이 페이지에서는 Vertex AI RAG Engine이 무엇이며 어떻게 작동하는지 설명합니다.
| 설명 | 콘솔 |
|---|---|
| Vertex AI SDK를 사용하여 Vertex AI RAG Engine 태스크를 실행하는 방법은 Python용 RAG 빠른 시작을 참조하세요. |
개요
Vertex AI RAG Engine은 검색 증강 생성(RAG)을 용이하게 하는 Vertex AI 플랫폼의 구성요소입니다. Vertex AI RAG 엔진은 컨텍스트 증강 대규모 언어 모델(LLM) 애플리케이션을 개발하기 위한 데이터 프레임워크입니다. 컨텍스트 증강은 데이터에 LLM을 적용할 때 발생합니다. 이는 검색 증강 생성(RAG)을 구현합니다.
LLM의 일반적인 문제는 비공개 지식, 즉 조직의 데이터를 이해하지 못한다는 것입니다. Vertex AI RAG Engine을 사용하면 추가 비공개 정보로 LLM 컨텍스트를 보강할 수 있습니다. 모델이 할루시네이션을 줄이고 질문에 더 정확하게 답변할 수 있기 때문입니다.
추가 지식 소스를 LLM이 보유한 기존 지식과 결합하여 더 나은 컨텍스트가 제공됩니다. 쿼리와 함께 개선된 컨텍스트는 LLM의 응답 품질을 향상시킵니다.
다음 이미지는 Vertex AI RAG 엔진을 이해하는 데 필요한 주요 개념을 보여줍니다.
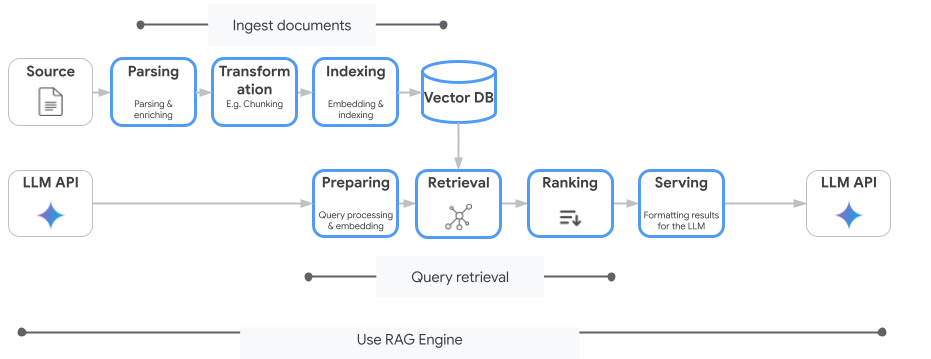
이러한 개념은 검색 증강 생성(RAG) 프로세스 순서로 나열되어 있습니다.
데이터 수집: 다양한 데이터 소스에서 데이터를 수집합니다. 예를 들면 로컬 파일, Cloud Storage, Google Drive가 있습니다.
데이터 변환: 색인 생성을 준비하는 동안 데이터를 변환합니다. 예를 들어 데이터가 청크로 분할됩니다.
임베딩: 단어나 텍스트 조각을 숫자로 표현한 것입니다. 이 숫자는 텍스트의 의미론적 의미와 맥락을 캡처합니다. 유사하거나 관련된 단어 또는 텍스트는 임베딩이 비슷한 경향이 있습니다. 즉, 고차원 벡터 공간에서 더 가깝게 위치합니다.
데이터 색인 생성: Vertex AI RAG Engine은 코퍼스라는 색인을 만듭니다. 색인은 기술 자료를 구조화하므로 검색에 최적화되어 있습니다. 예를 들어, 색인은 방대한 참조 서적의 상세한 목차와 같습니다.
검색: 사용자가 질문하거나 프롬프트를 제공하면 Vertex AI RAG Engine의 검색 구성요소는 기술 자료를 통해 쿼리와 관련된 정보를 찾습니다.
생성: 검색된 정보는 생성 AI 모델이 사실에 근거하고 관련성 있는 응답을 생성하기 위한 가이드로 원래 사용자 쿼리에 추가된 컨텍스트가 됩니다.
지원되는 리전
Vertex AI Agent Engine은 다음 리전에서 지원됩니다.
| 지역 | 위치 | 설명 | 출시 단계 |
|---|---|---|---|
us-central1 |
아이오와 | v1 및 v1beta1 버전이 지원됩니다. |
허용 목록 |
us-east4 |
버지니아 | v1 및 v1beta1 버전이 지원됩니다. |
GA |
europe-west3 |
독일 프랑크푸르트 | v1 및 v1beta1 버전이 지원됩니다. |
GA |
europe-west4 |
네덜란드 엠스하벤 | v1 및 v1beta1 버전이 지원됩니다. |
GA |
us-central1가Allowlist로 변경됩니다. Vertex AI RAG Engine을 실험하려면 다른 리전을 사용해 보세요. 프로덕션 트래픽을us-central1에 온보딩할 계획이라면vertex-ai-rag-engine-support@google.com에 문의하세요.
Vertex AI RAG Engine 삭제
다음 코드 샘플은 Google Cloud 콘솔, Python, REST에서 Vertex AI RAG 엔진을 삭제하는 방법을 보여줍니다.
의견 보내기
Google 지원팀과 채팅하려면 Vertex AI RAG Engine 지원 그룹으로 이동하세요.
이메일을 보내려면 이메일 주소 vertex-ai-rag-engine-support@google.com을 사용하세요.
다음 단계
- Vertex AI SDK를 사용하여 Vertex AI RAG Engine 태스크를 실행하는 방법은 Python용 RAG 빠른 시작을 참조하세요.
- 그라운딩에 대한 자세한 내용은 그라운딩 개요를 참조하세요.
- RAG의 응답에 대해 자세히 알아보려면 Vertex AI RAG 엔진의 검색 및 생성 출력을 참조하세요.
- RAG 아키텍처에 대해 알아보려면 다음을 참조하세요.