요약
이 튜토리얼에서는 Vertex AI에서 vLLM을 사용하여 Llama 3.1 및 3.2 모델을 배포하고 서빙하는 프로세스를 안내합니다. 이 프로세스는 텍스트 전용 Llama 3.1 모델 배포를 위해 vLLM으로 Llama 3.1을 서빙하는 노트북과 텍스트 및 이미지 입력을 둘 다 처리하는 멀티모달 Llama 3.2 모델 배포를 위해 vLLM으로 멀티모달 Llama 3.2를 서빙하는 노트북 등, 2개의 개별 노트북과 함께 사용하도록 설계되었습니다. 이 페이지에 설명된 단계는 GPU에서 모델 추론을 효율적으로 처리하고 다양한 애플리케이션에 맞게 모델을 맞춤설정하는 방법을 안내하며 고급 언어 모델을 프로젝트에 통합하는 도구를 제공합니다.
이 가이드를 마치면 다음을 수행하는 방법을 이해할 수 있습니다.
- vLLM 컨테이너를 사용하여 Hugging Face에서 사전 빌드된 Llama 모델을 다운로드합니다.
- vLLM을 사용하여 Google CloudVertex AI Model Garden 내 GPU 인스턴스에 이러한 모델을 배포합니다.
- 추론 요청을 규모에 맞게 처리할 수 있도록 모델을 효율적으로 서빙합니다.
- 텍스트 전용 요청 및 텍스트 + 이미지 요청에서 추론을 실행합니다.
- 삭제
- 배포를 디버그합니다.
vLLM 주요 기능
| 기능 | 설명 |
|---|---|
| PagedAttention | 추론 중에 메모리를 효율적으로 관리하는 최적화된 어텐션 메커니즘 메모리 리소스를 동적으로 할당하여 높은 처리량의 텍스트 생성을 지원하므로 여러 동시 요청에 대한 확장이 가능합니다. |
| 연속 일괄 처리 | 병렬 처리를 위해 다중 입력 요청을 단일 일괄 처리로 통합하여 GPU 사용률과 처리량을 극대화합니다. |
| 토큰 스트리밍 | 텍스트 생성 중에 토큰별 실시간 출력을 사용 설정합니다. 챗봇이나 대화형 AI 시스템과 같이 지연 시간이 짧아야 하는 애플리케이션에 적합합니다. |
| 모델 호환성 | Hugging Face Transformers와 같은 인기 프레임워크에서 다양한 선행 학습된 모델을 지원합니다. 다양한 LLM을 더 쉽게 통합하고 실험할 수 있습니다. |
| 멀티 GPU 및 멀티 호스트 | 단일 머신 내의 여러 GPU와 클러스터의 여러 머신에 워크로드를 분산하여 효율적인 모델 서빙을 지원하므로 처리량과 확장성이 크게 향상됩니다. |
| 효율적인 배포 | OpenAI 채팅 완성과 같은 API와 원활하게 통합되므로 프로덕션 사용 사례에 쉽게 배포할 수 있습니다. |
| Hugging Face 모델과의 원활한 통합 | vLLM은 Hugging Face 모델 아티팩트 형식과 호환되며 HF에서 로드를 지원하므로 최적화된 설정에서 Gemma, Phi, Qwen과 같은 다른 인기 모델과 함께 Llama 모델을 간편하게 배포할 수 있습니다. |
| 커뮤니티 주도 오픈소스 프로젝트 | vLLM은 오픈소스이며 커뮤니티 참여를 장려하여 LLM 서빙 효율성을 지속적으로 개선합니다. |
Google Vertex AI vLLM 맞춤설정: 성능 및 통합 개선
Google Vertex AI Model Garden 내의 vLLM 구현은 오픈소스 라이브러리의 직접적인 통합이 아닙니다. Vertex AI는 Google Cloud내에서 성능, 안정성, 원활한 통합을 개선하도록 특별히 조정된 맞춤설정 및 최적화된 버전의 vLLM을 유지합니다.
- 성능 최적화:
- Cloud Storage에서 병렬 다운로드: Cloud Storage에서 병렬 데이터 검색을 지원하여 모델 로드 및 배포 시간을 크게 가속화하고 지연 시간을 줄이며 시작 속도를 개선합니다.
- 기능 개선사항:
- 향상된 캐싱 및 Cloud Storage 지원을 갖춘 동적 LoRA: Cloud Storage 경로 및 서명된 URL에서 직접 LoRA 가중치를 로드하는 기능과 함께 로컬 디스크 캐싱 메커니즘 및 강력한 오류 처리기능을 통해 동적 LoRA 기능을 확장합니다. 이를 통해 맞춤설정된 모델의 관리 및 배포가 간소화됩니다.
- Llama 3.1/3.2 함수 호출 파싱: Llama 3.1/3.2 함수 호출을 위한 전문 파싱을 구현하여 파싱의 견고성을 개선합니다.
- 호스트 메모리 프리픽스 캐싱: 외부 vLLM은 GPU 메모리 프리픽스 캐싱만 지원합니다.
- 추측 디코딩: 기존 vLLM 기능이지만 성능이 우수한 모델 설정을 찾기 위해 Vertex AI에서 실험을 진행했습니다.
이러한 Vertex AI별 맞춤설정은 최종 사용자들이 대개 의식하지 못하지만 이를 통해 Vertex AI Model Garden에서 Llama 3.1 배포의 성능과 효율성을 극대화할 수 있습니다.
- Vertex AI 생태계 통합:
- Vertex AI 예측 입력/출력 형식 지원: Vertex AI 예측 입력 및 출력 형식과의 원활한 호환성을 보장하여 데이터 처리 및 다른 Vertex AI 서비스와의 통합을 간소화합니다.
- Vertex 환경 변수 인식: 구성 및 리소스 관리에 Vertex AI 환경 변수(
AIP_*)를 사용하고 활용하여 배포를 간소화하고 Vertex AI 환경 내에서 일관된 동작을 보장합니다. - 오류 처리 및 견고성 향상: 포괄적인 오류 처리, 입력/출력 검증, 서버 종료 메커니즘을 구현하여 관리형 Vertex AI 환경 내에서 안정성, 신뢰성, 원활한 작업을 보장합니다.
- 기능을 위한 Nginx 서버: vLLM 서버 위에 Nginx 서버를 통합해 여러 복제본의 배포를 용이하게 하고 서빙 인프라의 확장성과 고가용성을 개선합니다.
vLLM의 추가 이점
- 벤치마크 성능: vLLM은 처리량과 지연 시간 측면에서 Hugging Face text-generation-inference 및 NVIDIA의 FasterTransformer 같은 다른 서빙 시스템과 비교할 때 경쟁력 있는 성능을 제공합니다.
- 사용 편의성: 이 라이브러리는 기존 워크플로와의 통합을 위한 직관적인 API를 제공하므로 최소한의 설정으로 Llama 3.1 및 3.2 모델을 모두 배포할 수 있습니다.
- 고급 기능: vLLM은 스트리밍 출력을 지원하고(토큰별로 응답 생성) 가변 길이 프롬프트를 효율적으로 처리하여 애플리케이션의 상호작용성과 응답성을 개선합니다.
vLLM 시스템에 대한 개요는 문서를 참조하세요.
