Halaman ini menjelaskan cara melihat dan menafsirkan hasil evaluasi model setelah menjalankan evaluasi model.
Melihat hasil evaluasi
Setelah Anda menentukan tugas evaluasi, jalankan tugas untuk mendapatkan hasil evaluasi, sebagai berikut:
from vertexai.evaluation import EvalTask
eval_result = EvalTask(
dataset=DATASET,
metrics=[METRIC_1, METRIC_2, METRIC_3],
experiment=EXPERIMENT_NAME,
).evaluate(
model=MODEL,
experiment_run=EXPERIMENT_RUN_NAME,
)
Class EvalResult mewakili hasil eksekusi evaluasi dengan atribut berikut:
summary_metrics: Kamus metrik evaluasi gabungan untuk menjalankan evaluasi.metrics_table: Tabelpandas.DataFrameyang berisi input set data evaluasi, respons, penjelasan, dan hasil metrik per baris.metadata: nama eksperimen dan nama operasi eksperimen untuk operasi evaluasi.
Class EvalResult ditentukan sebagai berikut:
@dataclasses.dataclass
class EvalResult:
"""Evaluation result.
Attributes:
summary_metrics: A dictionary of aggregated evaluation metrics for an evaluation run.
metrics_table: A pandas.DataFrame table containing evaluation dataset inputs,
responses, explanations, and metric results per row.
metadata: the experiment name and experiment run name for the evaluation run.
"""
summary_metrics: Dict[str, float]
metrics_table: Optional["pd.DataFrame"] = None
metadata: Optional[Dict[str, str]] = None
Dengan menggunakan fungsi helper, hasil evaluasi dapat ditampilkan di notebook Colab sebagai berikut:

Memvisualisasikan hasil evaluasi
Anda dapat memetakan metrik ringkasan dalam diagram radar atau batang untuk visualisasi dan perbandingan antara hasil dari berbagai proses evaluasi. Visualisasi ini dapat membantu mengevaluasi berbagai model dan template perintah.
Dalam contoh berikut, kami memvisualisasikan empat metrik (koherensi, kelancaran, kepatuhan terhadap petunjuk, dan kualitas teks secara keseluruhan) untuk respons yang dibuat menggunakan empat template perintah yang berbeda. Dari radar dan plot batang, kita dapat menyimpulkan bahwa template perintah #2 secara konsisten mengungguli template lainnya di keempat metrik. Hal ini terutama terlihat pada skornya yang jauh lebih tinggi untuk kepatuhan terhadap perintah dan kualitas teks. Berdasarkan analisis ini, template perintah #2 tampaknya menjadi pilihan yang paling efektif di antara empat opsi.
