Panoramica di Cloud TPU Multislice
Cloud TPU Multislice è una tecnologia di scalabilità delle prestazioni full stack che consente a un job di addestramento di utilizzare più slice TPU all'interno di un singolo slice o su slice in più pod con parallelismo dei dati standard. Con i chip TPU v4, ciò significa che i job di addestramento possono utilizzare più di 4096 chip in una singola esecuzione. Per i job di addestramento che richiedono meno di 4096 chip, una singola sezione può offrire le prestazioni migliori. Tuttavia, sono disponibili più facilmente più segmenti più piccoli, il che consente un tempo di avvio più rapido quando Multislice viene utilizzato con segmenti più piccoli.
Quando vengono implementati in configurazioni multislice, i chip TPU in ogni slice comunicano tramite inter-chip-interconnect (ICI). I chip TPU in sezioni diverse comunicano trasferendo i dati alle CPU (host), che a loro volta trasmettono i dati tramite la rete del data center (DCN). Per ulteriori informazioni sulla scalabilità con Multislice, consulta Come scalare l'addestramento dell'AI fino a decine di migliaia di chip Cloud TPU con Multislice.
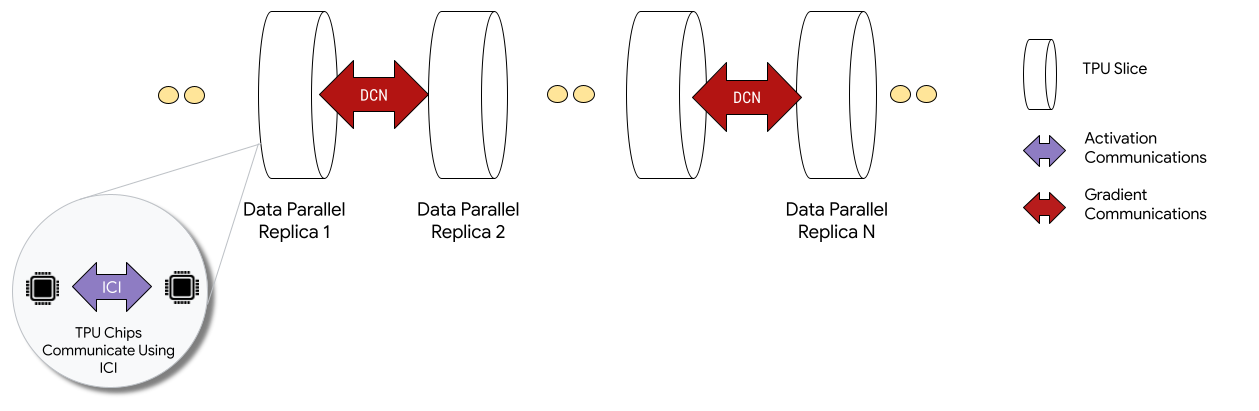
Gli sviluppatori non devono scrivere codice per implementare la comunicazione DCN tra slice. Il compilatore XLA genera questo codice per te e sovrappone la comunicazione al calcolo per ottenere le massime prestazioni.
Concetti
- Tipo di acceleratore
- La forma di ogni sezione TPU
che compone un multislice. Ogni slice in una
richiesta multislice è dello stesso tipo di acceleratore. Un tipo di acceleratore
è costituito da un tipo di TPU (v4 o versioni successive) seguito dal numero di TensorCore.
Ad esempio,
v5litepod-128specifica una TPU v5e con 128 TensorCore. - Riparazione automatica
- Quando uno slice incontra un evento di manutenzione, un'interruzione o un guasto hardware, Cloud TPU creerà un nuovo slice. Se non ci sono risorse sufficienti per creare una nuova sezione, la creazione non verrà completata finché l'hardware non sarà disponibile. Dopo la creazione della nuova sezione, tutte le altre sezioni nell'ambiente Multislice verranno riavviate in modo che l'addestramento possa continuare. Con uno script di avvioconfigurato correttamente, lo script di addestramento può essere riavviato automaticamente senza l'intervento dell'utente, caricando e riprendendo dall'ultimo checkpoint.
- Data Center Networking (DCN)
- Una rete con latenza più elevata e throughput inferiore (rispetto a ICI) che connette le sezioni TPU in una configurazione multisezione.
- Pianificazione di gruppo
- Quando tutte le sezioni TPU vengono sottoposte al provisioning contemporaneamente, garantendo che tutte o nessuna delle sezioni vengano sottoposte al provisioning correttamente.
- Interconnessione interchip (ICI)
- Collegamenti interni ad alta velocità e bassa latenza che connettono le TPU all'interno di un pod TPU.
- Multislice
- Due o più sezioni di chip TPU che possono comunicare tramite DCN.
- Nodo
- Nel contesto di Multislice, il nodo si riferisce a una singola sezione TPU. A ogni slice TPU in un Multislice viene assegnato un ID nodo.
- Script di avvio
- Uno script di avvio di Compute Engine standard che viene eseguito ogni volta che una VM viene avviata o riavviata. Per Multislice, viene specificato nella richiesta di creazione del QR. Per saperne di più sugli script di avvio di Cloud TPU, consulta Gestire le risorse TPU.
- Tensor
- Una struttura di dati utilizzata per rappresentare dati multidimensionali in un modello di machine learning.
- Tipi di capacità Cloud TPU
Le TPU possono essere create da diversi tipi di capacità (vedi Opzioni di utilizzo in Come funziona il prezzo delle TPU):
Prenotazione: per utilizzare una prenotazione, devi disporre di un contratto di prenotazione con Google. Utilizza il flag
--reserveddurante la creazione delle risorse.Spot: ha come target la quota prerilasciabile utilizzando le VM spot. Le tue risorse potrebbero essere preempted per fare spazio alle richieste di un job con priorità più alta. Utilizza il flag
--spotdurante la creazione delle risorse.On demand: ha come target la quota on demand, che non richiede una prenotazione e non verrà interrotta. La richiesta TPU verrà inserita in una coda di quote on demand offerta da Cloud TPU, la disponibilità delle risorse non è garantita. Selezionato per impostazione predefinita, non sono necessari flag.