지원되는 모델
vLLM은 다양한 최신 모델을 지원하므로 요구사항에 가장 적합한 모델을 선택할 수 있습니다. 다음 표에서는 이러한 모델을 선택하여 보여줍니다. 하지만 텍스트 전용 및 멀티모달 추론을 위한 모델을 포함하여 지원되는 모델의 포괄적인 목록에 액세스하려면 공식 vLLM 웹사이트를 참조하세요.
| 카테고리 | 모델 |
|---|---|
| Meta AI | Llama 3.3, Llama 3.2, Llama 3.1, Llama 3, Llama 2, Code Llama |
| Mistral AI | Mistral 7B, Mixtral 8x7B, Mixtral 8x22B, 및 변형 variants (Instruct, Chat), Mistral-tiny, Mistral-small, Mistral-medium |
| DeepSeek AI | DeepSeek-V3, DeepSeek-R1, DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Llama-8B, DeepSeek-R1-Distill-Qwen-14B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B, Deepseek-vl2-tiny, Deepseek-vl2-small, Deepseek-vl2 |
| MosaicML | MPT(7B, 30B) 및 변형 (안내, 채팅), MPT-7B-StoryWriter-65k |
| OpenAI | GPT-2, GPT-3, GPT-4, GPT-NeoX |
| Together AI | RedPajama, Pythia |
| Stability AI | StableLM(3B, 7B), StableLM-Alpha-3B, StableLM-Base-Alpha-7B, StableLM-Instruct-Alpha-7B |
| TII(기술 혁신 연구소) | Falcon 7B, Falcon 40B 및 변형 (Instruct, Chat), Falcon-RW-1B, Falcon-RW-7B |
| BigScience | BLOOM, BLOOMZ |
| FLAN-T5, UL2, Gemma(2B, 7B), PaLM 2, | |
| Salesforce | CodeT5, CodeT5+ |
| LightOn | Persimmon-8B-base, Persimmon-8B-chat |
| EleutherAI | GPT-Neo, Pythia |
| AI21 Labs | Jamba |
| Cerebras | Cerebras-GPT |
| Intel | Intel-NeuralChat-7B |
| 기타 주요 모델 | StarCoder, OPT, Baichuan, Aquila, Qwen, InternLM, XGen, OpenLLaMA, Phi-2, Yi, OpenCodeInterpreter, Nous-Hermes, Gemma-it, Mistral-Instruct-v0.2-7B-Zeus, |
Model Garden 시작하기
vLLM Cloud GPU 서빙 컨테이너는 Model Garden 플레이그라운드, 원클릭 배포, Colab Enterprise 노트북 예시로 통합되어 있습니다. 이 튜토리얼에서는 Meta AI의 Llama 모델 제품군을 예시로 들어 설명합니다.
Colab Enterprise 노트북 사용
Playground와 원클릭 배포도 사용할 수 있지만 이 튜토리얼에서는 설명하지 않습니다.
- 모델 카드 페이지로 이동하고 노트북 열기를 클릭합니다.
- Vertex Serving 노트북을 선택합니다. Colab Enterprise에서 노트북이 열립니다.
- 노트북을 실행하여 vLLM을 사용해 모델을 배포하고 엔드포인트에 예측 요청을 전송합니다.
설정 및 요건
이 섹션에서는 Google Cloud프로젝트를 설정하고 vLLM 모델을 배포하고 서빙하는 데 필요한 리소스를 확보하는 데 필요한 단계를 간략히 설명합니다.
1. 결제
- 결제 사용 설정: 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트의 결제 사용 설정, 사용 중지, 변경을 참조하세요.
2. GPU 가용성 및 할당량
- 고성능 GPU(NVIDIA A100 80GB 또는 H100 80GB)를 사용하여 예측을 실행하려면 선택한 리전에서 이러한 GPU의 할당량을 확인하세요.
| 머신 유형 | 가속기 유형 | 추천 리전 |
|---|---|---|
| a2-ultragpu-1g | 1 NVIDIA_A100_80GB | us-central1, us-east4, europe-west4, asia-southeast1 |
| a3-highgpu-8g | 8 NVIDIA_H100_80GB | us-central1, us-west1, europe-west4, asia-southeast1 |
3. Google Cloud 프로젝트 설정
다음 코드 샘플을 실행하여 Google Cloud 환경이 올바르게 설정되었는지 확인합니다. 이 단계에서는 필요한 Python 라이브러리를 설치하고 Google Cloud 리소스에 대한 액세스를 설정합니다. 다음 작업이 포함됩니다.
- 설치:
google-cloud-aiplatform라이브러리를 업그레이드하고 유틸리티 함수가 포함된 저장소를 클론합니다. - 환경 설정: Google Cloud 프로젝트 ID, 리전, 모델 아티팩트를 저장할 고유한 Cloud Storage 버킷의 변수를 정의합니다.
- API 활성화: AI 모델을 배포하고 관리하는 데 필수적인 Vertex AI 및 Compute Engine API를 사용 설정합니다.
- 버킷 구성: 새 Cloud Storage 버킷을 만들거나 기존 버킷을 확인하여 올바른 리전에 있는지 확인합니다.
- Vertex AI 초기화: 프로젝트, 위치, 스테이징 버킷 설정으로 Vertex AI 클라이언트 라이브러리를 초기화합니다.
- 서비스 계정 설정: Vertex AI 작업을 실행하고 필요한 권한을 부여할 기본 서비스 계정을 식별합니다.
BUCKET_URI = "gs://"
REGION = ""
! pip3 install --upgrade --quiet 'google-cloud-aiplatform>=1.64.0'
! git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.git
import datetime
import importlib
import os
import uuid
from typing import Tuple
import requests
from google.cloud import aiplatform
common_util = importlib.import_module(
"vertex-ai-samples.community-content.vertex_model_garden.model_oss.notebook_util.common_util"
)
models, endpoints = {}, {}
PROJECT_ID = os.environ["GOOGLE_CLOUD_PROJECT"]
if not REGION:
REGION = os.environ["GOOGLE_CLOUD_REGION"]
print("Enabling Vertex AI API and Compute Engine API.")
! gcloud services enable aiplatform.googleapis.com compute.googleapis.com
now = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
if BUCKET_URI is None or BUCKET_URI.strip() == "" or BUCKET_URI == "gs://":
BUCKET_URI = f"gs://{PROJECT_ID}-tmp-{now}-{str(uuid.uuid4())[:4]}"
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
! gsutil mb -l {REGION} {BUCKET_URI}
else:
assert BUCKET_URI.startswith("gs://"), "BUCKET_URI must start with `gs://`."
shell_output = ! gsutil ls -Lb {BUCKET_NAME} | grep "Location constraint:" | sed "s/Location constraint://"
bucket_region = shell_output[0].strip().lower()
if bucket_region != REGION:
raise ValueError(
"Bucket region %s is different from notebook region %s"
% (bucket_region, REGION)
)
print(f"Using this Bucket: {BUCKET_URI}")
STAGING_BUCKET = os.path.join(BUCKET_URI, "temporal")
MODEL_BUCKET = os.path.join(BUCKET_URI, "llama3_1")
print("Initializing Vertex AI API.")
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET)
shell_output = ! gcloud projects describe $PROJECT_ID
project_number = shell_output[-1].split(":")[1].strip().replace("'", "")
SERVICE_ACCOUNT = "your service account email"
print("Using this default Service Account:", SERVICE_ACCOUNT)
! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.admin $BUCKET_NAME
! gcloud config set project $PROJECT_ID
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/storage.admin"
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/aiplatform.user"
Meta Llama 3.1, 3.2 및 vLLM과 함께 Hugging Face 사용
Meta의 Llama 3.1 및 3.2 컬렉션은 다양한 사용 사례에서 고품질 텍스트를 생성하도록 설계된 다양한 다국어 대규모 언어 모델(LLM)을 제공합니다. 이러한 모델은 선행 학습되고 요청 사항에 맞게 조정되어 다국어 대화, 요약, 에이전트형 검색과 같은 작업에 탁월합니다. Llama 3.1 및 3.2 모델을 사용하려면 스크린샷에 표시된 이용약관에 동의해야 합니다. vLLM 라이브러리는 지연 시간, 메모리 효율성, 확장성을 최적화한 오픈소스 기반의 간소화된 서빙 환경을 제공합니다.
