TPU v4
Ce document décrit l'architecture et les configurations compatibles de Cloud TPU v4.
Architecture du système
Chaque puce TPU v4 contient deux TensorCores. Chaque TensorCore possède quatre unités de multiplication de matrices (MXU), une unité vectorielle et une unité scalaire. Le tableau suivant présente les principales spécifications d'un pod TPU v4.
| Principales caractéristiques | Valeurs des pods v4 |
|---|---|
| Calcul maximal par puce | 275 téraflops (bf16 ou int8) |
| Capacité et bande passante de la mémoire HBM2 | 32 Gio, 1 200 Gbit/s |
| Puissance minimale/moyenne/maximale mesurée | 90/170/192 W |
| Taille du pod TPU | 4 096 chips |
| Topologie d'interconnexion | Maillage 3D |
| Calcul maximal par pod | 1,1 exaflops (bf16 ou int8) |
| Bande passante de réduction globale par pod | 1,1 Po/s |
| Bande passante bissectionnelle par pod | 24 To/s |
Le schéma suivant illustre un chip TPU v4.
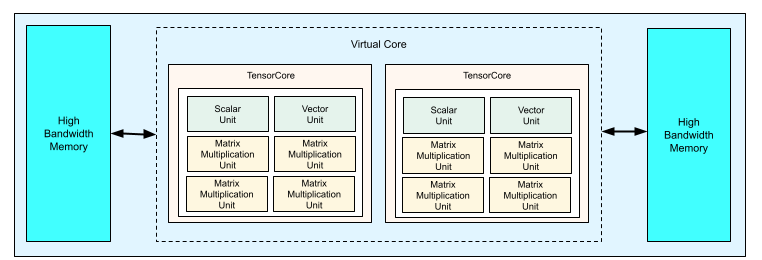
Pour en savoir plus sur les détails d'architecture et les caractéristiques de performances des TPU v4, consultez TPU v4: un supercalculateur optiquement reconfigurable pour le machine learning avec prise en charge matérielle des représentations vectorielles continues.
Maillage 3D et tore 3D
Les TPU v4 sont connectés directement aux puces voisines les plus proches en trois dimensions, ce qui donne un maillage 3D de connexions réseau. Les connexions peuvent être configurées en tant que tore 3D sur des tranches où la topologie, AxBxC, est 2A=B=C ou 2A=2B=C, où chaque dimension est un multiple de 4. Exemples : 4x4x8, 4x8x8 ou 12x12x24. En général, les performances d'une configuration de tore 3D sont meilleures que celles d'une configuration de maillage 3D. Pour en savoir plus, consultez la section Topologies de tores torsadés.
Avantages en termes de performances des TPU v4 par rapport aux TPU v3
Cette section présente une méthode efficace en termes de mémoire pour exécuter un exemple de script d'entraînement sur TPU v4, ainsi que les améliorations de performances de TPU v4 par rapport à TPU v3.
Système de mémoire
L'accès à la mémoire non uniforme (NUMA) est une architecture de mémoire informatique pour les machines dotées de plusieurs processeurs. Chaque processeur dispose d'un accès direct à un bloc de mémoire haute vitesse. Un CPU et sa mémoire sont appelés nœud NUMA. Les nœuds NUMA sont connectés à d'autres nœuds NUMA qui sont directement adjacents les uns aux autres. Un processeur d'un nœud NUMA peut accéder à la mémoire d'un autre nœud NUMA, mais cet accès est plus lent que l'accès à la mémoire d'un nœud NUMA.
Les logiciels exécutés sur une machine multiprocesseur peuvent placer les données dont un processeur a besoin dans son nœud NUMA, ce qui augmente le débit de mémoire. Pour en savoir plus sur NUMA, consultez l'article Non Uniform Memory Access (Accès à la mémoire non uniforme) sur Wikipédia.
Vous pouvez profiter des avantages de la localité NUMA en associant votre script d'entraînement au nœud NUMA 0.
