Cloud SQL では、バックアップから、またはポイントインタイム リカバリ(PITR)を実行することによってインスタンスを復元できます。これにより、バックアップを既存のインスタンスに復元するか、バックアップを新しいインスタンスに復元することで、インスタンスを特定の期間または時間に復元できます。復元するには、ライブ インスタンスまたは削除されたインスタンスのバックアップを使用します。復元オペレーションによって、ソース インスタンスの設定、データベース、ユーザーが取得されて、選択したターゲット インスタンスに設定されます。
新しいインスタンスに復元する場合、ターゲット インスタンスはソース インスタンスとは異なるリージョンまたはプロジェクトに存在できます。ターゲット インスタンスは、ソース インスタンスとは異なるコア数やメモリ容量を使用することもできます。
Cloud SQL は常に、ターゲット インスタンスのストレージ容量を、構成されたディスクとバックアップ ディスクの両方のサイズの最大値に設定します。バックアップ ディスクは、バックアップ取得時のディスクのサイズになります。
インスタンスで復元を実行する場合は、次の点を考慮してください。
- 復元オペレーションは、ターゲット インスタンスのすべてのデータを上書きします。
- ソース インスタンスのフラグは復元されません。ターゲット インスタンスで以前に設定されたフラグは、復元後も保持されます。
- 復元オペレーション中は既存の接続が失われるため、ターゲット インスタンスは接続に使用できません。
- リードレプリカがあるインスタンスに復元する場合は、すべてのレプリカを削除し、復元オペレーションの完了後に再作成する必要があります。
- 復元オペレーションによってインスタンスが再起動されます。
- バックアップから復元すると、ターゲット インスタンスのバックアップ構成がデフォルト値に設定されます。ソース インスタンスにカスタム バックアップ構成が存在していた場合や、拡張バックアップを使用していた場合は、復元が完了した後にバックアップ構成を更新する必要があります。
バックアップを使用して復元する
Cloud SQL では、バックアップを使用してインスタンスを復元できます。ライブ インスタンスまたは削除済みインスタンスのバックアップを使用して、新しいインスタンスまたは既存のインスタンスに復元できます。利用可能なバックアップを使用して、インスタンスを復元できます。Cloud SQL でのバックアップの仕組みについて詳しくは、バックアップの概要をご覧ください。
バックアップを使用してインスタンスを復元するときに、次の操作を行うことができます。
- 新しいインスタンスに復元する
- 既存のインスタンスに復元する
- 別のプロジェクトまたはリージョンのインスタンスに復元する
サービスが停止した場合でも、特定のプロジェクトのバックアップのリストを取得して、復元できます。
バックアップを使用してインスタンスを復元するには、バックアップを使用してインスタンスを復元するをご覧ください。
ポイントインタイム リカバリ(PITR)
PITR を使用すると、インスタンスをデータベースの特定の時点に復元できます。たとえば、エラーによってデータが失われた場合に、エラーが発生する前の状態にデータベースを復元できます。バックアップを使用した復元とは異なり、PITR では常に新しいインスタンスが作成されます。既存のインスタンスに対して PITR を実行することはできません。新しいインスタンスは、クローンを作成する場合と同様に、ソース インスタンスの設定を継承します。
Cloud SQL Enterprise Plus エディションのインスタンスを作成する場合、PITR はデフォルトで有効になります。この機能を無効にするには、手動で行う必要があります。
