La función de ejecución de código de la API de Gemini permite que el modelo genere y ejecute código Python, así como que aprenda de forma iterativa de los resultados hasta llegar a un resultado final. Puedes usar esta función de ejecución de código para crear aplicaciones que se beneficien del razonamiento basado en código y que generen texto. Por ejemplo, puedes usar la ejecución de código en una aplicación que resuelva ecuaciones o procese texto.
La API de Gemini ofrece la ejecución de código como herramienta, de forma similar a la llamada a funciones. Una vez que hayas añadido la ejecución de código como herramienta, el modelo decidirá cuándo usarla.
El entorno de ejecución de código incluye las siguientes bibliotecas. No puedes instalar tus propias bibliotecas.
- Altair
- Ajedrez
- Cv2
- Matplotlib
- Mpmath
- NumPy
- Pandas
- Pdfminer
- Reportlab
- Seaborn
- Sklearn
- Statsmodels
- Striprtf
- SymPy
- Tabular
Modelos admitidos
Los siguientes modelos admiten la ejecución de código:
- Gemini 2.5 Flash (versión preliminar)
- Gemini 2.5 Flash-Lite (versión preliminar)
- Gemini 2.5 Flash-Lite
- Gemini 2.0 Flash con la API Live (versión preliminar)
- Gemini 2.5 Pro
- Gemini 2.5 Flash
- Gemini 2.0 Flash
Empezar a usar la ejecución de código
En esta sección se presupone que has completado los pasos de configuración que se indican en la guía de inicio rápido de la API de Gemini.
Habilitar la ejecución de código en el modelo
Puedes habilitar la ejecución de código básica como se muestra aquí:
Python
Instalar
pip install --upgrade google-genai
Para obtener más información, consulta la documentación de referencia del SDK.
Define variables de entorno para usar el SDK de IA generativa con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Consulta cómo instalar o actualizar Go.
Para obtener más información, consulta la documentación de referencia del SDK.
Define variables de entorno para usar el SDK de IA generativa con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
Instalar
npm install @google/genai
Para obtener más información, consulta la documentación de referencia del SDK.
Define variables de entorno para usar el SDK de IA generativa con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Consulta cómo instalar o actualizar Java.
Para obtener más información, consulta la documentación de referencia del SDK.
Define variables de entorno para usar el SDK de IA generativa con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
GENERATE_RESPONSE_METHOD: el tipo de respuesta que quieres que genere el modelo. Elige un método que genere la forma en que quieres que se devuelva la respuesta del modelo:streamGenerateContent: la respuesta se transmite en tiempo real a medida que se genera para reducir la percepción de latencia de los usuarios.generateContent: La respuesta se devuelve una vez que se ha generado por completo.
LOCATION: la región en la que se procesará la solicitud. Entre las opciones disponibles se incluyen las siguientes:Haz clic para ver una lista parcial de las regiones disponibles
us-central1us-west4northamerica-northeast1us-east4us-west1asia-northeast3asia-southeast1asia-northeast1
PROJECT_ID: tu ID de proyecto.MODEL_ID: el ID del modelo que quieres usar.ROLE: el rol en una conversación asociado al contenido. Es obligatorio especificar un rol incluso en los casos prácticos de una sola interacción. Entre los valores aceptados se incluyen los siguientes:USER: especifica el contenido que has enviado.MODEL: especifica la respuesta del modelo.
TEXT
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json.
Ejecuta el siguiente comando en el terminal para crear o sobrescribir este archivo en el directorio actual:
cat > request.json << 'EOF'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
EOFA continuación, ejecuta el siguiente comando para enviar tu solicitud REST:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json.
Ejecuta el siguiente comando en el terminal para crear o sobrescribir este archivo en el directorio actual:
@'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
'@ | Out-File -FilePath request.json -Encoding utf8A continuación, ejecuta el siguiente comando para enviar tu solicitud REST:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD" | Select-Object -Expand Content
Deberías recibir una respuesta JSON similar a la siguiente.
Usar la ejecución de código en el chat
También puedes usar la ejecución de código como parte de una conversación.
REST
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://aiplatform.googleapis.com/v1/projects/test-project/locations/global/publishers/google/models/gemini-2.0-flash-001:generateContent -d \
$'{
"tools": [{'code_execution': {}}],
"contents": [
{
"role": "user",
"parts": {
"text": "Can you print \"Hello world!\"?"
}
},
{
"role": "model",
"parts": [
{
"text": ""
},
{
"executable_code": {
"language": "PYTHON",
"code": "\nprint(\"hello world!\")\n"
}
},
{
"code_execution_result": {
"outcome": "OUTCOME_OK",
"output": "hello world!\n"
}
},
{
"text": "I have printed \"hello world!\" using the provided python code block. \n"
}
],
},
{
"role": "user",
"parts": {
"text": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50."
}
}
]
}'
Ejecución de código frente a llamadas de función
La ejecución de código y la llamada a funciones son funciones similares:
- La ejecución de código permite que el modelo ejecute código en el backend de la API en un entorno fijo y aislado.
- La llamada a funciones te permite ejecutar las funciones que solicita el modelo en el entorno que quieras.
En general, deberías usar la ejecución de código si puede gestionar tu caso práctico. La ejecución de código es más sencilla de usar (solo tienes que habilitarla) y se resuelve en una sola solicitud GenerateContent. La llamada a funciones requiere una solicitud GenerateContent adicional para devolver la salida de cada llamada a función.
En la mayoría de los casos, deberías usar la llamada a funciones si tienes tus propias funciones que quieres ejecutar localmente, y deberías usar la ejecución de código si quieres que la API escriba y ejecute código Python por ti y devuelva el resultado.