Inizia
Configura l'ambiente Cloud TPU.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
ici_data_parallelismici_fsdp_parallelismici_tensor_parallelismConfigura l'ambiente:
$ gcloud auth login $ export QR_ID=your-queued-resource-id $ export TPU_NAME=your-tpu-name $ export PROJECT=your-project-name $ export ZONE=us-central1-a $ export NETWORK_NAME=your-network-name $ export SUBNETWORK_NAME=your-subnetwork-name $ export RUNTIME_VERSION=v2-alpha-tpuv5-lite $ export ACCELERATOR_TYPE=v5litepod-16 $ export EXAMPLE_TAG_1=your-tag-1 $ export EXAMPLE_TAG_2=your-tag-2 $ export SLICE_COUNT=4 $ export STARTUP_SCRIPT='#!/bin/bash\n'
Descrizioni delle variabili
Input Descrizione QR_ID L'ID assegnato dall'utente della risorsa in coda. TPU_NAME Il nome assegnato dall'utente della tua TPU. PROGETTO Google Cloud nome progetto ZONE Specifica la zona in cui creare le risorse. NETWORK_NAME Nome delle reti VPC. SUBNETWORK_NAME Nome della subnet nelle reti VPC RUNTIME_VERSION La versione software Cloud TPU. ACCELERATOR_TYPE v4-16 EXAMPLE_TAG_1, EXAMPLE_TAG_2 … Tag utilizzati per identificare origini o destinazioni valide per i firewall di rete SLICE_COUNT Numero di sezioni. Limite massimo di 256 segmenti. STARTUP_SCRIPT Se specifichi uno script di avvio, lo script viene eseguito quando lo slice TPU viene sottoposto a provisioning o riavviato. Crea chiavi SSH per
gcloud. Ti consigliamo di lasciare una password vuota (premi Invio due volte dopo aver eseguito il seguente comando). Se viene visualizzato un messaggio che indica che il filegoogle_compute_engineesiste già, sostituisci la versione esistente.$ ssh-keygen -f ~/.ssh/google_compute_engine
Esegui il provisioning delle TPU:
gcloud
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-id=${TPU_NAME} \ --zone=${ZONE} \ [--reserved |--spot]
Google Cloud CLI non supporta tutte le opzioni di creazione di QR, ad esempio i tag. Per saperne di più, vedi Creare QR.
Console
Nella console Google Cloud , vai alla pagina TPU:
Fai clic su Crea TPU.
Nel campo Nome, inserisci un nome per la TPU.
Nella casella Zona, seleziona la zona in cui vuoi creare la TPU.
Nella casella Tipo di TPU, seleziona un tipo di acceleratore. Il tipo di acceleratore specifica la versione e le dimensioni della Cloud TPU che vuoi creare. Per saperne di più sui tipi di acceleratore supportati per ogni versione di TPU, consulta Versioni di TPU.
Nella casella Versione software TPU, seleziona una versione software. Quando crei una VM Cloud TPU, la versione del software TPU specifica la versione del runtime TPU da installare. Per maggiori informazioni, vedi Versioni software TPU.
Fai clic sul pulsante di attivazione/disattivazione Attiva la messa in coda.
Nel campo Queued resource name (Nome risorsa in coda), inserisci un nome per la richiesta di risorsa in coda.
Fai clic su Crea per creare la richiesta di risorse in coda.
Attendi che la risorsa in coda sia nello stato
ACTIVE, il che significa che i nodi worker sono nello statoREADY. Una volta avviato il provisioning delle risorse in coda, potrebbero essere necessari da 1 a 5 minuti per il completamento, a seconda delle dimensioni della risorsa in coda. Puoi controllare lo stato di una richiesta di risorse in coda utilizzando gcloud CLI o la console Google Cloud :gcloud
$ gcloud compute tpus queued-resources \ list --filter=${QR_ID} --zone=${ZONE}
Console
Nella console Google Cloud , vai alla pagina TPU:
Fai clic sulla scheda Risorse in coda.
Fai clic sul nome della richiesta di risorsa in coda.
Connettiti alla VM TPU utilizzando SSH:
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} --zone=${ZONE}
Clona MaxText (che include
shardings.py) nella tua VM TPU:$ git clone https://github.com/AI-Hypercomputer/maxtext && cd maxtext
Installa Python 3.10:
$ sudo apt-get update $ sudo apt install python3.10 $ sudo apt install python3.10-venv
Crea e attiva un ambiente virtuale:
$ python3 -m venv your-venv-name $ source your-venv-name/bin/activate
Nella directory del repository MaxText, esegui lo script di configurazione per installare JAX e altre dipendenze sulla tua slice TPU. L'esecuzione dello script di configurazione richiede alcuni minuti.
$ bash setup.sh
Esegui questo comando per eseguire
shardings.pysulla tua slice TPU.$ python3 -m pedagogical_examples.shardings \ --ici_fsdp_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Puoi visualizzare i risultati nei log. Le TPU dovrebbero raggiungere circa 260 TFLOP al secondo o un utilizzo impressionante di oltre il 90%dei FLOP. In questo caso, abbiamo selezionato approssimativamente il batch massimo che rientra nella memoria ad alta larghezza di banda (HBM) della TPU.
Non esitare a esplorare altre strategie di partizionamento su ICI. Ad esempio, puoi provare la seguente combinazione:
$ python3 -m pedagogical_examples.shardings \ --ici_tensor_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Al termine, elimina la risorsa in coda e lo slice TPU. Devi eseguire questi passaggi di pulizia dall'ambiente in cui hai configurato lo slice (esegui prima
exitper uscire dalla sessione SSH). L'eliminazione richiede da due a cinque minuti. Se utilizzi gcloud CLI, puoi eseguire questo comando in background con il flag facoltativo--async.gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --force (--async)
Console
Nella console Google Cloud , vai alla pagina TPU:
Fai clic sulla scheda Risorse in coda.
Seleziona la casella di controllo accanto alla richiesta di risorse in coda.
Fai clic su Elimina.
- dcn_data_parallelism
- dcn_fsdp_parallelism
- dcn_tensor_parallelism
Clona MaxText sulla macchina runner:
$ git clone https://github.com/AI-Hypercomputer/maxtext
Vai alla directory del repository.
