Umfang
In dieser Anleitung laden Sie ein exportiertes, benutzerdefiniertes TensorFlow Lite-Modell von AutoML Vision Edge herunter. Anschließend führen Sie eine vorab entwickelte iOS-App aus, die mithilfe des Modells mehrere Objekte in einem Bild (mit Begrenzungsrahmen) erkennt und die Objektkategorien mit einem benutzerdefinierten Label versieht.
Ziele
In dieser einführenden Schritt-für-Schritt-Anleitung verwenden Sie Code für die folgende Aufgabe:
- In einer iOS-App mit dem TF Lite-Interpreter ein AutoML Vision Object Detection Edge-Modell ausführen
Hinweis
Git-Repository klonen
Klonen Sie das Git-Repository mit dem folgenden Befehl in der Befehlszeile:
git clone https://github.com/tensorflow/examples.git
Wechseln Sie zum ios-Verzeichnis des lokalen Klons des Repositorys (examples/lite/examples/object_detection/ios/). Sie führen alle folgenden Codebeispiele aus dem ios-Verzeichnis aus:
cd examples/lite/examples/object_detection/ios
Vorbereitung
- Git muss installiert sein.
- Unterstützte iOS-Versionen: iOS 12.0 und höher.
iOS-App einrichten
Arbeitsbereichsdatei erstellen und öffnen
Zu Beginn der Einrichtung der ursprünglichen iOS-App müssen Sie zuerst die Arbeitsbereichsdatei mit der entsprechenden Software erstellen:
Rufen Sie den Ordner
iosauf, falls Sie dies noch nicht getan haben:cd examples/lite/examples/object_detection/ios
Installieren Sie den Pod, um die Arbeitsbereichsdatei zu erstellen:
pod install
Wenn Sie diesen Pod zuvor installiert haben, verwenden Sie den folgenden Befehl:
pod update
Nachdem Sie die Arbeitsbereichsdatei erstellt haben, können Sie das Projekt mit Xcode öffnen. Führen Sie zum Öffnen des Projekts über die Befehlszeile den folgenden Befehl aus dem
ios-Verzeichnis aus:open ./ObjectDetection.xcworkspace
Eindeutige ID und App erstellen
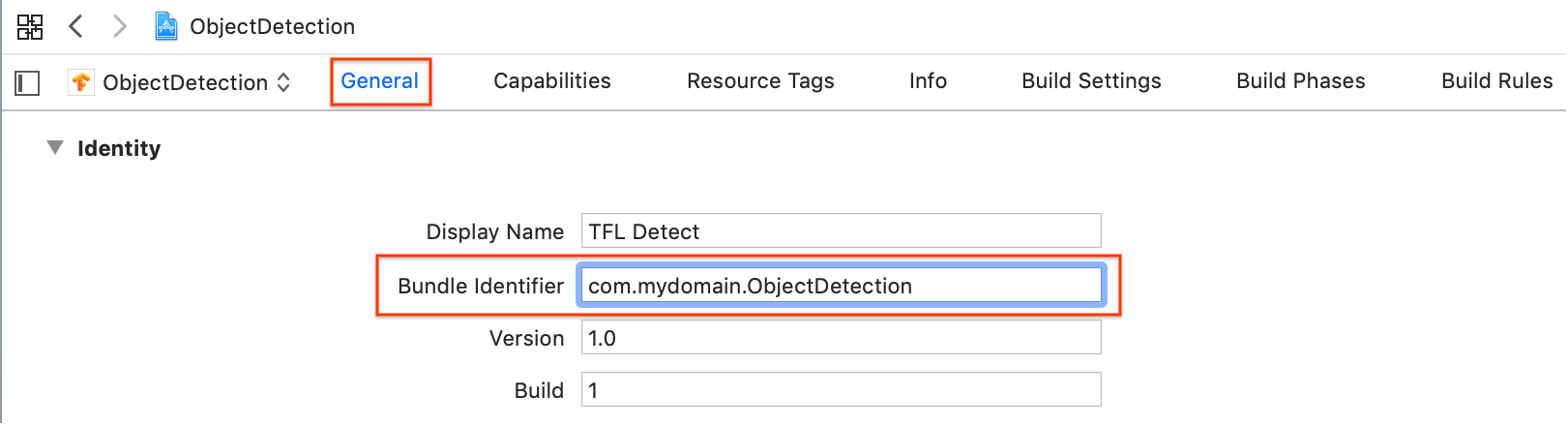
Bei geöffnetem ObjectDetection.xcworkspace in Xcode müssen Sie zuerst den Bundle Identifier (Paket-ID) in einen eindeutigen Wert ändern.
