Présentation de Cloud TPU Multislice
Cloud TPU multislice est une technologie de scaling des performances full stack qui permet à un job d'entraînement d'utiliser plusieurs tranches TPU dans une seule tranche ou sur des tranches dans plusieurs pods avec un parallélisme des données standard. Avec les puces TPU v4, les jobs d'entraînement peuvent utiliser plus de 4 096 puces en une seule exécution. Pour les tâches d'entraînement qui nécessitent moins de 4 096 puces, une seule tranche peut offrir les meilleures performances. Toutefois, plusieurs petites tranches sont plus facilement disponibles, ce qui permet un démarrage plus rapide lorsque Multislice est utilisé avec des tranches plus petites.
Lorsqu'elles sont déployées dans des configurations Multislice, les puces TPU de chaque tranche communiquent via une interconnexion entre puces (ICI). Les puces TPU de différentes tranches communiquent en transférant des données aux CPU (hôtes), qui à leur tour transmettent les données sur le réseau du centre de données (DCN). Pour en savoir plus sur le scaling avec Multislice, consultez Faire évoluer l'entraînement IA jusqu'à plusieurs dizaines de milliers de puces Cloud TPU grâce à Multislice.
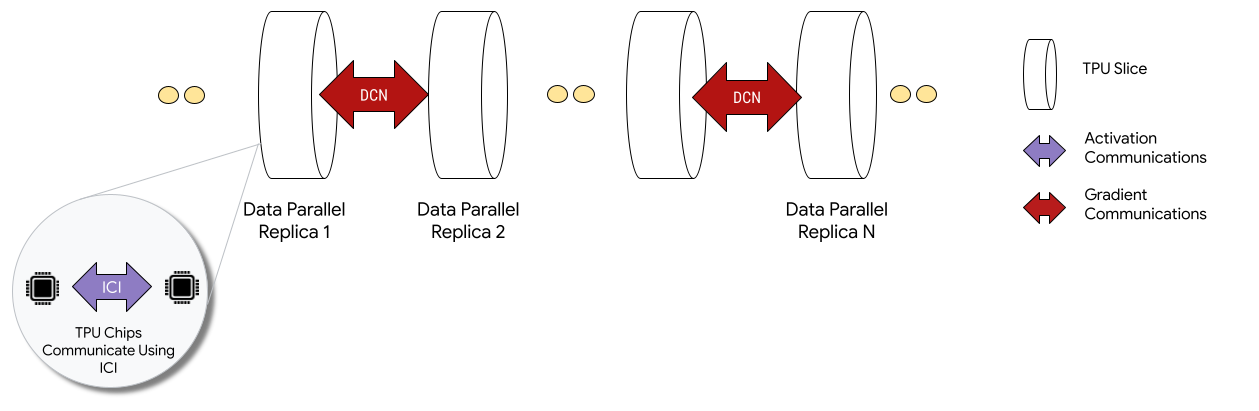
Les développeurs n'ont pas besoin d'écrire de code pour implémenter la communication DCN entre les tranches. Le compilateur XLA génère ce code pour vous et chevauche la communication avec le calcul pour des performances maximales.
Concepts
- Type d'accélérateur
- Forme de chaque tranche de TPU qui compose un environnement Multislice. Chaque tranche d'une requête multitranche est du même type d'accélérateur. Un type d'accélérateur se compose d'un type de TPU (v4 ou version ultérieure) suivi du nombre de TensorCores.
Par exemple,
v5litepod-128spécifie un TPU v5e avec 128 TensorCores. - Réparation automatique
- Lorsqu'une tranche rencontre un événement de maintenance, une préemption ou une défaillance matérielle, Cloud TPU crée une tranche. Si les ressources sont insuffisantes pour créer une tranche, la création ne se terminera pas tant que le matériel ne sera pas disponible. Une fois la nouvelle tranche créée, toutes les autres tranches de l'environnement Multislice seront redémarrées pour que l'entraînement puisse se poursuivre. Avec un script de démarrage correctement configuré, le script d'entraînement peut se relancer automatiquement sans intervention de l'utilisateur, en chargeant et en reprenant l'entraînement à partir du dernier point de contrôle.
- Réseau de centre de données (DCN)
- Réseau à latence plus élevée et à débit plus faible (par rapport à l'ICI) qui connecte les tranches de TPU dans une configuration Multislice.
- Planification de groupe
- Lorsque toutes les tranches de TPU sont provisionnées ensemble, en même temps, cela garantit que toutes les tranches sont provisionnées avec succès ou qu'aucune ne l'est.
- Interconnexion entre puces (ICI)
- Liens internes à haut débit et à faible latence qui connectent les TPU au sein d'un pod TPU.
- Multitranches
- Au moins deux tranches de puces TPU pouvant communiquer sur le DCN.
- Nœud
- Dans le contexte Multislice, le terme "nœud" fait référence à une seule tranche de TPU. Chaque tranche de TPU d'un environnement Multislice reçoit un ID de nœud.
- Script de démarrage
- Un script de démarrage Compute Engine standard qui s'exécute chaque fois qu'une VM est démarrée ou redémarrée. Pour un environnement Multislice, il est spécifié dans la demande de création du code QR. Pour en savoir plus sur les scripts de démarrage Cloud TPU, consultez Gérer les ressources TPU.
- Tensor
- Structure de données utilisée pour représenter des données multidimensionnelles dans un modèle de machine learning.
- Types de capacité Cloud TPU
Les TPU peuvent être créés à partir de différents types de capacité (voir "Options d'utilisation" dans Fonctionnement des tarifs des TPU) :
Réservation : pour utiliser une réservation, vous devez avoir conclu un accord de réservation avec Google. Utilisez le flag
--reservedlorsque vous créez vos ressources.Spot : cible le quota préemptif à l'aide de VM Spot. Vos ressources peuvent être préemptées pour faire de la place aux requêtes d'un job de priorité plus élevée. Utilisez le flag
--spotlorsque vous créez vos ressources.À la demande : cible le quota à la demande, qui ne nécessite pas de réservation et ne sera pas préempté. La demande de TPU sera mise en file d'attente dans une file d'attente de quota à la demande proposée par Cloud TPU. La disponibilité des ressources n'est pas garantie. Sélectionné par défaut, aucun flag n'est nécessaire.
