Architecture des TPU
Les TPU (Tensor Processing Units) sont des circuits intégrés propres aux applications (ASIC) conçus par Google pour accélérer les charges de travail de machine learning. Cloud TPU est un service Google Cloud qui met à disposition les TPU en tant que ressource évolutive.
Les TPU sont conçus pour effectuer rapidement des opérations matricielles, ce qui les rend idéaux pour les charges de travail de machine learning. Vous pouvez exécuter des charges de travail de machine learning sur des TPU à l'aide de frameworks tels que Pytorch et JAX.
Comment fonctionnent les TPU ?
Pour comprendre le fonctionnement des TPU, il convient de comprendre comment d'autres accélérateurs gèrent les difficultés de calcul liées à l'entraînement des modèles de ML.
Fonctionnement d'un CPU
Un CPU est un processeur à usage général basé sur l'architecture von Neumann. Cela signifie qu'un CPU fonctionne avec un logiciel et une mémoire, comme illustré ci-dessous :
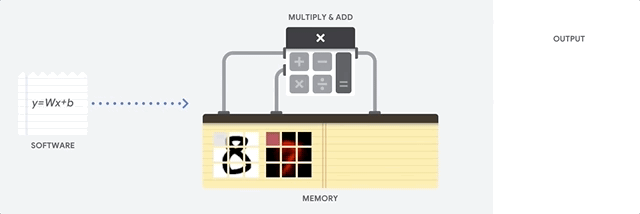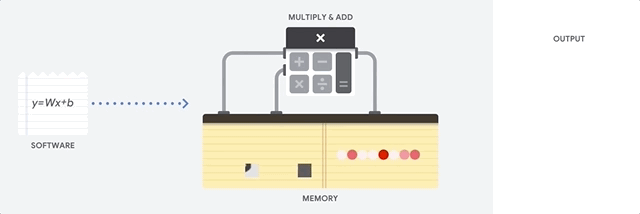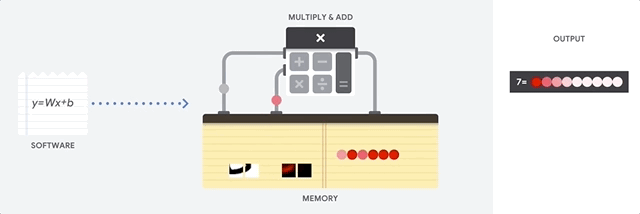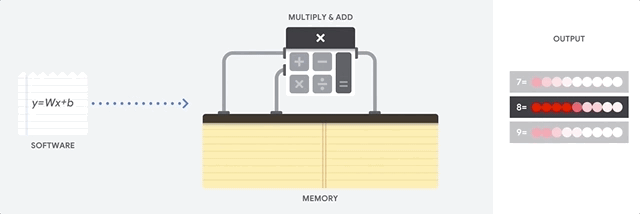
Le principal avantage des CPU est leur flexibilité. Vous pouvez charger n'importe quel type de logiciel sur un CPU pour différents types d'applications. Par exemple, un CPU peut servir au traitement de texte sur un PC, au contrôle des moteurs de fusées, à l'exécution de transactions bancaires ou au classement d'images avec un réseau de neurones.
Un CPU charge les valeurs à partir de la mémoire, effectue un calcul sur les valeurs et stocke le résultat en mémoire pour chaque calcul. Cependant, l'accès à la mémoire est lent par rapport à la vitesse de calcul, ce qui peut limiter le débit total des CPU. On parle souvent de goulot d'étranglement von Neumann.
Fonctionnement d'un GPU
Pour obtenir un débit supérieur à celui d'un CPU, les GPU contiennent des milliers d'unités arithmétiques et logiques (ALU) dans un seul processeur. Un GPU moderne contient généralement entre 2 500 et 5 000 ALU. Grâce à ce grand nombre de processeurs, vous pouvez exécuter des milliers de multiplications et d'additions simultanément.

Cette architecture GPU fonctionne bien sur les applications à parallélisme massif, comme les opérations matricielles dans un réseau de neurones. En réalité, avec une charge de travail d'entraînement classique pour le deep learning, un GPU peut fournir une commande beaucoup plus importante qu'un processeur.
