
/dev/sda 32G 293M 32G 1% /usr/sap
/dev/sdc 308G 164G 145G 54% /hana/data
/dev/sdd 128G 11G 118G 9% /hana/log
/dev/sde 256G 12G 245G 5% /hana/shared
/dev/sdf 256G 96G 161G 38% /hanabackupRessources créées lors du déploiement
Workload Manager utilise les API et services Google Cloud suivants pour le déploiement de SAP S/4HANA.
Compute Engine
Instances de VM
Les déploiements SAP S/4HANA incluent des ressources Compute Engine pour les composants suivants. Lorsque vous configurez des VM pour ces composants, vous ne pouvez sélectionner que les types de machines certifiés par SAP pour répondre aux exigences de dimensionnement du déploiement de S/4HANA.
- Bases de données SAP HANA
- ASCS : Services centraux SAP ABAP
- Contient le serveur de messagerie et le serveur de file d'attente, requis dans tout système SAP ABAP.
- Ils sont déployés sur leur propre instance de VM dans des déploiements à haute disponibilité ou déployés sur l'instance de VM hébergeant le PAS.
- Dans les déploiements à haute disponibilité, les ressources ASCS sont gérées par un gestionnaire de ressources de cluster Linux tel que Pacemaker.
- ERS : serveur de réplication de mise en file d'attente ou réplicateur de mise en file d'attente
- Déployé dans des déploiements à haute disponibilité pour conserver une instance dupliquée de la table de verrouillage en cas d'événement au niveau de l'instance ASCS.
- Géré par un gestionnaire de ressources de cluster Linux, tel que Pacemaker.
- PAS : serveur d'applications principal.
- Le premier ou le seul serveur d'applications pour le système SAP.
- AAS : serveur d'applications supplémentaire.
- Généralement déployé pour l'équilibrage de charge au niveau de l'application. Vous pouvez installer plusieurs systèmes AAS pour obtenir une disponibilité plus élevée du point de vue de la couche d'application. Si l'un des serveurs d'applications tombe en panne, toutes les sessions utilisateur connectées à ce serveur d'applications sont arrêtées, mais les utilisateurs peuvent se reconnecter à l'autre AAS de l'environnement.
- Dans les configurations de haute disponibilité, les serveurs d'applications sont répartis de manière égale entre les zones principale et secondaire.
Options de stockage
Persistent Disk ou Hyperdisk sont utilisés pour fournir une capacité de stockage aux instances de VM de votre déploiement SAP S/4HANA.
Les tailles de disque de chaque volume sont calculées automatiquement conformément aux bonnes pratiques de SAP S/4HANA pour la machine et les types de stockage en bloc sélectionnés.
Le tableau suivant présente les disques créés dans un déploiement SAP S/4HANA.
| Instance de VM pour: | Disque | Types acceptés* |
|---|---|---|
| Bases de données HANA | boot | Disque persistant SSD |
| Bases de données HANA | /hana/data |
Disque persistant équilibré Disques persistants SSD Hyperdisk Extreme |
| Bases de données HANA | /hana/log |
Disque persistant équilibré Disque persistant SSD Hyperdisk Extreme |
| Bases de données HANA | /hana/shared |
Disque persistant avec équilibrage Disque persistant SSD |
| Bases de données HANA | /usr/sap |
Disque persistant avec équilibrage Disque persistant SSD |
| Bases de données HANA | /hanabackup |
Disque persistant avec équilibrage Disque persistant SSD |
| ASCS/ERS | boot | Disque persistant SSD |
| ASCS/ERS | /usr/sap |
Disque persistant avec équilibrage |
| PAS/AAS | boot | Disque persistant SSD |
| PAS/AAS | /usr/sap |
Disque persistant avec équilibrage |
| PAS/AAS | export-interfaces | Disque persistant avec équilibrage |
*Pour la base de données SAP HANA, vous pouvez sélectionner "Disque persistant avec équilibrage", "Disque persistant SSD" ou "Hyperdisque extrême" si ces options sont compatibles avec le type de machine sélectionné.
Si vous sélectionnez "Disque persistant équilibré" ou "Disque persistant SSD", tous les disques du déploiement sont de type sélectionné. Si vous sélectionnez Hyperdisk Extreme, seuls les volumes /data et /log utilisent Hyperdisk Extreme, et les autres volumes de disque utilisent un disque persistant SSD.
Mise en réseau
VPC partagé
Un VPC partagé à partir d'un projet hôte peut être utilisé pour le déploiement dans un projet de service. Si vous sélectionnez "VPC partagé", les ressources réseau suivantes sont créées dans le projet hôte.