Facturación
No se cobra ningún cargo adicional por habilitar la ejecución de código desde la API de Gemini. Se te cobrará la tarifa actual de los tokens de entrada y salida en función del modelo de Gemini que estés usando.
A continuación, te indicamos algunos aspectos que debes tener en cuenta sobre la facturación de la ejecución de código:
- Solo se te cobra una vez por los tokens de entrada que envías al modelo y por los tokens de entrada intermedios que usa la herramienta de ejecución de código.
- Se te facturan los tokens de salida finales que se te devuelven en la respuesta de la API.
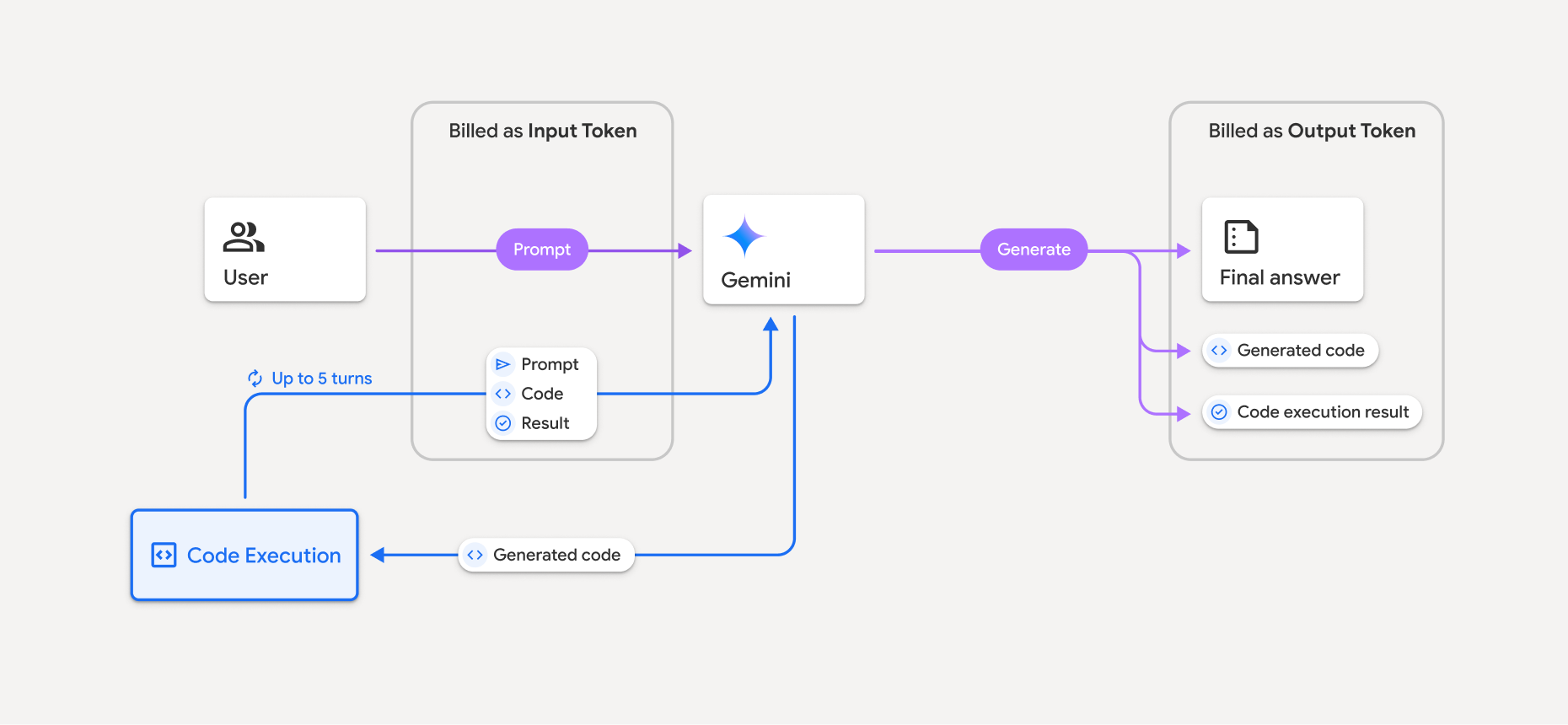
- Se te cobrará la tarifa actual de los tokens de entrada y salida en función del modelo de Gemini que utilices.
- Si Gemini usa la ejecución de código al generar tu respuesta, la petición original, el código generado y el resultado del código ejecutado se etiquetan como tokens intermedios y se facturan como tokens de entrada.
- A continuación, Gemini genera un resumen y devuelve el código generado, el resultado del código ejecutado y el resumen final. Se facturan como tokens de salida.
- La API de Gemini incluye un recuento de tokens intermedio en la respuesta de la API, por lo que puedes hacer un seguimiento de los tokens de entrada adicionales que se hayan añadido a tu petición inicial.
El código generado puede incluir texto y resultados multimodales, como imágenes.
Limitaciones
- El modelo solo puede generar y ejecutar código. No puede devolver otros artefactos, como archivos multimedia.
- La herramienta de ejecución de código no admite URIs de archivos como entrada o salida. Sin embargo, la herramienta de ejecución de código admite la entrada de archivos y la salida de gráficos como bytes insertados. Al usar estas funciones de entrada y salida, puedes subir archivos CSV y de texto, hacer preguntas sobre los archivos y generar gráficos de Matplotlib como parte del resultado de la ejecución del código.
Los tipos MIME admitidos para los bytes insertados son
.cpp,.csv,.java,.jpeg,.js,.png,.py,.tsy.xml. - La ejecución del código puede durar un máximo de 30 segundos antes de agotarse el tiempo.
- En algunos casos, habilitar la ejecución de código puede provocar regresiones en otras áreas de la salida del modelo (por ejemplo, al escribir una historia).