Commencer
Configurez votre environnement Cloud TPU.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
ici_data_parallelismici_fsdp_parallelismici_tensor_parallelismConfigurer l'environnement :
$ gcloud auth login $ export QR_ID=your-queued-resource-id $ export TPU_NAME=your-tpu-name $ export PROJECT=your-project-name $ export ZONE=us-central1-a $ export NETWORK_NAME=your-network-name $ export SUBNETWORK_NAME=your-subnetwork-name $ export RUNTIME_VERSION=v2-alpha-tpuv5-lite $ export ACCELERATOR_TYPE=v5litepod-16 $ export EXAMPLE_TAG_1=your-tag-1 $ export EXAMPLE_TAG_2=your-tag-2 $ export SLICE_COUNT=4 $ export STARTUP_SCRIPT='#!/bin/bash\n'
Descriptions des variables
Entrée Description QR_ID ID attribué par l'utilisateur à la ressource mise en file d'attente. TPU_NAME Nom attribué par l'utilisateur à votre TPU. PROJET Nom du projetGoogle Cloud ZONE Spécifie la zone dans laquelle créer les ressources. NETWORK_NAME Nom des réseaux VPC. SUBNETWORK_NAME Nom du sous-réseau dans les réseaux VPC RUNTIME_VERSION Version logicielle de Cloud TPU. ACCELERATOR_TYPE v4-16 EXAMPLE_TAG_1, EXAMPLE_TAG_2 … Tags utilisés pour identifier les sources ou cibles valides pour les pare-feu de réseau SLICE_COUNT Nombre de tranches. Limité à 256 tranches maximum. STARTUP_SCRIPT Si vous spécifiez un script de démarrage, il s'exécute lorsque la tranche de TPU est provisionnée ou redémarrée. Créez des clés SSH pour
gcloud. Nous vous recommandons de laisser le mot de passe vide (appuyez deux fois sur Entrée après avoir exécuté la commande suivante). Si vous êtes invité à remplacer le fichiergoogle_compute_engineexistant, faites-le.$ ssh-keygen -f ~/.ssh/google_compute_engine
Provisionnez vos TPU :
gcloud
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-id=${TPU_NAME} \ --zone=${ZONE} \ [--reserved |--spot]
Google Cloud CLI ne prend pas en charge toutes les options de création de codes QR, comme les tags. Pour en savoir plus, consultez Créer des QR codes.
Console
Dans la console Google Cloud , accédez à la page TPU :
Cliquez sur Créer un TPU.
Dans le champ Nom, saisissez un nom pour votre TPU.
Dans le champ Zone, sélectionnez la zone dans laquelle vous souhaitez créer le TPU.
Dans la zone Type de TPU, sélectionnez un type d'accélérateur. Le type d'accélérateur spécifie la version et la taille du Cloud TPU que vous souhaitez créer. Pour en savoir plus sur les types d'accélérateurs compatibles avec chaque version de TPU, consultez Versions de TPU.
Dans le champ Version logicielle du TPU, sélectionnez une version logicielle. Lorsque vous créez une VM Cloud TPU, la version logicielle du TPU spécifie la version de l'environnement d'exécution TPU à installer. Pour en savoir plus, consultez Versions logicielles de TPU.
Cliquez sur le bouton Activer la mise en file d'attente.
Dans le champ Nom de la ressource mise en file d'attente, saisissez un nom pour votre demande de ressource mise en file d'attente.
Cliquez sur Créer pour créer votre demande de ressource mise en file d'attente.
Attendez que la ressource mise en file d'attente soit à l'état
ACTIVE, ce qui signifie que les nœuds de calcul sont à l'étatREADY. Une fois le provisionnement des ressources en file d'attente démarré, il peut prendre entre une et cinq minutes, selon la taille de la ressource en file d'attente. Vous pouvez vérifier l'état d'une demande de ressources mise en file d'attente à l'aide de la gcloud CLI ou de la console Google Cloud :gcloud
$ gcloud compute tpus queued-resources \ list --filter=${QR_ID} --zone=${ZONE}
Console
Dans la console Google Cloud , accédez à la page TPU :
Cliquez sur l'onglet Ressources en file d'attente.
Cliquez sur le nom de votre demande de ressource mise en file d'attente.
Connectez-vous à la VM TPU à l'aide de SSH :
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} --zone=${ZONE}
Clonez MaxText (qui inclut
shardings.py) sur votre VM TPU :$ git clone https://github.com/AI-Hypercomputer/maxtext && cd maxtext
Installez Python 3.10 :
$ sudo apt-get update $ sudo apt install python3.10 $ sudo apt install python3.10-venv
Créez et activez un environnement virtuel :
$ python3 -m venv your-venv-name $ source your-venv-name/bin/activate
Dans le répertoire du dépôt MaxText, exécutez le script d'installation pour installer JAX et d'autres dépendances sur votre tranche de TPU. L'exécution du script de configuration prend quelques minutes.
$ bash setup.sh
Exécutez la commande suivante pour exécuter
shardings.pysur votre tranche de TPU.$ python3 -m pedagogical_examples.shardings \ --ici_fsdp_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Vous pouvez consulter les résultats dans les journaux. Vos TPU devraient atteindre environ 260 TFLOP par seconde, soit une utilisation des FLOPS de plus de 90 % ! Dans ce cas, nous avons sélectionné approximativement la taille de lot maximale qui tient dans la mémoire à haut débit (HBM) du TPU.
N'hésitez pas à explorer d'autres stratégies de segmentation sur l'ICI. Par exemple, vous pouvez essayer la combinaison suivante :
$ python3 -m pedagogical_examples.shardings \ --ici_tensor_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Une fois l'opération terminée, supprimez la ressource en file d'attente et la tranche de TPU. Vous devez exécuter ces étapes de nettoyage à partir de l'environnement dans lequel vous avez configuré la tranche (exécutez d'abord
exitpour quitter la session SSH). La suppression prend entre deux et cinq minutes. Si vous utilisez la gcloud CLI, vous pouvez exécuter cette commande en arrière-plan avec l'option facultative--async.gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --force (--async)
Console
Dans la console Google Cloud , accédez à la page TPU :
Cliquez sur l'onglet Ressources en file d'attente.
Cochez la case à côté de votre demande de ressource mise en file d'attente.
Cliquez sur Supprimer.
- dcn_data_parallelism
- dcn_fsdp_parallelism
- dcn_tensor_parallelism
Clonez MaxText sur la machine de votre exécuteur :
$ git clone https://github.com/AI-Hypercomputer/maxtext
Accédez au répertoire du dépôt.