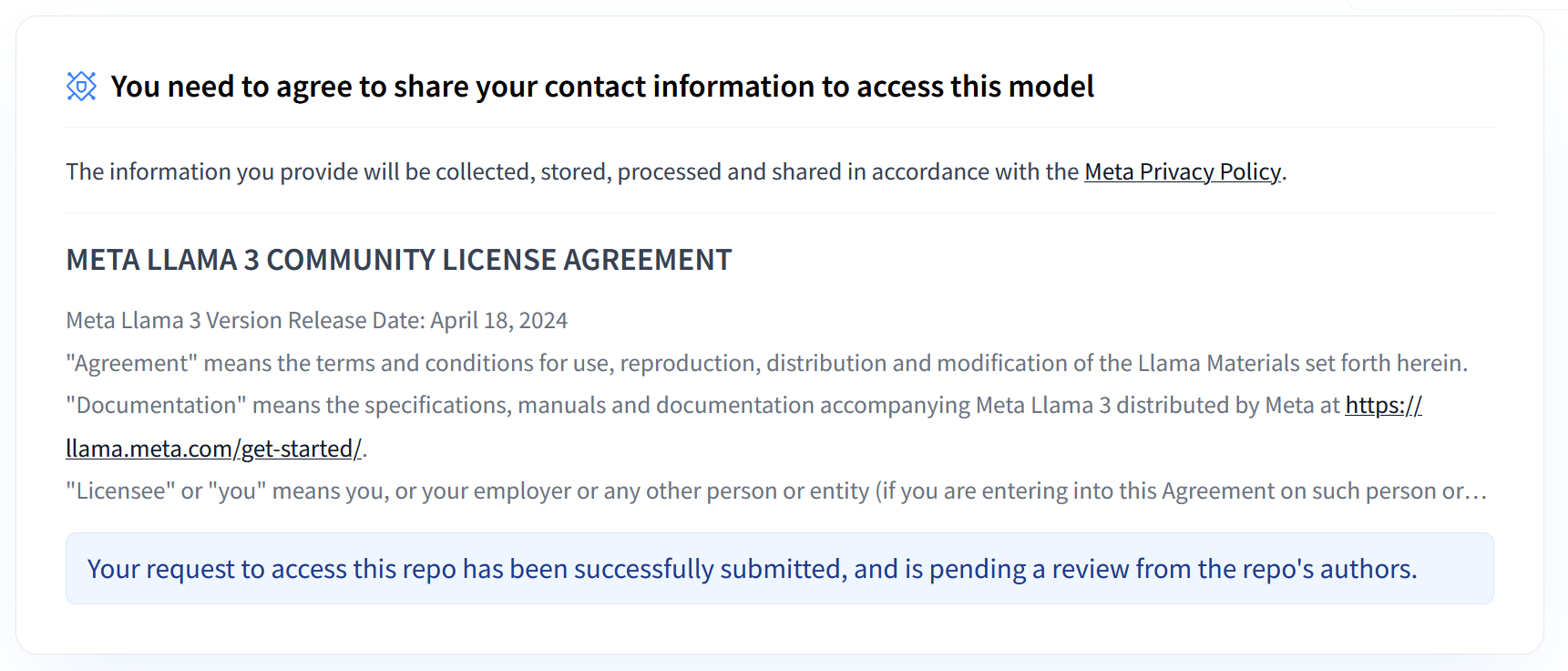 그림 1: Meta LLama 3 커뮤니티 라이선스 계약
그림 1: Meta LLama 3 커뮤니티 라이선스 계약
Meta Llama 3.1 및 3.2 컬렉션 개요
Llama 3.1 및 3.2 컬렉션은 각각 서로 다른 배포 규모와 모델 크기에 맞게 제공되어 다국어 대화 작업 등에 유연한 옵션을 제공합니다. 자세한 내용은 Llama 개요 페이지를 참조하세요.
- 텍스트 전용: 다국어 대규모 언어 모델(LLM)의 Llama 3.2 컬렉션은 10억 개 및 30억 개 크기(텍스트 입력, 텍스트 출력)로 선행 학습되고 요청 사항에 맞게 조정된 생성 모델 컬렉션입니다.
- Vision 및 Vision Instruct: 멀티모달 대규모 언어 모델(LLM)의 Llama 3.2-Vision 컬렉션은 110억 개 및 900억 개 크기(텍스트 + 이미지 입력, 텍스트 출력)로 선행 학습되고 요청 사항에 맞게 조정된 이미지 추론 생성 모델 컬렉션입니다. 최적화: Llama 3.1과 마찬가지로 3.2 모델은 다국어 대화에 맞게 조정되었으며 검색 및 요약 작업에서 우수한 성능을 보여 표준 벤치마크에서 최고의 결과를 달성합니다.
- 모델 아키텍처: Llama 3.2에는 자동 회귀 Transformer 프레임워크와 SFT 및 RLHF를 적용하여 유용성과 안전성을 위해 모델을 정렬하는 기능을 갖추고 있습니다.
Hugging Face 사용자 액세스 토큰
이 튜토리얼에서는 필요한 리소스에 액세스하기 위해 Hugging Face Hub의 읽기 액세스 토큰이 필요합니다. 다음 단계에 따라 인증을 설정하세요.
 그림 2: Hugging Face 액세스 토큰 설정
그림 2: Hugging Face 액세스 토큰 설정
읽기 액세스 토큰 생성
- Hugging Face 계정 설정으로 이동합니다.
- 새 토큰을 만들고 읽기 역할을 할당한 후 토큰을 안전하게 저장합니다.
토큰 사용
- 생성된 토큰을 사용하여 튜토리얼에 필요한 대로 공개 또는 비공개 저장소를 인증하고 액세스합니다.
 그림 3: Hugging Face 액세스 토큰 관리
그림 3: Hugging Face 액세스 토큰 관리
이렇게 설정하면 불필요한 권한 없이 적절한 수준의 액세스 권한을 확보할 수 있습니다. 이러한 관행은 보안을 강화하고 실수로 인한 토큰 노출을 방지합니다. 액세스 토큰 설정에 관한 자세한 내용은 Hugging Face 액세스 토큰 페이지를 참조하세요.
토큰을 공개적으로 또는 온라인에 공유하거나 노출하지 마세요. 배포 중에 토큰을 환경 변수로 설정하면 프로젝트에서 비공개로 유지됩니다. Vertex AI는 다른 사용자가 모델과 엔드포인트에 액세스하지 못하도록 하여 보안을 보장합니다.
액세스 토큰 보호에 관한 자세한 내용은 Hugging Face 액세스 토큰 - 권장사항을 참조하세요.
vLLM으로 텍스트 전용 Llama 3.1 모델 배포
대규모 언어 모델의 프로덕션 수준 배포를 위해 vLLM은 메모리 사용량을 최적화하고, 지연 시간을 줄이며, 처리량을 늘리는 효율적인 서빙 솔루션을 제공합니다. 이로 인해 대규모 Llama 3.1 모델은 물론, 멀티모달 Llama 3.2 모델을 처리하는 데에도 특히 적합합니다.
1단계: 배포할 모델 선택
배포할 Llama 3.1 모델 변형을 선택합니다. 사용 가능한 옵션에는 다양한 크기와 명령어에 맞게 조정된 버전이 포함됩니다.
base_model_name = "Meta-Llama-3.1-8B" # @param ["Meta-Llama-3.1-8B", "Meta-Llama-3.1-8B-Instruct", "Meta-Llama-3.1-70B", "Meta-Llama-3.1-70B-Instruct", "Meta-Llama-3.1-405B-FP8", "Meta-Llama-3.1-405B-Instruct-FP8"]
hf_model_id = "meta-Llama/" + base_model_name
2단계: 배포 하드웨어 및 할당량 확인
배포 함수는 모델 크기에 따라 적절한 GPU 및 머신 유형을 설정하고 특정 프로젝트에 대한 해당 리전에서 할당량을 확인합니다.
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
지정된 리전에서 GPU 할당량 가용성을 확인합니다.
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
3단계: vLLM을 사용하여 모델 검사
다음 함수는 모델을 Vertex AI에 업로드하고, 배포 설정을 구성하고, vLLM을 사용하여 엔드포인트에 배포합니다.
- Docker 이미지: 배포는 효율적인 서빙을 위해 사전 빌드된 vLLM Docker 이미지를 사용합니다.
- 구성: 메모리 사용량, 모델 길이, 기타 vLLM 설정을 구성합니다. 서버에서 지원하는 인수에 관한 자세한 내용은 공식 vLLM 문서 페이지를 참조하세요.
- 환경 변수: 인증 및 배포 소스의 환경 변수를 설정합니다.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 256,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
vllm_args = [
"python", "-m", "vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}", f"--dtype={dtype}",
f"--max-loras={max_loras}", f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}", "--disable-log-stats"
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": model_id,
"DEPLOY_SOURCE": "notebook",
"HF_TOKEN": HF_TOKEN
}
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
4단계: 배포 실행
선택한 모델과 구성으로 배포 함수를 실행합니다. 이 단계에서는 모델을 배포하고 모델 및 엔드포인트 인스턴스를 반환합니다.