- Règles de pare-feu
- L'instance Filestore réseau
- Règles de transfert
Règles de pare-feu
Au cours du processus de déploiement, Workload Manager crée automatiquement les règles de pare-feu pour autoriser la communication nécessaire entre les VM du déploiement. Dans les configurations haute disponibilité, ces règles de pare-feu permettent également d'effectuer des vérifications de l'état sur les équilibreurs de charge créés dans le sous-réseau spécifié.
Le Gestionnaire de charges de travail crée les règles de pare-feu suivantes:
DEPLOYMENT_NAME-communication-firewall: permet la communication entre les instances de VM du déploiement.Ilb-firewall-ascs-DEPLOYMENT_NAMEouIlb-firewall-ers-DEPLOYMENT_NAME: pour les configurations haute disponibilité uniquement. Active les vérifications d'état utilisées dans le basculement ASCS ou ERS.Ilb-firewall-db-DEPLOYMENT_NAME: pour les configurations de haute disponibilité uniquement. Active les vérifications de l'état utilisées dans le basculement de la base de données SAP HANA.
Lorsque vous utilisez une configuration de VPC partagé, ces règles de pare-feu sont créées dans le projet hôte où le réseau partagé est hébergé.
Équilibreurs de charge et règles de transfert
Dans les configurations haute disponibilité, les équilibreurs de charge et les règles de transfert suivants sont créés:
DEPLOYMENT_NAME-ascs-serviceDEPLOYMENT_NAME-ascs-forwarding-rule
DEPLOYMENT_NAME-db-serviceDEPLOYMENT_NAME-db-forwarding-rule
DEPLOYMENT_NAME-ers-serviceDEPLOYMENT_NAME-ers-forwarding-rule
Zones DNS
Lors du processus de configuration, vous pouvez choisir Workload Manager pour créer une zone Cloud DNS pour votre déploiement. Vous pouvez également ignorer la création de la zone DNS lors de la configuration et configurer manuellement une zone DNS plus tard.
Le Gestionnaire de charges de travail crée la zone et le DNS avec les noms suivants:
- Nom de la zone:
DEPLOYMENT_NAME - Nom DNS:
DEPLOYMENT_NAME-gcp.sapcloud.goog
Le Gestionnaire de charges de travail ajoute les ensembles d'enregistrements DNS nécessaires pour chaque VM du déploiement.
Lorsque vous utilisez une configuration VPC partagé, la configuration et la configuration liées au DNS se produisent dans le projet de service.
Filestore
Filestore Enterprise est un stockage de fichiers NFS hautes performances, entièrement géré et associé au réseau spécifié lors du processus de configuration. Sur les instances ASCS et ERS, il est utilisé pour les fichiers de transport, les répertoires /usr/sap/SID/ascs et /usr/sap/SID/ers. Sur les serveurs d'applications, il est utilisé pour le répertoire sapmnt/SID.
Lorsque vous utilisez une configuration VPC partagé, l'instance Filestore Enterprise est créée dans le projet hôte.
Points à noter concernant la sécurité
Cette section décrit les considérations de sécurité que le Gestionnaire de charges de travail prend en compte pour sécuriser vos déploiements sur Google Cloud.
Comptes de service et autorisations
Lors du processus de configuration, vous devez spécifier un compte de service utilisé pour l'authentification lors du déploiement de votre charge de travail. Workload Manager utilise les autorisations et les identifiants de ce compte de service pour appeler d'autres API et services Google Cloud utilisés lors du déploiement. Après avoir sélectionné un compte de service, le Gestionnaire de charges de travail évalue automatiquement les rôles IAM associés pour déterminer s'il dispose des autorisations nécessaires pour déployer votre système. Si un rôle est manquant, vous êtes invité à attribuer les rôles manquants, si vous disposez des autorisations nécessaires.
Les rôles suivants sont requis pour le compte de service utilisé pour déployer des systèmes SAP S/4HANA. Vous pouvez également créer des rôles personnalisés pour attribuer les autorisations individuelles requises lors du processus de déploiement. Notez que les autorisations spécifiques requises sont affichées à titre d'exemple uniquement. Les autorisations spécifiques peuvent varier en fonction de la configuration choisie et de la configuration du projet.