Toutefois, le GPU reste un processeur à usage général qui doit prendre en charge de nombreuses applications et logiciels différents. Par conséquent, les GPU rencontrent le même problème que les CPU. Pour chaque calcul réalisé dans les milliers d'ALU, un GPU doit accéder aux registres ou à la mémoire partagée pour lire les opérandes et stocker les résultats de calcul intermédiaires.
Fonctionnement d'un TPU
Cloud TPU a été conçu par Google comme un processeur matriciel spécialisé dans les charges de travail des réseaux de neurones. Les TPU ne peuvent pas faire de traitement de texte ni contrôler les moteurs de fusées ou exécuter des transactions bancaires, mais ils peuvent gérer des opérations matricielles massives dans les réseaux de neurones, à des vitesses très élevées.
La tâche principale des TPU est le traitement matriciel, qui est une combinaison d'opérations de multiplication et d'addition. Les TPU contiennent des milliers d'accumulateurs multiplicateurs qui sont directement connectés les uns aux autres pour former une grande matrice physique. C'est ce qu'on appelle une architecture de tableau systolique. Cloud TPU v3 contient deux tableaux systoliques de 128 x 128 ALU sur un seul processeur.
L'hôte TPU diffuse les données dans une file d'attente d'ingestion. Le TPU charge les données de la file d'attente d'ingestion et les stocke dans la mémoire HBM. Une fois le calcul terminé, le TPU charge les résultats dans la file d'attente de sortie. L'hôte TPU lit ensuite les résultats de la file d'attente de sortie et les stocke dans la mémoire de l'hôte.
Pour effectuer les opérations matricielles, le TPU charge les paramètres de la mémoire HBM dans l'unité de multiplication matricielle (MXU).

Ensuite, le TPU charge les données de la mémoire HBM. À chaque exécution d'une multiplication, le résultat est transmis à l'accumulateur multiplicateur suivant. Le résultat correspond à la somme de tous les résultats de multiplication entre les données et les paramètres. Aucun accès à la mémoire n'est requis lors du processus de multiplication matricielle.
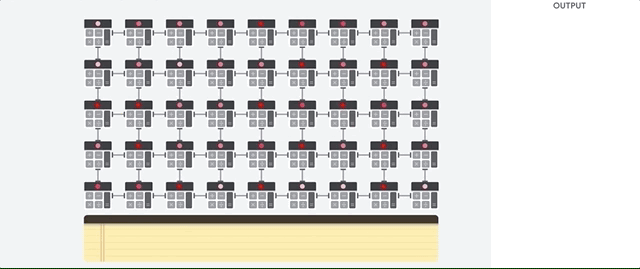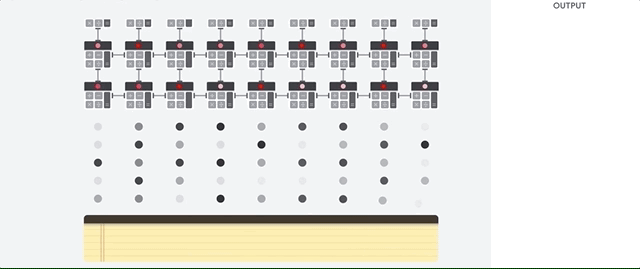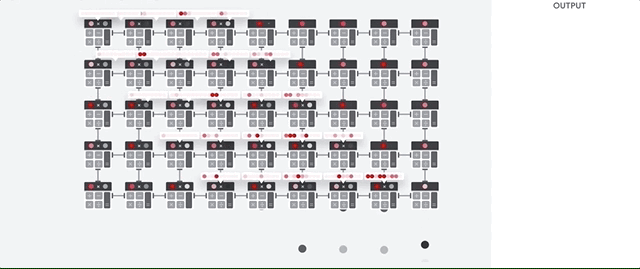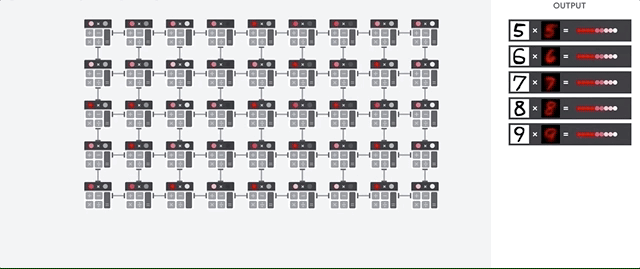
Par conséquent, les TPU peuvent atteindre un débit de calcul élevé sur les calculs de réseau de neurones.