Wählen Sie links in der Projektnavigation das oberste
ObjectDetection-Projektelement aus.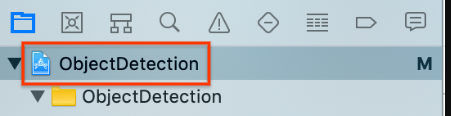
Achten Sie darauf, dass Sie Targets > ObjectDetection (Ziele > ObjectDetection) ausgewählt haben.
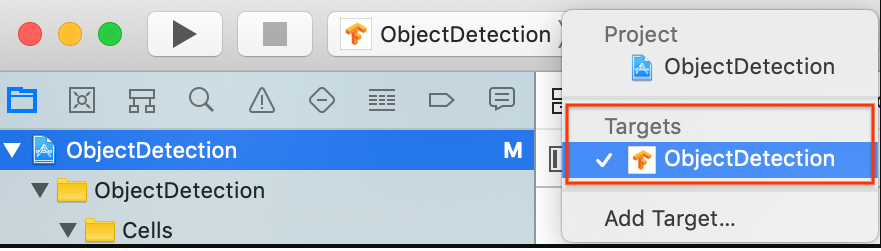
Ändern Sie im Bereich General > Identity (Allgemein > Identität) das Feld "Bundle Identifier" (Paket-Identifikator) in einen eindeutigen Wert. Der bevorzugte Stil ist die Reverse Domain Name Notation.
Geben Sie im Bereich General > Signing (Allgemein > Signieren) unter Identity (Identität) ein Team aus dem Drop-down-Menü an. Dieser Wert wird über Ihre Entwickler-ID bereitgestellt.
Verbinden Sie ein iOS-Gerät mit Ihrem Computer. Wählen Sie das Gerät, nachdem es erkannt wurde, aus der Liste der Geräte aus.
Erstellen Sie, nachdem Sie alle Konfigurationsänderungen angegeben haben, die App in Xcode mit dem folgenden Befehl: Befehl + B.
Ursprüngliche App ausführen
Bei der Beispiel-App handelt es sich um eine Kamera-App, die mithilfe eines quantisierten MobileNet-SSD-Modells, das mit dem COCO-Dataset trainiert wurde, kontinuierlich Objekte (Begrenzungsrahmen und Labels) in den von der Rückkamera des Geräts aus sichtbaren Frames erkennt.
In dieser Anleitung erfahren Sie, wie Sie die Demo auf einem iOS-Gerät erstellen und ausführen.
Die Modelldateien werden beim Erstellen und Ausführen über Skripts in Xcode heruntergeladen. Sie müssen keine Schritte ausführen, um TF Lite-Modelle explizit in das Projekt herunterzuladen.
Bevor Sie das benutzerdefinierte Modell einfügen, sollten Sie die Basisversion der App, die das trainierte Grundmodell "mobilenet" verwendet, testen.
Wählen Sie zum Starten der App im Simulator links oben im Xcode-Fenster die Schaltfläche Play
 (Wiedergabe) aus.
(Wiedergabe) aus.
Sobald Sie der App mit der Option Allow (Zulassen) Zugriff auf Ihre Kamera gewährt haben, startet die App die Live-Erkennung und -Annotation. Objekte werden erkannt und mit einem Begrenzungsrahmen sowie einem Label in jedem Kamera-Frame markiert.
Bewegen Sie das Gerät zu verschiedenen Objekten in Ihrer Umgebung und prüfen Sie, ob die App Bilder korrekt erkennt.
Angepasste App ausführen
Ändern Sie die App so, dass sie das neu trainierte Modell mit benutzerdefinierten Bildkategorien für Objekte verwendet.