Pour activer la liaison de nœud NUMA:
Installez l'outil de ligne de commande numactl. numactl vous permet d'exécuter des processus avec une stratégie d'ordonnancement ou de placement de mémoire NUMA spécifique.
$ sudo apt-get update $ sudo apt-get install numactl
Liez le code de votre script au nœud NUMA 0. Remplacez your-training-script par le chemin d'accès à votre script d'entraînement.
$ numactl --cpunodebind=0 python3 your-training-script
Activez la liaison de nœud NUMA si:
- Si votre charge de travail dépend fortement des charges de travail du processeur (par exemple, la classification des images, les charges de travail de recommandation), quel que soit le framework.
- Si vous utilisez une version d'exécution TPU sans suffixe "-pod" (par exemple,
tpu-vm-tf-2.10.0-v4).
Autres différences entre les systèmes de mémoire:
- Les puces TPU v4 disposent d'un espace de mémoire HBM unifié de 32 Gio sur l'ensemble de la puce, ce qui permet une meilleure coordination entre les deux TensorCores intégrés.
- Amélioration des performances de la mémoire HBM grâce aux dernières normes et vitesses de mémoire.
- Profil de performances DMA amélioré avec prise en charge intégrée de la segmentation hautes performances avec une granularité de 512 octets.
Tensor Cores
- Doublement du nombre de MXU et fréquence d'horloge plus élevée pour 275 TFLOPS de puissance maximale.
- Bande passante de transposition et de permutation x2.
- Modèle d'accès à la mémoire de chargement-stockage pour la mémoire commune (Cmem).
- Bande passante de chargement des poids MXU plus rapide et prise en charge du mode 8 bits pour réduire les tailles de lot et améliorer la latence d'inférence.
Interconnexion entre puces
Six liaisons d'interconnexion par puce pour permettre des topologies réseau de diamètre plus petit.
Autre
- Interface PCIe 3.0 x16 vers l'hôte (connexion directe).
- Modèle de sécurité amélioré
- Amélioration de l'efficacité énergétique
Configurations
Un pod TPU v4 est composé de 4 096 puces interconnectées par des liaisons haut débit reconfigurables. La flexibilité du réseau TPU v4 vous permet de connecter les puces d'une tranche de même taille de différentes manières. Lorsque vous créez une tranche TPU, vous devez indiquer la version de TPU et le nombre de ressources TPU dont vous avez besoin. Lorsque vous créez une tranche TPU v4, vous pouvez spécifier son type et sa taille de deux manières : AcceleratorType et AccleratorConfig.
Utiliser AcceleratorType
Utilisez AcceleratorType lorsque vous ne spécifiez pas de topologie. Pour configurer des TPU v4 à l'aide de AcceleratorType, utilisez l'option --accelerator-type lorsque vous créez votre tranche TPU. Définissez --accelerator-type sur une chaîne contenant la version du TPU et le nombre de TensorCores que vous souhaitez utiliser. Par exemple, pour créer une tranche v4 avec 32 TensorCores, vous devez utiliser --accelerator-type=v4-32.
Utilisez la commande gcloud compute tpus tpu-vm create pour créer une tranche TPU v4 avec 512 TensorCores à l'aide de l'option --accelerator-type:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --accelerator-type=v4-512 \ --version=tpu-ubuntu2204-base
Le nombre qui suit la version du TPU (v4) indique le nombre de TensorCores.
Un TPU v4 contient deux TensorCores. Le nombre de puces TPU est donc de 512/2 = 256.
Pour en savoir plus sur la gestion des TPU, consultez Gérer les TPU. Pour en savoir plus sur l'architecture système de Cloud TPU, consultez la page Architecture du système.
Utiliser AcceleratorConfig
Utilisez AcceleratorConfig lorsque vous souhaitez personnaliser la topologie physique de votre tranche de TPU. Cela est généralement nécessaire pour le réglage des performances avec des tranches de plus de 256 chips.