Google Cloud コンソールで Cloud SQL Enterprise エディションのインスタンスを作成する場合、PITR はデフォルトで有効になります。 それ以外の場合、gcloud CLI、Terraform、または Cloud SQL Admin API を使用してインスタンスを作成するときには、PITR はデフォルトで無効になります。これらのインスタンスで PITR を有効にするには、手動で有効にする必要があります。
PITR を実行する手順ガイドについては、ポイントインタイム リカバリ(PITR)を使用するをご覧ください。
PITR 用のログストレージ
PITR では、ログをアーカイブします。バックアップを使用して既存のインスタンスを復元すると、これらのアーカイブログが削除され、PITR を実行するために使用できなくなります。復元が完了した後に生成された新しいログのみを PITR に使用できます。
2024 年 5 月 31 日、Google は、PITR のトランザクション ログの Cloud Storage への保存を開始しました。今回のリリース以降、次の条件が適用されます。
Cloud SQL Enterprise Plus エディションのインスタンスはすべて、PITR に使用されるトランザクション ログを Cloud Storage に保存します。2024 年 4 月 1 日より前に Cloud SQL Enterprise エディションからアップグレードし、2024 年 5 月 31 日より前に PITR を有効にした Cloud SQL Enterprise Plus エディションのインスタンスのみが、PITR のログをディスクに保存します。
2024 年 5 月 31 日より前に PITR を有効にして作成された Cloud SQL Enterprise エディションのインスタンスは、引き続き PITR のログをディスクに保存します。
2024 年 5 月 31 日以降に、PITR 用のトランザクション ログをディスクに保存する Cloud SQL Enterprise エディションのインスタンスを Cloud SQL Enterprise Plus エディションにアップグレードすると、アップグレード プロセスで PITR 用のトランザクション ログの保存場所が Cloud Storage に切り替わります。詳細については、インプレース アップグレードを使用してインスタンスを Cloud SQL Enterprise Plus エディションにアップグレードするをご覧ください。
2024 年 5 月 31 日より後に PITR を有効にして作成したすべての Cloud SQL Enterprise エディションのインスタンスは、PITR に使用されるログを Cloud Storage に保存します。
インスタンスがトランザクション ログの保存に Cloud Storage を使用している場合、ログはプライマリ インスタンスと同じリージョンに保存されます。これらのログは、Cloud SQL Enterprise Plus エディションでは最大 35 日間、Cloud SQL Enterprise エディションでは最大 7 日間保存され、インスタンスごとの追加費用は発生しません。
PITR に使用されるトランザクション ログの保存場所を確認する方法について詳しくは、インスタンスのトランザクション ログの保存場所を確認するをご覧ください。
ディスクにのみトランザクション ログを保存するインスタンスの場合、gcloud CLI または Cloud SQL Admin API を使用して、PITR に使用されるトランザクション ログの保存場所をディスクから Cloud Storage に切り替えることができます。詳細については、トランザクション ログ ストレージを Cloud Storage に切り替えるをご覧ください。
インスタンスのログがディスクではなく Cloud Storage に保存されるようにするには、次の操作を行います。