Modelldateien zum Projekt hinzufügen
Das Demoprojekt ist so konfiguriert, dass im ios/objectDetection/model-Verzeichnis nach zwei Dateien gesucht wird:
detect.tflitelabelmap.txt
Führen Sie den folgenden Befehl aus, um diese beiden Dateien durch Ihre benutzerdefinierten Versionen zu ersetzen:
cp tf_files/optimized_graph.lite ios/objectDetection/model/detect.tflite cp tf_files/retrained_labels.txt ios/objectDetection/model/labelmap.txt
App ausführen
Wählen Sie für den Neustart der App auf Ihrem iOS-Gerät die Schaltfläche Play ![]() (Wiedergabe) links oben im Xcode-Fenster aus.
(Wiedergabe) links oben im Xcode-Fenster aus.
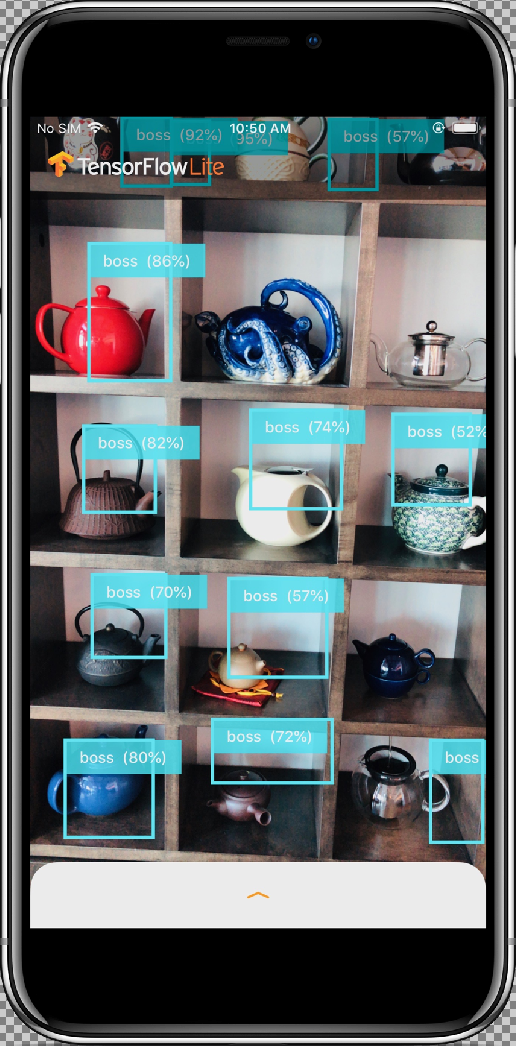
Zum Testen der Änderungen bewegen Sie die Kamera des Geräts auf eine Vielzahl von Objekten, damit Sie Live-Vorhersagen sehen.
Die Ergebnisse sollten in etwa so aussehen:
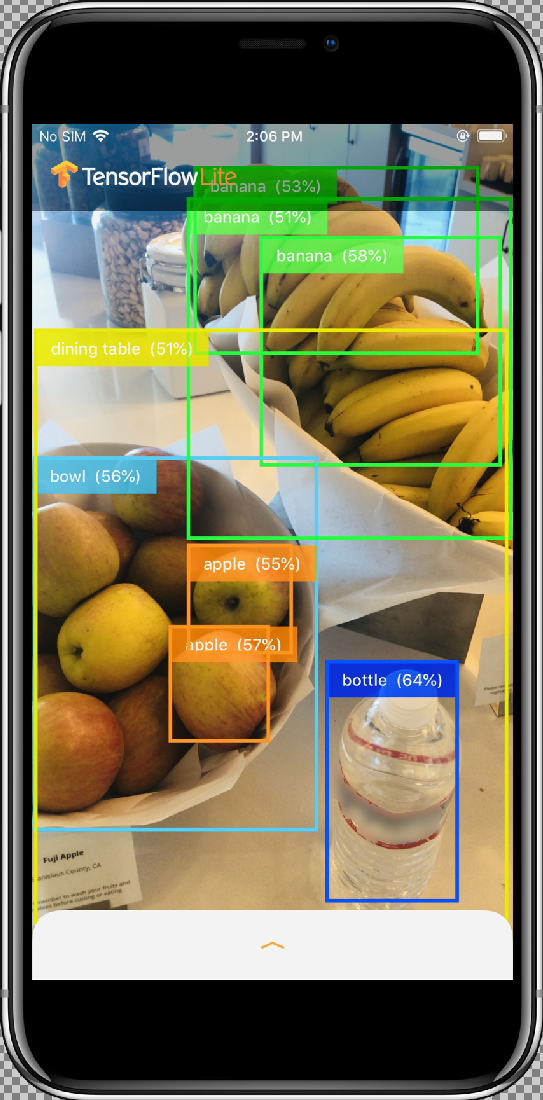
Funktionsweise
Sehen Sie sich, nachdem Sie die App ausgeführt haben, den TensorFlow Lite-spezifischen Code an.