$ cd maxtext
Créez des clés SSH pour
gcloud. Nous vous recommandons de laisser le mot de passe vide (appuyez deux fois sur Entrée après avoir exécuté la commande suivante). Si le messagegoogle_compute_engineexiste déjà s'affiche, sélectionnez l'option permettant de ne pas conserver votre version existante.$ ssh-keygen -f ~/.ssh/google_compute_engine
Ajoutez une variable d'environnement pour définir le nombre de tranches de TPU sur
2.$ export SLICE_COUNT=2
Créez un environnement Multislice à l'aide de la commande
queued-resources createou de la console Google Cloud .gcloud
La commande suivante montre comment créer un TPU v5e Multislice. Pour utiliser une autre version de TPU, spécifiez un autre
accelerator-typeet une autreruntime-version.$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-count=${SLICE_COUNT} \ --node-prefix=${TPU_NAME} \ --zone=${ZONE} \ [--reserved|--spot]
Console
Dans la console Google Cloud , accédez à la page TPU :
Cliquez sur Créer un TPU.
Dans le champ Nom, saisissez un nom pour votre TPU.
Dans le champ Zone, sélectionnez la zone dans laquelle vous souhaitez créer le TPU.
Dans la zone Type de TPU, sélectionnez un type d'accélérateur. Le type d'accélérateur spécifie la version et la taille du Cloud TPU que vous souhaitez créer. Multislice n'est compatible qu'avec les Cloud TPU v4 et les versions ultérieures. Pour en savoir plus sur les versions de TPU, consultez Versions de TPU.
Dans le champ Version logicielle du TPU, sélectionnez une version logicielle. Lorsque vous créez une VM Cloud TPU, la version logicielle du TPU spécifie la version de l'environnement d'exécution TPU à installer sur les VM TPU. Pour en savoir plus, consultez Versions logicielles de TPU.
Cliquez sur le bouton Activer la mise en file d'attente.
Dans le champ Nom de la ressource mise en file d'attente, saisissez un nom pour votre demande de ressource mise en file d'attente.
Cochez la case Transformer en TPU multitranches.
Dans le champ Nombre de tranches, saisissez le nombre de tranches que vous souhaitez créer.
Cliquez sur Créer pour créer votre demande de ressource mise en file d'attente.
Lorsque le provisionnement des ressources mises en file d'attente démarre, il peut prendre jusqu'à cinq minutes, en fonction de la taille de la ressource mise en file d'attente. Attendez que la ressource mise en file d'attente soit à l'état
ACTIVE. Vous pouvez vérifier l'état d'une demande de ressources en file d'attente à l'aide de la gcloud CLI ou de la console Google Cloud :gcloud
$ gcloud compute tpus queued-resources list \ --filter=${QR_ID} --zone=${ZONE} --project=${PROJECT}
Vous devriez obtenir un résultat semblable à celui-ci :
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central2-b 4 v5litepod-16 ACTIVE ...
Console
Dans la console Google Cloud , accédez à la page TPU :
Cliquez sur l'onglet Ressources en file d'attente.
Cliquez sur le nom de votre demande de ressource mise en file d'attente.
Contactez votre responsable de compte Google Cloud si l'état du code QR est
WAITING_FOR_RESOURCESouPROVISIONINGdepuis plus de 15 minutes.Installez les dépendances.
$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="bash setup.sh"
Exécutez
shardings.pysur chaque nœud de calcul à l'aide demultihost_runner.py.$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="python3 -m pedagogical_examples.shardings \ --dcn_data_parallelism ${SLICE_COUNT} \ --ici_fsdp_parallelism 16 \ --batch_size 131072 \ --embedding_dimension 2048"
Vous verrez environ 230 TFLOPS par seconde de performances dans les fichiers journaux.
Pour en savoir plus sur la configuration du parallélisme, consultez Segmentation multitranches à l'aide du parallélisme DCN et de
shardings.py.Nettoyez les TPU et la ressource en file d'attente lorsque vous avez terminé. La suppression prendra entre deux et cinq minutes. Si vous utilisez la gcloud CLI, vous pouvez exécuter cette commande en arrière-plan avec le flag facultatif
--async.- Utilisez jax.experimental.mesh_utils.create_hybrid_device_mesh au lieu de jax.experimental.mesh_utils.create_device_mesh lorsque vous créez votre maillage.
- À l'aide du script d'exécution des tests,
multihost_runner.py - À l'aide du script du lanceur de production,
multihost_job.py - À l'aide d'une approche manuelle
Créez une demande de ressource mise en file d'attente à l'aide de la commande suivante :
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --project=${PROJECT} \ --zone=${ZONE} \ --node-count=${SLICE_COUNT} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --network=${NETWORK_NAME} \ --subnetwork=${SUBNETWORK_NAME} \ --tags=${EXAMPLE_TAG_1},${EXAMPLE_TAG_2} \ --metadata=startup-script="${STARTUP_SCRIPT}" \ [--reserved|--spot]
Créez un fichier nommé
queued-resource-req.jsonet copiez-y le JSON ci-dessous :{ "guaranteed": { "reserved": true }, "tpu": { "node_spec": [ { "parent": "projects/your-project-number/locations/your-zone", "node": { "accelerator_type": "accelerator-type", "runtime_version": "tpu-vm-runtime-version", "network_config": { "network": "your-network-name", "subnetwork": "your-subnetwork-name", "enable_external_ips": true }, "tags" : ["example-tag-1"] "metadata": { "startup-script": "your-startup-script" } }, "multi_node_params": { "node_count": slice-count, "node_id_prefix": "your-queued-resource-id" } } ] } }
Remplacez les valeurs suivantes :
- your-project-number : votre numéro de projet Google Cloud
- your-zone : zone dans laquelle vous souhaitez créer votre ressource mise en file d'attente
- accelerator-type : version et taille d'une seule tranche Multislice n'est compatible qu'avec les Cloud TPU v4 et les versions ultérieures
- tpu-vm-runtime-version : version d'exécution de la VM TPU que vous souhaitez utiliser
- your-network-name (facultatif) : réseau auquel la ressource mise en file d'attente sera associée
- your-subnetwork-name (facultatif) : sous-réseau auquel la ressource mise en file d'attente sera associée
- example-tag-1 (facultatif) : chaîne de tag arbitraire
- your-startup-script : script de démarrage qui sera exécuté lorsque la ressource mise en file d'attente sera allouée
- slice-count : nombre de tranches de TPU dans votre environnement Multislice
- your-queued-resource-id : ID fourni par l'utilisateur pour la ressource mise en file d'attente
Pour en savoir plus sur toutes les options disponibles, consultez la documentation de l'API REST Queued Resource.