Pour configurer des TPU v4 à l'aide de AcceleratorConfig, utilisez les options --type et --topology. Définissez --type sur la version de TPU que vous souhaitez utiliser et --topology sur la disposition physique des puces de TPU dans la tranche.
Vous spécifiez une topologie TPU à l'aide d'un triplet AxBxC, où A <= B <= C et A, B et C sont tous inférieurs ou égaux à 4 ou sont tous des multiples entiers de 4. Les valeurs A, B et C correspondent au nombre de puces dans chacune des trois dimensions. Par exemple, pour créer une tranche v4 avec 16 puces, vous devez définir --type=v4 et --topology=2x2x4.
Utilisez la commande gcloud compute tpus tpu-vm create pour créer une tranche de TPU v4 avec 128 puces TPU disposées dans un tableau 4x4x8:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --type=v4 \ --topology=4x4x8 \ --version=tpu-ubuntu2204-base
Les variantes de topologie optimisées pour la communication de type "tous à tous" (par exemple, 4 × 4 × 8, 8 × 8 × 16 et 12 × 12 × 24) sont également disponibles pour les topologies où 2A=B=C ou 2A=2B=C. Il s'agit des topologies torus torsadés.
Les illustrations suivantes présentent certaines topologies TPU v4 courantes.
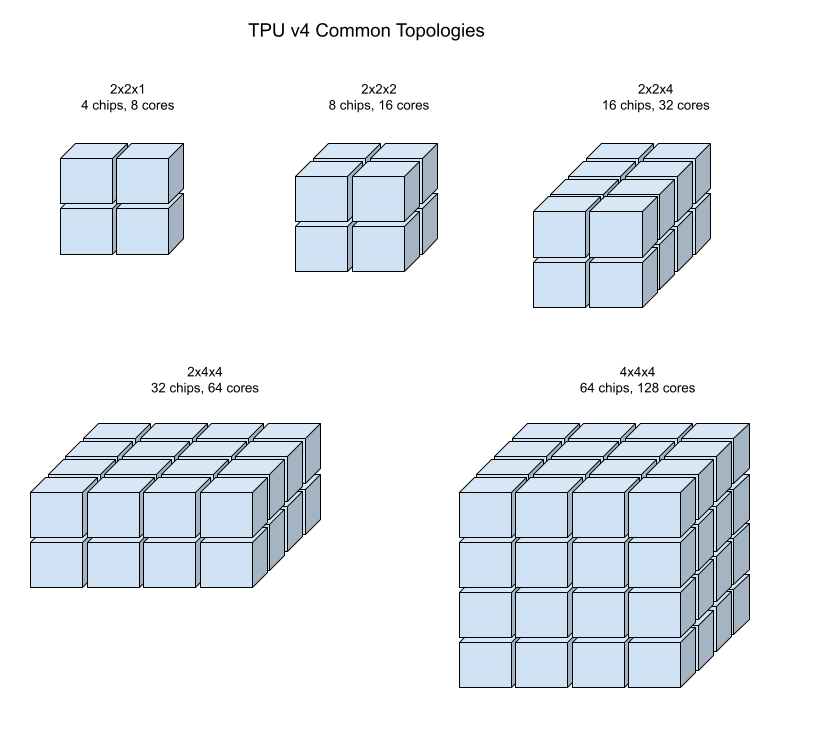
Vous pouvez créer des tranches plus grandes à partir d'un ou de plusieurs "cubes" de chips de 4 x 4 x 4.
Pour en savoir plus sur la gestion des TPU, consultez Gérer les TPU. Pour en savoir plus sur l'architecture système de Cloud TPU, consultez la page Architecture du système.