HF_TOKEN = ""
VLLM_DOCKER_URI = "us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241001_0916_RC00"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
gpu_memory_utilization = 0.9
max_model_len = 4096
max_loras = 1
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve"),
model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=use_dedicated_endpoint,
)
이 코드 샘플을 실행하면 Llama 3.1 모델이 Vertex AI에 배포되고 지정된 엔드포인트를 통해 액세스할 수 있습니다. 텍스트 생성, 요약, 대화와 같은 추론 작업을 위해 상호작용할 수 있습니다. 모델 크기에 따라 새 모델 배포에 최대 1시간이 걸릴 수 있습니다. 온라인 예측에서 진행 상황을 확인할 수 있습니다.
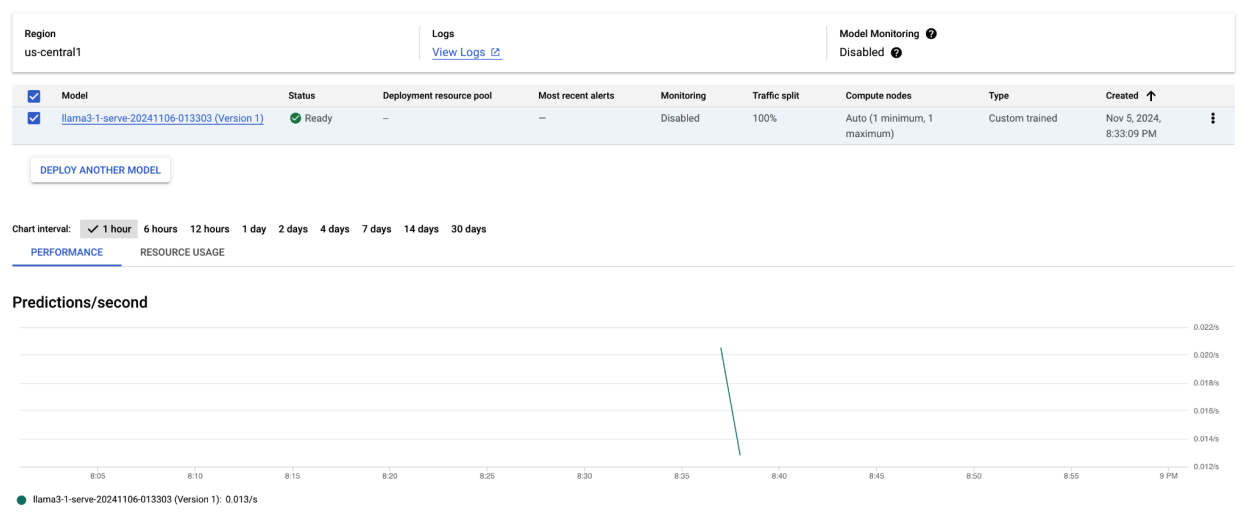 그림 4: Vertex 대시보드의 Llama 3.1 배포 엔드포인트
그림 4: Vertex 대시보드의 Llama 3.1 배포 엔드포인트
Vertex AI에서 Llama 3.1로 예측하기
Llama 3.1 모델을 Vertex AI에 성공적으로 배포한 후 엔드포인트에 텍스트 프롬프트를 전송하여 예측을 시작할 수 있습니다. 이 섹션에서는 출력을 제어하기 위해 맞춤설정 가능한 다양한 파라미터를 사용하여 응답을 생성하는 예시를 제공합니다.
1단계: 프롬프트 및 파라미터 정의
먼저 텍스트 프롬프트와 샘플링 파라미터를 설정하여 모델의 응답을 유도합니다. 주요 파라미터 다음과 같습니다.
prompt: 모델에게 응답 생성을 요청하는 입력 텍스트입니다. 예: 프롬프트 = '자동차란 무엇인가요?'max_tokens: 생성된 출력의 최대 토큰 수입니다. 이 값을 줄이면 제한 시간 문제를 방지하는 데 도움이 됩니다.temperature: 예측 무작위성을 제어합니다. 값이 클수록(예: 1.0) 다양성이 증가하고 값이 작을수록(예: 0.5) 출력이 더 집중됩니다.top_p: 샘플링 풀을 상위 누적 확률 값으로 제한합니다. 예를 들어 top_p = 0.9를 설정하면 상위 90% 확률 질량 내의 토큰만 고려됩니다.top_k: 샘플링을 가장 가능성이 높은 상위 k개 토큰으로 제한합니다. 예를 들어 top_k = 50을 설정하면 상위 50개 토큰에서만 샘플링됩니다.raw_response: True인 경우 원시 모델 출력을 반환합니다. False인 경우 'Prompt:\n{prompt}\nOutput:\n{output}' 구조로 추가 형식을 적용합니다.lora_id(선택사항): LoRA(Low-Rank Adaptation) 가중치를 적용할 LoRA 가중치 파일의 경로입니다. Cloud Storage 버킷 또는 Hugging Face 저장소 URL일 수 있습니다. 이는 배포 인수에--enable-lora가 설정된 경우에만 작동합니다. 멀티모달 모델에서는 동적 LoRA가 지원되지 않습니다.
prompt = "What is a car?"
max_tokens = 50
temperature = 1.0
top_p = 1.0
top_k = 1
raw_response = False
lora_id = ""
2단계: 예측 요청 보내기
이제 인스턴스가 구성되었으므로 배포된 Vertex AI 엔드포인트에 예측 요청을 보낼 수 있습니다. 다음 예시에서는 예측을 실행하고 결과를 출력하는 방법을 보여줍니다.
response = endpoints["vllm_gpu"].predict(
instances=instances, use_dedicated_endpoint=use_dedicated_endpoint
)
for prediction in response.predictions:
print(prediction)
출력 예
다음은 모델이 '자동차란 무엇인가요?'라는 프롬프트에 응답하는 방법의 예시입니다.
Human: What is a car?
Assistant: A car, or a motor car, is a road-connected human-transportation system
used to move people or goods from one place to another.
기타 참고사항
- 검토: 안전한 콘텐츠를 보장하기 위해 Vertex AI의 텍스트 검토 기능을 사용하여 생성된 텍스트를 검토할 수 있습니다.
- 제한 시간 처리:
ServiceUnavailable: 503과 같은 문제가 발생하면max_tokens파라미터를 줄여보세요.
이 접근 방식은 다양한 샘플링 기법과 LoRA 어댑터를 사용하여 Llama 3.1 모델과 상호작용하는 유연한 방법을 제공하므로 범용 텍스트 생성부터 작업별 응답까지 다양한 사용 사례에 적합합니다.
vLLM으로 멀티모달 Llama 3.2 모델 배포
이 섹션에서는 사전 빌드된 Llama 3.2 모델을 Model Registry에 업로드하고 Vertex AI 엔드포인트에 배포하는 과정을 안내합니다. 모델의 크기에 따라 배포 시간이 최대 1시간까지 걸릴 수 있습니다. Llama 3.2 모델은 텍스트와 이미지 입력을 모두 지원하는 멀티모달 버전으로 제공됩니다. vLLM은 다음을 지원합니다.
- 텍스트 전용 형식
- 단일 이미지 + 텍스트 형식
이러한 형식을 사용하면 Llama 3.2를 시각적 처리와 텍스트 처리가 모두 필요한 애플리케이션에 적합하게 사용할 수 있습니다.
1단계: 배포할 모델 선택
배포하려는 Llama 3.2 모델 변형을 지정합니다. 다음 예시에서는 Llama-3.2-11B-Vision을 선택한 모델로 사용하지만 요구사항에 따라 사용 가능한 다른 옵션 중에서 선택할 수 있습니다.
base_model_name = "Llama-3.2-11B-Vision" # @param ["Llama-3.2-1B", "Llama-3.2-1B-Instruct", "Llama-3.2-3B", "Llama-3.2-3B-Instruct", "Llama-3.2-11B-Vision", "Llama-3.2-11B-Vision-Instruct", "Llama-3.2-90B-Vision", "Llama-3.2-90B-Vision-Instruct"]
hf_model_id = "meta-Llama/" + base_model_name
2단계: 하드웨어 및 리소스 구성
모델 크기에 적합한 하드웨어를 선택합니다. vLLM은 모델의 컴퓨팅 요구사항에 따라 다른 GPU를 사용할 수 있습니다.