Pour utiliser la capacité Spot, remplacez :
"guaranteed": { "reserved": true }par"spot": {}Supprimez la ligne pour utiliser la capacité à la demande par défaut.
Envoyez la requête de création de ressource mise en file d'attente avec la charge utile JSON :
$ curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d @queuedresourcereq.json \ https://tpu.googleapis.com/v2alpha1/projects/your-project-id/locations/your-zone/queuedResources\?queued_resource_id\=your-queued-resource-id
Remplacez les valeurs suivantes :
- your-project-id : Google Cloud ID de votre projet
- your-zone : zone dans laquelle vous souhaitez créer votre ressource mise en file d'attente
- your-queued-resource-id : ID fourni par l'utilisateur pour la ressource mise en file d'attente
Dans la console Google Cloud , accédez à la page TPU :
Cliquez sur Créer un TPU.
Dans le champ Nom, saisissez un nom pour votre TPU.
Dans le champ Zone, sélectionnez la zone dans laquelle vous souhaitez créer le TPU.
Dans la zone Type de TPU, sélectionnez un type d'accélérateur. Le type d'accélérateur spécifie la version et la taille du Cloud TPU que vous souhaitez créer. Multislice n'est compatible qu'avec les Cloud TPU v4 et les versions ultérieures. Pour en savoir plus sur les types d'accélérateurs compatibles avec chaque version de TPU, consultez Versions de TPU.
Dans le champ Version logicielle du TPU, sélectionnez une version logicielle. Lorsque vous créez une VM Cloud TPU, la version logicielle du TPU spécifie la version de l'environnement d'exécution TPU à installer. Pour en savoir plus, consultez Versions logicielles de TPU.
Cliquez sur le bouton Activer la mise en file d'attente.
Dans le champ Nom de la ressource mise en file d'attente, saisissez un nom pour votre demande de ressource mise en file d'attente.
Cochez la case Transformer en TPU multitranches.
Dans le champ Nombre de tranches, saisissez le nombre de tranches que vous souhaitez créer.
Cliquez sur Créer pour créer votre demande de ressource mise en file d'attente.
Dans la console Google Cloud , accédez à la page TPU :
Cliquez sur l'onglet Ressources en file d'attente.
Cliquez sur le nom de votre demande de ressource mise en file d'attente.
Dans la console Google Cloud , accédez à la page TPU :
Cliquez sur l'onglet Ressources en file d'attente.
Dans la console Google Cloud , accédez à la page TPU :
Cliquez sur l'onglet Ressources en file d'attente.
Cochez la case à côté de votre demande de ressource mise en file d'attente.
Cliquez sur Supprimer.
- B est la taille du lot en jetons ;
- P est le nombre de paramètres.
- Cela entraîne une "bulle de pipeline", où les puces sont inactives parce qu'elles attendent des données.
- Il nécessite un micro-batching qui diminue la taille de lot effective, l'intensité arithmétique et, en fin de compte, l'utilisation des FLOP du modèle.
Pour utiliser Multislice, vos ressources TPU doivent être gérées en tant que ressources mises en file d'attente.
Exemple d'introduction
Ce tutoriel utilise le code du dépôt GitHub MaxText. MaxText est un LLM de base hautes performances, évolutif à volonté, Open Source et bien testé, écrit en Python et Jax. MaxText a été conçu pour s'entraîner efficacement sur Cloud TPU.
Le code de shardings.py
est conçu pour vous aider à tester différentes options de parallélisme. Par exemple, le parallélisme des données, le parallélisme des données entièrement segmentées (FSDP) et le parallélisme des tenseurs. Le code s'adapte aux environnements à une ou plusieurs tranches.
Parallélisme ICI
ICI fait référence à l'interconnexion à haut débit qui connecte les TPU d'une même tranche. La segmentation ICI correspond à la segmentation au sein d'une tranche. shardings.py fournit trois paramètres de parallélisme ICI :
Les valeurs que vous spécifiez pour ces paramètres déterminent le nombre de segments pour chaque méthode de parallélisme.
Ces entrées doivent être contraintes de sorte que ici_data_parallelism * ici_fsdp_parallelism * ici_tensor_parallelism soit égal au nombre de puces de la tranche.
Le tableau suivant présente des exemples de saisies utilisateur pour le parallélisme ICI pour les quatre puces disponibles dans la version 4-8 :
| ici_data_parallelism | ici_fsdp_parallelism | ici_tensor_parallelism | |
| FSDP à quatre voies | 1 | 4 | 1 |
| Parallélisme de tenseur à quatre voies | 1 | 1 | 4 |
| FSDP à deux voies + parallélisme de tenseur à deux voies | 1 | 2 | 2 |
Notez que ici_data_parallelism doit être défini sur 1 dans la plupart des cas, car le réseau ICI est suffisamment rapide pour que FSDP soit presque toujours préféré au parallélisme des données.
Cet exemple suppose que vous savez exécuter du code sur une seule tranche de TPU, comme dans la section Exécuter un calcul sur une VM Cloud TPU à l'aide de JAX.
Cet exemple montre comment exécuter shardings.py sur une seule tranche.
Segmentation multitranches utilisant le parallélisme DCN
Le script shardings.py accepte trois paramètres qui spécifient le parallélisme DCN, correspondant au nombre de segments de chaque type de parallélisme de données :
Les valeurs de ces paramètres doivent être limitées de sorte que dcn_data_parallelism * dcn_fsdp_parallelism * dcn_tensor_parallelism soit égal au nombre de tranches.
Pour deux tranches, utilisez par exemple --dcn_data_parallelism = 2.
| dcn_data_parallelism | dcn_fsdp_parallelism | dcn_tensor_parallelism | Nombre de tranches | |
| Parallélisme des données bidirectionnel | 2 | 1 | 1 | 2 |
dcn_tensor_parallelism doit toujours être défini sur 1, car le DCN ne convient pas à une telle segmentation. Pour les charges de travail LLM types sur les puces v4, dcn_fsdp_parallelism doit également être défini sur 1 et, par conséquent, dcn_data_parallelism doit être défini sur le nombre de tranches, mais cela dépend de l'application.
Si vous augmentez le nombre de tranches (en supposant que vous conserviez la taille des tranches et le lot par tranche constants), vous augmentez le parallélisme des données.
Exécuter shardings.py dans un environnement Multislice
Vous pouvez exécuter shardings.py dans un environnement Multislice à l'aide de multihost_runner.py ou en exécutant shardings.py sur chaque VM TPU. Ici, nous utilisons multihost_runner.py. Les étapes suivantes sont très similaires à celles de Getting Started: Quick Experiments on Multiple slices (Premiers pas : tests rapides sur plusieurs tranches) du dépôt MaxText, sauf qu'ici, nous exécutons shardings.py au lieu du LLM plus complexe dans train.py.