Topologies de tores torsadés
Certaines formes de tranche de tore 3D v4 peuvent utiliser ce que l'on appelle une topologie de torus torsadé. Par exemple, deux cubes v4 peuvent être disposés en tranche 4x4x8 ou 4x4x8_twisted. Les topologies torsadées offrent une bande passante de bisection nettement plus élevée. Par exemple, une tranche avec la topologie 4x4x8_twisted offre une augmentation théorique de 70 % de la bande passante de bisection par rapport à une tranche 4x4x8 non torsadée. Une bande passante de bisection accrue est utile pour les charges de travail qui utilisent des modèles de communication globaux. Les topologies en hélice peuvent améliorer les performances de la plupart des modèles, en particulier pour les charges de travail d'encapsulation TPU de grande envergure.
Pour les charges de travail qui utilisent le parallélisme des données comme seule stratégie de parallélisme, les topologies torsadées peuvent être légèrement plus performantes. Pour les LLM, les performances utilisant une topologie en hélice peuvent varier en fonction du type de parallélisme (DP, MP, etc.). Il est recommandé d'entraîner votre LLM avec et sans topologie torsadée pour déterminer laquelle offre les meilleures performances pour votre modèle. Certains tests sur le modèle MaxText FSDP ont permis d'obtenir une amélioration de 1 à 2 MFU à l'aide d'une topologie torsadée.
L'avantage principal des topologies torsadées est qu'elles transforment une topologie de tore asymétrique (par exemple, 4 × 4 × 8) en une topologie symétrique étroitement liée. La topologie symétrique présente de nombreux avantages:
- Amélioration de l'équilibrage de charge
- Bande passante bissectionnelle plus élevée
- Itinéraires de paquets plus courts
Ces avantages se traduisent finalement par de meilleures performances pour de nombreux modèles de communication globaux.
Le logiciel TPU est compatible avec les tores torsadés sur des tranches dont la taille de chaque dimension est égale ou double de celle de la plus petite dimension. Par exemple, 4x4x8, 4×8×8 ou 12x12x24.
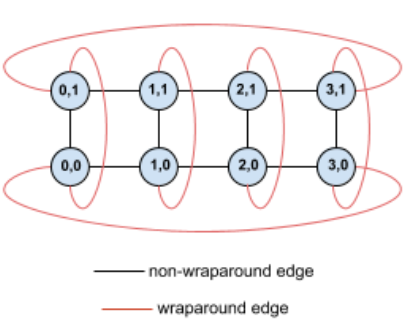
Prenons l'exemple de cette topologie de tore 4x2 avec des TPU étiquetés avec leurs coordonnées (X,Y) dans la tranche:
Pour plus de clarté, les arêtes de ce graphique de topologie sont représentées comme des arêtes non orientées. En pratique, chaque arête est une connexion bidirectionnelle entre les TPU. Nous appelons les bords entre un côté de cette grille et l'autre des bords en boucle, comme indiqué dans le diagramme.
En tordant cette topologie, nous obtenons une topologie de tore torsadé 4 x 2 complètement symétrique:
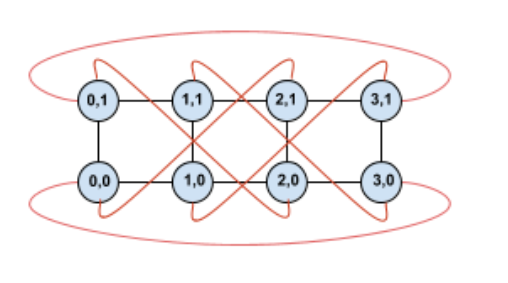
La seule chose qui a changé entre ce diagramme et le précédent est les bords de retour en arrière en Y. Au lieu de se connecter à un autre TPU avec la même coordonnée X, ils ont été décalés pour se connecter au TPU avec la coordonnée X+2 mod 4.
Le même principe s'applique à différentes tailles de dimensions et à différents nombres de dimensions. Le réseau obtenu est symétrique, à condition que chaque dimension soit égale ou deux fois plus grande que la plus petite.
Pour savoir comment spécifier une configuration de tore torsadé lors de la création d'un Cloud TPU, consultez la section Utiliser AcceleratorConfig.