Architecture du système TPU
Les sections suivantes décrivent les concepts clés d'un système TPU. Pour en savoir plus sur les termes courants du machine learning, consultez le Glossaire du machine learning.
Si vous débutez avec Cloud TPU, consultez la page d'accueil de la documentation TPU.
Puce TPU
Une puce TPU contient un ou plusieurs TensorCores. Le nombre de TensorCores dépend de la version de la puce TPU. Chaque TensorCore se compose d'une ou plusieurs unités de multiplication matricielle (MXU), d'une unité vectorielle et d'une unité scalaire. Pour en savoir plus sur les TensorCores, consultez A Domain-Specific Supercomputer for Training Deep Neural Networks.
Une unité matricielle est composée de 256 x 256 (TPU v6e) ou 128 x 128 (versions TPU antérieures à v6e) accumulateurs multiplicateurs dans un tableau systolique. Les unités matricielles fournissent la majorité de la puissance de calcul d'un TensorCore. Chaque unité matricielle est capable d'effectuer 16 000 opérations de multiplication/addition par cycle. Toutes les multiplications prennent des entrées bfloat16, mais toutes les accumulations sont effectuées au format numérique FP32.
L'unité vectorielle est utilisée pour les calculs généraux tels que les activations et softmax. L'unité scalaire est utilisée pour le flux de contrôle, le calcul d'adresses mémoire et d'autres opérations de maintenance.
Pod TPU
Un pod TPU est un ensemble contigu de TPU regroupés sur un réseau spécialisé. Le nombre de puces TPU dans un pod TPU dépend de la version du TPU.
Tranche
Une tranche est un ensemble de puces situées dans le même pod TPU et connectées par des interconnexions entre puces (ICI) à haut débit. Les tranches sont décrites en termes de puces ou de TensorCores, selon la version du TPU.
Forme de puce et topologie de puce font également référence aux formes de tranche.
Multislice ou tranche unique
Multislice est un groupe de tranches qui étend la connectivité TPU au-delà des connexions ICI et utilise le réseau de centre de données (DCN) pour transmettre des données au-delà d'une tranche. Les données de chaque tranche sont toujours transmises par l'ICI. Grâce à cette connectivité hybride, Multislice permet un parallélisme entre les tranches et vous permet d'utiliser sur un job unique un plus grand nombre de cœurs de TPU que ne le permettrait une simple tranche.
Les TPU peuvent être utilisés pour exécuter un job sur une ou plusieurs tranches. Pour en savoir plus, consultez la présentation du multislice.
Cube TPU
Topologie 4x4x4 de puces TPU interconnectées. Cela ne s'applique qu'aux topologies 3D (à partir de TPU v4).
SparseCore
Les SparseCores sont des processeurs Dataflow qui accélèrent les modèles à l'aide d'opérations éparses. L'un des principaux cas d'utilisation est l'accélération des modèles de recommandation qui reposent fortement sur les embeddings. TPU v5p inclut quatre SparseCores par puce, et TPU v6e en inclut deux par puce. Pour obtenir une explication détaillée de l'utilisation des SparseCores, consultez Présentation détaillée de SparseCore pour les grands modèles d'embedding (LEM). Vous contrôlez la façon dont le compilateur XLA utilise les SparseCores à l'aide des flags XLA. Pour en savoir plus, consultez Flags XLA pour TPU.
