La replica è la possibilità di creare copie di un'istanza Cloud SQL o di un database on-premise e di trasferire il lavoro alle copie.
Introduzione
Il motivo principale per utilizzare la replica è scalare l'utilizzo dei dati in un database senza peggiorare le prestazioni.
Altri motivi sono:
- Migrazione dei dati tra regioni
- Migrazione dei dati tra piattaforme
- Migrazione dei dati da un database on-premise a Cloud SQL
Inoltre, una replica potrebbe essere promossa se l'istanza originale viene danneggiata.
Quando si fa riferimento a un'istanza Cloud SQL, l'istanza replicata è chiamata istanza principale e le copie sono chiamate repliche di lettura. L'istanza principale e le repliche di lettura si trovano in Cloud SQL.
Quando si fa riferimento a un database on-premise, lo scenario di replica è chiamato replica da un server esterno. In questo scenario, il database replicato è il server di database di origine. Le copie che risiedono in Cloud SQL sono chiamate repliche Cloud SQL. Esiste anche un'istanza che rappresenta il server di database di origine in Cloud SQL chiamata istanza di rappresentazione dell'origine.
In uno scenario di ripristino di emergenza, puoi promuovere una replica per convertirla in un'istanza primaria. In questo modo, puoi utilizzarlo al posto di un'istanza che si trova in una regione in cui si è verificato un'interruzione. Puoi anche promuovere una replica per sostituire un'istanza danneggiata.
Cloud SQL supporta i seguenti tipi di repliche:
- Repliche di lettura
- Repliche di lettura tra regioni
- Repliche di lettura a cascata
- Repliche di lettura esterne
- Replica Cloud SQL, quando esegue la replica da un server esterno
Utilizzando l'applicazione del connettore, puoi forzare l'utilizzo solo del proxy di autenticazione Cloud SQL o dei connettori dei linguaggi di Cloud SQL per connetterti alle istanze Cloud SQL. Con l'applicazione del connettore, Cloud SQL rifiuta le connessioni dirette al database. Non puoi creare repliche di lettura per un'istanza per cui è abilitata l'applicazione del connettore. Allo stesso modo, se un'istanza ha repliche di lettura, non puoi abilitare l'applicazione del connettore per l'istanza.
Puoi anche utilizzare Database Migration Service per la replica continua da un server di database di origine a Cloud SQL.Cloud SQL non supporta la replica tra due server esterni.
Tuttavia, Cloud SQL supporta la
replica basata sull'ID transazione globale (GTID).
Gli ID transazione globali identificano in modo univoco ogni transazione sul server e all'interno di una
configurazione di replica. Poiché ogni transazione ha un identificatore univoco, il server MySQL
può tenere traccia delle transazioni che ha eseguito. Un GTID utilizza coordinate
assolute, quindi la replica di un'istanza Cloud SQL può puntare alla sua istanza
primaria e non devi specificare un nome file per il log binario o una
posizione nell'istruzione CHANGE MASTER. Ci sono meno errori
con le repliche e con il ripristino point-in-time. A causa di questi vantaggi,
non puoi disattivare la replica basata su GTID in Cloud SQL.
Repliche di lettura
Utilizzi una replica di lettura per trasferire il lavoro da un'istanza Cloud SQL. La replica di lettura è una copia esatta dell'istanza principale. I dati e le altre modifiche all'istanza primaria vengono aggiornati quasi in tempo reale sulla replica di lettura.
Le repliche di lettura sono di sola lettura, non puoi scriverci. La replica di lettura elabora query, richieste di lettura e traffico di analisi, riducendo così il carico sull'istanza primaria.
Ti connetti a una replica direttamente utilizzando il nome della connessione e l'indirizzo IP. Se ti connetti a una replica utilizzando un indirizzo IP privato, non devi creare una connessione privata VPC aggiuntiva per la replica perché la connessione viene ereditata dall'istanza primaria.
Per informazioni su come creare una replica di lettura, consulta Creazione di repliche di lettura. Per informazioni sulla gestione di una replica di lettura, vedi Gestione delle repliche di lettura.