$ cd maxtext
Crea chiavi SSH per
gcloud. Ti consigliamo di lasciare una password vuota (premi INVIO due volte dopo aver eseguito il seguente comando). Se viene visualizzato un messaggio che indica che il filegoogle_compute_engineesiste già, scegli di non mantenere la versione esistente.$ ssh-keygen -f ~/.ssh/google_compute_engine
Aggiungi una variabile di ambiente per impostare il conteggio delle sezioni TPU su
2.$ export SLICE_COUNT=2
Crea un ambiente Multislice utilizzando il comando
queued-resources createo la console Google Cloud .gcloud
Il seguente comando mostra come creare una TPU multislice v5e. Per utilizzare una versione TPU diversa, specifica un
accelerator-typee unruntime-versiondiversi.$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-count=${SLICE_COUNT} \ --node-prefix=${TPU_NAME} \ --zone=${ZONE} \ [--reserved|--spot]
Console
Nella console Google Cloud , vai alla pagina TPU:
Fai clic su Crea TPU.
Nel campo Nome, inserisci un nome per la TPU.
Nella casella Zona, seleziona la zona in cui vuoi creare la TPU.
Nella casella Tipo di TPU, seleziona un tipo di acceleratore. Il tipo di acceleratore specifica la versione e le dimensioni della Cloud TPU che vuoi creare. Multislice è supportato solo su Cloud TPU v4 e versioni successive di TPU. Per maggiori informazioni sulle versioni di TPU, consulta la sezione Versioni di TPU.
Nella casella Versione software TPU, seleziona una versione software. Quando crei una VM Cloud TPU, la versione software TPU specifica la versione del runtime TPU da installare sulle VM TPU. Per maggiori informazioni, vedi Versioni software delle TPU.
Fai clic sul pulsante di attivazione/disattivazione Attiva la messa in coda.
Nel campo Queued resource name (Nome risorsa in coda), inserisci un nome per la richiesta di risorsa in coda.
Fai clic sulla casella di controllo Rendi questa TPU multislice.
Nel campo Conteggio slice, inserisci il numero di slice che vuoi creare.
Fai clic su Crea per creare la richiesta di risorse in coda.
Quando inizia il provisioning della risorsa in coda, il completamento può richiedere fino a cinque minuti, a seconda delle dimensioni della risorsa. Attendi che la risorsa in coda sia nello stato
ACTIVE. Puoi controllare lo stato di una richiesta di risorse in coda utilizzando gcloud CLI o la console Google Cloud :gcloud
$ gcloud compute tpus queued-resources list \ --filter=${QR_ID} --zone=${ZONE} --project=${PROJECT}
In questo modo dovrebbe essere generato un output simile al seguente:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central2-b 4 v5litepod-16 ACTIVE ...
Console
Nella console Google Cloud , vai alla pagina TPU:
Fai clic sulla scheda Risorse in coda.
Fai clic sul nome della richiesta di risorsa in coda.
Contatta il tuo Google Cloud account representative se lo stato del QR è
WAITING_FOR_RESOURCESoPROVISIONINGper più di 15 minuti.Installa le dipendenze.
$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="bash setup.sh"
Esegui
shardings.pysu ogni worker utilizzandomultihost_runner.py.$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="python3 -m pedagogical_examples.shardings \ --dcn_data_parallelism ${SLICE_COUNT} \ --ici_fsdp_parallelism 16 \ --batch_size 131072 \ --embedding_dimension 2048"
Nei file di log vedrai un rendimento di circa 230 TFLOP al secondo.
Per ulteriori informazioni sulla configurazione del parallelismo, consulta Multislice sharding utilizzando il parallelismo DCN e
shardings.py.Al termine, pulisci le TPU e la risorsa in coda. L'eliminazione richiede da due a cinque minuti. Se utilizzi gcloud CLI, puoi eseguire questo comando in background con il flag facoltativo
--async.- Utilizza jax.experimental.mesh_utils.create_hybrid_device_mesh anziché jax.experimental.mesh_utils.create_device_mesh quando crei la mesh.
- Utilizzando lo script di esecuzione dell'esperimento,
multihost_runner.py - Utilizzando lo script di esecuzione della produzione,
multihost_job.py - Utilizzare un approccio manuale
Crea una richiesta di risorsa in coda utilizzando il seguente comando:
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --project=${PROJECT} \ --zone=${ZONE} \ --node-count=${SLICE_COUNT} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --network=${NETWORK_NAME} \ --subnetwork=${SUBNETWORK_NAME} \ --tags=${EXAMPLE_TAG_1},${EXAMPLE_TAG_2} \ --metadata=startup-script="${STARTUP_SCRIPT}" \ [--reserved|--spot]
Crea un file denominato
queued-resource-req.jsone copia al suo interno il seguente JSON.{ "guaranteed": { "reserved": true }, "tpu": { "node_spec": [ { "parent": "projects/your-project-number/locations/your-zone", "node": { "accelerator_type": "accelerator-type", "runtime_version": "tpu-vm-runtime-version", "network_config": { "network": "your-network-name", "subnetwork": "your-subnetwork-name", "enable_external_ips": true }, "tags" : ["example-tag-1"] "metadata": { "startup-script": "your-startup-script" } }, "multi_node_params": { "node_count": slice-count, "node_id_prefix": "your-queued-resource-id" } } ] } }
Sostituisci i seguenti valori:
- your-project-number - Il numero del tuo progetto Google Cloud
- your-zone: la zona in cui vuoi creare la risorsa in coda
- accelerator-type: la versione e le dimensioni di una singola sezione. Multislice è supportato solo su Cloud TPU v4 e versioni successive di TPU.
- tpu-vm-runtime-version: la versione del runtime della VM TPU che vuoi utilizzare.
- your-network-name - (facoltativo) una rete a cui verrà collegata la risorsa in coda
- your-subnetwork-name - Facoltativo, una subnet a cui verrà collegata la risorsa in coda
- example-tag-1 - Facoltativo, una stringa tag arbitraria
- your-startup-script: uno script di avvio che verrà eseguito quando viene allocata la risorsa in coda
- slice-count: il numero di sezioni TPU nel tuo ambiente multislice
- your-queued-resource-id: l'ID fornito dall'utente per la risorsa in coda
Per saperne di più, consulta la documentazione dell'API REST Queued Resource per tutte le opzioni disponibili.
Per utilizzare la capacità spot, sostituisci:
"guaranteed": { "reserved": true }con"spot": {}Rimuovi la riga per utilizzare la capacità on demand predefinita.