- インスタンスのネットワーク アーキテクチャを確認します。 インスタンスが古いネットワーク アーキテクチャを使用している場合は、新しいネットワーク アーキテクチャにアップグレードします。
ディスク上のログのサイズが原因でインスタンスのパフォーマンスの問題が発生している場合は、PITR を無効にしてから再度有効にします。この操作を行うと、新しいログがディスクではなく Cloud Storage に保存される状態を確保できます。
ログの保持期間
Cloud SQL は、transactionLogRetentionDays PITR 構成設定で設定された値まで、Cloud Storage にトランザクション ログを保持します。この値は、Cloud SQL Enterprise Plus エディションでは 1~35 日、Cloud SQL Enterprise エディションでは 1~7 日の範囲に設定できます。このパラメータの値が設定されていない場合、デフォルトのトランザクション ログ保持期間は、Cloud SQL Enterprise Plus エディションのインスタンスでは 14 日間、Cloud SQL Enterprise エディションのインスタンスでは 7 日間です。トランザクション ログの保持期間を設定する方法について詳しくは、トランザクション ログの保持期間を設定するをご覧ください。
インスタンスは、PITR に使用されるトランザクション ログを Cloud Storage に保存しますが、ログを Cloud Storage にレプリケートできるように、少数の重複トランザクション ログをディスクにも保持します。デフォルトでは、PITR を有効にしてインスタンスを作成すると、インスタンスは PITR 用のトランザクション ログを Cloud Storage に保存します。Cloud SQL では、expire_logs_days フラグと binlog_expire_logs_seconds フラグの値も 1 日に相当する値に自動的に設定されます。これらの設定値で、ディスクに 1 日分のログが保存されます。
PITR トランザクション ログがディスクに保存されている場合、Cloud Storage に切り替えられている場合、またはすでに Cloud Storage に切り替えられた場合、Cloud SQL は次の構成に設定された値のうち最短となる期間、ログを保持します。
transactionLogRetentionDaysバックアップ構成設定expire_logs_daysフラグまたはbinlog_expire_logs_secondsフラグ
トランザクション ログがディスクに保存されている場合、Cloud Storage に切り替えられている場合、またはすでに Cloud Storage に切り替えられた場合、Cloud SQL はこれらのフラグの値を設定しません。ログがディスクに保存されている場合、これらのフラグの値を変更すると、PITR の復元の動作や、何日分のログがディスクに保存されるかに影響する可能性があります。ログの保存場所が Cloud Storage に切り替えられている間は、フラグの値を変更できません。また、いずれかのフラグの値を 0 に構成することはおすすめしません。詳細については、データベース フラグを構成するをご覧ください。
transactionLogRetentionDays構成設定expire_logs_daysデータベース フラグbinlog_expire_logs_secondsデータベース フラグ
たとえば、パフォーマンスの問題を回避するには、フラグの値を数日間にわたって毎日 1 日ずつ減らします。その結果、Cloud SQL はすべてのトランザクション ログを同時にパージしません。
顧客管理の暗号鍵(CMEK)対応のインスタンスの場合、トランザクション ログは最新バージョンの CMEK を使用して暗号化されます。復元を実施するには、retained-transaction-log-days パラメータの一部として保持されているすべての日について、最新の鍵バージョンが必要です。
