Nach dem Training eines Modells verwendet AutoML Translation Elemente aus dem Set TEST, um die Qualität und Treffsicherheit des neuen Modells zu bewerten. AutoML Translation ermittelt die Modellqualität. Es nutzt dazu den BLEU-Score (Bilingual Evaluation Understudy) der angibt, wie ähnlich der Kandidatentext den Referenztexten ist, wobei Werte, die näher an 1 liegen, ähnlichere Texte darstellen.
Mithilfe des BLEU-Scores kann auch die Modellqualität insgesamt bewertet werden. Außerdem können Sie die Modellausgabe im Hinblick auf bestimmte Datenelemente bewerten. Exportieren Sie dazu das Set TEST mit den Modellvorhersagen. Die exportierten Daten enthalten sowohl den Referenztext (aus dem Original-Dataset) als auch den Kandidatentext des Modells.
Mit diesen Daten können Sie nun bewerten, ob Ihr Modell einsatzbereit ist. Wenn Sie mit der Qualität nicht zufrieden sind, fügen Sie am besten weitere (und stärker unterschiedliche) Paare von Trainingssätzen hinzu. Die eine Möglichkeit besteht also darin, weitere Satzpaare hinzuzufügen. Verwenden Sie dazu den Link Dateien hinzufügen in der Titelleiste. Nachdem Sie Dateien hinzugefügt haben, erstellen Sie ein neues Modell. Klicken Sie hierzu auf der Seite Trainieren auf die Schaltfläche Neues Modell trainieren. Wiederholen Sie diesen Vorgang, bis Sie eine ausreichend hohe Qualität erreicht haben.
Modellbewertung abrufen
Web-UI
Öffnen Sie die AutoML Translation-Konsole und klicken Sie auf das Glühbirnensymbol neben Modelle in der linken Navigationsleiste. Die verfügbaren Modelle werden angezeigt. Für jedes Modell sind die folgenden Informationen enthalten: Dataset (aus dem das Modell trainiert wurde), Quelle (Sprache), Zielsprache, Basismodell, das zum Trainieren des Modells verwendet wird.
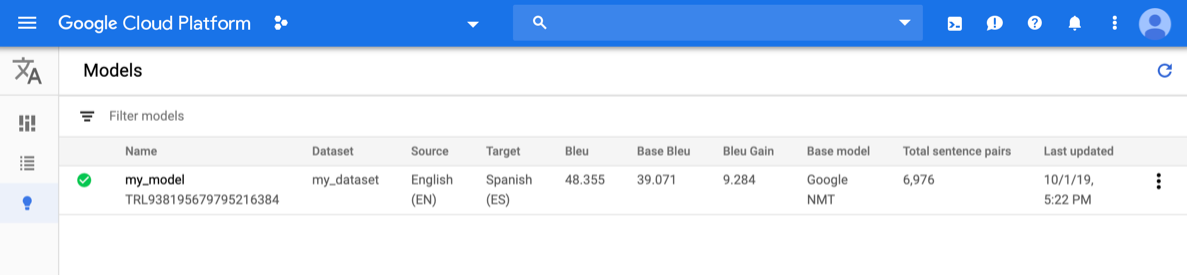
Wählen Sie zum Anzeigen der Modelle für ein anderes Projekt das Projekt in der Dropdown-Liste oben rechts in der Titelleiste aus.
Klicken Sie in die Zeile für das Modell, das Sie auswerten möchten.
Der Tab Predict (Prognose) wird angezeigt.
Hier können Sie Ihr Modell testen und die Ergebnisse sowohl für das benutzerdefinierte Modell als auch für das Basismodell ansehen, mit dem Sie trainiert haben.
