Die Funktion zur Codeausführung der Gemini API ermöglicht es dem Modell, Python-Code zu generieren und auszuführen und iterativ aus den Ergebnissen zu lernen, bis das Modell eine endgültige Ausgabe erstellt hat. Sie können diese Codeausführungsfunktion verwenden, um Anwendungen zu erstellen, die die Vorteile codebasierter Schlussfolgerungen nutzen und Textausgaben erzeugen. Die Codeausführung können Sie beispielsweise in einer Anwendung verwenden, die Gleichungen löst oder Text verarbeitet.
Die Gemini API stellt die Codeausführung ähnlich wie den Funktionsaufruf als Tool zur Verfügung. Nachdem Sie die Codeausführung als Tool hinzugefügt haben, entscheidet das Modell, wann es sie verwendet.
Die Codeausführungsumgebung umfasst die folgenden Bibliotheken. Sie können keine eigenen Bibliotheken installieren.
- Altair
- Schach
- Cv2
- Matplotlib
- Mpmath
- NumPy
- Pandas
- Pdfminer
- Reportlab
- Seaborn
- Sklearn
- Statsmodels
- Striprtf
- SymPy
- Tabulate
Unterstützte Modelle
Die folgenden Modelle unterstützen die Codeausführung:
- Gemini 2.5 Flash (Vorschau)
- Gemini 2.5 Flash-Lite (Vorschau)
- Gemini 2.5 Flash-Lite
- Gemini 2.0 Flash mit Live API (Vorschau)
- Gemini 2.5 Pro
- Gemini 2.5 Flash
- Gemini 2.0 Flash
Erste Schritte mit der Codeausführung
In diesem Abschnitt wird davon ausgegangen, dass Sie die Einrichtungs- und Konfigurationsschritte in der Kurzanleitung für die Gemini API ausgeführt haben.
Codeausführung für das Modell aktivieren
So aktivieren Sie die grundlegende Codeausführung:
Python
Installieren
pip install --upgrade google-genai
Weitere Informationen finden Sie in der SDK-Referenzdokumentation.
Umgebungsvariablen für die Verwendung des Gen AI SDK mit Vertex AI festlegen:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Informationen zum Installieren oder Aktualisieren von Go
Weitere Informationen finden Sie in der SDK-Referenzdokumentation.
Umgebungsvariablen für die Verwendung des Gen AI SDK mit Vertex AI festlegen:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
Installieren
npm install @google/genai
Weitere Informationen finden Sie in der SDK-Referenzdokumentation.
Umgebungsvariablen für die Verwendung des Gen AI SDK mit Vertex AI festlegen:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Informationen zum Installieren oder Aktualisieren von Java
Weitere Informationen finden Sie in der SDK-Referenzdokumentation.
Umgebungsvariablen für die Verwendung des Gen AI SDK mit Vertex AI festlegen:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
GENERATE_RESPONSE_METHOD: Der Typ der Antwort, die das Modell generieren soll. Wählen Sie eine Methode aus, mit der generiert wird, wie die Antwort des Modells zurückgegeben werden soll:streamGenerateContent: Die Antwort wird während der Generierung gestreamt, um die Wahrnehmung der Latenz für menschliche Zielgruppen zu reduzieren.generateContent: Die Antwort wird zurückgegeben, nachdem sie vollständig generiert wurde.
LOCATION: Die Region, in der die Anfrage verarbeitet werden soll. Folgende Optionen sind verfügbar:Klicken Sie, um eine unvollständige Liste der verfügbaren Regionen einzublenden
us-central1us-west4northamerica-northeast1us-east4us-west1asia-northeast3asia-southeast1asia-northeast1
PROJECT_ID: Ihre Projekt-ID.MODEL_ID: Die Modell-ID des Modells, das Sie verwenden möchten.ROLE: Die Rolle in einer Unterhaltung, die mit dem Inhalt verknüpft ist. Die Angabe einer Rolle ist auch bei Anwendungsfällen mit nur einem Schritt erforderlich. Unter anderem sind folgende Werte zulässig:USER: Gibt Inhalte an, die von Ihnen gesendet werdenMODEL: Gibt die Antwort des Modells an.
TEXT
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
curl
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json.
Führen Sie folgenden Befehl im Terminal aus, um diese Datei im aktuellen Verzeichnis zu erstellen oder zu überschreiben:
cat > request.json << 'EOF'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
EOFFühren Sie dann folgenden Befehl aus, um Ihre REST-Anfrage zu senden:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD"
PowerShell
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json.