TensorFlowLite-Pod
Diese App verwendet einen vorkompilierten TFLite CocoaPod. Die Pod-Datei enthält CocoaPod im Projekt:
# Uncomment the next line to define a global platform for your project platform :ios, '12.0' target 'ObjectDetection' do # Comment the next line if you're not using Swift and don't want to use dynamic frameworks use_frameworks! # Pods for ObjectDetection pod 'TensorFlowLiteSwift' end
Die Code-Schnittstelle zu TFLite ist in der Datei ModelDataHandler.swift enthalten. Diese Klasse übernimmt die gesamte Datenvorverarbeitung und führt Aufrufe durch, um Inferenz für einen bestimmten Frame auszuführen. Dazu wird der Interpreter aufgerufen.
Anschließend werden die erhaltenen Inferenzen formatiert und die besten N Ergebnisse für eine erfolgreiche Inferenz zurückgegeben.
Code erforschen
Der erste relevante Block (nach den erforderlichen Importen) sind Attributdeklarationen. Die inputShape-Parameter (batchSize, inputChannels, inputWidth, inputHeight) des TF Lite-Modells finden Sie in der tflite_metadata.json. Sie erhalten diese Datei beim Exportieren des TF Llite-Modells. Weitere Informationen finden Sie im Anleitungsthema Edge-Modelle exportieren.
Das Beispiel tflite_metadata.json ähnelt dem folgenden Code:
{
"inferenceType": "QUANTIZED_UINT8",
"inputShape": [
1, // This represents batch size
512, // This represents image width
512, // This represents image Height
3 //This represents inputChannels
],
"inputTensor": "normalized_input_image_tensor",
"maxDetections": 20, // This represents max number of boxes.
"outputTensorRepresentation": [
"bounding_boxes",
"class_labels",
"class_confidences",
"num_of_boxes"
],
"outputTensors": [
"TFLite_Detection_PostProcess",
"TFLite_Detection_PostProcess:1",
"TFLite_Detection_PostProcess:2",
"TFLite_Detection_PostProcess:3"
]
}
...
Modellparameter:
Ersetzen Sie in Ihrem Modell die folgenden Werte gemäß der tflite_metadata.json-Datei.
let batchSize = 1 //Number of images to get prediction, the model takes 1 image at a time let inputChannels = 3 //The pixels of the image input represented in RGB values let inputWidth = 300 //Width of the image let inputHeight = 300 //Height of the image ...
init
Die init-Methode, wodurch der Interpreter mit dem Model-Pfad und InterpreterOptions erstellt wird, weist dann Speicher zur Modelleingabe zu.
init?(modelFileInfo: FileInfo, labelsFileInfo: FileInfo, threadCount: Int = 1) {
let modelFilename = modelFileInfo.name
// Construct the path to the model file.
guard let modelPath = Bundle.main.path(forResource: modelFilename,ofType: modelFileInfo.extension)
// Specify the options for the `Interpreter`.
var options = InterpreterOptions()
options.threadCount = threadCount
do {
// Create the `Interpreter`.
interpreter = try Interpreter(modelPath: modelPath, options: options)
// Allocate memory for the model's input `Tensor`s.
try interpreter.allocateTensors()
}
super.init()
// Load the classes listed in the labels file.
loadLabels(fileInfo: labelsFileInfo)
}
…
runModel
Die folgende runModel-Methode:
- Skaliert das Eingabebild auf das Seitenverhältnis, für das das Modell trainiert wurde.