L'outil multihost_runner.py est optimisé pour les tests rapides, en réutilisant plusieurs fois les mêmes TPU. Étant donné que le script multihost_runner.py dépend des connexions SSH de longue durée, nous ne le recommandons pas pour les tâches de longue durée.
Si vous souhaitez exécuter une tâche plus longue (par exemple, pendant des heures ou des jours), nous vous recommandons d'utiliser multihost_job.py.
Dans ce tutoriel, nous utilisons le terme exécuteur pour désigner la machine sur laquelle vous exécutez le script multihost_runner.py. Nous utilisons le terme nœuds de calcul pour désigner les VM TPU qui composent vos tranches. Vous pouvez exécuter multihost_runner.py sur une machine locale ou sur n'importe quelle VM Compute Engine appartenant au même projet que vos tranches. L'exécution de multihost_runner.py sur un nœud de calcul n'est pas prise en charge.
multihost_runner.py se connecte automatiquement aux nœuds de calcul de TPU à l'aide de SSH.
Dans cet exemple, vous exécutez shardings.py sur deux tranches v5e-16, soit un total de quatre VM et 16 puces TPU. Vous pouvez modifier l'exemple pour l'exécuter sur davantage de TPU.
Configurer votre environnement
Mettre à l'échelle une charge de travail sur Multislice
Avant d'exécuter votre modèle dans un environnement Multislice, apportez les modifications de code suivantes :
Ce devraient être les seules modifications de code nécessaires lors du passage à un environnement Multislice. Pour obtenir des performances élevées, le DCN doit être mappé sur des axes de parallélisme des données, de parallélisme des données entièrement partitionnées ou de parallélisme de pipeline. Les considérations sur les performances et les stratégies de partitionnement sont abordées plus en détail dans Partitionnement avec Multislice pour des performances maximales.
Pour valider que votre code peut accéder à tous les appareils, vous pouvez affirmer que len(jax.devices()) est égal au nombre de puces dans votre environnement Multislice. Par exemple, si vous utilisez quatre tranches de v4-16, vous avez huit puces par tranche * 4 tranches, donc len(jax.devices()) doit renvoyer 32.
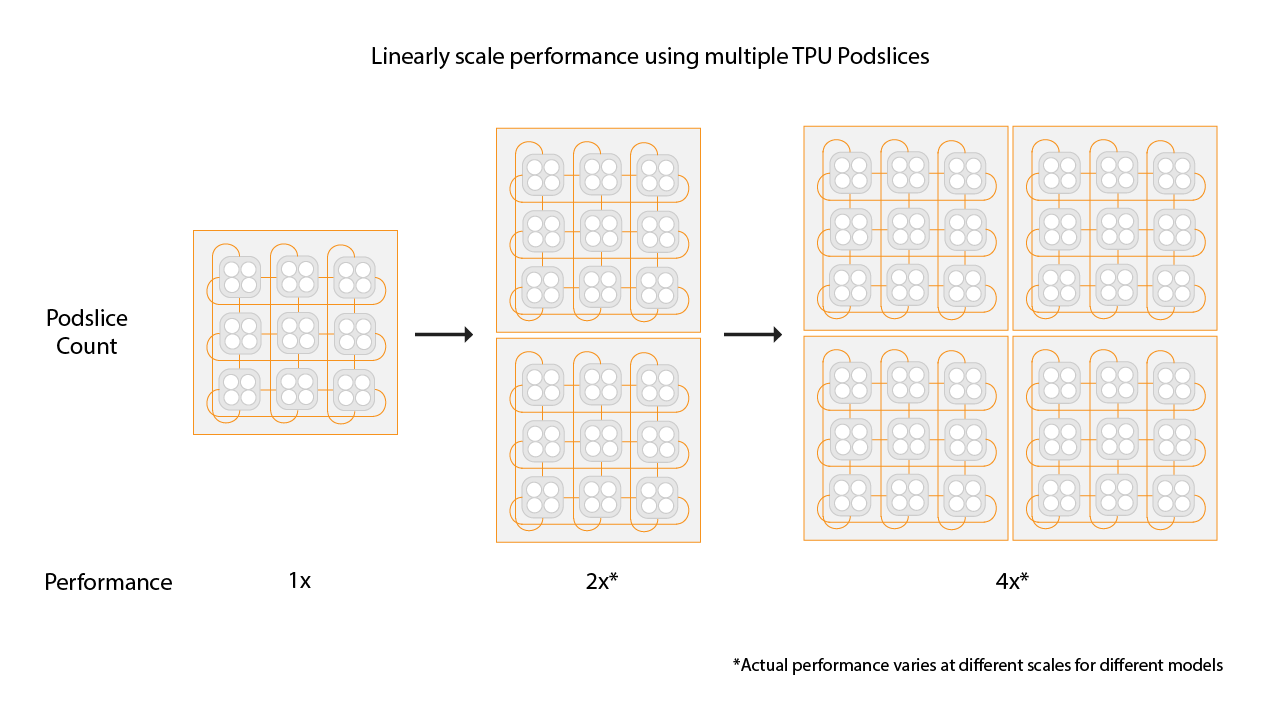
Choisir la taille des tranches pour les environnements Multislices
Pour obtenir une accélération linéaire, ajoutez des tranches de la même taille que votre tranche existante. Par exemple, si vous utilisez une tranche v4-512, l'environnement Multislice obtiendra des performances environ deux fois supérieures en ajoutant une deuxième tranche v4-512 et en doublant la taille de votre lot global. Pour en savoir plus, consultez Segmentation avec Multislice pour des performances maximales.
Exécuter votre job sur plusieurs tranches
Il existe trois approches différentes pour exécuter votre charge de travail personnalisée dans un environnement Multislice :
Script d'exécution des tests
Le script multihost_runner.py distribue le code à un environnement Multislice existant, exécute votre commande sur chaque hôte, copie vos journaux et suit l'état d'erreur de chaque commande. Le script multihost_runner.py est documenté dans le fichier README de MaxText.
Étant donné que multihost_runner.py maintient des connexions SSH persistantes, il ne convient qu'aux expérimentations de taille modeste et de durée relativement courte. Vous pouvez adapter les étapes du tutoriel multihost_runner.py à votre charge de travail et à votre configuration matérielle.