Invia la richiesta di creazione della risorsa in coda con il payload JSON:
$ curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d @queuedresourcereq.json \ https://tpu.googleapis.com/v2alpha1/projects/your-project-id/locations/your-zone/queuedResources\?queued_resource_id\=your-queued-resource-id
Sostituisci i seguenti valori:
- your-project-id - Il tuo ID progetto Google Cloud
- your-zone: la zona in cui vuoi creare la risorsa in coda
- your-queued-resource-id: l'ID fornito dall'utente per la risorsa in coda
Nella console Google Cloud , vai alla pagina TPU:
Fai clic su Crea TPU.
Nel campo Nome, inserisci un nome per la TPU.
Nella casella Zona, seleziona la zona in cui vuoi creare la TPU.
Nella casella Tipo di TPU, seleziona un tipo di acceleratore. Il tipo di acceleratore specifica la versione e le dimensioni della Cloud TPU che vuoi creare. Multislice è supportato solo su Cloud TPU v4 e versioni successive di TPU. Per saperne di più sui tipi di acceleratore supportati per ogni versione di TPU, consulta la pagina Versioni di TPU.
Nella casella Versione software TPU, seleziona una versione software. Quando crei una VM Cloud TPU, la versione del software TPU specifica la versione del runtime TPU da installare. Per maggiori informazioni, vedi Versioni software TPU.
Fai clic sul pulsante di attivazione/disattivazione Attiva la messa in coda.
Nel campo Queued resource name (Nome risorsa in coda), inserisci un nome per la richiesta di risorsa in coda.
Fai clic sulla casella di controllo Rendi questa TPU multislice.
Nel campo Conteggio slice, inserisci il numero di slice che vuoi creare.
Fai clic su Crea per creare la richiesta di risorse in coda.
Nella console Google Cloud , vai alla pagina TPU:
Fai clic sulla scheda Risorse in coda.
Fai clic sul nome della richiesta di risorsa in coda.
Nella console Google Cloud , vai alla pagina TPU:
Fai clic sulla scheda Risorse in coda.
Nella console Google Cloud , vai alla pagina TPU:
Fai clic sulla scheda Risorse in coda.
Seleziona la casella di controllo accanto alla richiesta di risorse in coda.
Fai clic su Elimina.
- B è la dimensione del batch in token
- P è il numero di parametri
- Si verifica la "bolla della pipeline" in cui i chip sono inattivi perché sono in attesa dei dati.
- Richiede il micro-batching, che riduce la dimensione effettiva del batch, l'intensità aritmetica e, in definitiva, l'utilizzo dei FLOP del modello.
Per utilizzare il multislice, le risorse TPU devono essere gestite come risorse in coda.
Esempio introduttivo
Questo tutorial utilizza il codice del repository GitHub di MaxText. MaxText è un LLM di base open source ad alte prestazioni, scalabile in modo arbitrario e ben testato scritto in Python e Jax. MaxText è stato progettato per l'addestramento efficiente su Cloud TPU.
Il codice in shardings.py
è progettato per aiutarti a iniziare a sperimentare con diverse opzioni di parallelismo. Ad esempio, parallelismo dei dati, parallelismo dei dati completamente suddiviso (FSDP)
e parallelismo dei tensori. Il codice viene scalato da ambienti a singola sezione a ambienti multisezione.
Parallelismo ICI
ICI si riferisce all'interconnessione ad alta velocità che collega le TPU in una singola sezione. Lo sharding ICI corrisponde allo sharding all'interno di una sezione. shardings.py
fornisce tre parametri di parallelismo ICI:
I valori specificati per questi parametri determinano il numero di shard per ogni metodo di parallelismo.
Questi input devono essere vincolati in modo che
ici_data_parallelism * ici_fsdp_parallelism * ici_tensor_parallelism sia uguale
al numero di chip nella sezione.
La seguente tabella mostra esempi di input utente per il parallelismo ICI per i quattro chip disponibili in v4-8:
| ici_data_parallelism | ici_fsdp_parallelism | ici_tensor_parallelism | |
| FSDP a 4 vie | 1 | 4 | 1 |
| Parallelismo tensore a 4 vie | 1 | 1 | 4 |
| Parallelismo FSDP bidirezionale + parallelismo dei tensori bidirezionale | 1 | 2 | 2 |
Tieni presente che ici_data_parallelism deve essere lasciato come 1 nella maggior parte dei casi perché la
rete ICI è abbastanza veloce da preferire quasi sempre FSDP al parallelismo dei dati.
Questo esempio presuppone che tu abbia familiarità con l'esecuzione di codice su una singola sezione TPU, ad esempio in Esegui un calcolo su una VM Cloud TPU utilizzando JAX.
Questo esempio mostra come eseguire shardings.py su una singola sezione.
Sharding multislice utilizzando il parallelismo DCN
Lo script shardings.py accetta tre parametri che specificano il parallelismo DCN,
corrispondenti al numero di shard di ogni tipo di parallelismo dei dati:
I valori di questi parametri devono essere vincolati in modo che
dcn_data_parallelism * dcn_fsdp_parallelism * dcn_tensor_parallelism sia uguale
al numero di segmenti.
Ad esempio, per due fette, utilizza --dcn_data_parallelism = 2.
| dcn_data_parallelism | dcn_fsdp_parallelism | dcn_tensor_parallelism | N. di sezioni | |
| Parallelismo dei dati bidirezionale | 2 | 1 | 1 | 2 |
dcn_tensor_parallelism deve essere sempre impostato su 1 perché la DCN non è adatta
a questo tipo di partizionamento. Per i tipici workload LLM sui chip v4,
dcn_fsdp_parallelism deve essere impostato anche su 1 e quindi
dcn_data_parallelism deve essere impostato sul numero di slice, ma questo dipende
dall'applicazione.
Se aumenti il numero di segmenti (supponendo di mantenere costanti le dimensioni del segmento e il batch per segmento), aumenti la quantità di parallelismo dei dati.
Esecuzione di shardings.py in un ambiente Multislice
Puoi eseguire shardings.py in un ambiente multislice utilizzando
multihost_runner.py o eseguendo shardings.py su ogni VM TPU. Qui utilizziamo
multihost_runner.py. I passaggi seguenti sono molto simili a quelli descritti in
Getting Started: Quick Experiments on Multiple slices
del repository MaxText, tranne per il fatto che qui eseguiamo shardings.py anziché
l'LLM più complesso in train.py.