- Entfernt die Alpha-Komponente aus dem Bilderzwischenspeicher, um RGB-Daten abzurufen.
- Kopiert die RGB-Daten in den Eingabe-Tensor.
- Führt Inferenz durch Aufrufen des
Interpreteraus. - Ruft die Ausgabe vom Interpreter ab.
- Formatiert die Ausgabe.
func runModel(onFrame pixelBuffer: CVPixelBuffer) -> Result? {
Schneidet das Bild auf das größte Quadrat in der Mitte zu und skaliert es auf die Modellabmessungen herunter:
let scaledSize = CGSize(width: inputWidth, height: inputHeight)
guard let scaledPixelBuffer = pixelBuffer.resized(to: scaledSize) else
{
return nil
}
...
do {
let inputTensor = try interpreter.input(at: 0)
Entfernt die Alpha-Komponente aus dem Bilderzwischenspeicher, um RGB-Daten abzurufen:
guard let rgbData = rgbDataFromBuffer(
scaledPixelBuffer,
byteCount: batchSize * inputWidth * inputHeight * inputChannels,
isModelQuantized: inputTensor.dataType == .uInt8
) else {
print("Failed to convert the image buffer to RGB data.")
return nil
}
Kopiert die RGB-Daten in den Eingabe-Tensor:
try interpreter.copy(rgbData, toInputAt: 0)
Führt Inferenz durch Aufrufen des Interpreter aus:
let startDate = Date()
try interpreter.invoke()
interval = Date().timeIntervalSince(startDate) * 1000
outputBoundingBox = try interpreter.output(at: 0)
outputClasses = try interpreter.output(at: 1)
outputScores = try interpreter.output(at: 2)
outputCount = try interpreter.output(at: 3)
}
Formatiert die Ergebnisse:
let resultArray = formatResults(
boundingBox: [Float](unsafeData: outputBoundingBox.data) ?? [],
outputClasses: [Float](unsafeData: outputClasses.data) ?? [],
outputScores: [Float](unsafeData: outputScores.data) ?? [],
outputCount: Int(([Float](unsafeData: outputCount.data) ?? [0])[0]),
width: CGFloat(imageWidth),
height: CGFloat(imageHeight)
)
...
}
Filtert alle Ergebnisse mit Konfidenzwert < Schwellenwert heraus und gibt die besten N Ergebnisse in absteigender Reihenfolge zurück:
func formatResults(boundingBox: [Float], outputClasses: [Float],
outputScores: [Float], outputCount: Int, width: CGFloat, height: CGFloat)
-> [Inference]{
var resultsArray: [Inference] = []
for i in 0...outputCount - 1 {
let score = outputScores[i]
Filtert die Ergebnisse mit Konfidenzwert < Schwellenwert heraus:
guard score >= threshold else {
continue
}
Ruft die Ausgabeklassennamen für erkannte Klassen aus der Labelliste ab:
let outputClassIndex = Int(outputClasses[i])
let outputClass = labels[outputClassIndex + 1]
var rect: CGRect = CGRect.zero
Übersetzt den erkannten Begrenzungsrahmen in CGRect.
rect.origin.y = CGFloat(boundingBox[4*i])
rect.origin.x = CGFloat(boundingBox[4*i+1])
rect.size.height = CGFloat(boundingBox[4*i+2]) - rect.origin.y
rect.size.width = CGFloat(boundingBox[4*i+3]) - rect.origin.x
Die erkannten Ecken beziehen sich auf Modellabmessungen. Wir skalieren rect also in Bezug auf die tatsächlichen Bildabmessungen.
let newRect = rect.applying(CGAffineTransform(scaleX: width, y: height))
Ruft die für die Klasse zugewiesene Farbe ab:
let colorToAssign = colorForClass(withIndex: outputClassIndex + 1)
let inference = Inference(confidence: score,
className: outputClass,
rect: newRect,
displayColor: colorToAssign)
resultsArray.append(inference)
}
// Sort results in descending order of confidence.
resultsArray.sort { (first, second) -> Bool in
return first.confidence > second.confidence
}
return resultsArray
}
CameraFeedManager
CameraFeedManager.swift verwaltet alle Kamerafunktionen.
