Mit Vertex AI-Embedding-Modellen können optimierte Embeddings für verschiedene Aufgabentypen generiert werden, z. B. für den Dokumentabruf, das Stellen und Beantworten von Fragen und die Faktenprüfung. Aufgabentypen sind Labels, mit denen die vom Modell generierten Einbettungen anhand des beabsichtigten Anwendungsfalls optimiert werden. In diesem Dokument wird beschrieben, wie Sie den optimalen Aufgabentyp für Ihre Einbettungen auswählen.
Unterstützte Modelle
Aufgabentypen werden von den folgenden Modellen unterstützt:
text-embedding-005text-multilingual-embedding-002gemini-embedding-001
Vorteile von Aufgabentypen
Mit Aufgabentypen lässt sich die Qualität der Einbettungen verbessern, die von einem Einbettungsmodell generiert werden.
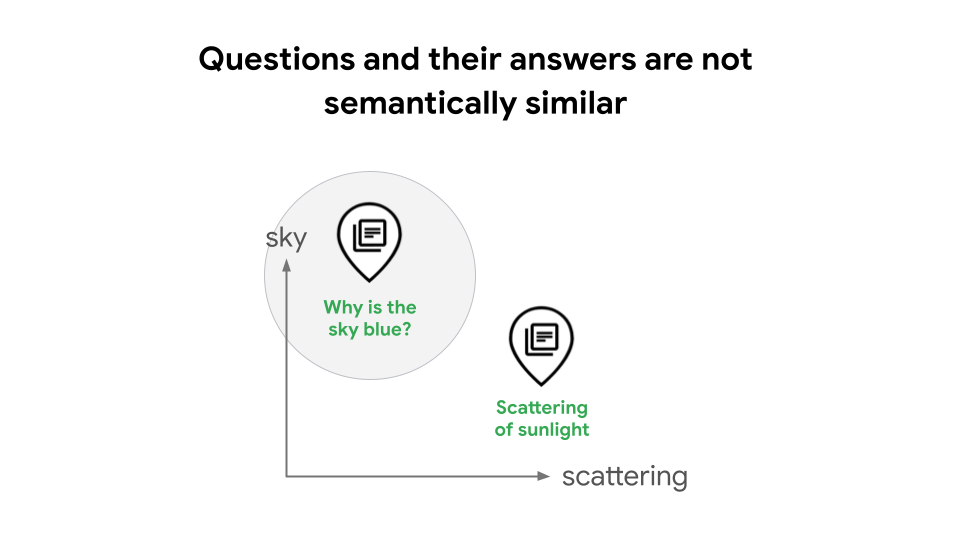
Wenn Sie beispielsweise RAG-Systeme (Retrieval Augmented Generation) erstellen, ist es üblich, Text-Embeddings und die Vektorsuche für die Ähnlichkeitssuche zu verwenden. In einigen Fällen kann dies zu einer schlechteren Suchqualität führen, da Fragen und ihre Antworten semantisch nicht ähnlich sind. Eine Frage wie „Warum ist der Himmel blau?“ und die Antwort „Die Streuung des Sonnenlichts bewirkt die blaue Farbe“ haben beispielsweise als Aussagen deutlich unterschiedliche Bedeutungen. Das bedeutet, dass ein RAG-System ihre Beziehung nicht automatisch erkennt, wie in Abbildung 1 dargestellt. Ohne Aufgabentypen müsste ein RAG-Entwickler sein Modell trainieren, um die Beziehung zwischen Suchanfragen und Antworten zu lernen. Das erfordert fortgeschrittene Data-Science-Kenntnisse und Erfahrung. Alternativ kann er LLM-basierte Suchanfrageerweiterung oder HyDE verwenden, was zu hoher Latenz und hohen Kosten führen kann.