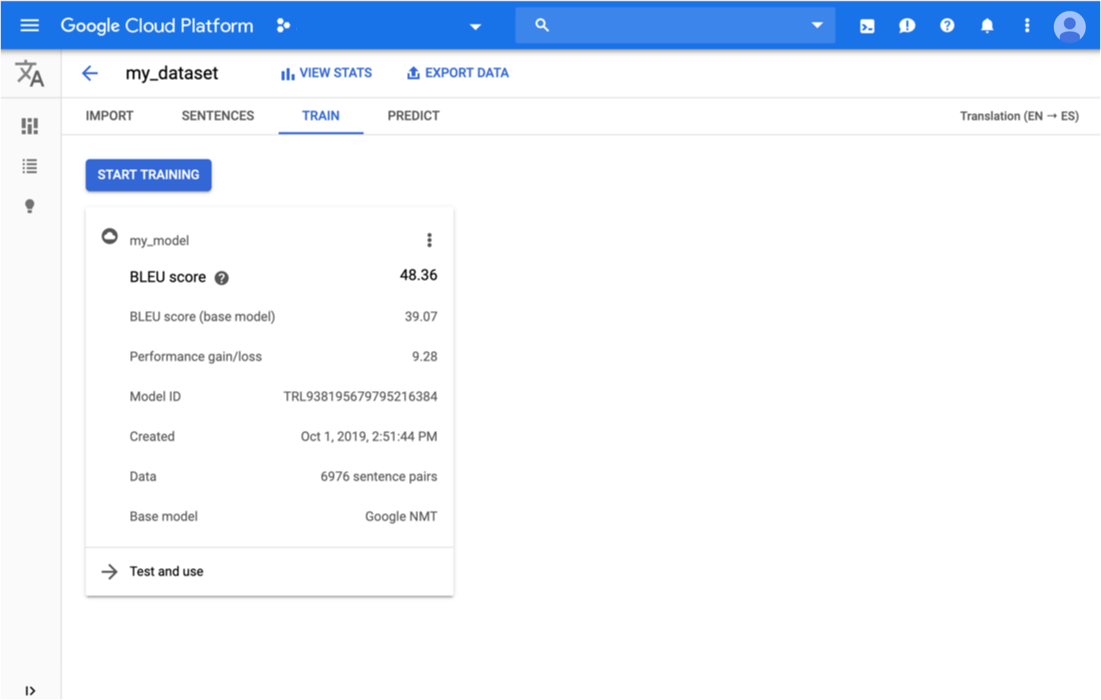
Klicken Sie unterhalb der Titelleiste auf den Tab Trainieren.
Sobald das Training für das Modell abgeschlossen ist, werden die entsprechenden Bewertungsmesswerte in AutoML Translation angezeigt.
REST
Ersetzen Sie dabei folgende Werte für die Anfragedaten:
- model-name: der vollständige Name Ihres Modells. Er enthält den Projektnamen und den Standort. Ein Modellname sieht in etwa so aus:
projects/project-id/locations/us-central1/models/model-id. - project-id: Ihre Google Cloud Platform-Projekt-ID
HTTP-Methode und URL:
GET https://automl.googleapis.com/v1/model-name/modelEvaluations
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"modelEvaluation": [
{
"name": "projects/project-number/locations/us-central1/models/model-id/modelEvaluations/evaluation-id",
"createTime": "2019-10-02T00:20:30.972732Z",
"evaluatedExampleCount": 872,
"translationEvaluationMetrics": {
"bleuScore": 48.355409502983093,
"baseBleuScore": 39.071375131607056
}
}
]
}
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Translation finden Sie unter AutoML Translation-Clientbibliotheken. Weitere Informationen finden Sie in der AutoML Translation Go API-Referenzdokumentation.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Translation zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Translation finden Sie unter AutoML Translation-Clientbibliotheken. Weitere Informationen finden Sie in der AutoML Translation Java API-Referenzdokumentation.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Translation zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Translation finden Sie unter AutoML Translation-Clientbibliotheken. Weitere Informationen finden Sie in der AutoML Translation Node.js API-Referenzdokumentation.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Translation zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für AutoML Translation finden Sie unter AutoML Translation-Clientbibliotheken. Weitere Informationen finden Sie in der AutoML Translation Python API-Referenzdokumentation.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei AutoML Translation zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Weitere Sprachen
C#: Folgen Sie der Anleitung zur Einrichtung von C# auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Translation-Referenzdokumentation für .NET auf.
PHP: Folgen Sie der Anleitung zur Einrichtung von PHP auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Translation-Referenzdokumentation für PHP auf.
Ruby: Folgen Sie der Anleitung zur Einrichtung von Ruby auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Translation-Referenzdokumentation für Ruby auf.