Initialisiert und konfiguriert AVCaptureSession:
private func configureSession() {session.beginConfiguration()
Anschließend wird versucht,
AVCaptureDeviceInputhinzuzufügen, undbuiltInWideAngleCamerawird als Geräteeingabe für die Sitzung hinzugefügt.addVideoDeviceInput()
Dann wird versucht,
AVCaptureVideoDataOutputhinzuzufügen:addVideoDataOutput()
session.commitConfiguration() self.cameraConfiguration = .success }Startet die Sitzung.
Stoppt die Sitzung.
AVCaptureSession-Benachrichtigungen werden hinzugefügt und entfernt.
Fehlerbehandlung:
- NSNotification.Name.AVCaptureSessionRuntimeError: wird angezeigt, wenn ein unerwarteter Fehler auftritt, während die
AVCaptureSession-Instanz ausgeführt wird. Das userInfo-Schlüsselverzeichnis enthält einNSError-Objekt für SchlüsselAVCaptureSessionErrorKey. - NSNotification.Name.AVCaptureSessionWasInterrupted: Wird angezeigt, wenn eine Unterbrechung (z. B. Telefonanruf, Alarm usw.) auftritt. Bei Bedarf wird die Ausführung der
AVCaptureSession-Instanz als Reaktion auf die Unterbrechung automatisch gestoppt. UserInfo enthältAVCaptureSessionInterruptionReasonKeyund gibt den Grund für die Unterbrechung an. - NSNotification.Name.AVCaptureSessionInterruptionEnded: Wird angezeigt, wenn
AVCaptureSessiondie Unterbrechung beendet. Die Sitzungsinstanz kann nach einer Unterbrechung, wenn beispielsweise ein Telefonanruf beendet wird, fortgesetzt werden.
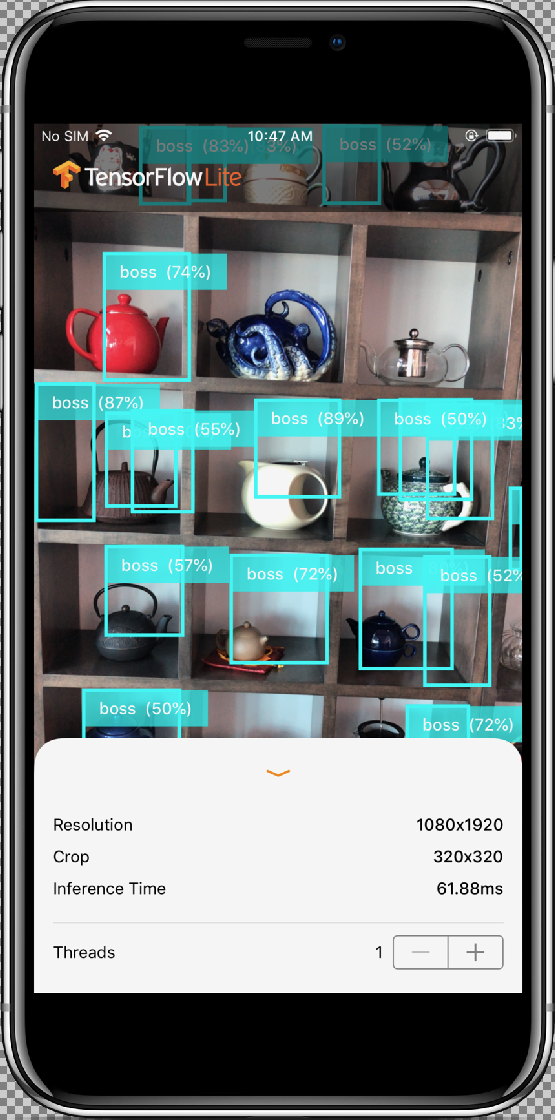
Die Klasse InferenceViewController.swift ist für den unteren Bildschirmbereich zuständig, wobei unser Hauptaugenmerk auf dem hervorgehobenen Teil liegt.