- 1B 및 3B 모델: NVIDIA L4 GPU를 사용합니다.
- 11B 모델: NVIDIA A100 GPU를 사용합니다.
- 90B 모델: NVIDIA H100 GPU를 사용합니다.
이 예시에서는 모델 선택에 따라 배포를 구성합니다.
if "3.2-1B" in base_model_name or "3.2-3B" in base_model_name:
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-8"
accelerator_count = 1
elif "3.2-11B" in base_model_name:
accelerator_type = "NVIDIA_TESLA_A100"
machine_type = "a2-highgpu-1g"
accelerator_count = 1
elif "3.2-90B" in base_model_name:
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {base_model_name}.")
필요한 GPU 할당량이 있는지 확인합니다.
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
3단계: vLLM을 사용하여 모델 배포
다음 함수는 Vertex AI에 Llama 3.2 모델을 배포합니다. 효율적인 서빙을 위해 모델의 환경, 메모리 사용량, vLLM 설정을 구성합니다.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 12,
model_type: str = None,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if not base_model_id:
base_model_id = model_id
vllm_args = [
"python",
"-m",
"vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}",
f"--dtype={dtype}",
f"--max-loras={max_loras}",
f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}",
"--disable-log-stats",
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": base_model_id,
"DEPLOY_SOURCE": "notebook",
}
# HF_TOKEN is not a compulsory field and may not be defined.
try:
if HF_TOKEN:
env_vars["HF_TOKEN"] = HF_TOKEN
except NameError:
pass
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
4단계: 배포 실행
구성된 모델과 설정으로 배포 함수를 실행합니다. 이 함수는 추론에 사용할 수 있는 모델과 엔드포인트 인스턴스를 모두 반환합니다.
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
enforce_eager=True,
use_dedicated_endpoint=use_dedicated_endpoint,
max_num_seqs=max_num_seqs,
)
 그림 5: Vertex 대시보드의 Llama 3.2 배포 엔드포인트
그림 5: Vertex 대시보드의 Llama 3.2 배포 엔드포인트
모델 크기에 따라 새 모델 배포가 완료되는 데 최대 1시간이 걸릴 수 있습니다. 온라인 예측에서 진행 상황을 확인할 수 있습니다.
기본 예측 경로를 사용하여 Vertex AI에서 vLLM을 통한 추론
이 섹션에서는 기본 예측 경로를 사용하여 Vertex AI에서 Llama 3.2 Vision 모델의 추론을 설정하는 방법을 안내합니다. 효율적인 서빙을 위해 vLLM 라이브러리를 사용하고 텍스트와 함께 시각적 프롬프트를 전송하여 모델과 상호작용합니다.
시작하려면 모델 엔드포인트가 배포되어 예측을 수행할 준비가 되었는지 확인하세요.
1단계: 프롬프트 및 파라미터 정의
이 예시에서는 모델이 처리하여 응답을 생성하는 이미지 URL과 텍스트 프롬프트를 제공합니다.
 그림 6: Llama 3.2 프롬프트용 샘플 이미지 입력
그림 6: Llama 3.2 프롬프트용 샘플 이미지 입력
image_url = "https://images.pexels.com/photos/1254140/pexels-photo-1254140.jpeg"
raw_prompt = "This is a picture of"
# Reference prompt formatting guidelines here: https://www.Llama.com/docs/model-cards-and-prompt-formats/Llama3_2/#-base-model-prompt
prompt = f"<|begin_of_text|><|image|>{raw_prompt}"
2단계: 예측 파라미터 구성
다음 파라미터를 조정하여 모델의 응답을 제어합니다.
max_tokens = 64
temperature = 0.5
top_p = 0.95
3단계: 예측 요청 준비
이미지 URL, 프롬프트, 기타 매개변수를 사용하여 예측 요청을 설정합니다.
instances = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_url},
"max_tokens": max_tokens,
"temperature": temperature,
"top_p": top_p,
},
]
4단계: 예측하기
Vertex AI 엔드포인트에 요청을 보내고 응답을 처리합니다.
response = endpoints["vllm_gpu"].predict(instances=instances)
for raw_prediction in response.predictions:
prediction = raw_prediction.split("Output:")
print(prediction[1])
제한 시간 문제가 발생하면(예: ServiceUnavailable: 503 Took too
long to respond when processing) max_tokens 값을 더 낮은 숫자(예: 20)로 줄여 응답 시간을 완화해 보세요.
OpenAI Chat Completion을 사용하여 Vertex AI에서 vLLM을 통한 추론
이 섹션에서는 Vertex AI에서 OpenAI Chat Completions API를 사용하여 Llama 3.2 Vision 모델에 대한 추론을 실행하는 방법을 다룹니다. 이 접근 방식을 사용하면 이미지와 텍스트 프롬프트를 모두 모델에 전송하여 보다 상호작용적인 응답을 얻을 수 있는 멀티모달 기능을 사용할 수 있습니다.
1단계: Llama 3.2 Vision Instruct 모델 배포 실행
구성된 모델과 설정으로 배포 함수를 실행합니다. 이 함수는 추론에 사용할 수 있는 모델과 엔드포인트 인스턴스를 모두 반환합니다.
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
model, endpoint = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type="a2-highgpu-1g",
accelerator_type="NVIDIA_TESLA_A100",
accelerator_count=1,
gpu_memory_utilization=0.9,
max_model_len=4096,
enforce_eager=True,
max_num_seqs=12,
)
2단계: 엔드포인트 리소스 구성
먼저 Vertex AI 배포에 대한 엔드포인트 리소스 이름을 설정합니다.
ENDPOINT_RESOURCE_NAME = "projects/{}/locations/{}/endpoints/{}".format(
PROJECT_ID, REGION, endpoint.name
)
3단계: OpenAI SDK 및 인증 라이브러리 설치
OpenAI의 SDK를 사용하여 요청을 보내려면 필요한 라이브러리가 설치되어 있어야 합니다.
!pip install -qU openai google-auth requests
4단계: Chat Completion의 입력 파라미터 정의
모델에 전송될 이미지 URL과 텍스트 프롬프트를 설정합니다. 응답 길이와 무작위성을 각각 제어하려면 max_tokens 및 temperature를 조정합니다.
user_image = "https://images.freeimages.com/images/large-previews/ab3/puppy-2-1404644.jpg"
user_message = "Describe this image?"
max_tokens = 50
temperature = 1.0
5단계: 인증 및 기준 URL 설정
사용자 인증 정보를 가져오고 API 요청의 기준 URL을 설정합니다.
import google.auth
import openai
creds, project = google.auth.default()
auth_req = google.auth.transport.requests.Request()
creds.refresh(auth_req)
BASE_URL = (
f"https://{REGION}-aiplatform.googleapis.com/v1beta1/{ENDPOINT_RESOURCE_NAME}"
)
try:
if use_dedicated_endpoint:
BASE_URL = f"https://{DEDICATED_ENDPOINT_DNS}/v1beta1/{ENDPOINT_RESOURCE_NAME}"
except NameError:
pass
6단계: Chat Completion 요청 전송
OpenAI의 Chat Completions API를 사용하여 이미지와 텍스트 프롬프트를 Vertex AI 엔드포인트로 전송합니다.
client = openai.OpenAI(base_url=BASE_URL, api_key=creds.token)
model_response = client.chat.completions.create(
model="",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": user_image}},
{"type": "text", "text": user_message},
],
}
],
temperature=temperature,
max_tokens=max_tokens,
)
print(model_response)
(선택사항) 7단계: 기존 엔드포인트에 다시 연결
이전에 만든 엔드포인트에 다시 연결하려면 엔드포인트 ID를 사용하세요. 이 단계는 새 엔드포인트를 만드는 대신 기존 엔드포인트를 재사용하려는 경우에 유용합니다.
endpoint_name = ""
aip_endpoint_name = (
f"projects/{PROJECT_ID}/locations/{REGION}/endpoints/{endpoint_name}"
)
endpoint = aiplatform.Endpoint(aip_endpoint_name)
이 설정을 사용하면 필요에 따라 새로 생성된 엔드포인트와 기존 엔드포인트 간에 유연하게 전환할 수 있으므로 테스트와 배포를 간소화할 수 있습니다.