PITR の制限事項
インスタンスで PITR が有効になっていて、ディスク上のトランザクション ログのサイズが原因でインスタンスに問題が発生している場合、次の制限が適用されます。
- PITR を無効にして再度有効にすると、Cloud SQL がログをインスタンスと同じリージョンの Cloud Storage に保存するようになります。ただし、Cloud SQL は既存のログを削除するため、PITR を再度有効にした時点よりも前に PITR オペレーションを実行することはできません。
- インスタンスのストレージ サイズを増やすことはできますが、ディスク使用量のトランザクションログ サイズの増加は一時的なものである可能性があります。
- 予期しないストレージの問題を回避するには、ストレージの自動増量を有効にすることをおすすめします。この推奨事項は、インスタンスで PITR が有効になっていて、ログがディスクに保存されている場合にのみ適用されます。
データベース スナップショット
PITR が有効になっているインスタンス内のデータベースでは、SQL Server データベース スナップショットを使用できません。
データベース スナップショットは、PITR が依存するデータベースの完全バックアップとトランザクション ログのバックアップを妨げる可能性があります。この干渉により、インスタンス上のすべてのデータベースで PITR オペレーションが正常に完了しない可能性があります。
PITR 用のデータベース復旧モデル
インスタンスで PITR を有効にすると、Cloud SQL は既存のデータベースと後続のデータベースの復旧モデルを自動的に完全復旧モデルに設定します。
SQL Server の復旧モデルの詳細については、Microsoft のドキュメントをご覧ください。
PITR を実行する手順ガイドについては、[ポイントインタイム リカバリ(PITR)を使用する][perform-pitr] をご覧ください。
PITR を使用して削除したインスタンスを復元する
PITR を使用すると、削除後に Cloud SQL インスタンスを復元できます。この機能を使用するには、インスタンスが削除される前に、インスタンスで PITR と保持されたバックアップが有効になっている必要があります。有効にすると、インスタンスを削除した後も PITR ログが保持されます。
インスタンスが削除された後も、PITR ログは、インスタンスがライブ状態であったときに定義された保持設定に従います。PITR ログは、インスタンスの削除後、保持設定に基づいて段階的に期限切れになります。周期的な期間は、削除前のインスタンスに設定された PITR 保持期間に基づいて定義されます。たとえば、Cloud SQL Enterprise Plus エディションのインスタンスで PITR の保持期間が 14 日に設定されている場合、インスタンスの削除から 14 日後に最新の PITR ログが削除されます。PITR ログの有効期限が切れると、復元できなくなります。
インスタンス名は Cloud SQL でインスタンスが削除された後に再利用できるため、保持された PITR ログは Google Cloud で次のフィールドを使用して識別できます。
instance_deletion_timelog_retention_days
これらのフィールドを使用すると、PITR ログが削除されたインスタンスに属しているかどうかを特定できます。
PITR 復元期間は、PITR を使用してインスタンスを復元するために使用できる最も新しい復元時間と最も古い復元時間として定義されます。削除したインスタンスの最も古い復元時刻と最も新しい復元時刻を確認するには、最も古い復元時刻と最も新しい復元時刻を取得するをご覧ください。