- Resolution (Auflösung): Zeigt die Auflösung des aktuellen Frames an (Bild aus Videositzung).
- Crop (Zuschneiden): Zeigt die Zuschneidegröße des aktuellen Frames an.
- Inference Time (Inferenzzeit): Zeigt an, wie viel Zeit das Modell benötigt, um das Objekt zu erkennen.
- Threads: Zeigt an, wie viele Threads ausgeführt werden.
Sie können diese Zahl erhöhen oder verringern. Tippen Sie dafür auf das Zeichen
+oder-des Steppers. Die aktuelle Thread-Anzahl, die vom TensorFlow Lite-Interpreter verwendet wird.
Die Klasse ViewController.swift enthält die Instanz CameraFeedManager, die die Kamerafunktionen verwaltet, und ModelDataHandler. ModelDataHandler verarbeitet das Model (trainiertes Modell) und ruft die Ausgabe für den Bildframe der Videositzung ab.
private lazy var cameraFeedManager = CameraFeedManager(previewView: previewView)
private var modelDataHandler: ModelDataHandler? =
ModelDataHandler(modelFileInfo: MobileNetSSD.modelInfo, labelsFileInfo: MobileNetSSD.labelsInfo)
Startet die Kamerasitzung durch Aufruf von:
cameraFeedManager.checkCameraConfigurationAndStartSession()
Wenn Sie die Anzahl der Threads ändern, initialisiert diese Klasse das Modell mit der neuen Thread-Anzahl in der didChangeThreadCount-Funktion neu.
Die Klasse CameraFeedManager sendet ImageFrame als CVPixelBuffer an ViewController, das zur Vorhersage an das Modell gesendet wird.
Bei dieser Methode wird der pixelBuffer der Live-Kamera über TensorFlow ausgeführt, um das Ergebnis abzurufen.
@objc
func runModel(onPixelBuffer pixelBuffer: CVPixelBuffer) {
Führt den pixelBuffer der Live-Kamera über TensorFlow aus, um das Ergebnis abzurufen:
result = self.modelDataHandler?.runModel(onFrame: pixelBuffer)
...
let displayResult = result
let width = CVPixelBufferGetWidth(pixelBuffer)
let height = CVPixelBufferGetHeight(pixelBuffer)
DispatchQueue.main.async {
Zeigt die Ergebnisse durch Übergabe an InferenceViewController an:
self.inferenceViewController?.resolution = CGSize(width: width, height: height) self.inferenceViewController?.inferenceTime = inferenceTime
Zeichnet die Begrenzungsrahmen und zeigt Klassennamen und Konfidenzwerte an:
self.drawAfterPerformingCalculations(onInferences: displayResult.inferences, withImageSize: CGSize(width: CGFloat(width), height: CGFloat(height)))
}
}
Nächste Schritte
Sie sind nun am Ende der Schritt-für-Schritt-Anleitung angelangt, in der gezeigt wird, wie Sie eine iOS-App zur Objekterkennung und Annotation mit einem Edge-Modell nutzen. Sie haben ein trainiertes Edge TensorFlow Lite-Modell verwendet, um eine App zur Objekterkennung zu testen, bevor Sie Änderungen daran vorgenommen und Beispielannotationen erhalten haben. Anschließend haben Sie TensorFlow Lite-spezifischen Code untersucht, um die zugrunde liegende Funktionalität nachzuvollziehen.
Die folgenden Informationen helfen Ihnen dabei, sich weiter mit TensorFlow-Modellen und AutoML Vision Edge vertraut zu machen:
- Weitere Informationen zu TFLite erhalten Sie in der offiziellen Dokumentation und im Code-Repository.
- Testen Sie andere TFLite-fähige Modelle, einschließlich einer Hot-Word-Erkennung für die Sprachausgabe und einer Version für intelligente Antworten auf dem Gerät.
- Allgemeine Informationen zu TensorFlow finden Sie in der Dokumentation zum Einstieg in TensorFlow.