삭제
지속적인 요금을 피하고 리소스를 확보하려면 배포된 모델, 엔드포인트, 이 실험에 사용된 스토리지 버킷(선택사항)을 삭제해야 합니다.
1단계: 엔드포인트 및 모델 삭제
다음 코드는 각 모델을 배포 취소하고 연결된 엔드포인트를 삭제합니다.
# Undeploy model and delete endpoint
for endpoint in endpoints.values():
endpoint.delete(force=True)
# Delete models
for model in models.values():
model.delete()
2단계: (선택사항) Cloud Storage 버킷 삭제
이 실험을 위해 특별히 Cloud Storage 버킷을 만든 경우 delete_bucket을 True로 설정하여 삭제할 수 있습니다. 버킷이 더 이상 필요하지 않은 경우 이 단계는 선택사항이지만 권장됩니다.
delete_bucket = False
if delete_bucket:
! gsutil -m rm -r $BUCKET_NAME
이 단계를 따르면 이 튜토리얼에서 사용된 모든 리소스가 정리되어 실험과 관련된 불필요한 비용이 절감됩니다.
일반적인 문제 디버깅
이 섹션에서는 Vertex AI에서 vLLM 모델을 배포하고 추론할 때 발생하는 일반적인 문제를 파악하고 해결하는 방법에 대한 안내를 제공합니다.
로그 확인
로그를 확인하여 배포 실패 또는 예기치 않은 동작의 근본 원인을 파악합니다.
- Vertex AI Prediction 콘솔로 이동: Google Cloud 콘솔에서 Vertex AI Prediction 콘솔로 이동합니다.
- 엔드포인트 선택: 문제가 발생한 엔드포인트를 클릭합니다. 상태 표시를 통해 배포가 실패했는지 확인할 수 있습니다.
- 로그 보기: 엔드포인트를 클릭한 후 로그 탭으로 이동하거나 로그 보기를 클릭합니다. 그러면 해당 엔드포인트 및 모델 배포와 관련된 로그가 표시되도록 필터링된 Cloud Logging으로 이동합니다. Cloud Logging 서비스를 통해 직접 로그에 액세스할 수도 있습니다.
- 로그 분석: 로그 항목에서 오류 메시지, 경고, 기타 관련 정보를 검토합니다. 타임스탬프를 확인하여 로그 항목을 특정 작업과 연계시킵니다. 리소스 제약조건(메모리 및 CPU), 인증 문제 또는 구성 오류와 관련된 문제를 찾습니다.
일반적인 문제 1: 배포 중 CUDA 메모리 부족(OOM)
CUDA 메모리 부족(OOM) 오류는 모델의 메모리 사용량이 사용 가능한 GPU 용량을 초과할 때 발생합니다.
텍스트 전용 모델의 경우 다음 엔진 인수를 사용했습니다.
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 256
멀티모달 모델의 경우 다음 엔진 인수를 사용했습니다.
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 12
텍스트 전용 모델의 경우와 같이 max_num_seqs = 256으로 멀티모달 모델을 배포하면 다음과 같은 오류가 발생할 수 있습니다.
[rank0]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 3.91 GiB. GPU 0 has a total capacity of 39.38 GiB of which 3.76 GiB is free. Including non-PyTorch memory, this process has 0 bytes memory in use. Of the allocated memory 34.94 GiB is allocated by PyTorch, and 175.15 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
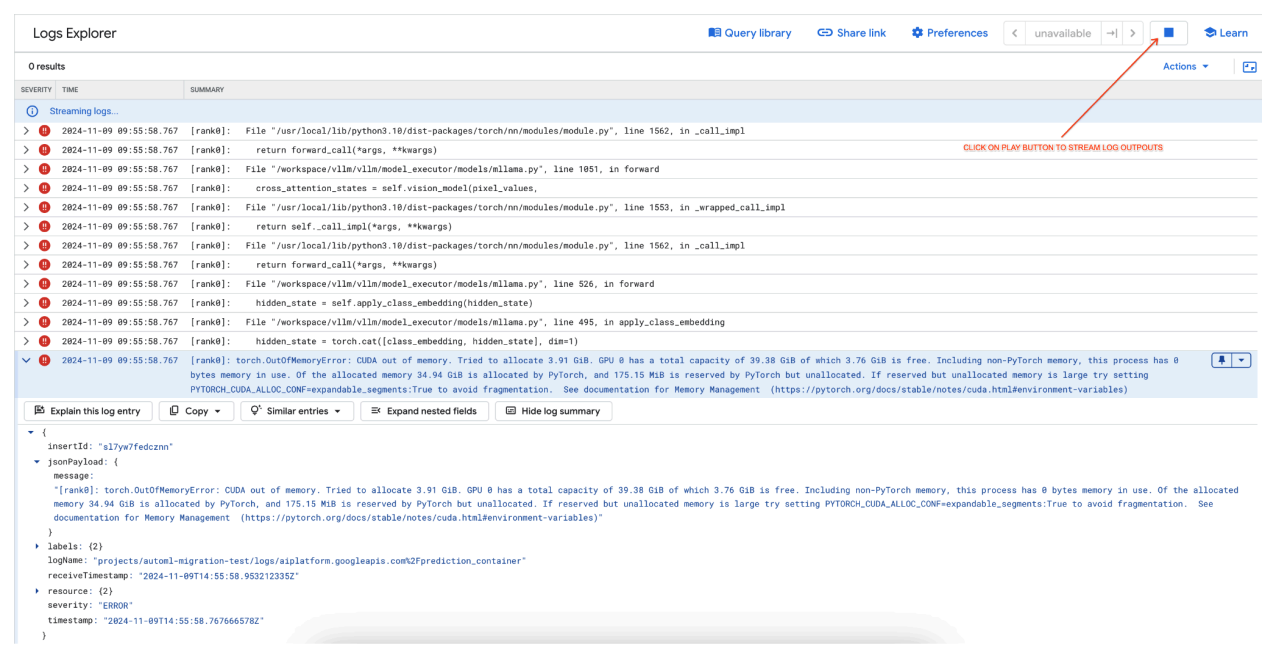 그림 7: 메모리 부족(OOM) GPU 오류 로그
그림 7: 메모리 부족(OOM) GPU 오류 로그
max_num_seqs 및 GPU 메모리 이해:
max_num_seqs파라미터는 모델이 처리할 수 있는 최대 동시 요청 수를 정의합니다.- 모델에서 처리하는 각 시퀀스는 GPU 메모리를 소비합니다. 총 메모리 사용량은 시퀀스당 메모리와
max_num_seqs의 곱에 비례합니다. - 텍스트 전용 모델(예: Meta-Llama-3.1-8B)은 일반적으로 텍스트와 이미지를 모두 처리하는 멀티모달 모델(예: Llama-3.2-11B-Vision-Instruct)보다 시퀀스당 메모리를 적게 사용합니다.
오류 로그를 검토(그림 8):
- GPU에 메모리를 할당하려고 하면 로그에
torch.OutOfMemoryError가 표시됩니다. - 이 오류는 모델의 메모리 사용량이 사용 가능한 GPU 용량을 초과할 때 발생합니다. NVIDIA L4 GPU는 24GB이며,
max_num_seqs파라미터를 멀티모달 모델에 너무 높게 설정하면 오버플로가 발생합니다. - 로그에는 메모리 관리를 개선하기 위해
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True를 설정할 것을 제안하지만, 여기서 가장 큰 문제는 메모리 사용량이 높다는 것입니다.