Script du lanceur de production
Pour les jobs de production qui doivent être résilients face aux défaillances matérielles et autres préemptions, il est préférable d'intégrer directement l'API Create Queued Resource. Utilisez multihost_job.py comme exemple de fonctionnement, qui déclenche l'appel d'API Created Queued Resource avec le script de démarrage approprié pour exécuter votre entraînement et le reprendre en cas de préemption. Le script multihost_job.py est documenté dans le fichier README de MaxText.
Étant donné que multihost_job.py doit provisionner des ressources pour chaque exécution, il ne fournit pas un cycle d'itération aussi rapide que multihost_runner.py.
Approche manuelle
Nous vous recommandons d'utiliser ou d'adapter multihost_runner.py ou multihost_job.py pour exécuter votre charge de travail personnalisée dans votre configuration Multislice. Toutefois, si vous préférez provisionner et gérer votre environnement à l'aide de commandes QR directement, consultez Gérer un environnement Multislice.
Gérer un environnement Multislice
Pour provisionner et gérer manuellement les QR sans utiliser les outils fournis dans le dépôt MaxText, consultez les sections suivantes.
Créer des ressources en file d'attente
gcloud
Assurez-vous de disposer du quota correspondant avant de sélectionner --reserved, --spot ou le quota à la demande par défaut. Pour en savoir plus sur les types de quotas, consultez les Règles relatives aux quotas.
curl
La réponse devrait ressembler à l'exemple ci-dessous :
{ "name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qr-guid>", "metadata": { "@type": "type.googleapis.com/google.cloud.common.OperationMetadata", "createTime": "2023-11-01T00:17:05.742546311Z", "target": "projects/<your-project-id>/locations/<your-zone>/queuedResources/<your-qa-id>", "verb": "create", "cancelRequested": false, "apiVersion": "v2alpha1" }, "done": false }
Utilisez la valeur GUID à la fin de la valeur de chaîne pour l'attribut name afin d'obtenir des informations sur la demande de ressource mise en file d'attente.
Console
Récupérer l'état d'une ressource en file d'attente
gcloud
$ gcloud compute tpus queued-resources describe ${QR_ID} --zone=${ZONE}
Pour une ressource mise en file d'attente et dont l'état est ACTIVE, le résultat ressemble à ce qui suit :
...
state:
state: ACTIVE
...
curl
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/queuedResources/${YOUR_QR_ID}
Pour une ressource mise en file d'attente et dont l'état est ACTIVE, le résultat ressemble à ce qui suit :
{
"name": your-queued-res,
"tpu": {
"nodeSpec": [
{
... // node 1
},
{
... // node 2
},
...
]
},
...
"state": "ACTIVE"
}
Console
Une fois votre TPU provisionné, vous pouvez également afficher des informations sur votre demande de ressources en file d'attente en accédant à la page TPU, en recherchant votre TPU, puis en cliquant sur le nom de la demande de ressources en file d'attente correspondante.
Dans de rares cas, il est possible que votre ressource mise en file d'attente soit à l'état FAILED alors que certaines tranches sont ACTIVE. Dans ce cas, supprimez les ressources créées, puis réessayez dans quelques minutes ou contactez l'assistanceGoogle Cloud .
SSH et installation de dépendances
L'article Exécuter du code JAX sur des tranches de TPU explique comment se connecter à vos VM TPU à l'aide de SSH dans une seule tranche. Pour vous connecter à toutes les VM TPU de votre environnement multislices via SSH et installer les dépendances, utilisez la commande gcloud suivante :
$ gcloud compute tpus queued-resources ssh ${QR_ID} \ --zone=${ZONE} \ --node=all \ --worker=all \ --command="command-to-run" \ --batch-size=4
Cette commande gcloud envoie la commande spécifiée à tous les nœuds de calcul et nœuds de QR à l'aide de SSH. La commande est regroupée par lots de quatre et envoyée simultanément. Le prochain lot de commandes est envoyé lorsque le lot actuel a terminé son exécution. Si l'une des commandes échoue, le traitement s'arrête et aucun autre lot n'est envoyé. Pour en savoir plus, consultez la documentation de référence de l'API de ressources mises en file d'attente.
Si le nombre de tranches que vous utilisez dépasse la limite de threading (également appelée limite de traitement par lot) de votre ordinateur local, vous rencontrerez un interblocage. Par exemple, supposons que la limite de traitement par lot sur votre ordinateur local soit de 64. Si vous essayez d'exécuter un script d'entraînement sur plus de 64 tranches, par exemple 100, la commande SSH divisera les tranches en lots. Elle exécutera le script d'entraînement sur le premier lot de 64 tranches et attendra la fin de l'exécution des scripts avant d'exécuter le script sur le lot restant de 36 tranches. Toutefois, le premier lot de 64 tranches ne peut pas se terminer tant que les 36 tranches restantes n'ont pas commencé à exécuter le script, ce qui provoque un interblocage.
Pour éviter ce scénario, vous pouvez exécuter le script d'entraînement en arrière-plan sur chaque VM en ajoutant une esperluette (&) à la commande de script que vous spécifiez avec le flag --command. Dans ce cas, une fois le script d'entraînement lancé sur le premier lot de tranches, le contrôle est immédiatement renvoyé à la commande SSH. La commande SSH peut alors commencer à exécuter le script d'entraînement sur le lot restant de 36 tranches. Vous devrez rediriger correctement vos flux stdout et stderr lorsque vous exécuterez les commandes en arrière-plan. Pour augmenter le parallélisme au sein du même QR, vous pouvez sélectionner des tranches spécifiques à l'aide du paramètre --node.
Configuration du réseau
Assurez-vous que les tranches de TPU peuvent communiquer entre elles en procédant comme suit.
Installez JAX sur chacune des tranches. Pour en savoir plus, consultez Exécuter du code JAX sur des tranches de TPU. Vérifiez que len(jax.devices()) est égal au nombre de puces dans votre environnement Multislice. Pour ce faire, exécutez la commande suivante sur chaque tranche :
$ python3 -c 'import jax; print(jax.devices())'
Si vous exécutez ce code sur quatre tranches de v4-16, il y a huit puces par tranche et quatre tranches. Au total, 32 puces (appareils) devraient être renvoyées par jax.devices().
Lister les ressources en file d'attente
gcloud
Vous pouvez afficher l'état de vos ressources mises en file d'attente à l'aide de la commande queued-resources list :
$ gcloud compute tpus queued-resources list --zone=${ZONE}
Le résultat ressemble à ceci :
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central1-a 4 v5litepod-16 ACTIVE ...