Testdaten mit Modellvorhersagen exportieren
Nach dem Training eines Modells verwendet AutoML Translation Elemente aus dem Set TEST, um die Qualität und Treffsicherheit des neuen Modells zu bewerten. Über die AutoML Translation Console können Sie die TEST-Gruppe exportieren, um zu sehen, wie die Modellausgabe mit dem Referenztext aus dem ursprünglichen Dataset verglichen wird. AutoML Translation speichert in Ihrem Google Cloud Storage-Bucket eine TSV-Datei, deren einzelne Zeilen jeweils wie folgt aufgebaut sind:
Source sentence Tabulatorzeichen Reference translation Tabulatorzeichen Model candidate translation
Web-UI
Öffnen Sie die AutoML Translation Console und klicken Sie in der linken Navigationsleiste links neben "Modelle" auf das Glühbirnensymbol, um die verfügbaren Modelle anzuzeigen.
Wählen Sie zum Anzeigen der Modelle für ein anderes Projekt das Projekt in der Dropdown-Liste oben rechts in der Titelleiste aus.
Wählen Sie das Modell aus.
Klicken Sie in der Titelleiste auf die Schaltfläche Daten exportieren.
Geben Sie den vollständigen Pfad zum Google Cloud Storage-Bucket ein, in dem Sie die exportierte TSV-Datei speichern möchten.
Sie müssen einen Bucket verwenden, der dem aktuellen Projekt zugeordnet ist.
Wählen Sie das Modell aus, dessen TEST-Daten Sie exportieren möchten.
Die Drop-down-Liste Test-Dataset mit Modellvorhersagen enthält die Modelle, die mit demselben Eingabe-Dataset trainiert wurden.
Klicken Sie auf Exportieren.
AutoML Translation schreibt eine Datei mit dem Namen model-name
_evaluated.tsvin den angegebenen Google Cloud Storage-Bucket.
Modelle mit einem neuen Test-Dataset bewerten und vergleichen
In der AutoML Translation Console können Sie vorhandene Modelle mithilfe eines neuen Satzes von Testdaten neu bewerten. In einer einzelnen Bewertung können Sie bis zu fünf verschiedene Modelle einschließen und dann deren Ergebnisse vergleichen.