Résilience de l'interconnexion entre puces (ICI) Cloud TPU
La résilience ICI permet d'améliorer la tolérance aux pannes des liaisons optiques et des commutateurs de circuits optiques (OCS) qui connectent les TPU entre les cubes. (Les connexions ICI à l'intérieur d'un cube utilisent des liens en cuivre qui ne sont pas concernés.) La résilience ICI permet aux connexions ICI de contourner les défaillances ICI des liaisons OCS et optiques. Cela améliore la disponibilité de la planification des tranches TPU, mais entraîne en retour une dégradation temporaire des performances de l'ICI.
Pour Cloud TPU v4 et v5p, la résilience ICI est activée par défaut pour les tranches dont la taille et d'un cube ou plus, par exemple :
- v5p-128 lors de la spécification du type d'accélérateur
- 4x4x4 lors de la spécification de la configuration de l'accélérateur
Versions de TPU
L'architecture exacte d'une puce TPU dépend de la version de TPU que vous utilisez. Chaque version de TPU prend aussi en charge différentes tailles et configurations de tranche. Pour en savoir plus sur l'architecture du système et les configurations compatibles, consultez les pages suivantes :
Architecture cloud TPU
Google Cloud met à disposition les TPU en tant que ressources de calcul via des VM TPU. Vous pouvez utiliser directement les VM TPU pour vos charges de travail ou les utiliser via Google Kubernetes Engine ou Vertex AI. Les sections suivantes décrivent les principaux composants de l'architecture cloud des TPU.
Architecture de VM TPU
L'architecture des VM TPU vous permet de vous connecter directement à la VM physiquement connectée à l'appareil TPU via SSH. Une VM TPU, que l'on appelle également un "travailleur", est une machine virtuelle exécutant Linux et ayant accès aux TPU sous-jacents. Vous obtenez un accès racine à la VM afin de pouvoir exécuter le code de votre choix. Vous avez accès aux journaux de débogage du compilateur et de l'environnement d'exécution, ainsi qu'aux messages d'erreur.

Hôte unique, hôtes multiples et sous-hôte
Un hôte TPU est une VM qui s'exécute sur un ordinateur physique connecté à du matériel TPU. Les charges de travail TPU peuvent utiliser un ou plusieurs hôtes.
Une charge de travail à hôte unique est limitée à une VM TPU. Une charge de travail multi-hôte distribue l'entraînement sur plusieurs VM TPU. Une charge de travail sous-hôte n'utilise pas tous les puces d'une VM TPU.
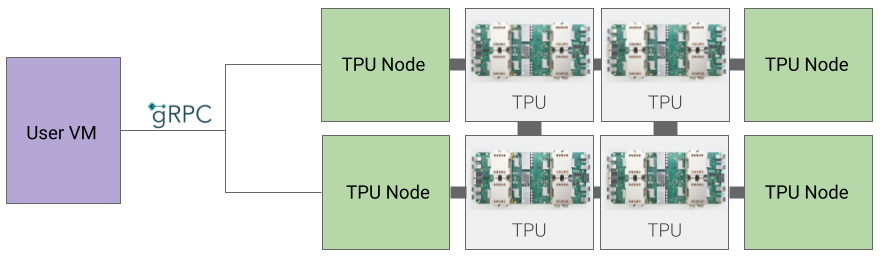
Architecture de nœud TPU (obsolète)
L'architecture de nœud TPU se compose d'une VM utilisateur qui communique avec l'hôte TPU via gRPC. Lorsque vous utilisez cette architecture, vous ne pouvez pas accéder directement à l'hôte TPU, ce qui rend difficile le débogage des erreurs d'entraînement et de TPU.
Passer d'une architecture de nœud TPU à une architecture de VM TPU
Si vous disposez de TPU utilisant l'architecture de nœud TPU, suivez les étapes ci-dessous pour les identifier, les supprimer et les reprovisionner en tant que VM TPU.
Accédez à la page des TPU :
Recherchez votre TPU et son architecture sous l'en-tête Architecture. Si l'architecture est "VM TPU", aucune action n'est requise de votre part. Si l'architecture est "Nœud TPU", vous devez supprimer le TPU et le provisionner à nouveau.
Supprimez le TPU, puis provisionnez-le à nouveau.
Consultez Gérer des TPU pour savoir comment supprimer et reprovisionner des TPU.