| Rôle IAM requis | Cas d'utilisation | Autorisations requises |
|---|---|---|
| Lecteur d'actions | Obligatoire pour vérifier que le projet est valide et que le compte de service dispose des autorisations requises pour accéder à la ressource. | resourcemanager.projects.get |
| Éditeur Cloud Filestore | Autorisations requises pour créer et gérer les volumes de stockage partagé Filestore Enterprise associés au déploiement. |
file.instances.create file.instances.delete file.instances.get file.operations.get |
| Agent Cloud Infrastructure Manager | Obligatoire pour le service Infrastructure Manager, qui permet de déployer l'infrastructure lors du déploiement à l'aide de la console Google Cloud . |
config.deployments.getLock config.deployments.getState config.deployments.updateState logging.logEntries.create storage.buckets.create storage.buckets.delete storage.buckets.get storage.objects.create storage.objects.delete storage.objects.get storage.objects.list |
| Administrateur de Compute | Autorisations requises pour créer et gérer toutes les ressources de calcul créées pour le déploiement |
compute.addresses.createInternal compute.addresses.deleteInternal compute.addresses.get compute.addresses.useInternal compute.disks.create compute.disks.delete compute.disks.get compute.disks.setLabels compute.disks.use compute.firewalls.create compute.firewalls.delete compute.firewalls.get compute.forwardingRules.create compute.forwardingRules.delete compute.forwardingRules.get compute.forwardingRules.setLabels compute.globalOperations.get compute.healthChecks.create compute.healthChecks.delete compute.healthChecks.get compute.healthChecks.useReadOnly compute.instanceGroups.create compute.instanceGroups.delete compute.instanceGroups.get compute.instanceGroups.update compute.instanceGroups.use compute.instances.create compute.instances.delete compute.instances.get compute.instances.setLabels compute.instances.setMetadata compute.instances.setServiceAccount compute.instances.setTags compute.instances.use compute.networks.get compute.networks.updatePolicy compute.regionBackendServices.create compute.regionBackendServices.delete compute.regionBackendServices.get compute.regionBackendServices.use compute.regionOperations.get compute.subnetworks.get compute.subnetworks.use compute.subnetworks.useExternalIp compute.zoneOperations.get compute.zones.get resourcemanager.projects.get serviceusage.services.list |
| Administrateur DNS | Autorisations requises pour créer une zone DNS et les ensembles d'enregistrements nécessaires. |
compute.networks.get dns.changes.create dns.changes.get dns.managedZones.create dns.managedZones.delete dns.managedZones.get dns.networks.bindPrivateDNSZone dns.resourceRecordSets.create dns.resourceRecordSets.delete dns.resourceRecordSets.list dns.resourceRecordSets.update resourcemanager.projects.get |
Administrateur IAM de projet |
Autorisations requises pour attribuer des rôles IAM aux comptes de service créés pour chaque couche du déploiement | resourcemanager.projects.get resourcemanager.projects.getIamPolicy resourcemanager.projects.setIamPolicy |
Administrateur de compte de service |
Autorisations requises pour créer et gérer les comptes de service créés pour chaque couche du déploiement. |
iam.serviceAccounts.create iam.serviceAccounts.delete iam.serviceAccounts.get iam.serviceAccounts.getIamPolicy iam.serviceAccounts.list iam.serviceAccounts.setIamPolicy resourcemanager.projects.get |
Utilisateur du compte de service |
Obligatoire pour autoriser le compte de service choisi à agir en tant que compte de service lors de l'appel d'autres produits et services |
iam.serviceAccounts.actAs iam.serviceAccounts.get iam.serviceAccounts.list resourcemanager.projects.get |
| Administrateur Service Usage | Autorisations permettant de vérifier l'état des API requises et d'activer les API, si nécessaire. | Serviceusage.services.list serviceusage.services.enable |
| Administrateur de l'espace de stockage | Autorisations requises pour accéder aux fichiers multimédias d'installation SAP importés dans Cloud Storage et les utiliser. | resourcemanager.projects.get storage.buckets.getIamPolicy storage.objects.get storage.objects.getIamPolicy storage.objects.list |
Lorsque vous utilisez une configuration de VPC partagé, les autorisations IAM suivantes peuvent également être requises dans le projet hôte, en plus des rôles précédents requis dans le projet de service.