Laden Sie Ihre Testdaten in Cloud Storage als eine tabulatorgetrennte Werte-Datei (.tsv) oder als Translation Memory eXchange(.tmx)-Datei.
AutoML Translation wertet Ihre Modelle anhand des Testsets aus und erstellt dann Bewertungsergebnisse. Sie können die Ergebnisse für jedes Modell optional als .tsv-Datei in einem Cloud Storage-Bucket speichern, wobei jede Zeile das folgende Format hat:
Source sentence tab Model candidate translation tab Reference translation
Web-UI
Öffnen Sie die AutoML Translation-Konsole und klicken Sie im linken Navigationsbereich auf Modelle, um die verfügbaren Modelle aufzurufen.
Wenn Sie die Modelle für ein anderes Projekt ansehen möchten, wählen Sie das Projekt in der Dropdown-Liste rechts oben in der Titelleiste aus.
Wählen Sie eines der Modelle aus, die Sie auswerten möchten.
Klicken Sie unterhalb der Titelleiste auf den Tab Bewerten.
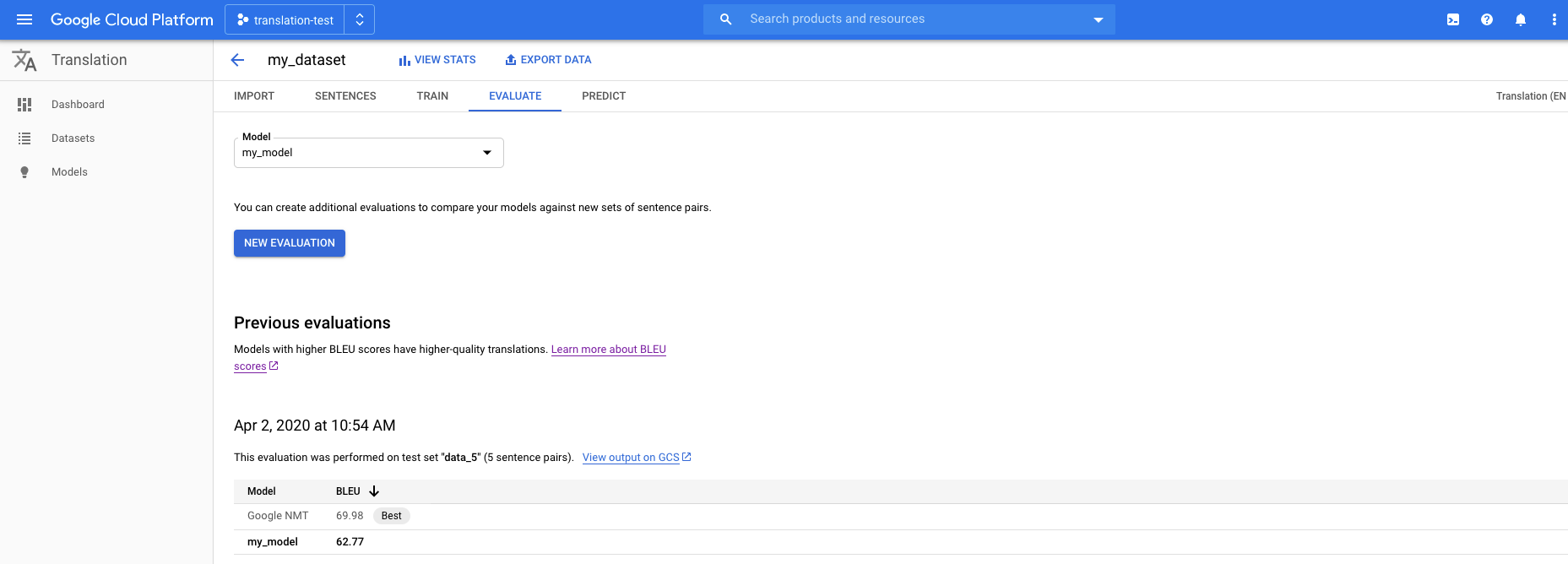
Klicken Sie auf dem Tab Bewerten auf Neue Bewertung.
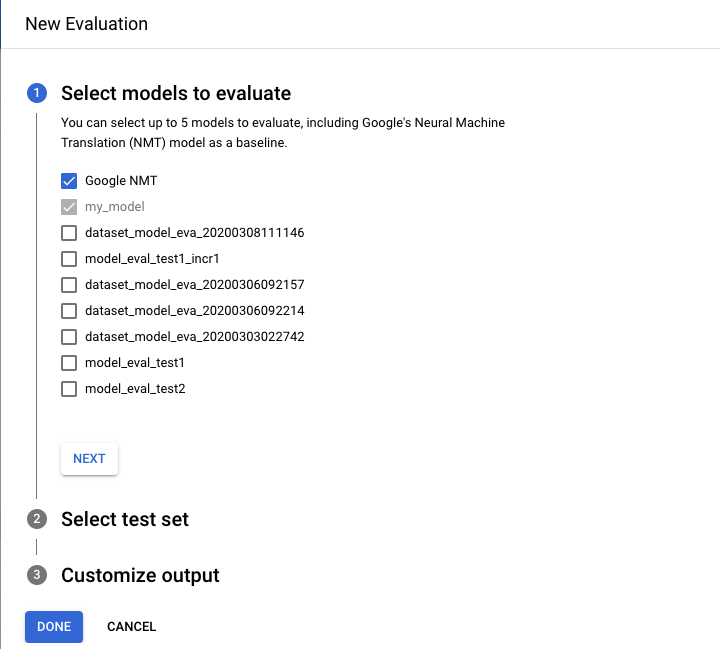
- Wählen Sie die Modelle aus, die Sie bewerten und vergleichen möchten. Das aktuelle Modell muss ausgewählt werden und Google NMÜ ist standardmäßig ausgewählt, was Sie aufheben können.
- Geben Sie einen Namen für den Testsatzname an, damit Sie ihn von anderen Auswertungen unterscheiden können, und wählen Sie dann Ihr neues Test-Dataset aus Cloud Storage aus.
- Wenn Sie die auf Ihrem Test-Dataset basierenden Vorhersagen exportieren möchten, geben Sie einen Cloud Storage-Bucket an, in dem die Ergebnisse gespeichert werden (Standard pro Zeichenrate). Preise gelten.
Klicken Sie auf Fertig.
Nachdem die Bewertung abgeschlossen ist, werden in AutoML Console die Bewertungsergebnisse in einem Tabellenformat in einer Tabelle angezeigt. Es kann immer nur eine Bewertung gleichzeitig ausgeführt werden. Wenn Sie einen Bucket zum Speichern von Vorhersageergebnissen angegeben haben, schreibt AutoML Translation Dateien mit dem Namen model-name _ test-set-name
.tsvin den Bucket.