インスタンスの削除後に PITR を使用してインスタンスを復元するには、削除されたインスタンスで PITR を実行するをご覧ください。
新しいインスタンスに復元するための要件
インスタンスを新しいインスタンスに復元する場合は、次の要件に注意してください。
ターゲット インスタンスのデータベースは、バックアップの取得元であるインスタンスのデータベースと同じバージョンであることが必要です。
ターゲット インスタンスのストレージ容量は、バックアップされるインスタンスの容量と同じかそれ以上である必要があります。使用中のストレージ容量は関係ありません。インスタンスのストレージ容量は、コンソールの Cloud SQL インスタンス ページで確認できます。この要件は、単一のデータベースの PITR を実行するかどうかに関係なく適用されます。
ターゲット インスタンスは
RUNNABLEの状態であることが必要です。
復元のレート制限
1 つのプロジェクト、1 つのリージョン、1 つのインスタンスにつき、30 分ごとに最大 3 つの復元オペレーションが許可されます。復元オペレーションが失敗した場合は、この割り当てにカウントされません。上限に達するとオペレーションは失敗し、オペレーションの再実行が可能となるタイミングを示すエラー メッセージが表示されます。
Cloud SQL は、バケットからのトークンを使用して、一度に実行可能な復元オペレーションの数を決定します。各バックアップには、ターゲット プロジェクトとターゲット リージョンごとに 1 つのバケットがあります。同じリージョンにある場合、同じプロジェクトのターゲット インスタンスは 1 つのバケットを共有します。各バケットには、復元オペレーションに使用できるトークンが最大で 3 つあります。10 分ごとに新しいトークンがバケットに追加されます。バケットに空き容量がない場合、トークンはオーバーフローします。
復元オペレーションのたびに、バケットからトークンが付与されます。オペレーションが成功すると、バケットからトークンが削除されます。失敗した場合、トークンがバケットに返されます。次の図は、この仕組みを示しています。

たとえば、次の図では、Backup1、Backup2、Backup3 が同じソース インスタンスのバックアップです。
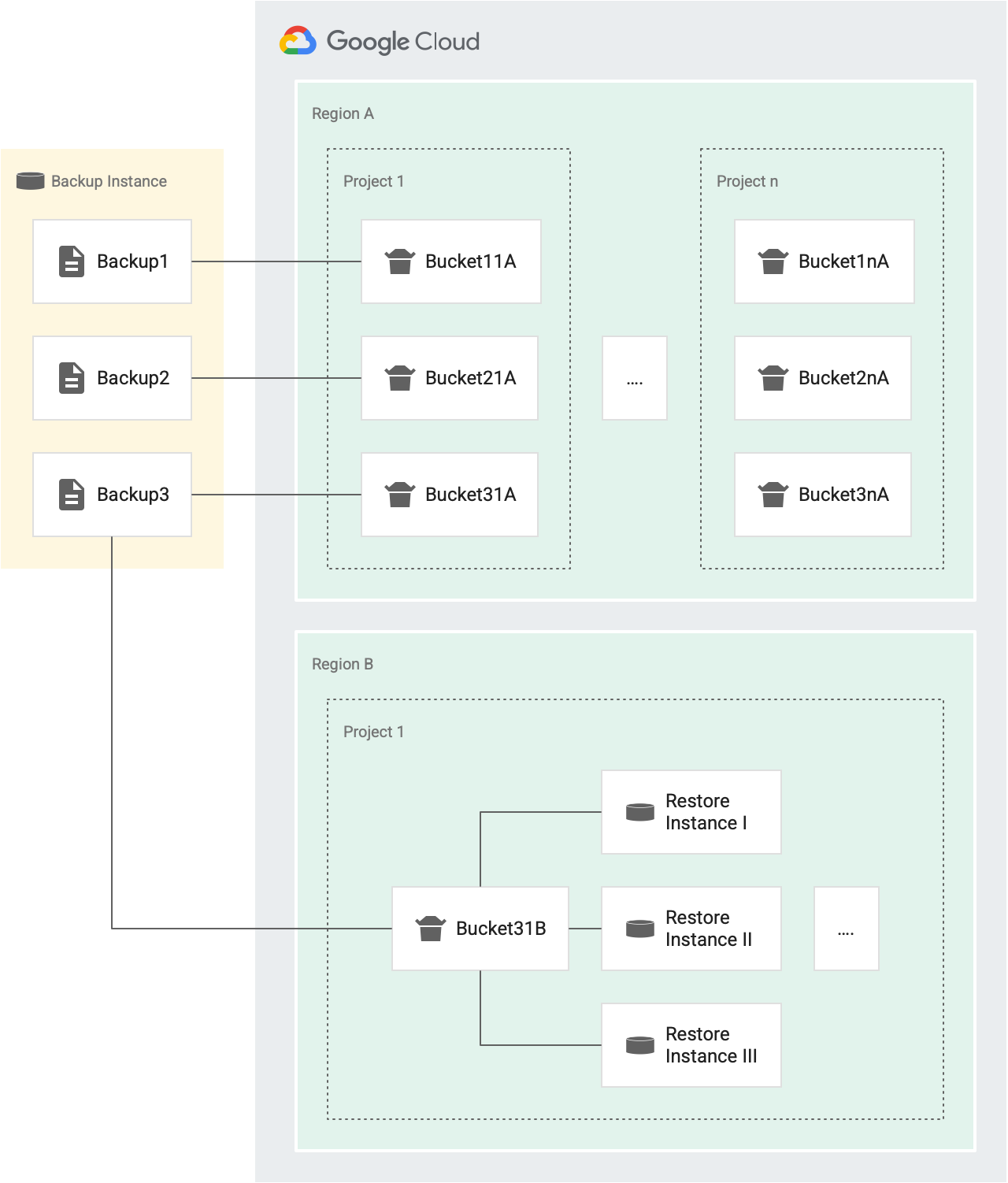
- 各バックアップ(Backup1、Backup2、Backup3)には、リージョン A のプロジェクト 1 の異なるインスタンスをターゲットとする復元オペレーション用のトークン バケットがあります(Bucket11A、Bucket21A、Bucket31A)。各バックアップには独自のバケットがあるため、30 分ごとに各バックアップを同じインスタンスに 3 回、復元できます。
- 各バックアップには、プロジェクトとリージョンごとに 1 つのバケットがあります。たとえば、リージョンに 5 つのプロジェクトがある場合、そのリージョンにバックアップ用のバケットが 5 つあります(プロジェクトごとに 1 つずつ)。上の図では、リージョン A にプロジェクト 1 とプロジェクト n の 2 つのプロジェクトがあります。
- Backup1 には、リージョン A の復元オペレーション用に 2 つのトークン バケットがあります。1 つのバケットはプロジェクト 1 用(Bucket11A)、もう 1 つのバケットはプロジェクト n 用(Bucket1nA)です。
- 同様に、Backup3 には、リージョン A での復元オペレーション用の 2 つのバケットがあります。1 つはプロジェクト 1 用(Bucket31A)、もう 1 つはプロジェクト n 用(Bucket3nA)です。
- 同じターゲット プロジェクトと同じターゲット リージョン内のすべてのインスタンスが 1 つのバケットを共有するため、Backup3 にはリージョン B にプロジェクト 1 用のパケットが 1 つあります。