- compute.firewalls.create
- compute.firewalls.delete
- compute.firewalls.get
- compute.globalOperations.get
- compute.networks.get
- compute.networks.updatePolicy
- compute.subnetworks.get
- compute.subnetworks.use
- compute.subnetworks.useExternalIp
- dns.networks.bindPrivateDNSZone
- file.instances.create
- file.instances.delete
- file.instances.get
- file.operations.get
Vous pouvez utiliser Workload Manager pour créer les comptes de service suivants pour chaque couche du déploiement. Workload Manager ne fournit que les autorisations requises à ces comptes de service pour leur rôle dans le déploiement. Vous pouvez également sélectionner un compte de service existant disposant des autorisations IAM requises pour chaque couche du déploiement.
| Compte de service pour: | Adresse e-mail du compte de service | Rôles IAM attribués |
|---|---|---|
| VM Ansible Runner | DEPLOYMENT_NAME-ansible@PROJECT_ID.iam.gserviceaccount.com |
Administrateur d'instances Compute (v1) Lecteur Compute Administrateur DNS Administrateur de journalisation Administrateur de surveillance Lecteur de rôles Accès aux secrets Secret Manager Lecteur Secret Manager Utilisateur du compte de service Lecteur d'objets de l'espace de stockage Rédacteur d'insights du gestionnaire de charges de travail |
| VM SAP ASCS / ERS | DEPLOYMENT_NAME-ascs@PROJECT_ID.iam.gserviceaccount.com |
Administrateur d'instances Compute (v1) Lecteur Compute Administrateur de journaux Administrateur de surveillance Rédacteur de métriques de surveillance Lecteur des objets de l'espace de stockage Rédacteur d'insights Workload Manager |
| VM d'application | DEPLOYMENT_NAME-app@PROJECT_ID.iam.gserviceaccount.com |
Lecteur Compute Administrateur de la journalisation Administrateur de la surveillance Rédacteur de métriques de surveillance Lecteur d'objets Storage Rédacteur d'insights Workload Manager |
| VM de base de données | DEPLOYMENT_NAME-db@PROJECT_ID.iam.gserviceaccount.com |
Administrateur d'instances Compute (v1) Lecteur Compute Administrateur de journalisation Administrateur de surveillance Rédacteur de métriques de surveillance Lecteur d'objets de l'espace de stockage Rédacteur d'insights Workload Manager |
Remplacez les éléments suivants :
DEPLOYMENT_NAME: nom de votre déploiement SAP.PROJECT_ID: ID de votre projet Google Cloud dans lequel vous créez le déploiement.
Pour en savoir plus sur l'IAM et les autorisations permettant d'exécuter SAP sur Google Cloud, consultez la page Gestion de l'authentification et des accès pour les programmes SAP sur Google Cloud.
Identifiants utilisateur de la base de données et de l'application SAP
Workload Manager utilise Secret Manager pour stocker les identifiants de votre système SAP, tels que le mot de passe des comptes utilisateur administrateur et SYSTEM. Pour fournir le mot de passe de manière sécurisée, vous devez créer un secret et l'utiliser lors du processus de déploiement. Vous pouvez créer des secrets distincts pour stocker les identifiants de votre base de données et des couches d'application.
Le secret fourni pour SAP HANA est utilisé comme mot de passe initial pour les utilisateurs suivants:
- Base de données système :
SYSTEMSERVICE_BACKUPDBACOCKPIT
- Base de données de locataire HANA :
SYSTEMSERVICE_BACKUP
- Base de données de locataire S/4HANA :
SYSTEMSAPDBCTRLDBACOCKPITSAPHANADB
Les identifiants de l'application sont utilisés pour les utilisateurs suivants dans le client 000:
DDICSAP*
Une fois le déploiement terminé, vous pouvez modifier ou attribuer de nouveaux mots de passe à ces utilisateurs.
API requises
Pour déployer une charge de travail SAP S/4HANA, les API et services suivants sont requis. Au cours du processus de déploiement, ces API sont automatiquement activées via Terraform si le compte de service que vous utilisez pour le déploiement dispose des autorisations nécessaires. Vous êtes soumis aux conditions d'utilisation de chacun de ces services. Des frais commenceront à vous être facturés lorsqu'ils seront utilisés dans la solution après le déploiement.
- API Resource Manager: pour gérer les ressources de vos projets.
- API Compute Engine: pour créer et gérer des VM pour votre déploiement.
- API Cloud DNS: pour créer une zone DNS pour votre déploiement.
- API Filestore: pour créer et gérer des Google Cloud serveurs de fichiers.
- API Service Account Credentials: permet de créer des identifiants pour les comptes de service sur Google Cloud.
- API Secret Manager: permet de créer et de gérer les secrets qui stockent les mots de passe de votre application et de votre base de données.
- API Service Usage: pour activer les services Google Cloud requis pour votre déploiement.
Assistance
Consultez Obtenir de l'aide concernant SAP sur Google Cloud.
Étape suivante
- Consultez les prérequis pour déployer un système SAP S/4HANA.
- Découvrez comment déployer une charge de travail SAP S/4HANA.