Führen Sie folgenden Befehl im Terminal aus, um diese Datei im aktuellen Verzeichnis zu erstellen oder zu überschreiben:
@'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
'@ | Out-File -FilePath request.json -Encoding utf8Führen Sie dann folgenden Befehl aus, um Ihre REST-Anfrage zu senden:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD" | Select-Object -Expand Content
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
Codeausführung in Chats verwenden
Sie können die Codeausführung auch im Rahmen eines Chats verwenden.
REST
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://aiplatform.googleapis.com/v1/projects/test-project/locations/global/publishers/google/models/gemini-2.0-flash-001:generateContent -d \
$'{
"tools": [{'code_execution': {}}],
"contents": [
{
"role": "user",
"parts": {
"text": "Can you print \"Hello world!\"?"
}
},
{
"role": "model",
"parts": [
{
"text": ""
},
{
"executable_code": {
"language": "PYTHON",
"code": "\nprint(\"hello world!\")\n"
}
},
{
"code_execution_result": {
"outcome": "OUTCOME_OK",
"output": "hello world!\n"
}
},
{
"text": "I have printed \"hello world!\" using the provided python code block. \n"
}
],
},
{
"role": "user",
"parts": {
"text": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50."
}
}
]
}'
Codeausführung im Vergleich zu Funktionsaufrufen
Codeausführung und Funktionsaufrufe sind ähnliche Funktionen:
- Durch die Codeausführung kann das Modell Code im API-Backend in einer festen, isolierten Umgebung ausführen.
- Mit dem Funktionsaufruf können Sie die vom Modell angeforderten Funktionen in einer beliebigen Umgebung ausführen.
Im Allgemeinen sollten Sie die Codeausführung bevorzugen, wenn sie Ihren Anwendungsfall abdecken kann. Die Codeausführung ist einfacher zu verwenden (Sie müssen sie nur aktivieren) und wird in einer einzigen GenerateContent-Anfrage aufgelöst. Für Funktionsaufrufe ist eine zusätzliche GenerateContent-Anfrage erforderlich, um die Ausgabe jedes Funktionsaufrufs zurückzusenden.
In den meisten Fällen sollten Sie Funktionsaufrufe verwenden, wenn Sie eigene Funktionen haben, die Sie lokal ausführen möchten. Die Codeausführung ist die richtige Wahl, wenn die API Python-Code für Sie schreiben und ausführen und das Ergebnis zurückgeben soll.
Abrechnung
Für die Aktivierung der Codeausführung über die Gemini API fallen keine zusätzlichen Kosten an. Die Abrechnung erfolgt zum aktuellen Preis für Eingabe- und Ausgabetokens, je nachdem, welches Gemini-Modell Sie verwenden.
Weitere Informationen zur Abrechnung der Codeausführung:
- Die Abrechnung erfolgt nur einmal für die Eingabetokens, die Sie an das Modell übergeben, und für die Zwischeneingabetokens, die vom Tool zur Codeausführung generiert werden.
- Die Abrechnung erfolgt für die endgültigen Ausgabetokens, die in der API-Antwort an Sie zurückgegeben werden.