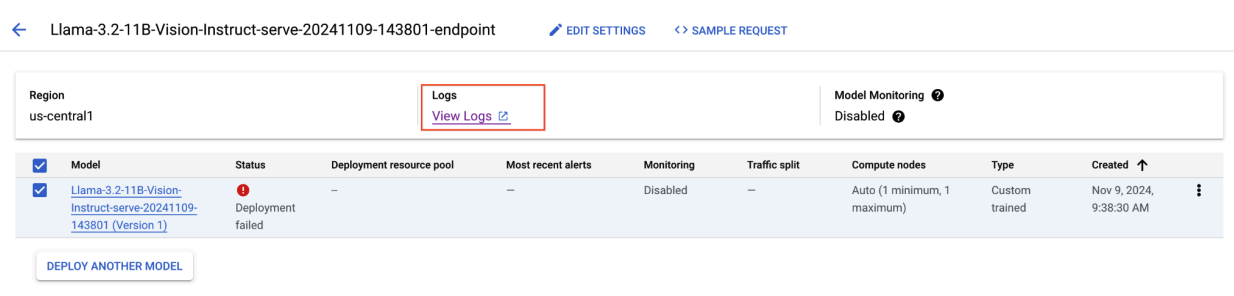 그림 8: Llama 3.2 배포 실패
그림 8: Llama 3.2 배포 실패
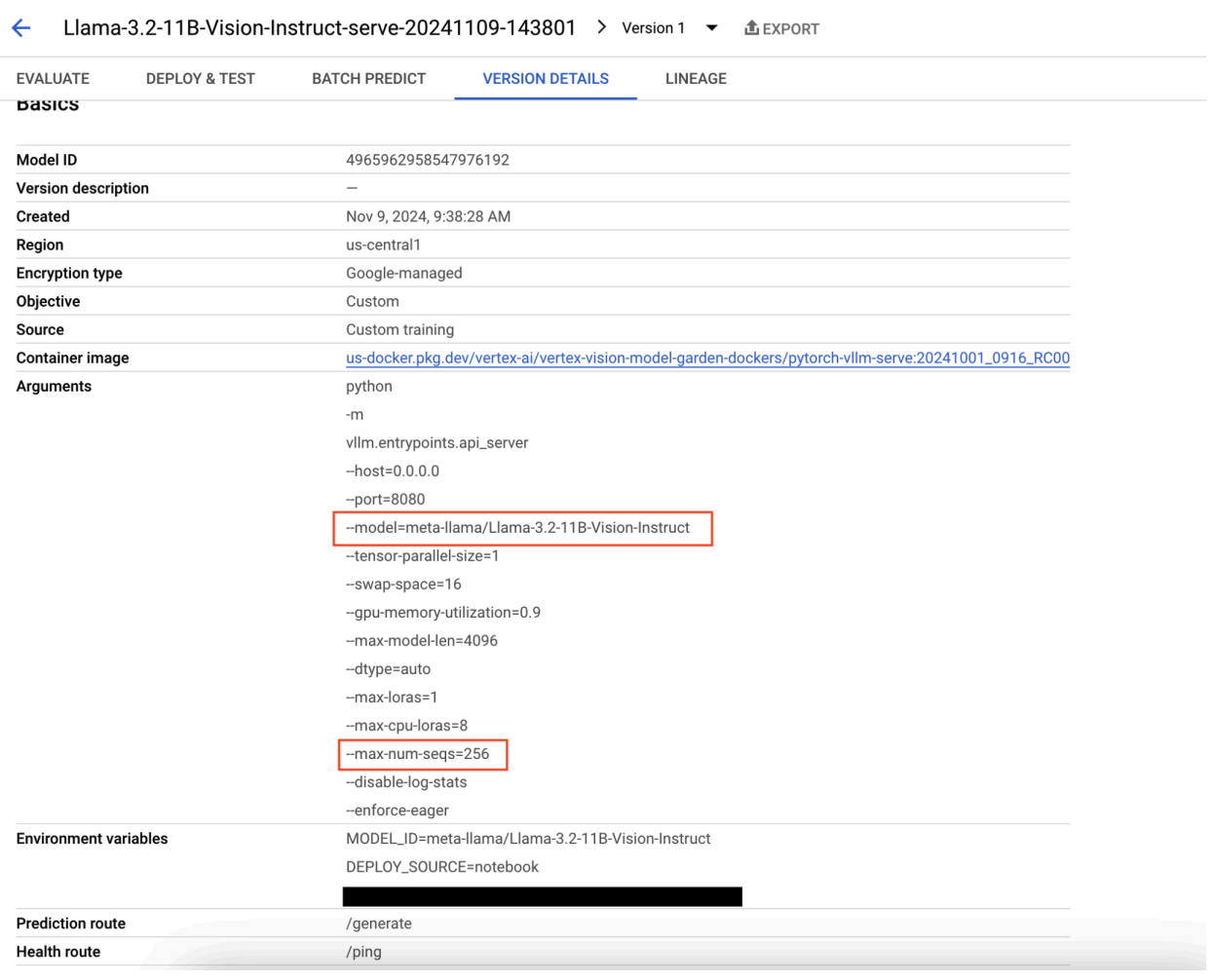 그림 9: 모델 버전 세부정보 패널
그림 9: 모델 버전 세부정보 패널
이 문제를 해결하려면 Vertex AI Prediction 콘솔로 이동하여 엔드포인트를 클릭합니다. 상태는 배포 실패를 나타냅니다. 클릭하여 로그를 봅니다. max-num-seqs = 256인지 확인합니다. 이 값은 Llama-3.2-11B-Vision-Instruct에 너무 큽니다. 더 적절한 값은 12입니다.
일반적인 문제 2: Hugging Face 토큰 필요
Hugging Face 토큰 오류는 모델이 제한되고 액세스하려면 적절한 사용자 인증 정보가 필요한 경우에 발생합니다.
다음 스크린샷은 Hugging Face에 호스팅된 Meta LLaMA-3.2-11B-Vision 모델에 액세스하는 것과 관련된 오류 메시지를 보여주는 Google Cloud 로그 탐색기의 로그 항목을 보여줍니다. 이 오류는 모델에 대한 액세스가 제한되어 계속 진행하려면 인증이 필요함을 나타냅니다. 메시지에는 'URL의 비공개 저장소에 액세스할 수 없습니다'라고 명시되어 있으며, 이는 모델이 제한되고 액세스하려면 적절한 사용자 인증 정보가 필요하다는 것을 나타냅니다. 이 로그 항목은 외부 저장소에서 제한된 리소스를 사용할 때 인증 문제를 해결하는 데 도움이 될 수 있습니다.
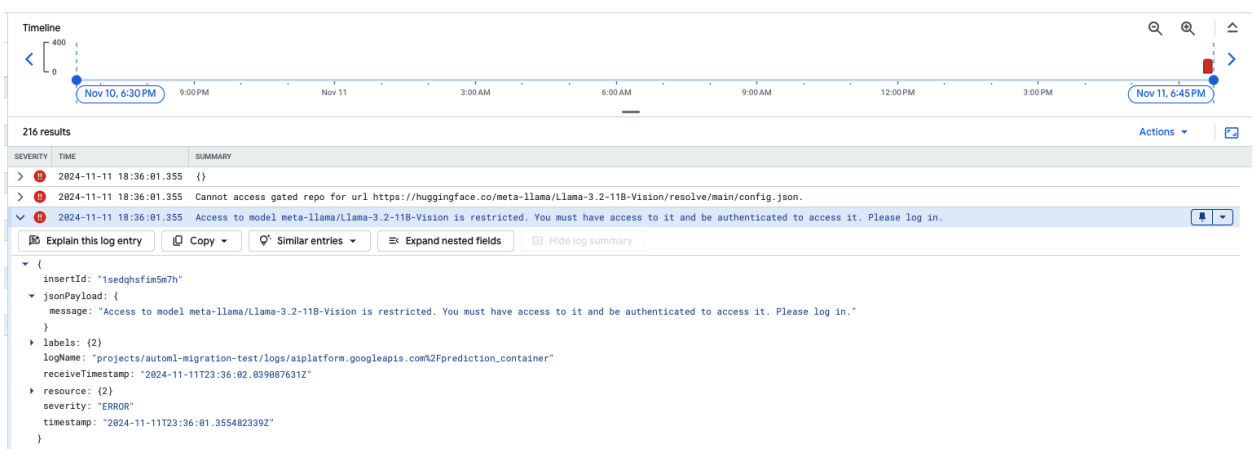 그림 10: Hugging Face 토큰 오류
그림 10: Hugging Face 토큰 오류
이 문제를 해결하려면 Hugging Face 액세스 토큰의 권한을 확인하세요. 최신 토큰을 복사하고 새 엔드포인트를 배포합니다.
일반적인 문제 3: 채팅 템플릿 필요
채팅 템플릿 오류는 기본 채팅 템플릿이 더 이상 허용되지 않을 때 발생하며, 토크나이저가 템플릿을 정의하지 않은 경우 커스텀 채팅 템플릿을 제공해야 합니다.