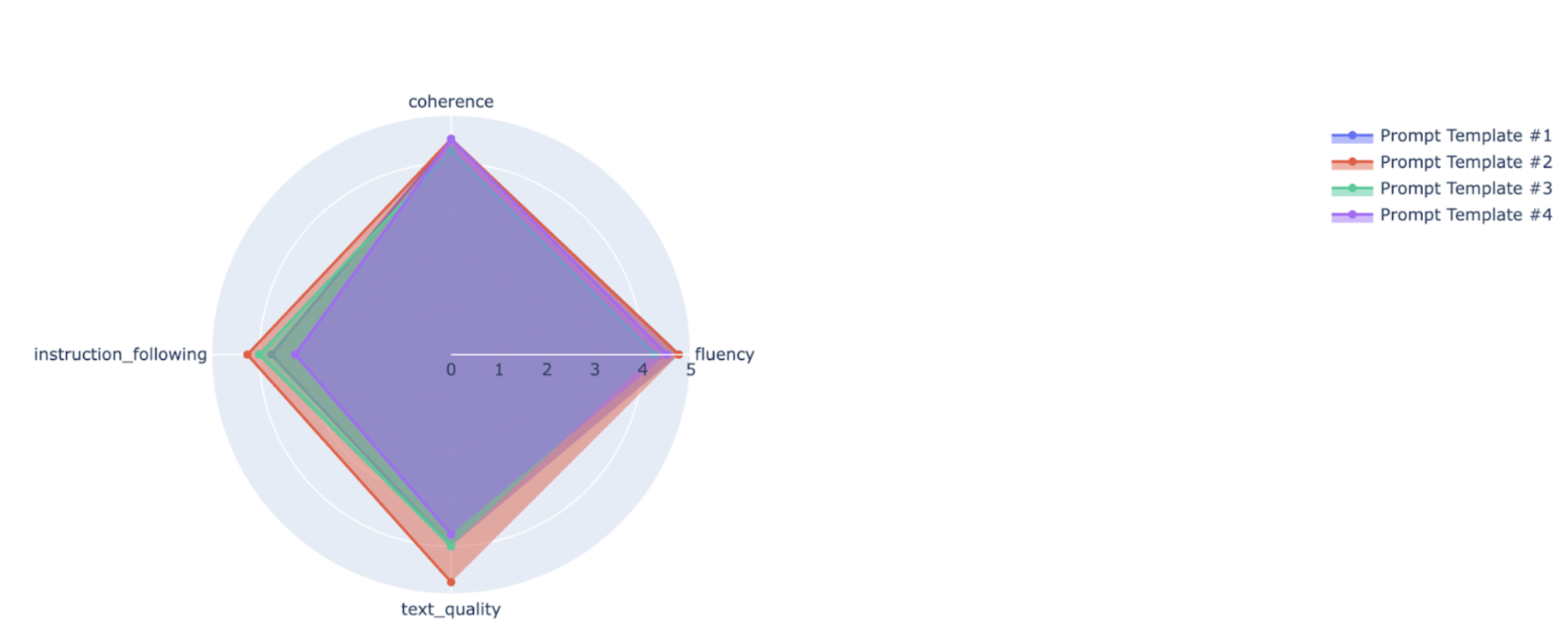
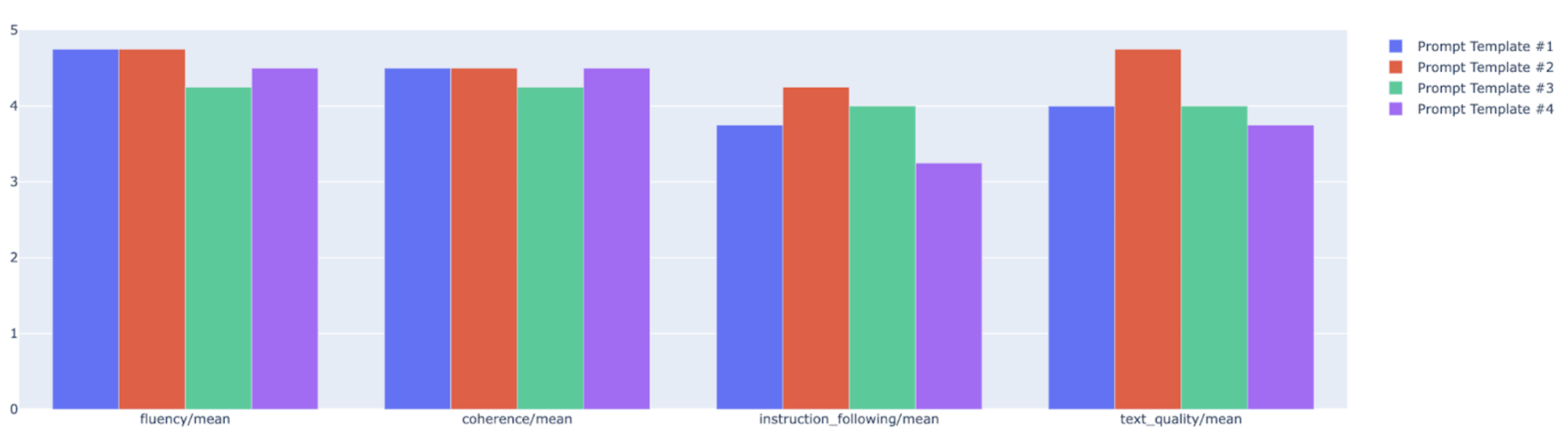
Memahami hasil metrik
Tabel berikut mencantumkan berbagai komponen hasil tingkat instance dan gabungan yang disertakan dalam metrics_table dan summary_metrics masing-masing untuk PointwiseMetric, PairwiseMetric, dan metrik berbasis komputasi:
PointwiseMetric
Hasil tingkat instance
| Kolom | Deskripsi |
|---|---|
| respons | Respons yang dihasilkan untuk perintah oleh model. |
| skor | Rating yang diberikan untuk respons sesuai dengan kriteria dan rubrik penilaian. Skor dapat berupa biner (0 dan 1), skala Likert (1 hingga 5, atau -2 hingga 2), atau float (0,0 hingga 1,0). |
| penjelasan | Alasan model hakim memberikan skor. Kami menggunakan penalaran rantai pikiran untuk memandu model hakim menjelaskan alasan di balik setiap putusannya. Memaksa model hakim untuk bernalar terbukti meningkatkan akurasi evaluasi. |
Hasil gabungan
| Kolom | Deskripsi |
|---|---|
| skor rata-rata | Skor rata-rata untuk semua instance. |
| simpangan baku | Simpangan baku untuk semua skor. |
PairwiseMetric
Hasil tingkat instance
| Kolom | Deskripsi |
|---|---|
| respons | Respons yang dihasilkan untuk perintah oleh model kandidat. |
| baseline_model_response | Respons yang dihasilkan untuk perintah oleh model dasar. |
| pairwise_choice | Model dengan respons yang lebih baik. Nilai yang mungkin adalah CANDIDATE, BASELINE, atau TIE. |
| penjelasan | Alasan model hakim memilih opsi tersebut. |
Hasil gabungan
| Kolom | Deskripsi |
|---|---|
| candidate_model_win_rate | Rasio waktu saat model hakim memutuskan bahwa model kandidat memiliki respons yang lebih baik terhadap total respons. Rentang antara 0 hingga 1. |
| baseline_model_win_rate | Rasio waktu saat model hakim memutuskan bahwa model dasar memiliki respons yang lebih baik terhadap total respons. Rentang antara 0 hingga 1. |
Metrik berbasis komputasi
Hasil tingkat instance
| Kolom | Deskripsi |
|---|---|
| respons | Respons model yang sedang dievaluasi. |
| referensi | Respons referensi. |
| skor | Skor dihitung untuk setiap pasangan respons dan referensi. |
Hasil gabungan
| Kolom | Deskripsi |
|---|---|
| skor rata-rata | Skor rata-rata untuk semua instance. |
| simpangan baku | Simpangan baku untuk semua skor. |
Contoh
Contoh di bagian ini menunjukkan cara membaca dan memahami hasil evaluasi.