Lo strumento multihost_runner.py è ottimizzato per esperimenti rapidi, riutilizzando ripetutamente le stesse TPU. Poiché lo script multihost_runner.py dipende da
connessioni SSH di lunga durata, non lo consigliamo per job di lunga durata.
Se vuoi eseguire un job più lungo (ad esempio, ore o giorni), ti consigliamo di
utilizzare multihost_job.py.
In questo tutorial, utilizziamo il termine runner per indicare la macchina su cui
esegui lo script multihost_runner.py. Utilizziamo il termine worker per indicare le
VM TPU che compongono le tue sezioni. Puoi eseguire multihost_runner.py su una macchina locale o su qualsiasi VM di Compute Engine nello stesso progetto delle tue sezioni. L'esecuzione di
multihost_runner.py su un worker non è supportata.
multihost_runner.py si connette automaticamente ai worker TPU utilizzando SSH.
In questo esempio, esegui shardings.py su due slice v5e-16, per un totale di quattro VM e 16 chip TPU. Puoi modificare l'esempio per eseguirlo su più TPU.
Configura l'ambiente
Scalare un carico di lavoro a Multislice
Prima di eseguire il modello in un ambiente Multislice, apporta le seguenti modifiche al codice:
Queste dovrebbero essere le uniche modifiche al codice necessarie quando si passa a Multislice. Per ottenere prestazioni elevate, DCN deve essere mappato su assi paralleli ai dati, paralleli ai dati completamente sharded o paralleli alla pipeline. Le considerazioni sul rendimento e le strategie di sharding sono trattate in modo più dettagliato in Sharding con Multislice per il massimo rendimento.
Per verificare che il codice possa accedere a tutti i dispositivi, puoi affermare che
len(jax.devices()) è uguale al numero di chip nell'ambiente Multislice. Ad esempio, se utilizzi quattro fette di v4-16, hai
otto chip per fetta * 4 fette, quindi len(jax.devices()) dovrebbe restituire 32.
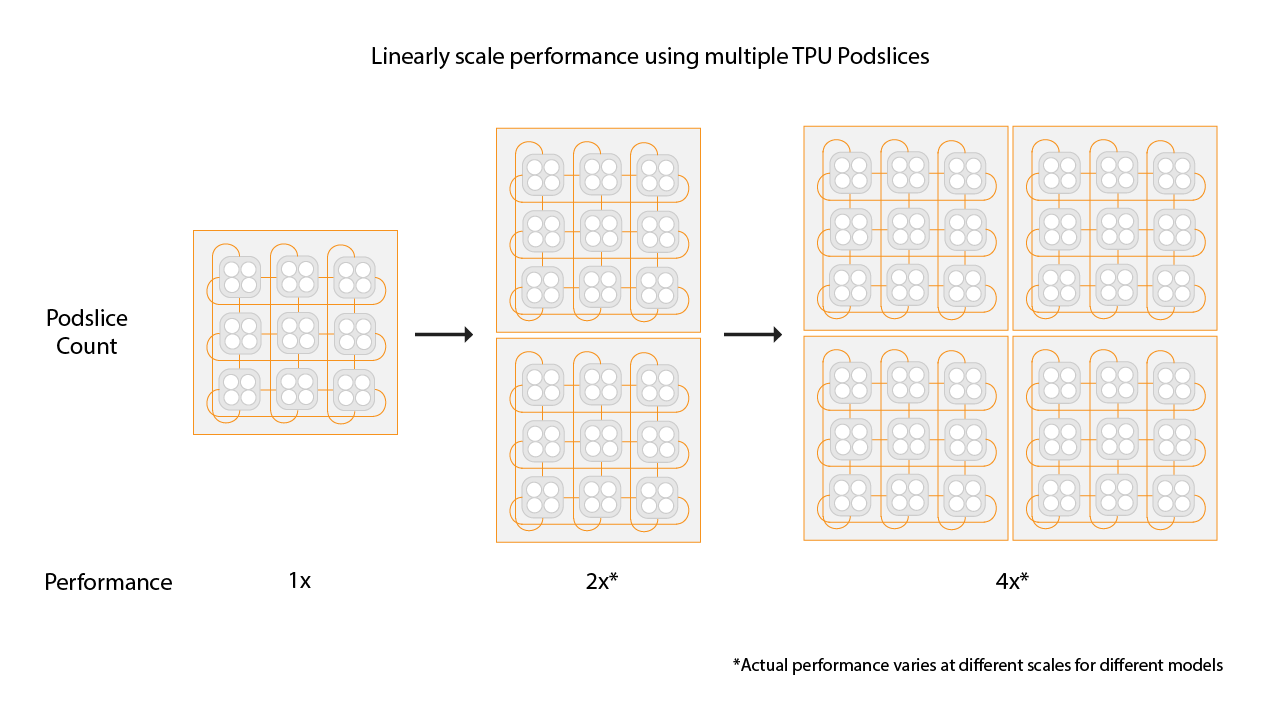
Scegliere le dimensioni delle sezioni per gli ambienti Multislice
Per ottenere un aumento lineare della velocità, aggiungi nuove sezioni della stessa dimensione di quelle esistenti. Ad esempio, se utilizzi una sezione v4-512, Multislice
otterrà prestazioni circa doppie aggiungendo una seconda sezione v4-512
e raddoppiando la dimensione del batch globale. Per saperne di più, consulta
Sharding con multislice per il massimo rendimento.
Esecuzione del job su più sezioni
Esistono tre approcci diversi per eseguire il workload personalizzato in un ambiente multislice:
Script di esecuzione dell'esperimento
Lo script multihost_runner.py
distribuisce il codice a un ambiente Multislice esistente ed esegue
il comando su ogni host, copia i log e tiene traccia dello stato di errore di ogni comando. Lo script multihost_runner.py è documentato in
MaxText README.
Poiché multihost_runner.py mantiene connessioni SSH persistenti, è adatto solo per esperimenti di dimensioni modeste e di durata relativamente breve. Puoi
adattare i passaggi del tutorial multihost_runner.py
alla tua configurazione di workload e hardware.