Mit Aufgabentypen können Sie optimierte Einbettungen für bestimmte Aufgaben generieren. So sparen Sie Zeit und Kosten, die für die Entwicklung eigener aufgabenspezifischer Einbettungen erforderlich wären. Das generierte Einbettungselement für die Suchanfrage „Warum ist der Himmel blau?“ und die Antwort „Die Streuung des Sonnenlichts bewirkt die blaue Farbe“ würden sich im gemeinsamen Einbettungsraum befinden, der die Beziehung zwischen ihnen darstellt, wie in Abbildung 2 dargestellt. In diesem RAG-Beispiel würden die optimierten Einbettungen zu verbesserten Ähnlichkeitssuchen führen.
Neben dem Anwendungsfall für Suchanfragen und Antworten bieten Aufgabentypen auch optimierte Platzkapazitäten für Aufgaben wie Klassifizierung, Clustering und Faktenprüfung.
Unterstützte Aufgabentypen
Einbettungsmodelle, die Aufgabentypen verwenden, unterstützen die folgenden Aufgabentypen:
| Aufgabentyp | Beschreibung |
|---|---|
CLASSIFICATION |
Wird verwendet, um Einbettungen zu generieren, die für die Klassifizierung von Texten nach vordefinierten Labels optimiert sind. |
CLUSTERING |
Wird verwendet, um Einbettungen zu generieren, die für das Clustern von Texten basierend auf ihren Ähnlichkeiten optimiert sind. |
RETRIEVAL_DOCUMENT, RETRIEVAL_QUERY, QUESTION_ANSWERING und FACT_VERIFICATION |
Wird verwendet, um Einbettungen zu generieren, die für die Dokumentsuche oder die Informationsabfrage optimiert sind. |
CODE_RETRIEVAL_QUERY |
Wird verwendet, um einen Codeblock basierend auf einer Anfrage in natürlicher Sprache abzurufen, z. B. Sortiere ein Array oder Kehre eine verkettete Liste um. Einbettungen der Codeblöcke werden mit RETRIEVAL_DOCUMENT berechnet. |
SEMANTIC_SIMILARITY |
Wird verwendet, um Einbettungen zu generieren, die für die Beurteilung der Textähnlichkeit optimiert sind. Dies ist nicht für Abrufanwendungsfälle vorgesehen. |
Der beste Aufgabentyp für Ihren Einbettungsjob hängt davon ab, welchen Anwendungsfall Sie für Ihre Einbettungen haben. Bevor Sie einen Aufgabentyp auswählen, sollten Sie den Anwendungsfall für die Einbettungen bestimmen.
Anwendungsfall für Einbettungen bestimmen
Anwendungsfälle für Einbettungen fallen in der Regel in eine der vier Kategorien: Textähnlichkeit beurteilen, Texte klassifizieren, Texte clustern oder Informationen aus Texten abrufen. Wenn Ihr Anwendungsfall nicht in eine der oben genannten Kategorien fällt, verwenden Sie standardmäßig den Aufgabentyp RETRIEVAL_QUERY.
Es gibt zwei Arten der Formatierung von Aufgabenanweisungen: asymmetrisches und symmetrisches Format. Sie müssen den richtigen Parameter für Ihren Anwendungsfall verwenden.
| Anwendungsfälle für den Abruf (asymmetrisches Format) |
Typ der Abfrageaufgabe | Dokumentaufgabentyp |
|---|---|---|
| Suchanfrage | RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT |
| Question Answering | QUESTION_ANSWERING | |
| Faktenchecks | FACT_VERIFICATION | |
| Codeabruf | CODE_RETRIEVAL_QUERY |
| Anwendungsfälle mit einem einzelnen Eingabefeld (symmetrisches Format) |
Aufgabentyp eingeben |
|---|---|
| Klassifizierung | KLASSIFIZIERUNG |
| Clustering | CLUSTERING |
| Semantische Ähnlichkeit (Nicht für Abrufanwendungsfälle verwenden; für STS vorgesehen) |
SEMANTIC_SIMILARITY |
Texte klassifizieren
Wenn Sie Texte mithilfe von Einbettungen nach vordefinierten Labels klassifizieren möchten, verwenden Sie den Aufgabentyp CLASSIFICATION. Bei diesem Aufgabentyp werden Einbettungen in einem für die Klassifizierung optimierten Einbettungsraum generiert.