Contoh 1: Evaluasi pointwise
Pada contoh pertama, pertimbangkan untuk mengevaluasi instance evaluasi pointwise untuk TEXT_QUALITY. Skor dari evaluasi pointwise metrik TEXT_QUALITY adalah 4 (dari skala 1 hingga 5), yang berarti responsnya bagus. Selain itu, penjelasan dalam hasil evaluasi menunjukkan alasan model hakim berpikir bahwa prediksi tersebut layak mendapatkan skor 4, dan bukan skor yang lebih tinggi atau lebih rendah.
Set data
prompt: "Ringkas teks berikut agar dapat dipahami oleh anak berusia lima tahun: Platform Media Sosial Menghadapi Reaksi Negatif atas Kebijakan Moderasi Konten\nSebuah platform media sosial terkemuka terlibat dalam kontroversi karena pengguna dan kreator konten menyatakan ketidakpuasan atas kebijakan moderasi kontennya. Tuduhan sensor yang bias, penegakan yang tidak konsisten, dan penekanan sudut pandang tertentu telah memicu kemarahan di kalangan pengguna yang mengklaim bahwa platform tersebut menghambat kebebasan berpendapat. Di sisi lain, platform tersebut menyatakan bahwa kebijakannya dirancang untuk menjaga lingkungan online yang aman dan inklusif. Kontroversi ini menimbulkan pertanyaan yang lebih luas tentang peran media sosial dalam membentuk wacana publik dan tanggung jawab platform dalam menyeleksi konten online."response: "Orang-orang kesal dengan sebuah situs karena mereka menganggap situs tersebut tidak adil dalam hal apa yang dapat diposting orang. Beberapa orang mengatakan bahwa situs tersebut menghalangi mereka untuk mengatakan apa yang mereka inginkan. Namun, situs tersebut mengatakan bahwa mereka berusaha menjaga keamanan semua orang. Hal ini membuat orang bertanya-tanya apakah situs harus mengontrol apa yang dapat dikatakan orang secara online."
Hasil
score: 4,explanation: Ringkasan dalam respons mengikuti petunjuk untuk meringkas konteks dengan cara yang dapat dipahami oleh anak berusia lima tahun. Ringkasan ini didasarkan pada konteks dan memberikan detail penting dalam ringkasannya. Namun, bahasa yang digunakan dalam respons agak bertele-tele.
Contoh 2: Evaluasi berpasangan
Contoh kedua adalah evaluasi perbandingan berpasangan pada PAIRWISE_QUESTION_ANSWERING_QUALITY. Hasil pairwise_choice menunjukkan bahwa respons kandidat "Prancis adalah negara yang terletak di Eropa Barat" lebih disukai oleh model penilaian dibandingkan dengan respons dasar "Prancis adalah sebuah negara" untuk menjawab pertanyaan dalam perintah. Mirip dengan hasil pointwise, penjelasan juga diberikan untuk menjelaskan mengapa respons kandidat lebih baik daripada respons dasar (respons kandidat lebih membantu dalam hal ini).
Set data
prompt: "Dapatkah Anda menjawab di mana lokasi Prancis berdasarkan paragraf berikut? Prancis adalah negara yang terletak di Eropa Barat. Negara ini berbatasan dengan Belgia, Luksemburg, Jerman, Swiss, Italia, Monako, Spanyol, dan Andorra. Garis pantai Prancis membentang di sepanjang Selat Inggris, Laut Utara, Samudra Atlantik, dan Laut Mediterania. Dikenal dengan sejarahnya yang kaya, landmark ikonis seperti Menara Eiffel, dan kulinernya yang lezat, Prancis adalah kekuatan budaya dan ekonomi utama di Eropa dan di seluruh dunia."response: "Prancis adalah negara yang terletak di Eropa Barat.",baseline_model_response: "Prancis adalah sebuah negara.",
Hasil
pairwise_choice: KANDIDAT,explanation: Respons BASELINE memiliki rujukan, tetapi tidak sepenuhnya menjawab pertanyaan. Namun, respons KANDIDAT benar dan memberikan detail bermanfaat tentang lokasi Prancis.
Langkah berikutnya
Coba notebook contoh evaluasi.
Pelajari evaluasi AI generatif.