Le tableau suivant présente les topologies torsadées compatibles et une augmentation théorique de la bande passante de bisection avec elles par rapport aux topologies non torsadées.
| Topologie en paires torsadées | Augmentation théorique de la bande passante de la bisection par rapport à un tore non torsadé |
|---|---|
| 4×4×8_twisted | ~70% |
| 8x8x16_twisted | |
| 12×12×24_twisted | |
| 4×8×8_twisted | ~40% |
| 8×16×16_twisted |
Variantes de topologie TPU v4
Certaines topologies contenant le même nombre de puces peuvent être organisées de différentes manières. Par exemple, une tranche TPU avec 512 puces (1 024 TensorCores) peut être configurée à l'aide des topologies suivantes: 4x4x32, 4x8x16 ou 8x8x8. Une tranche TPU avec 2 048 puces (4 096 TensorCores) offre encore plus d'options de topologie: 4x4x128, 4x8x64, 4x16x32 et 8x16x16.
La topologie par défaut associée à un nombre de puces donné est celle qui ressemble le plus à un cube. Cette forme est probablement le meilleur choix pour l'entraînement de ML en parallélisme de données. D'autres topologies peuvent être utiles pour les charges de travail comportant plusieurs types de parallélisme (par exemple, le parallélisme des modèles et des données, ou le partitionnement spatial d'une simulation). Ces charges de travail fonctionnent mieux si la topologie correspond au parallélisme utilisé. Par exemple, placer un parallélisme de modèle à quatre voies sur la dimension X et un parallélisme de données à 256 voies sur les dimensions Y et Z correspond à une topologie 4x16x16.
Les modèles avec plusieurs dimensions de parallélisme fonctionnent mieux lorsque leurs dimensions de parallélisme sont mappées sur les dimensions de topologie TPU. Il s'agit généralement de grands modèles de langage (LLM) parallèles aux données et au modèle. Par exemple, pour une tranche TPU v4 avec une topologie 8x16x16, les dimensions de la topologie TPU sont 8, 16 et 16. Il est plus performant d'utiliser un parallélisme de modèle à 8 ou 16 cœurs (mappé sur l'une des dimensions de la topologie TPU physique). Un parallélisme de modèle à quatre voies serait sous-optimal avec cette topologie, car il n'est aligné sur aucune des dimensions de la topologie TPU, mais il serait optimal avec une topologie 4x16x32 sur le même nombre de puces.
Les configurations TPU v4 se composent de deux groupes : ceux dont les topologies sont inférieures à 64 puces (petites topologies) et ceux dont les topologies sont supérieures à 64 puces (grandes topologies).
Petites topologies v4
Cloud TPU est compatible avec les tranches TPU v4 suivantes de moins de 64 puces, soit un cube 4x4x4. Vous pouvez créer ces petites topologies v4 à l'aide de leur nom basé sur TensorCore (par exemple, v4-32) ou de leur topologie (par exemple, 2x2x4):
| Nom (en fonction du nombre de TensorCore) | Nombre de puces | Topologie |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
Grandes topologies v4
Les tranches TPU v4 sont disponibles par tranches de 64 puces, avec des formes multiples de 4 dans les trois dimensions. Les dimensions doivent être triées par ordre croissant. Vous trouverez plusieurs exemples dans le tableau suivant. Certaines de ces topologies sont des topologies "personnalisées" qui ne peuvent être créées qu'à l'aide des indicateurs --type et --topology, car il existe plusieurs façons d'organiser les puces.
| Nom (en fonction du nombre de TensorCore) | Nombre de puces | Topologie |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
topologie personnalisée: vous devez utiliser les options --type et --topology |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1 024 | 8x8x16 |
topologie personnalisée: vous devez utiliser les options --type et --topology |
1 024 | 4x16x16 |
| v4-4096 | 2 048 | 8x16x16 |
| … | … | … |