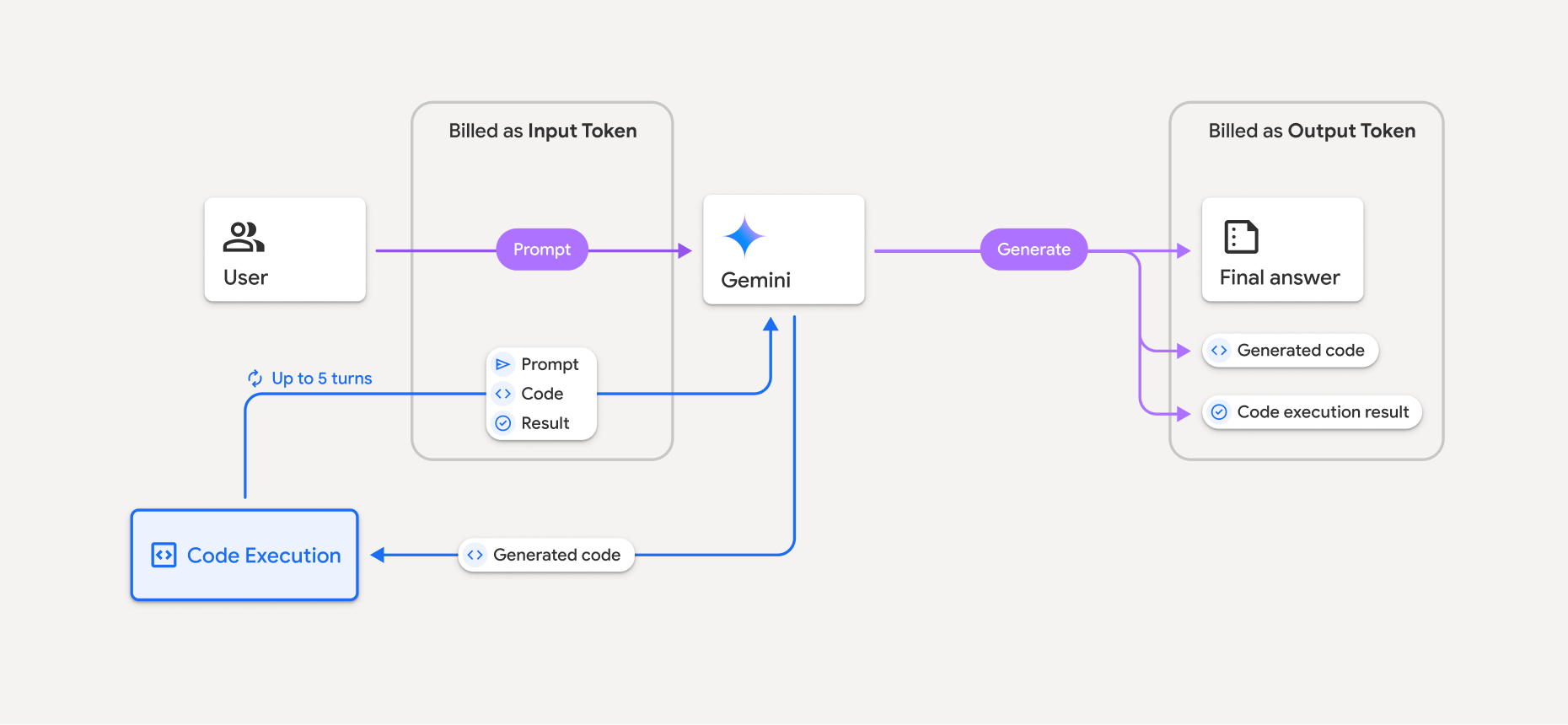
- Die Abrechnung erfolgt zum aktuellen Preis für Eingabe- und Ausgabetokens, je nachdem, welches Gemini-Modell Sie verwenden.
- Wenn Gemini die Codeausführung zum Generieren Ihrer Antwort verwendet, werden der ursprüngliche Prompt, der generierte Code und das Ergebnis des ausgeführten Codes als Zwischentokens gekennzeichnet und als Eingabetokens abgerechnet.
- Gemini generiert dann eine Zusammenfassung und gibt den generierten Code, das Ergebnis des ausgeführten Codes und die endgültige Zusammenfassung zurück. Diese werden als Ausgabe-Tokens abgerechnet.
- Die Gemini API enthält eine Zwischenanzahl von Tokens in der API-Antwort, damit Sie zusätzliche Eingabetokens im Blick behalten können, die über die in Ihrem ursprünglichen Prompt übergebenen Tokens hinausgehen.
Generierter Code kann sowohl Text als auch multimodale Ausgaben wie Bilder enthalten.
Beschränkungen
- Das Modell kann nur Code generieren und ausführen. Andere Artefakte wie Mediendateien können nicht zurückgegeben werden.
- Das Tool zur Codeausführung unterstützt keine Datei-URIs als Eingabe/Ausgabe. Das Tool zur Codeausführung unterstützt jedoch Dateieingaben und Grafikausgaben als Inline-Bytes. Mit diesen Ein- und Ausgabefunktionen können Sie CSV- und Textdateien hochladen, Fragen zu den Dateien stellen und Matplotlib-Diagramme als Teil des Codeausführungsergebnisses generieren lassen.
Die unterstützten MIME-Typen für Inline-Bytes sind
.cpp,.csv,.java,.jpeg,.js,.png,.py,.tsund.xml. - Die Codeausführung kann maximal 30 Sekunden dauern, bevor eine Zeitüberschreitung auftritt.
- In einigen Fällen kann die Aktivierung der Codeausführung zu Regressionen in anderen Bereichen der Modellausgabe führen, z. B. beim Schreiben einer Geschichte.