Hintergrundinformationen zum BLEU-Score
BLEU (BiLingual Evaluation Understudy) ist ein Messverfahren für die automatische Bewertung von maschinell übersetzten Texten. Der BLEU-Score ist eine Zahl zwischen null und eins, die die Ähnlichkeit des maschinenübersetzten Textes mit einer Reihe von Referenzübersetzungen hoher Qualität misst. Der Wert 0 bedeutet, dass die maschinell übersetzte Ausgabe keinerlei Übereinstimmung mit der Referenzübersetzung hat (niedrige Qualität). Der Wert 1 hingegen bedeutet, dass die maschinelle Übersetzung vollkommen deckungsgleich mit den Referenzübersetzungen ist (hohe Qualität).
Es konnte nachgewiesen werden, dass BLEU-Werte gut mit der Beurteilung der Übersetzungsqualität durch Menschen korrelieren. Beachten Sie im Übrigen, dass selbst menschliche Übersetzer normalerweise nicht den Bestwert 1,0 erreichen.
AutoML gibt BLEU-Werte als Prozentsatz und nicht als Dezimalzahl zwischen 0 und 1 an.
Interpretation
Es wird dringend davon abgeraten, BLEU-Werte über verschiedene Korpora und Sprachen hinweg zu vergleichen. Auch der Vergleich der BLEU-Werte für denselben Korpus, aber mit einer abweichenden Anzahl von Referenzübersetzungen, kann sehr irreführend sein.
Als grobe Richtlinie kann jedoch die folgende Interpretation der BLEU-Werte hilfreich sein (angegeben in Prozent statt als Dezimalzahlen).
| BLEU-Wert | Interpretation |
|---|---|
| < 10 | Fast unbrauchbar |
| 10–19 | Schwierig, das Wesentliche zu verstehen |
| 20–29 | Das Wesentliche ist verständlich, aber es gibt erhebliche Grammatikfehler |
| 30–40 | Verständliche bis gute Übersetzungen |
| 40–50 | Hochwertige Übersetzungen |
| 50–60 | Sehr hochwertige, adäquate und flüssige Übersetzungen |
| > 60 | Qualität oft besser als menschliche Übersetzungen |
Der folgende Farbverlauf kann als generelle Skala zur Interpretation des BLEU-Scores verwendet werden.

Die mathematischen Details
Mathematisch gesehen wird der BLEU-Score so definiert:
mit
\[ precision_i = \dfrac{\sum_{\text{snt}\in\text{Cand-Corpus}}\sum_{i\in\text{snt}}\min(m^i_{cand}, m^i_{ref})} {w_t^i = \sum_{\text{snt'}\in\text{Cand-Corpus}}\sum_{i'\in\text{snt'}} m^{i'}_{cand}} \]
Wobei Folgendes gilt:
- \(m_{cand}^i\hphantom{xi}\) ist die Anzahl der i-Gramme für den Kandidaten, die mit der Referenzübersetzung übereinstimmen
- \(m_{ref}^i\hphantom{xxx}\) ist die Anzahl der i-Gramme in der Referenzübersetzung
- \(w_t^i\hphantom{m_{max}}\) ist die Gesamtzahl der i-Gramme in der Kandidatenübersetzung
Die Formel besteht aus zwei Teilen: dem Abzug für die Kürze und der N-Gramm-Übereinstimmung.
Abzug für die Kürze
Der Abzug für die Kürze bestraft generierte Übersetzungen, die verglichen mit der ähnlichsten Referenzlänge exponentiell abnehmend zu kurz sind. Der Abzug für die Kürze kompensiert die Tatsache, dass der BLEU-Score keinen Term für Recall hat.N-Gramm-Übereinstimmung
Die N-Gramm-Übereinstimmung zählt, wie viele Unigramme, Bigramme, Trigramme und Tetragramme (i = 1, ..., 4) mit ihrem N-Gramm-Gegenstück in den Referenzübersetzungen übereinstimmen. Über die N-Gramm-Übereinstimmung wird die Genauigkeit (Precision) der Übersetzung gemessen. Unigramme ermitteln die Adäquatheit, längere N-Gramme die Flüssigkeit der Übersetzung. Zur Vermeidung einer unnötigen Zählung wird die n-Gramm-Zählung auf die maximale n-Gramm-Anzahl begrenzt, die in der Referenz auftritt (\(m_{ref}^n\)).