Script di esecuzione della produzione
Per i job di produzione che richiedono resilienza agli errori hardware e ad altri
interruzioni, è consigliabile l'integrazione diretta con l'API Create Queued Resource. Utilizza multihost_job.py come esempio pratico
che attiva la chiamata API Created Queued Resource con lo script di avvio appropriato
per eseguire l'addestramento e riprendere in caso di preempt. Lo script multihost_job.py
è documentato nel
README di MaxText.
Poiché multihost_job.py deve eseguire il provisioning delle risorse per ogni esecuzione, non
fornisce un ciclo di iterazione rapido come multihost_runner.py.
Approccio manuale
Ti consigliamo di utilizzare o adattare multihost_runner.py o multihost_job.py per eseguire il tuo workload personalizzato nella configurazione Multislice. Tuttavia, se preferisci eseguire il provisioning e gestire l'ambiente utilizzando direttamente i comandi QR, consulta Gestire un ambiente multislice.
Gestire un ambiente Multislice
Per eseguire il provisioning e gestire manualmente i QR senza utilizzare gli strumenti forniti nel repository MaxText, leggi le sezioni seguenti.
Crea risorse in coda
gcloud
Assicurati di disporre della quota corrispondente prima di selezionare --reserved,
--spot o la quota on demand predefinita. Per informazioni sui tipi di quota,
consulta le norme sulle quote.
curl
La risposta dovrebbe essere simile alla seguente:
{ "name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qr-guid>", "metadata": { "@type": "type.googleapis.com/google.cloud.common.OperationMetadata", "createTime": "2023-11-01T00:17:05.742546311Z", "target": "projects/<your-project-id>/locations/<your-zone>/queuedResources/<your-qa-id>", "verb": "create", "cancelRequested": false, "apiVersion": "v2alpha1" }, "done": false }
Utilizza il valore GUID alla fine del valore stringa per l'attributo name per ottenere
informazioni sulla richiesta di risorse in coda.
Console
Recupera lo stato di una risorsa in coda
gcloud
$ gcloud compute tpus queued-resources describe ${QR_ID} --zone=${ZONE}
Per una risorsa in coda nello stato ACTIVE, l'output è simile al seguente:
...
state:
state: ACTIVE
...
curl
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/queuedResources/${YOUR_QR_ID}
Per una risorsa in coda nello stato ACTIVE, l'output è simile al seguente:
{
"name": your-queued-res,
"tpu": {
"nodeSpec": [
{
... // node 1
},
{
... // node 2
},
...
]
},
...
"state": "ACTIVE"
}
Console
Una volta eseguito il provisioning della TPU, puoi anche visualizzare i dettagli della richiesta di risorse in coda andando alla pagina TPU, trovando la tua TPU e facendo clic sul nome della richiesta di risorse in coda corrispondente.
In rari casi, potresti trovare la risorsa in coda nello stato FAILED mentre alcune
fette sono ACTIVE. In questo caso, elimina le risorse create e riprova tra qualche minuto o contatta l'assistenzaGoogle Cloud .
SSH e installazione delle dipendenze
Esecuzione del codice JAX sulle sezioni TPU
descrive come connettersi alle VM TPU utilizzando SSH in una singola sezione. Per
connetterti a tutte le VM TPU nel tuo ambiente Multislice tramite SSH e
installare le dipendenze, utilizza il seguente comando gcloud:
$ gcloud compute tpus queued-resources ssh ${QR_ID} \ --zone=${ZONE} \ --node=all \ --worker=all \ --command="command-to-run" \ --batch-size=4
Questo comando gcloud invia il comando specificato a tutti i worker e i nodi in
QR utilizzando SSH. Il comando viene raggruppato in batch di quattro e inviato
contemporaneamente. Il batch successivo di comandi viene inviato al termine dell'esecuzione del batch corrente. Se si verifica un errore con uno dei comandi, l'elaborazione
si interrompe e non vengono inviati altri batch. Per saperne di più, consulta il
riferimento API delle risorse in coda.
Se il numero di sezioni che utilizzi supera il limite di threading (chiamato anche limite di batch) del computer locale, si verifica un deadlock. Ad esempio,
supponiamo che il limite di batch sulla tua macchina locale sia 64. Se tenti di eseguire uno
script di addestramento su più di 64 segmenti, ad esempio 100, il comando SSH suddividerà
i segmenti in batch. Eseguirà lo script di addestramento sul primo batch di 64
sezioni e attenderà il completamento degli script prima di eseguirli sul
batch rimanente di 36 sezioni. Tuttavia, il primo batch di 64 segmenti non può
essere completato finché i 36 segmenti rimanenti non iniziano a eseguire lo script, causando un
blocco.
Per evitare questo scenario, puoi eseguire lo script di addestramento in background su
ogni VM aggiungendo una e commerciale (&) al comando dello script specificato
con il flag --command.& In questo modo, dopo aver avviato lo script di addestramento
sul primo batch di sezioni, il controllo tornerà immediatamente al
comando SSH. Il comando SSH può quindi iniziare a eseguire lo script di addestramento sul batch rimanente di 36 sezioni. Quando esegui i comandi in background, devi reindirizzare i flussi stdout e stderr in modo appropriato. Per aumentare
il parallelismo all'interno dello stesso QR, puoi selezionare segmenti specifici utilizzando il parametro --node.
Configurazione rete
Assicurati che le sezioni TPU possano comunicare tra loro eseguendo i seguenti passaggi.
Installa JAX su ogni slice. Per maggiori informazioni, vedi
Esecuzione del codice JAX nelle sezioni di TPU. Afferma che
len(jax.devices()) è uguale al numero di chip nel tuo ambiente
Multislice. Per farlo, esegui questo comando su ogni slice:
$ python3 -c 'import jax; print(jax.devices())'
Se esegui questo codice su quattro slice di v4-16, ci sono otto chip per
slice e quattro slice, per un totale di 32 chip (dispositivi) che dovrebbero essere restituiti
da jax.devices().
Elenco delle risorse in coda
gcloud
Puoi visualizzare lo stato delle risorse in coda utilizzando il comando queued-resources list:
$ gcloud compute tpus queued-resources list --zone=${ZONE}
L'output è simile al seguente:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central1-a 4 v5litepod-16 ACTIVE ...
Console
Avvia il job in un ambiente di cui è stato eseguito il provisioning
Puoi eseguire manualmente i carichi di lavoro connettendoti a tutti gli host di ogni slice tramite SSH ed eseguendo il seguente comando su tutti gli host.