Angenommen, Sie möchten beispielsweise Einbettungen für Beiträge in sozialen Medien generieren, mit denen Sie deren Sentiment als positiv, negativ oder neutral klassifizieren können. Wenn Einbettungen für einen Social-Media-Beitrag mit dem Text „Ich mag es nicht, mit dem Flugzeug zu reisen“ klassifiziert werden, wird das Sentiment als negativ eingestuft.
Clustertexte
Wenn Sie Texte anhand ihrer Ähnlichkeiten mithilfe von Einbettungen clustern möchten, verwenden Sie den Aufgabentyp CLUSTERING. Bei diesem Aufgabentyp werden Einbettungen generiert, die für die Gruppierung nach Ähnlichkeit optimiert sind.
Angenommen, Sie möchten embeddings für Nachrichtenartikel generieren, damit Sie Nutzern Artikel präsentieren können, die thematisch mit den Artikeln zusammenhängen, die sie zuvor gelesen haben. Nachdem die Einbettungen generiert und geclustert wurden, können Sie Nutzern, die viel über Sport lesen, weitere sportbezogene Artikel vorschlagen.
Weitere Anwendungsfälle für das Clustering:
- Kundensegmentierung:Kunden mit ähnlichen Einbettungen gruppieren, die aus ihren Profilen oder Aktivitäten generiert wurden, um personalisierte Werbung zu präsentieren.
- Produktsegmentierung: Wenn Sie Produkt-Embeddings nach Produkttitel und -beschreibung, Produktbildern oder Kundenrezensionen gruppieren, können Sie Ihre Produkte segmentieren.
- Marktforschung: Durch das Clustern von Antworten aus Verbraucherumfragen oder durch das Einbetten von Daten aus sozialen Medien können verborgene Muster und Trends in den Meinungen, Vorlieben und Verhaltensweisen von Verbrauchern aufgedeckt werden. So können Marktforschungsbemühungen unterstützt und Strategien zur Produktentwicklung fundiert werden.
- Gesundheitswesen: Durch das Clustern von Patienten-Embeddings, die aus medizinischen Daten abgeleitet wurden, können Gruppen mit ähnlichen Erkrankungen oder Behandlungsreaktionen identifiziert werden. Dies führt zu personalisierten Gesundheitsplänen und zielgerichteten Therapien.
- Trends beim Kundenfeedback: Wenn Sie Kundenfeedback aus verschiedenen Kanälen (Umfragen, soziale Medien, Supporttickets) in Gruppen zusammenfassen, können Sie häufige Probleme, Funktionsanfragen und Bereiche für Produktverbesserungen identifizieren.
Informationen aus Texten abrufen
Wenn Sie ein Such- oder Abrufsystem entwickeln, arbeiten Sie mit zwei Arten von Text:
- Korpus: Die Sammlung von Dokumenten, die Sie durchsuchen möchten.
- Suchanfrage: Der Text, den ein Nutzer eingibt, um im Korpus nach Informationen zu suchen.
Um die beste Leistung zu erzielen, müssen Sie verschiedene Aufgabentypen verwenden, um Einbettungen für Ihren Korpus und Ihre Anfragen zu generieren.
Zuerst generieren Sie Einbettungen für Ihre gesamte Dokumentensammlung. Dies sind die Inhalte, die durch Nutzeranfragen abgerufen werden. Verwenden Sie beim Einbetten dieser Dokumente den Aufgabentyp RETRIEVAL_DOCUMENT. Normalerweise führen Sie diesen Schritt einmal aus, um Ihren gesamten Korpus zu indexieren und die resultierenden Einbettungen in einer Vektordatenbank zu speichern.
Wenn ein Nutzer eine Suche ausführt, generieren Sie in Echtzeit ein Embedding für den Suchanfragetext. Verwenden Sie dazu einen Aufgabentyp, der der Intention des Nutzers entspricht. Ihr System verwendet diese Abfrageeinbettung dann, um die ähnlichsten Dokumenteinbettungen in Ihrer Vektordatenbank zu finden.
