Visual Question & Answering(VQA)機能を使用すると、モデルに画像を渡して画像の内容について質問できます。質問に対して、自然言語の回答が 1 つ以上返されます。
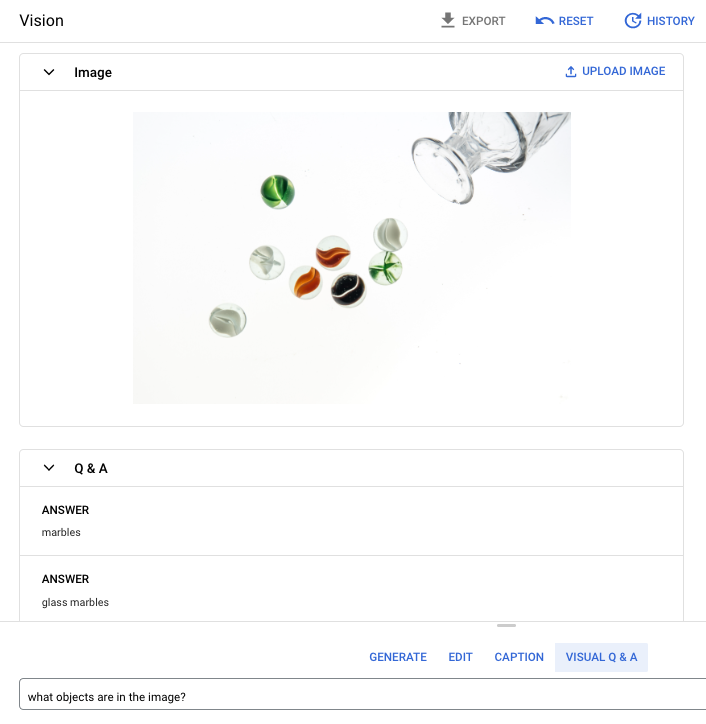
プロンプトの質問: 画像に写っているものは何?
回答 1: ビー玉
回答 2: ガラスのビー玉
サポートされている言語
VQA は以下の言語でご利用いただけます。
- English (en)
パフォーマンスと制限事項
このモデルを使用するときは次の上限が適用されます。
| 上限 | 値 |
|---|---|
| 各プロジェクト 1 分あたりの最大 API リクエスト数(短形式) | 500 |
| レスポンスで返されるトークンの最大数(短形式) | 64 トークン |
| リクエストで受け入れられるトークンの最大数(VQA の短形式のみ) | 80 トークン |
このモデルを使用する場合は、次のサービス レイテンシの見積もりが適用されます。これらの値は例示を目的としたものであり、サービスを約束するものではありません。
| レイテンシ | 値 |
|---|---|
| API リクエスト(短形式) | 1.5 秒 |
ロケーション
ロケーションは、データの保存場所を制御するためにリクエストで指定できるリージョンです。使用可能なリージョンの一覧については、Vertex AI の生成 AI のロケーションをご覧ください。
責任ある AI の安全フィルタリング
画像キャプションと Visual Question Answering(VQA)の機能モデルは、ユーザーが構成可能な安全フィルタをサポートしていません。ただし、Imagen の全体的な安全フィルタリングは、次のデータに対して行われます。
- ユーザー入力
- モデル出力
その結果、Imagen がこれらの安全フィルタを適用すると、出力がサンプル出力と異なる場合があります。以下の例を考えてみましょう。
フィルタされた入力
入力がフィルタされている場合、レスポンスは次のようになります。
{
"error": {
"code": 400,
"message": "Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.DebugInfo",
"detail": "[ORIGINAL ERROR] generic::invalid_argument: Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394 [google.rpc.error_details_ext] { message: \"Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394\" }"
}
]
}
}
フィルタされた出力
返されたレスポンス数が指定したサンプル数より少ない場合は、欠落しているレスポンスが責任ある AI によってフィルタされていることを示しています。たとえば、"sampleCount": 2 を含むリクエストに対するレスポンスは次のようになりますが、レスポンスの一つは除外されます。
{
"predictions": [
"cappuccino"
]
}
すべての出力がフィルタされている場合、レスポンスは次のような空のオブジェクトになります。
{}
画像で VQA を使用する(短形式のレスポンス)
次のサンプルを使用して画像について質問し、回答を得てみましょう。
REST
imagetext モデル リクエストの詳細については、imagetext モデル API リファレンスをご覧ください。
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: 実際の Google Cloud プロジェクト ID。
- LOCATION: プロジェクトのリージョン。たとえば、
us-central1、europe-west2、asia-northeast3です。使用可能なリージョンの一覧については、Vertex AI の生成 AI のロケーションをご覧ください。 - VQA_PROMPT: 回答を得たい画像に関する質問。
- この靴は何色?
- シャツの袖の種類を教えて。
- B64_IMAGE: キャプションを取得する画像。画像は base64 でエンコードされたバイト文字列として指定する必要があります。サイズの上限: 10 MB。
- RESPONSE_COUNT: 生成したい回答の数。指定できる整数値: 1~3。
HTTP メソッドと URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict
リクエストの本文(JSON):
{
"instances": [
{
"prompt": "VQA_PROMPT",
"image": {
"bytesBase64Encoded": "B64_IMAGE"
}
}
],
"parameters": {
"sampleCount": RESPONSE_COUNT
}
}
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict"
PowerShell
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict" | Select-Object -Expand Content
"sampleCount": 2 と "prompt": "What is this?" を含むリクエストに対するものです。レスポンスは回答として 2 つの予測文字列を返します。
{
"predictions": [
"cappuccino",
"coffee"
]
}
Python
このサンプルを試す前に、Vertex AI クイックスタート: クライアント ライブラリの使用にある Python の設定手順を完了してください。詳細については、Vertex AI Python API のリファレンス ドキュメントをご覧ください。
Vertex AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
このサンプルでは、load_from_file メソッドを使用して、情報の取得対象となるベース Image としてローカル ファイルを参照します。ベース画像を指定したら、ImageTextModel で ask_question メソッドを使用して、回答を表示します。
Node.js
このサンプルを試す前に、Vertex AI クイックスタート: クライアント ライブラリの使用にある Node.js の設定手順を完了してください。詳細については、Vertex AI Node.js API のリファレンス ドキュメントをご覧ください。
Vertex AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
このサンプルでは、PredictionServiceClient で predict メソッドを呼び出します。サービスは、指定された質問に対する回答を返します。
VQA 用パラメータを使用する
VQA のレスポンスを受け取るとき、ユースケースに応じていくつかのパラメータを設定できます。
検索結果の表示件数
検索結果の表示件数のパラメータを使用して、送信するリクエストごとに返される回答の数を制限できます。詳細については、imagetext(VQA)モデル API リファレンスをご覧ください。
シード番号
生成される回答を確定するためリクエストに追加する数値。リクエストにシード番号を追加すると、毎回確実に同じ予測(回答)が得られます。ただし、回答が同じ順序で返されるとは限りません。詳細については、imagetext(VQA)モデル API リファレンスをご覧ください。
次のステップ
Imagen や Vertex AI のその他の生成 AI プロダクトに関する次の記事を読む。
- Vertex AI で Imagen 3 を使い始めるためのデベロッパー ガイド
- クリエイターとともにクリエイターのために構築された、新しい生成メディアのモデルとツール
- Gemini の新機能: カスタム Gem と Imagen 3 による画像生成の改善
- Google DeepMind: Imagen 3 - 最も高い品質水準の Text-to-Image モデル