借助 Vertex AI 中的 Gemini API,您可以将文本、图片和视频等多模态输入内容作为提示的一部分发送给 Gemini 模型。本页介绍了设计多模态提示的最佳实践,以及在提示未按预期发挥作用时如何进行问题排查。如需了解提示设计方面的通用指导,请参阅我们推荐的提示设计策略,或参阅以下针对多模态的最佳实践列表。
提示设计基础知识
使用具体说明
清晰详细的提示可带来最佳效果。如果您考虑获得特定输出,请在提示中包含该要求,以提高获得正确输出的可能性。
即使提示对编写者来说似乎很清晰,但提示也可能不够明确。如需自定义模型行为,请考虑对您的提示的解释,并确保您提供的说明简短具体。
如果您在提示中添加了下方的机场面板图片,要求模型仅“描述此图片”可能会生成一般性说明。如果您需要模型从图片中解析时间和城市,请直接在提示中添加该请求。
| 提示 | 模型回答 |
|---|---|

描述此图片。 |
此图片显示了机场到达和出发信息面板。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
将下图中显示的机场面板中的时间和城市解析为列表。 |
|
添加示例
模型可以接受多个输入,并将这些输入用作示例来理解所需的输出。添加这些示例有助于模型识别模式,并将给定图片与回答之间的关系应用于新示例。这也称为少量样本学习。
在以下示例中,初始输出是一个完整的句子,其中还包含国家/地区(巴西)。如果首选输出结果仅为城市,而非国家/地区,那么向提示中添加少样本示例可以引导模型以该格式进行回答。
| 提示 | 模型回答 |
|---|---|

确定城市以及地标。 |
地标是巴西里约热内卢的基督救世主雕像。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
确定城市以及地标。 
|
城市:罗马,地标:斗兽场。 |

|
城市:北京,地标:紫禁城 |
|
|
城市:里约热内卢,地标:基督救世主雕像 |
将复杂任务分解为较小的任务
对于复杂的任务(例如需要视觉理解和推理的任务),请将任务拆分为更小、更直接的步骤,或者直接在提示中要求模型逐步思考。
| 提示 | 模型回答 |
|---|---|

我什么时候会将卫生纸用完? |
您只剩下 3 卷了。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
|
数学问题或其他类型的字词问题也可以分解为较小的任务。
| 提示 | 答案 |
|---|---|
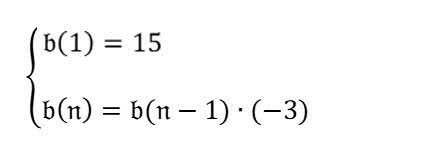
序列中的第 4 项是什么? |
-135 |
模型的回答不正确。尝试要求模型在回答提示之前,先解析问题。
| 提示 | 答案 |
|---|---|
|
首先解析图片中的公式。 然后,根据公式回答“序列中的第 4 项是什么?”。 |
点击可展开结果$$b(n) = b(n-1) * (-3)$$ $$b(1) = 15$$
因此,序列中的第 4 项是 -405。 |
如需进一步简化回答,您可以要求模型分步思考提示。
| 更新后的提示 | 改进后的回答 |
|---|---|
|
序列中的第 4 项是什么?请分步思考。 |
第一项是 15。 第二项是 b(1) * (-3) = 15 * (-3) = -45。 第三项是 b(2) * (-3) = -45 * (-3) = 135。 第四项是 b(3) * (-3) = 135 * (-3) = -405。 |
指定输出格式
如果需要特定格式,您可以指示模型使用该格式生成输出。
| 提示 | 模型回答 |
|---|---|
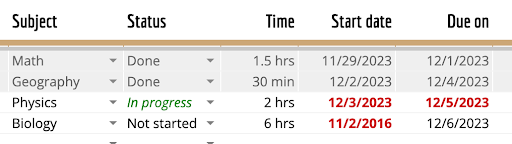
将此图片中的表格解析为 Markdown 格式 |
| Subject | Status | Time | Start date | Due on |
|-----------|-------------|---------|------------|------------|
| Math | Done | 1.5 hrs | 11/29/2023 | 12/1/2023 |
| Geography | Done | 30 min | 12/2/2023 | 12/4/2023 |
| Physics | In progress | 2 hrs | 12/3/2023 | 12/5/2023 |
| Biology | Not started | 6 hrs | 11/2/2016 | 12/6/2023 |
|
| 提示 | 模型回答 |
|---|---|

请提供以下所有属性的列表: 配料、菜系类型、是否为素菜,采用 JSON 格式 |
|
排查多模态提示问题
问题排查可能涉及改进提示的语言、引导提示的重点或调优参数。这些不同的方法有助于改进结果,尤其是在确定问题的根本原因之后。
聚焦于图片的相关部分
为了改进回答,请指明图片的哪些部分与提示最相关。
| 提示 | 模型回答 |
|---|---|

这些尿片可供一个婴儿使用多少天? |
这些尿片可以使用 198 天。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
这些尿片可以使用多长时间? 使用包装盒上显示的体重确定孩子的年龄,并使用包装盒中的尿片总数。 用总数除以孩子每天要换的尿片数量。 |
包装盒中有 198 张尿片。包装盒上注明尿片适用于体重 22-37 磅的孩子。 此体重范围内的普通孩子可能在 1 至 2 岁之间。 2 岁的孩子通常每天要换 6 片尿片,因此尿片的使用寿命约为 33 天 (198/6)。 |
根据输入内容调整模型回答
要求模型在执行提示中的任务之前描述图片。
| 提示 | 模型回答 |
|---|---|