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone=${ZONE} \ --worker=all \ --command="command-to-run"
Reimpostazione delle risposte rapide
L'API ResetQueuedResource può essere utilizzata per reimpostare
tutte le VM in un ACTIVE QR. Il reset delle VM cancella forzatamente la memoria
della macchina e reimposta la VM allo stato iniziale. Tutti i dati archiviati localmente
rimarranno intatti e lo script di avvio verrà richiamato dopo un ripristino. L'API
ResetQueuedResource può essere utile quando vuoi riavviare tutte le TPU. Ad esempio, quando l'addestramento è bloccato e il ripristino di tutte le VM è più semplice del debug.
I ripristini di tutte le VM vengono eseguiti in parallelo e un'operazione ResetQueuedResource
richiede da uno a due minuti. Per richiamare l'API, utilizza il seguente
comando:
$ gcloud compute tpus queued-resources reset ${QR_ID} --zone=${ZONE}
Eliminazione delle risorse in coda
Per rilasciare le risorse al termine della sessione di addestramento, elimina la risorsa
in coda. L'eliminazione richiede da 2 a 5 minuti. Se utilizzi gcloud CLI, puoi eseguire questo comando in background con il flag facoltativo --async.
gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --zone=${ZONE} --force [--async]
Console
Recupero automatico dagli errori
In caso di interruzione, Multislice offre la riparazione senza intervento della slice interessata e il ripristino di tutte le slice in seguito. La sezione interessata viene sostituita con una nuova sezione e le sezioni rimanenti, altrimenti integre, vengono reimpostate. Se non è disponibile capacità per allocare una sezione sostitutiva, l'addestramento si interrompe.
Per riprendere l'addestramento automaticamente dopo un'interruzione, devi specificare uno script di avvio che controlli e carichi gli ultimi checkpoint salvati. Lo script di avvio viene eseguito automaticamente ogni volta che una sezione viene riassegnata o una VM viene reimpostata. Specifichi uno script di avvio nel payload JSON che invii all'API di richiesta di creazione del codice QR.
Il seguente script di avvio (utilizzato in Create QRs) ti consente di eseguire automaticamente il ripristino in caso di errori e riprendere l'addestramento dai checkpoint archiviati in un bucket Cloud Storage durante l'addestramento MaxText:
{
"tpu": {
"node_spec": [
{
...
"metadata": {
"startup-script": "#! /bin/bash \n pwd \n runuser -l user1 -c 'cd /home/user1/MaxText && python3 -m MaxText.train MaxText/configs/base.yml run_name=run_test_failure_recovery dcn_data_parallelism=4 ici_fsdp_parallelism=8 steps=10000 save_period=10 base_output_directory='gs://user1-us-central2'' EOF"
}
...
}
]
}
}
Clona il repository MaxText prima di provare questa soluzione.
Profilazione e debug
La profilazione è la stessa negli ambienti a singola sezione e a più sezioni. Per maggiori informazioni, consulta Profilazione dei programmi JAX.
Ottimizza la formazione
Le sezioni seguenti descrivono come ottimizzare l'addestramento multislice.
Sharding con Multislice per ottenere le massime prestazioni
Per ottenere le massime prestazioni negli ambienti multislice è necessario valutare come eseguire lo sharding tra le varie sezioni. In genere ci sono tre opzioni (parallelismo dei dati, parallelismo dei dati completamente partizionati e parallelismo della pipeline). Non consigliamo di suddividere le attivazioni tra le dimensioni del modello (a volte chiamato parallelismo dei tensori) perché richiede una larghezza di banda tra le sezioni troppo elevata. Per tutte queste strategie, puoi mantenere la stessa strategia di partizionamento all'interno di una sezione che hai utilizzato in passato.
Ti consigliamo di iniziare con il parallelismo dei dati puro. L'utilizzo del parallelismo dei dati completamente partizionati è utile per liberare l'utilizzo della memoria. Lo svantaggio è che la comunicazione tra le sezioni utilizza la rete DCN e rallenta il tuo carico di lavoro. Utilizza il parallelismo della pipeline solo quando necessario in base alle dimensioni del batch (come analizzato di seguito).
Quando utilizzare il parallelismo dei dati
Il parallelismo dei dati puro funziona bene nei casi in cui hai un carico di lavoro che funziona bene, ma vorresti migliorarne il rendimento eseguendo lo scale up su più slice.
Per ottenere uno scaling efficace su più sezioni, il tempo necessario per eseguire all-reduce su DCN deve essere inferiore al tempo necessario per eseguire un passaggio all'indietro. DCN viene utilizzato per la comunicazione tra le sezioni ed è un fattore limitante nella velocità effettiva del workload.
Ogni chip TPU v4 ha un picco di 275 * 1012 FLOPS al secondo.
Ogni host TPU ha quattro chip e una larghezza di banda di rete massima di 50 Gbps.
Ciò significa che l'intensità aritmetica è 4 * 275 * 1012 FLOPS / 50 Gbps = 22.000 FLOPS / bit.
Il modello utilizzerà da 32 a 64 bit di larghezza di banda DCN per ogni parametro per passaggio. Se utilizzi due sezioni, il modello utilizzerà 32 bit di larghezza di banda DCN. Se utilizzi più di due sezioni, il compilatore eseguirà un'operazione di riduzione completa e casuale e utilizzerai fino a 64 bit di larghezza di banda DCN per ogni parametro per passaggio. La quantità di FLOPS necessaria per ogni parametro varia a seconda del modello. Nello specifico, per i modelli linguistici basati su Transformer, il numero di FLOPS richiesti per un passaggio in avanti e uno indietro è circa 6 * B * P, dove:
Il numero di FLOPS per parametro è 6 * B e il numero di FLOPS per parametro
durante il passaggio all'indietro è 4 * B.
Per garantire uno scaling efficace su più sezioni, assicurati che l'intensità operativa superi l'intensità aritmetica dell'hardware TPU. Per calcolare l'intensità operativa, dividi il numero di FLOPS per parametro durante il passaggio all'indietro per la larghezza di banda della rete (in bit) per parametro per passaggio:
Operational Intensity = FLOPSbackwards_pass / DCN bandwidth
Pertanto, per un modello linguistico basato su Transformer, se utilizzi due sezioni:
Operational intensity = 4 * B / 32
Se utilizzi più di due sezioni: Operational intensity = 4 * B/64
Ciò suggerisce una dimensione minima del batch compresa tra 176.000 e 352.000 per i modelli linguistici basati su Transformer. Poiché la rete DCN può eliminare brevemente i pacchetti, è consigliabile mantenere un margine di errore significativo, eseguendo il deployment del parallelismo dei dati solo se la dimensione batch per pod è almeno 350.000 (due pod) fino a 700.000 (molti pod).