Console
Démarrer votre job dans un environnement provisionné
Vous pouvez exécuter manuellement des charges de travail en vous connectant à tous les hôtes de chaque tranche via SSH et en exécutant la commande suivante sur tous les hôtes.
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone=${ZONE} \ --worker=all \ --command="command-to-run"
Réinitialiser les QR
L'API ResetQueuedResource peut être utilisée pour réinitialiser toutes les VM d'un QR ACTIVE. La réinitialisation forcée des VM efface la mémoire de la machine et rétablit l'état initial de la VM. Toutes les données stockées localement resteront intactes et le script de démarrage sera appelé après une réinitialisation. L'API ResetQueuedResource peut être utile lorsque vous souhaitez redémarrer tous les TPU. Par exemple, lorsque l'entraînement est bloqué et qu'il est plus facile de réinitialiser toutes les VM que de déboguer.
Les réinitialisations de toutes les VM sont effectuées en parallèle. Une opération ResetQueuedResource prend une à deux minutes. Pour appeler l'API, utilisez la commande suivante :
$ gcloud compute tpus queued-resources reset ${QR_ID} --zone=${ZONE}
Suppression des ressources en file d'attente
Pour libérer les ressources à la fin de votre session de formation, supprimez la ressource mise en file d'attente. La suppression prend entre deux et cinq minutes. Si vous utilisez la gcloud CLI, vous pouvez exécuter cette commande en arrière-plan avec le flag facultatif --async.
gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --zone=${ZONE} --force [--async]
Console
Récupération automatique en cas d'échec
En cas d'interruption, Multislice propose une réparation sans intervention de la tranche concernée et une réinitialisation de toutes les tranches par la suite. La tranche concernée est remplacée par une nouvelle tranche, et les autres tranches saines sont réinitialisées. Si aucune capacité n'est disponible pour allouer une tranche de remplacement, l'entraînement s'arrête.
Pour reprendre l'entraînement automatiquement après une interruption, vous devez spécifier un script de démarrage qui vérifie et charge les derniers points de contrôle enregistrés. Votre script de démarrage s'exécute automatiquement chaque fois qu'une tranche est réattribuée ou qu'une VM est réinitialisée. Vous spécifiez un script de démarrage dans la charge utile JSON que vous envoyez à l'API de requête de création de QR.
Le script de démarrage suivant (utilisé dans Créer des QR) vous permet de récupérer automatiquement les données en cas d'échec et de reprendre l'entraînement à partir des points de contrôle stockés dans un bucket Cloud Storage pendant l'entraînement MaxText :
{
"tpu": {
"node_spec": [
{
...
"metadata": {
"startup-script": "#! /bin/bash \n pwd \n runuser -l user1 -c 'cd /home/user1/MaxText && python3 -m MaxText.train MaxText/configs/base.yml run_name=run_test_failure_recovery dcn_data_parallelism=4 ici_fsdp_parallelism=8 steps=10000 save_period=10 base_output_directory='gs://user1-us-central2'' EOF"
}
...
}
]
}
}
Clonez le dépôt MaxText avant d'essayer.
Profilage et débogage
Le profilage est identique dans les environnements à tranche unique et dans les environnements Multislice. Pour en savoir plus, consultez Profiler des programmes JAX.
Optimiser l'entraînement
Les sections suivantes décrivent comment optimiser l'entraînement Multislice.
Segmentation avec Multislice pour des performances maximales
Pour obtenir des performances maximales dans les environnements Multislice, vous devez réfléchir à la manière de segmenter les données sur plusieurs tranches. Il existe généralement trois choix (parallélisme des données, parallélisme des données entièrement segmentées et parallélisme du pipeline). Nous vous déconseillons de segmenter les activations dans les dimensions du modèle (parfois appelé parallélisme tensoriel), car cela nécessite une bande passante inter-tranches trop importante. Pour toutes ces stratégies, vous pouvez conserver la même stratégie de segmentation dans une tranche qui a fonctionné pour vous par le passé.
Nous vous recommandons de commencer par le parallélisme des données pures. L'utilisation du parallélisme des données entièrement segmentées est utile pour libérer de la mémoire. L'inconvénient est que la communication entre les tranches utilise le réseau DCN et ralentit votre charge de travail. N'utilisez le parallélisme de pipeline que lorsque cela est nécessaire en fonction de la taille du lot (comme analysé ci-dessous).
Quand utiliser le parallélisme des données
Le parallélisme pur des données fonctionnera bien dans les cas où vous avez une charge de travail qui s'exécute correctement, mais que vous souhaitez améliorer ses performances en la répartissant sur plusieurs tranches.
Pour obtenir un scaling fort sur plusieurs tranches, le temps nécessaire pour effectuer une réduction globale sur le DCN doit être inférieur au temps nécessaire pour effectuer une propagation arrière. Le DCN est utilisé pour la communication entre les tranches et constitue un facteur limitant du débit de la charge de travail.
Chaque puce TPU v4 offre un pic de 275 * 1012 FLOPS par seconde.
Chaque hôte TPU comporte quatre puces et une bande passante réseau maximale de 50 Gbit/s.
Cela signifie que l'intensité arithmétique est de 4 * 275 * 1012 FLOPS/50 Gbit/s = 22 000 FLOPS/bit.
Votre modèle utilisera entre 32 et 64 bits de bande passante DCN pour chaque paramètre par étape. Si vous utilisez deux tranches, votre modèle utilisera 32 bits de bande passante DCN. Si vous utilisez plus de deux tranches, le compilateur effectue une opération all-reduce de permutation complète et vous utilisez jusqu'à 64 bits de bande passante DCN pour chaque paramètre par étape. Le nombre de FLOPS nécessaires pour chaque paramètre varie en fonction de votre modèle. Plus précisément, pour les modèles de langage basés sur Transformer, le nombre de FLOPS requis pour une propagation avant et une propagation arrière est d'environ 6 * B * P, où :
Le nombre de FLOPS par paramètre est de 6 * B et le nombre de FLOPS par paramètre lors de la propagation arrière est de 4 * B.