Beispiele
\(precision_1\)berechnen
Betrachten Sie folgenden Referenzsatz und den Kandidaten für die Übersetzung:
Referenz: the cat is on the mat
Kandidat: the the the cat mat
Im ersten Schritt wird berechnet, wie oft die einzelnen Unigramme jeweils in der Referenzübersetzung und in der Kandidatenübersetzung vorkommen. Beachten Sie, dass für den BLEU-Score zwischen Groß- und Kleinschreibung unterschieden wird.
| Unigramm | \(m_{cand}^i\hphantom{xi}\) | \(m_{ref}^i\hphantom{xxx}\) | \(\min(m^i_{cand}, m^i_{ref})\) |
|---|---|---|---|
the |
3 | 2 | 2 |
cat |
1 | 1 | 1 |
is |
0 | 1 | 0 |
on |
0 | 1 | 0 |
mat |
1 | 1 | 1 |
Die Gesamtzahl der Unigramme für den Kandidaten (\(w_t^1\)) beträgt 5, also gilt \(precision_1\) = (2 + 1 + 1)/5 = 0,8.
Berechnung des BLEU-Scores
Referenz:
The NASA Opportunity rover is battling a massive dust storm on Mars .
Kandidat 1:
The Opportunity rover is combating a big sandstorm on Mars .
Kandidat 2:
A NASA rover is fighting a massive storm on Mars .
Das Beispiel oben besteht aus einer Referenz- und zwei Kandidatenübersetzungen. Die Sätze werden vor dem Berechnen der BLEU-Scores, wie oben dargestellt, tokenisiert; beispielsweise wird der abschließende Punkt als separates Token gezählt.
Wir stellen die folgenden Statistikwerte fest, um den BLEU-Score für jede der beiden Übersetzungen zu berechnen.
- N-Gramm-Genauigkeit
Die folgende Tabelle enthält die N-Gramm-Genauigkeit für beide Kandidaten. - Abzug für die Kürze
Der Abzug für die Kürze ist für Kandidat 1 und Kandidat 2 identisch, da beide Sätze aus elf Tokens bestehen. - BLEU-Score
Es ist mindestens ein übereinstimmendes Tetragramm erforderlich, um einen BLEU-Wert > 0 zu erhalten. Da die Kandidatenübersetzung 1 kein übereinstimmendes Tetragramm aufweist, hat sie den BLEU-Wert 0.
| Messgröße | Kandidat 1 | Kandidat 2 |
|---|---|---|
| \(precision_1\) (1gram) | 8/11 | 9/11 |
| \(precision_2\) (2gram) | 4/10 | 5/10 |
| \(precision_3\) (3gram) | 2/9 | 2/9 |
| \(precision_4\) (4gram) | 0/8 | 1/8 |
| Abzug für die Kürze | 0,83 | 0,83 |
| BLEU-Score | 0,0 | 0,27 |
Attribute
BLEU ist ein Corpus-basierter Messwert
BLEU als Messverfahren funktioniert schlecht, wenn es zum Bewerten einzelner Sätze verwendet wird. So erhalten die beiden Beispielsätze sehr niedrige BLEU-Werte, obwohl sie den größten Teil der Bedeutung erfassen. Aufgrund der niedrigen Aussagekraft der N-Gramm-Statistik für einzelne Sätze ist BLEU ein korpusbasierter Messwert. Das heißt, zur Berechnung des Ergebnisses werden Statistikwerte über ein gesamtes Korpus gesammelt. Achten Sie daher darauf, dass das oben definierte BLEU-Messverfahren für einzelne Sätze nicht faktorisiert werden kann.Keine Unterscheidung zwischen Inhalts- und Funktionswörtern
Das BLEU-Messverfahren unterscheidet nicht zwischen Inhalts- und Funktionswörtern, das heißt, dass ein ausgelassenes Funktionswort wie "ein" zum gleichen Abzug führt wie die fälschliche Ersetzung des Namens "NASA" durch "ESA".Schwach in der Erfassung von Bedeutung und Grammatik eines Satzes
Das Auslassen eines einzelnen Wortes wie "nicht" kann die Polarität eines ganzen Satzes ändern. Und wenn nur N-Gramme mit n ≤ 4 berücksichtigt werden, werden weiterreichende Abhängigkeiten ignoriert, sodass BLEU oft nur einen geringen Abzug für grammatisch falsche Sätze vornimmt.Normalisierung und Tokenisierung
Vor der Berechnung des BLEU-Scores werden sowohl die Referenz- als auch die Kandidatenübersetzungen normalisiert und tokenisiert. Die Auswahl der Normalisierungs- und Tokenisierungsschritte hat einen erheblichen Einfluss auf den endgültigen BLEU-Score.