Die folgenden Aufgabentypen werden für Anfragen verwendet:
RETRIEVAL_QUERY: Verwenden Sie diese Option für eine Standard-Suchanfrage, wenn Sie relevante Dokumente finden möchten. Das Modell sucht nach Dokumenteinbettungen, die der Abfrageeinbettung semantisch ähnlich sind.QUESTION_ANSWERING: Verwenden Sie diesen Wert, wenn alle Suchanfragen als richtige Fragen formatiert sein sollen, z. B. „Warum ist der Himmel blau?“ oder „Wie binde ich meine Schnürsenkel?“.FACT_VERIFICATION: Verwenden Sie diesen Befehl, wenn Sie ein Dokument aus Ihrem Korpus abrufen möchten, das eine Aussage bestätigt oder widerlegt. Bei der Suchanfrage „Äpfel wachsen unter der Erde“ wird beispielsweise möglicherweise ein Artikel über Äpfel zurückgegeben, der die Aussage letztendlich widerlegt.
Betrachten Sie das folgende reale Szenario, in dem Abfragen zum Abrufen nützlich wären:
- Für eine E-Commerce-Plattform sollten Sie Einbettungen verwenden, damit Nutzer sowohl mit Textabfragen als auch mit Bildern nach Produkten suchen können. So wird das Einkaufserlebnis intuitiver und ansprechender.
- Sie möchten für eine Bildungsplattform ein Frage-Antwort-System entwickeln, das Fragen von Schülern und Studenten anhand von Lehrbuchinhalten oder Bildungsressourcen beantworten kann. So soll eine personalisierte Lernerfahrung ermöglicht und Schülern und Studenten dabei geholfen werden, komplexe Konzepte zu verstehen.
Codeabruf
text-embedding-005 unterstützt einen neuen Aufgabentyp CODE_RETRIEVAL_QUERY, mit dem relevante Codeblöcke mithilfe von Suchanfragen in Nur-Text abgerufen werden können. Zur Verwendung dieser Funktion sollten Codeblöcke mithilfe des Aufgabentyps RETRIEVAL_DOCUMENT eingebettet werden, während Textabfragen mit CODE_RETRIEVAL_QUERY eingebettet werden.
Informationen zu allen Aufgabentypen finden Sie in der Modellreferenz.
Hier ein Beispiel:
REST
PROJECT_ID=PROJECT_ID
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-005:predict -d \
$'{
"instances": [
{
"task_type": "CODE_RETRIEVAL_QUERY",
"content": "Function to add two numbers"
}
],
}'
Python
Informationen zur Installation des Vertex AI SDK for Python finden Sie unter Vertex AI SDK for Python installieren. Weitere Informationen finden Sie in der Python-API-Referenzdokumentation.
Textähnlichkeit bewerten
Wenn Sie Einbettungen verwenden möchten, um die Textähnlichkeit zu beurteilen, verwenden Sie den Aufgabentyp SEMANTIC_SIMILARITY. Bei diesem Aufgabentyp werden Einbettungen generiert, die für die Generierung von Ähnlichkeitswerten optimiert sind.
Angenommen, Sie möchten Einbettungen generieren, um die Ähnlichkeit der folgenden Texte zu vergleichen:
- Die Katze schläft
- Die Katze döst
Wenn die Einbettungen verwendet werden, um einen Ähnlichkeitsscore zu erstellen, ist dieser hoch, da beide Texte fast dieselbe Bedeutung haben.
Betrachten Sie die folgenden realen Szenarien, in denen die Ähnlichkeit von Eingaben nützlich wäre:
- Für ein Empfehlungssystem möchten Sie Elemente (z.B. Produkte, Artikel, Filme) identifizieren, die semantisch den bevorzugten Elementen eines Nutzers ähneln, um personalisierte Empfehlungen zu geben und die Nutzerzufriedenheit zu steigern.
Bei der Verwendung dieser Modelle gelten die folgenden Einschränkungen:
- Verwenden Sie diese Vorschaumodelle nicht in geschäftskritischen oder Produktionssystemen.
- Diese Modelle sind nur in
us-central1verfügbar. - Batchvorhersagen werden nicht unterstützt.
- Anpassung wird nicht unterstützt.
Nächste Schritte
- Lernen Sie Texteinbettungen abzurufen.