这些图片有什么共同之处? |
全部四张图片都是横向摄影的示例。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
首先,详细描述每张图片中的内容。这些图片有什么共同之处? |
第一张图片显示一个人正在收拾手提包。第二张图片显示购物中心内空无一人的走廊。第三张图片显示一卷卫生纸。第四张图片显示黑暗汹涌的大海。 这些图片之间的共同之处在于,它们都是临界空间的示例。临界空间是指处于两个其他场所或情景之间的场所或情景。它们通常以一种不确定或模糊的感觉为特征。 第一张图片显示处于居家与旅行之间的人。第二张图片显示两家商店之间的走廊。第三张图片是卫生纸,可以代表浴室。而浴室是私人领域与公共领域之间的过渡空间。它是一个让我们为进入或离开外部世界做好准备的场所。 第四张图片显示介于平静与风暴之间的大海。 临界空间可能既令人兴奋,又令人不安。它们既可以作为崭新开始的场所,也可以作为结束的场所。它们可以是反思的场所,也可以是行动的场所。 |
您可以明确要求模型参考图片中的内容。
| 更新后的提示 | 改进后的回答 |
|---|---|
|
这些图片有什么共同之处?请在回答中参考图片的内容。 |
所有图片都与旅行相关。第一张图片显示一个人正在收拾手提包,第二张图片显示购物中心空无一人的走廊,第三张图片显示一叠卫生纸,第四张图片显示黑暗汹涌的大海。 这些图片都与旅行相关,因为它们都是人们在旅行时所需要或使用的事物。第一张图片显示一个人正在收拾手提包,这是人们在旅行时要做的事情。第二张图片显示购物中心内空无一人的走廊,人们经常来到这个场所购买旅行用品。第三张图片显示一叠卫生纸,这是人们在旅行时经常使用的物品。第四张图片显示黑暗汹涌的大海,这是人们在旅行时经常遇到的景象。 |
同样的提示适用于创意输出。明确要求模型包含图片中的各个方面;这可以改进输出。
| 提示 | 模型回答 |
|---|---|

您能为我写一首关于此图片的诗歌吗? |
Little bunny, so soft and brown,
Hopping through the field, up and down.
Your ears so long, your tail so small,
You're the cutest creature of them all.You nibble on the grass, so green and sweet,
And hop away when you see me.
But I'll always be your friend,
Little bunny, until the very end. |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
您能为我写一首关于此图片的兼具描述性和戏剧性的诗歌,并在其中包含地点吗? |
Little bunny on the green,
Ears so long, so keen.
What do you see out there,
In the distance, where you stare?Is it the ocean blue,
Sparkling in the sun's hue?
Or the waves that crash and roar,
A rhythm that you adore?Little bunny, tell me true,
What captures your attention so?
Is it the salty breeze,
Or the seagulls' cries that please?Perhaps it's the vastness of it all,
A world so big and small.
A place where dreams can roam,
And adventures can be sown.Little bunny, I wonder what you dream,
As you sit on the grass, so serene.
Do you yearn to explore the deep,
Or stay on land, where you can leap?Whatever it may be, little bunny,
Keep that spark of wonder burning brightly.
For in your dreams and aspirations,
Lies a world waiting for your creation. |
确定提示失败的原因
提示失败可能是因为模型根本不理解图片,也可能是因为模型随后没有执行正确的推理步骤。如需区分这些原因,请要求模型描述图片中的内容。
在此示例中,如果在与茶搭配时,模型以似乎令人惊讶的零食(例如爆米花)作为回答,请先确定模型是否识别出图片中包含茶。
| 提示 | 用于问题排查的提示 |
|---|---|

我在 1 分钟内能拿出什么零食来与此图片中的内容搭配食用? |
描述此图片中的内容。 |
让模型解释其推理过程有助于缩小推理失败的部分(如果有)。
| 提示 | 用于问题排查的提示 |
|---|---|
|
我在 1 分钟内能拿出什么零食来与此图片中的内容搭配食用? |
我在 1 分钟内能拿出什么零食来与此图片中的内容搭配食用?请说明原因。 |
调优采样参数
在每个请求中,您不仅向模型发送多模态提示,还会发送一组采样参数。对于不同的参数值,模型会生成不同的结果。因此请尝试不同的参数,以获得任务的最佳值。最常调整的参数如下:
温度
温度用于在回答生成期间进行采样,这会在应用 top-P 和 top-K 时进行。温度可以控制 token 选择的随机性。较低的温度有利于需要更具确定性、更少开放性或创造性回答的提示,而较高的温度可以带来更具多样性或创造性的结果。温度为 0 表示确定性,即最有可能选择概率最高的回答。
对于大多数应用场景,不妨先试着将温度设为 0.4。如果您需要更具创造性的结果,请提高温度。如果您观察到明显的幻觉,请降低温度。
Top-P
Top-P 可更改模型选择输出词元的方式。系统会按照概率从最高到最低的顺序选择 token,直到所选 token 的概率总和等于 top-P 值。例如,如果词元 A、B 和 C 的概率分别为 0.6、0.3 和 0.1,并且 Top-P 的值为 0.9,则模型将选择 A 或 B 作为下一个词元(通过温度确定),并会排除 C 作为候选词元。
指定较低的值可获得随机程度较低的响应,指定较高的值可获得随机程度较高的响应。top-P 的默认值为 1.0。
后续步骤
- 使用 Vertex AI Studio 或 Vertex AI API 尝试学习快速入门教程。
- 如需开始使用 Vertex AI 中的 Gemini API,请参阅 Vertex AI 中的 Gemini API 快速入门。