이 스크린샷은 Google Cloud의 로그 탐색기에 표시된 로그 항목으로, 트랜스포머 라이브러리 버전 4.44에 채팅 템플릿이 누락되어 ValueError가 발생한 사례를 보여줍니다. 이 오류 메시지는 기본 채팅 템플릿이 더 이상 허용되지 않으며 토크나이저에서 정의하지 않은 경우 커스텀 채팅 템플릿을 제공해야 함을 나타냅니다. 이 오류는 채팅 기반 애플리케이션을 배포할 때 문제를 디버깅하는 데 유용하며, 채팅 템플릿을 명시적으로 정의해야 하는 라이브러리의 최근 변경사항을 나타냅니다.
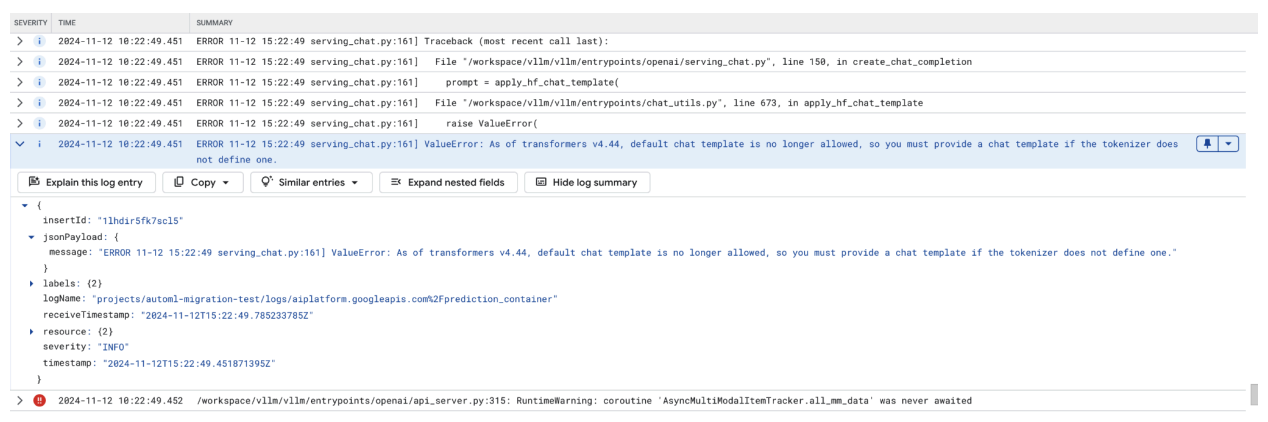 그림 11: 채팅 템플릿 필요
그림 11: 채팅 템플릿 필요
이 문제를 해결하려면 --chat-template 입력 인수를 사용하여 배포 중에 채팅 템플릿을 제공해야 합니다. 샘플 템플릿은 vLLM 예시 저장소에서 확인할 수 있습니다.
일반적인 문제 4: 모델 최대 시퀀스 길이
모델 최대 시퀀스 길이 오류는 모델의 최대 시퀀스 길이(4096)가 KV 캐시에 저장할 수 있는 최대 토큰 수(2256)보다 큰 경우에 발생합니다.
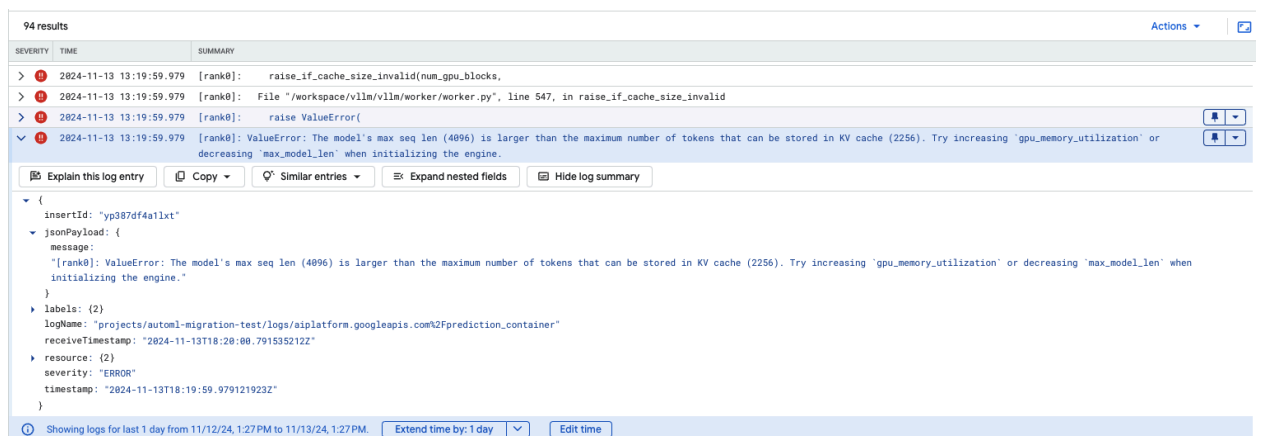 그림 12: 최대 시퀀스 길이가 너무 큼
그림 12: 최대 시퀀스 길이가 너무 큼
ValueError: 모델의 최대 시퀀스 길이(4096)가 KV 캐시에 저장할 수 있는 최대 토큰 수(2256)보다 큽니다. 엔진을 초기화할 때 gpu_memory_utilization을 늘리거나 max_model_len을 줄여 보세요.
이 문제를 해결하려면 max_model_len을 2256보다 작은 2048로 설정하세요. 이 문제를 해결하는 또 다른 방법은 더 많거나 더 큰 GPU를 사용하는 것입니다. GPU를 더 많이 사용하는 경우 tensor-parallel-size를 적절하게 설정해야 합니다.
Model Garden vLLM 컨테이너 출시 노트
기본 버전
표준 vLLM
출시일 |
아키텍처 |
vLLM 버전 |
컨테이너 URI |
|---|---|---|---|
| 2025년 7월 17일 | ARM |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250717_0916_arm_RC01 |
| 2025년 7월 10일 | x86 |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250710_0916_RC01 |
| 2025년 6월 20일 | x86 |
v0.9.1 이후 커밋 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250620_0916_RC01 |
| 2025년 6월 11일 | x86 |
v0.9.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250611_0916_RC01 |
| 2025년 6월 2일 | x86 |
v0.9.0 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250601_0916_RC01 |
| 2025년 5월 6일 | x86 |
v0.8.5.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250506_0916_RC01 |
| 2025년 4월 29일 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250429_0916_RC01, 20250430_0916_RC00_maas |
| 2025년 4월 17일 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250417_0916_RC01 |
| Apr 10, 2025 | x86 |
v0.8.3 이후 커밋 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250410_0917_RC01 |
| 2025년 4월 7일 | x86 |
v0.8.3 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250407_0917_RC01, 20250407_0917_RC0120250429_0916_RC00_maas |
| 2025년 4월 7일 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250404_0916_RC01 |
| 2025년 4월 5일 | x86 |
v0.8.2 이후 커밋 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250405_1205_RC01 |
| 2025년 5월 31일 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250401_0916_RC01 |
| 2025년 3월 26일 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250327_0916_RC01 |
| 2025년 3월 23일 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250324_0916_RC01 |
| 2025년 3월 21일 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250321_0916_RC01 |
| 2025년 3월 11일 | x86 |
v0.7.3 이후 커밋 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250312_0916_RC01 |
| 2025년 3월 3일 | x86 |
v0.7.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250304_0916_RC01 |
| 2025년 1월 14일 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250114_0916_RC00_maas |
| 2024년 12월 2일 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241202_0916_RC00_maas |
| 2024년 11월 12일 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241112_0916_RC00_maas |
| 2024년 10월 16일 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241016_0916_RC00_maas |
최적화된 vLLM
출시일 |
아키텍처 |
컨테이너 URI |
|---|---|---|
| Jan 21, 2025 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20250121_0835_RC00 |
| 2024년 10월 29일 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20241029_0835_RC00 |
추가 버전
VMG 표준 vLLM 컨테이너 출시의 전체 목록은 Artifact Registry 페이지에서 확인할 수 있습니다.
실험 상태의 vLLM-TPU 버전에는 <yyyymmdd_hhmm_tpu_experimental_RC00> 태그가 지정됩니다.