Per altre architetture di modelli, devi stimare il runtime del passaggio all'indietro per slice (cronometrandolo utilizzando un profiler o contando le operazioni in virgola mobile). Puoi quindi confrontarlo con il tempo di esecuzione previsto per ridurre al minimo l'utilizzo della rete di comunicazione dei dati e ottenere una stima precisa se il parallelismo dei dati è utile per te.
Quando utilizzare il parallelismo dei dati completamente partizionati (FSDP)
Il parallelismo dei dati completamente suddivisi (FSDP) combina il parallelismo dei dati (suddivisione dei dati tra i nodi) con la suddivisione dei pesi tra i nodi. Per ogni operazione nei passaggi in avanti e indietro, i pesi vengono raccolti in modo che ogni slice abbia i pesi necessari. Anziché sincronizzare i gradienti utilizzando all-reduce, i gradienti vengono ridotti e distribuiti man mano che vengono prodotti. In questo modo, ogni sezione riceve solo i gradienti per i pesi di cui è responsabile.
Analogamente al parallelismo dei dati, FSDP richiede di scalare la dimensione del batch globale in modo lineare con il numero di slice. FSDP ridurrà la pressione della memoria man mano che aumenti il numero di sezioni. Questo perché il numero di pesi e lo stato dell'ottimizzatore per slice diminuisce, ma a costo di un aumento del traffico di rete e di una maggiore possibilità di blocco a causa di un ritardo collettivo.
In pratica, FSDP tra le sezioni è la soluzione migliore se aumenti il batch per sezione, memorizzi più attivazioni per ridurre al minimo la ri-materializzazione durante il passaggio all'indietro o aumenti il numero di parametri nella rete neurale.
Le operazioni all-gather e all-reduce in FSDP funzionano in modo simile a quelle in DP, quindi puoi determinare se il tuo carico di lavoro FSDP è limitato dalle prestazioni DCN nello stesso modo descritto nella sezione precedente.
Quando utilizzare il parallelismo della pipeline
Il parallelismo della pipeline diventa pertinente quando si ottengono prestazioni elevate con altre strategie di parallelismo che richiedono una dimensione batch globale superiore alla dimensione batch massima preferita. Il parallelismo della pipeline consente alle sezioni che compongono una pipeline di "condividere" un batch. Tuttavia, il parallelismo della pipeline presenta due svantaggi significativi:
Il parallelismo della pipeline deve essere utilizzato solo se le altre strategie di parallelismo richiedono una dimensione del batch globale troppo grande. Prima di provare il parallelismo della pipeline, vale la pena fare un esperimento per verificare empiramente se la convergenza per campione rallenta alla dimensione del batch necessaria per ottenere FSDP ad alte prestazioni. FSDP tende a ottenere un utilizzo FLOP del modello più elevato, ma se la convergenza per campione rallenta con l'aumentare delle dimensioni del batch, il parallelismo della pipeline potrebbe comunque essere la scelta migliore. La maggior parte dei workload può tollerare dimensioni dei batch sufficientemente grandi da non trarre vantaggio dal parallelismo della pipeline, ma il tuo workload potrebbe essere diverso.
Se è necessario il parallelismo della pipeline, ti consigliamo di combinarlo con il parallelismo dei dati o FSDP. In questo modo, puoi ridurre al minimo la profondità della pipeline aumentando le dimensioni del batch per pipeline finché la latenza DCN non diventa un fattore meno importante nel throughput. In concreto, se hai N sezioni, considera pipeline di profondità 2 e N/2 repliche di parallelismo dei dati, poi pipeline di profondità 4 e N/4 repliche di parallelismo dei dati e così via, finché il batch per pipeline non diventa abbastanza grande da nascondere i collettivi DCN dietro l'aritmetica nel passaggio all'indietro. In questo modo, il rallentamento introdotto dal parallelismo della pipeline viene ridotto al minimo, consentendoti di superare il limite della dimensione del batch globale.
Best practice per le multislice
Le seguenti sezioni descrivono le best practice per l'addestramento multislice.
Caricamento dei dati
Durante l'addestramento, carichiamo ripetutamente batch da un set di dati da inserire nel modello. Disporre di un caricatore di dati asincrono efficiente che distribuisca il batch tra gli host è importante per evitare di sovraccaricare le TPU. L'attuale caricatore di dati in MaxText fa in modo che ogni host carichi un sottoinsieme uguale di esempi. Questa soluzione è adeguata per il testo, ma richiede una ridistribuzione all'interno del modello. Inoltre, MaxText non offre ancora l'istantanea deterministica, che consentirebbe all'iteratore di dati di caricare gli stessi dati prima e dopo la preemption.
Checkpoint
La libreria di checkpointing Orbax fornisce
primitive per il checkpointing di JAX PyTrees nell'archiviazione locale o Google Cloud nell'archiviazione.
Forniamo un'integrazione di riferimento con il checkpointing sincrono in MaxText
in checkpointing.py.
Configurazioni supportate
Le sezioni seguenti descrivono le forme delle sezioni, l'orchestrazione, i framework e il parallelismo supportati per Multislice.
Forme
Tutte le sezioni devono avere la stessa forma (ad esempio, lo stesso AcceleratorType).
Le forme delle sezioni eterogenee non sono supportate.
Orchestrazione
L'orchestrazione è supportata con GKE. Per maggiori informazioni, consulta TPU in GKE.
Framework
Multislice supporta solo i carichi di lavoro JAX e PyTorch.
Parallelismo
Consigliamo agli utenti di testare Multislice con il parallelismo dei dati. Per saperne di più sull'implementazione del parallelismo della pipeline con Multislice, contatta il tuo rappresentante dell'accountGoogle Cloud .
Assistenza e feedback
Accogliamo con piacere tutti i feedback. Per condividere un feedback o richiedere assistenza, contattaci utilizzando il modulo di assistenza o feedback di Cloud TPU.