Pour assurer un scaling fort sur plusieurs tranches, assurez-vous que l'intensité opérationnelle dépasse l'intensité arithmétique du matériel TPU. Pour calculer l'intensité opérationnelle, divisez le nombre de FLOPS par paramètre lors de la propagation arrière par la bande passante du réseau (en bits) par paramètre et par étape :
Operational Intensity = FLOPSbackwards_pass / DCN bandwidth
Par conséquent, pour un modèle de langage basé sur Transformer, si vous utilisez deux tranches :
Operational intensity = 4 * B / 32
Si vous utilisez plus de deux tranches : Operational intensity = 4 * B/64
Cela suggère une taille de lot minimale comprise entre 176 000 et 352 000 pour les modèles de langage basés sur Transformer. Étant donné que le réseau DCN peut brièvement supprimer des paquets, il est préférable de maintenir une marge d'erreur importante et de déployer le parallélisme des données uniquement si la taille du lot par pod est d'au moins 350 000 (deux pods) à 700 000 (plusieurs pods).
Pour les autres architectures de modèle, vous devrez estimer le temps d'exécution de votre propagation arrière par tranche (en le chronométrant à l'aide d'un profileur ou en comptant les FLOPS). Vous pouvez ensuite comparer cette valeur au temps d'exécution attendu pour une opération all-reduce sur DCN afin d'obtenir une bonne estimation de l'utilité du parallélisme des données pour vous.
Quand utiliser le parallélisme des données entièrement segmentées (FSDP)
Le parallélisme des données entièrement segmentées (FSDP) combine le parallélisme des données (segmentation des données sur les nœuds) avec la segmentation des pondérations sur les nœuds. Pour chaque opération de propagation avant et arrière, les pondérations sont collectées afin que chaque tranche dispose des pondérations dont elle a besoin. Au lieu de synchroniser les gradients à l'aide de l'opération all-reduce, ils sont répartis au fur et à mesure de leur production. De cette façon, chaque tranche n'obtient que les gradients pour les pondérations dont elle est responsable.
Comme pour le parallélisme des données, FSDP nécessitera de mettre à l'échelle la taille de lot globale de manière linéaire avec le nombre de tranches. FSDP réduit la pression sur la mémoire à mesure que vous augmentez le nombre de tranches. En effet, le nombre de pondérations et l'état de l'optimiseur par tranche diminuent, mais au prix d'un trafic réseau accru et d'une plus grande possibilité de blocage en raison d'un collectif retardé.
En pratique, FSDP sur les tranches est préférable si vous augmentez la taille du lot par tranche, si vous stockez plus d'activations pour minimiser la rematérialisation lors de la propagation arrière ou si vous augmentez le nombre de paramètres dans votre réseau de neurones.
Les opérations all-gather et all-reduce dans FSDP fonctionnent de la même manière que dans DP. Vous pouvez donc déterminer si votre charge de travail FSDP est limitée par les performances DCN de la même manière que décrit dans la section précédente.
Quand utiliser le parallélisme de pipeline ?
Le parallélisme de pipeline devient pertinent lorsque vous souhaitez obtenir des performances élevées avec d'autres stratégies de parallélisme qui nécessitent une taille de lot globale supérieure à la taille de lot maximale de votre choix. Le parallélisme de pipeline permet aux tranches qui composent un pipeline de "partager" un lot. Toutefois, le parallélisme de pipeline présente deux inconvénients majeurs :
Le parallélisme de pipeline ne doit être utilisé que si les autres stratégies de parallélisme nécessitent une taille de lot globale trop importante. Avant d'essayer le parallélisme de pipeline, il est intéressant de vérifier empiriquement si la convergence par échantillon ralentit à la taille de lot nécessaire pour obtenir un FSDP très performant. FSDP a tendance à obtenir une utilisation plus élevée des FLOP du modèle, mais si la convergence par échantillon ralentit à mesure que la taille du lot augmente, le parallélisme de pipeline peut toujours être le meilleur choix. La plupart des charges de travail peuvent tolérer des tailles de lot suffisamment importantes pour ne pas bénéficier du parallélisme de pipeline, mais votre charge de travail peut être différente.
Si le parallélisme de pipeline est nécessaire, nous vous recommandons de le combiner avec le parallélisme de données ou FSDP. Cela vous permettra de minimiser la profondeur du pipeline tout en augmentant la taille du lot par pipeline jusqu'à ce que la latence DCN devienne moins un facteur de débit. Concrètement, si vous avez N tranches, envisagez d'utiliser des pipelines de profondeur 2 et N/2 instances répliquées de parallélisme des données, puis des pipelines de profondeur 4 et N/4 instances répliquées de parallélisme des données, et ainsi de suite, jusqu'à ce que le lot par pipeline devienne suffisamment grand pour que les collectifs DCN puissent être masqués derrière l'arithmétique dans la propagation arrière. Cela permet de minimiser le ralentissement introduit par le parallélisme de pipeline tout en vous permettant de dépasser la limite de taille de lot globale.
Bonnes pratiques concernant Multislice
Les sections suivantes décrivent les bonnes pratiques pour l'entraînement Multislice.
Chargement des données…
Pendant l'entraînement, nous chargeons à plusieurs reprises des lots à partir d'un ensemble de données pour les fournir au modèle. Il est important de disposer d'un chargeur de données asynchrone et efficace qui segmente le lot sur les hôtes pour éviter de priver les TPU de travail. Dans MaxText, le chargeur de données actuel permet à chaque hôte de charger un sous-ensemble égal d'exemples. Cette solution est adaptée au texte, mais nécessite une re-segmentation dans le modèle. De plus, MaxText ne propose pas encore de création d'instantanés déterministes, ce qui permettrait à l'itérateur de données de charger les mêmes données avant et après la préemption.
Points de contrôle
La bibliothèque de points de contrôle Orbax fournit des primitives pour le point de contrôle des PyTrees JAX vers le stockage local ou le stockage Google Cloud .
Nous fournissons une intégration de référence avec la création de points de contrôle synchrones dans MaxText dans checkpointing.py.
Configurations compatibles
Les sections suivantes décrivent les formes de tranche, l'orchestration, les frameworks et le parallélisme compatibles avec Multislice.
Formes
Toutes les tranches doivent avoir la même forme (par exemple, le même AcceleratorType). Les formes de tranche hétérogènes ne sont pas acceptées.
Orchestration
L'orchestration est compatible avec GKE. Pour en savoir plus, consultez la section TPU dans GKE.
Frameworks
Multislice n'est compatible qu'avec les charges de travail JAX et PyTorch.
Parallélisme
Nous recommandons aux utilisateurs de tester Multislice avec le parallélisme des données. Pour en savoir plus sur l'implémentation du parallélisme de pipeline avec Multislice, contactez votre responsable de compteGoogle Cloud .
Assistance et commentaires
Tous vos commentaires sont les bienvenus. Pour partager vos commentaires ou demander de l'aide, contactez-nous à l'aide du formulaire d'assistance ou de commentaires Cloud TPU.