Come best practice, inserisci le repliche di lettura in una zona diversa dall'istanza principale quando utilizzi l'alta disponibilità sull'istanza principale. Questa pratica garantisce che le repliche di lettura continuino a funzionare quando la zona che contiene l'istanza principale ha un'interruzione. Per ulteriori informazioni, consulta la panoramica dell'alta disponibilità.
Selezionare un tipo di macchina appropriato
Le repliche di lettura possono avere un numero diverso di vCPU e memoria rispetto a quelle del primario. Devi monitorare le metriche sulla tua istanza, come l'utilizzo di CPU e memoria, per assicurarti che l'istanza di replica sia dimensionata correttamente per il suo workload, soprattutto se è più piccola dell'istanza principale. Un'istanza di replica sottodimensionata è più soggetta a prestazioni scarse, ad esempio a frequenti eventi di esaurimento della memoria (OOM).
Capacità di archiviazione sulle repliche di lettura
Quando viene ridimensionata un'istanza primaria, vengono ridimensionate anche tutte le relative repliche di lettura, se necessario, in modo che abbiano almeno la stessa capacità di archiviazione dell'istanza primaria aggiornata.
Repliche di lettura tra regioni
La replica tra regioni consente di creare una replica di lettura in una regione diversa dall'istanza principale. Crea una replica di lettura tra regioni nello stesso modo in cui crei una replica nella regione.
Repliche tra regioni:
- Migliora le prestazioni di lettura rendendo disponibili le repliche più vicine alla regione della tua applicazione.
- Fornire una funzionalità di ripristino di emergenza aggiuntiva per proteggersi da un errore a livello regionale.
- Consente di eseguire la migrazione dei dati da una regione all'altra.
Per saperne di più sulle repliche tra regioni, consulta la sezione Promozione di repliche per la migrazione a livello di area geografica o il ripristino di emergenza.
Repliche di lettura a cascata
La replica a cascata consente di creare una replica di lettura sotto un'altra replica di lettura nella stessa regione o in una regione diversa. I seguenti scenari sono casi d'uso per l'utilizzo di repliche in cascata:
- Disaster recovery: puoi utilizzare una gerarchia a cascata di repliche di lettura per simulare la topologia dell'istanza principale e delle relative repliche di lettura. Durante un'interruzione, la replica di lettura selezionata viene promossa a principale e le repliche di lettura sotto la nuova istanza principale continuano a replicarsi e sono pronte per l'uso.
- Miglioramenti delle prestazioni: riduci il carico sull'istanza principale trasferendo il lavoro di replica a più repliche di lettura.
- Scalare le letture: puoi avere più repliche per condividere il carico di lettura.
- Riduzione dei costi: puoi ridurre i costi di networking utilizzando una singola replica in cascata con la replica tra regioni in altre regioni.
Terminologia
- Replica a cascata: una replica di lettura che può avere la propria replica.
- Livelli: puoi creare livelli di repliche in una gerarchia di repliche a cascata. Ad esempio, se aggiungi quattro repliche a un'istanza, queste quattro repliche si trovano allo stesso livello.
- Istanze secondarie: più repliche che vengono replicate dalla stessa istanza principale. I peer si trovano allo stesso livello nella gerarchia di replica. Una replica può avere ufficialmente fino a otto fratelli.
- Replica foglia: una replica di lettura che non ha repliche proprie. In una gerarchia di replica multilivello, la replica foglia è l'ultimo livello.
- Promuovi Un'azione che converte una replica, a qualsiasi livello della gerarchia, in un'istanza principale. Una volta promossa, la gerarchia delle repliche a cascata della replica viene mantenuta.
Configurare le repliche a cascata
Le repliche a cascata ti consentono di aggiungere repliche di lettura a qualsiasi replica esistente. Puoi aggiungere fino a quattro livelli di repliche, inclusa l'istanza primaria. Quando promuovi la replica nella parte superiore di una gerarchia di repliche a cascata, questa diventa un'istanza principale e le relative repliche a cascata continuano a essere replicate.
Per pianificare la configurazione, devi avere un obiettivo per le repliche di lettura. Le due sezioni successive descrivono le configurazioni per il ripristino di emergenza e la replica multiregionale.
Disaster recovery
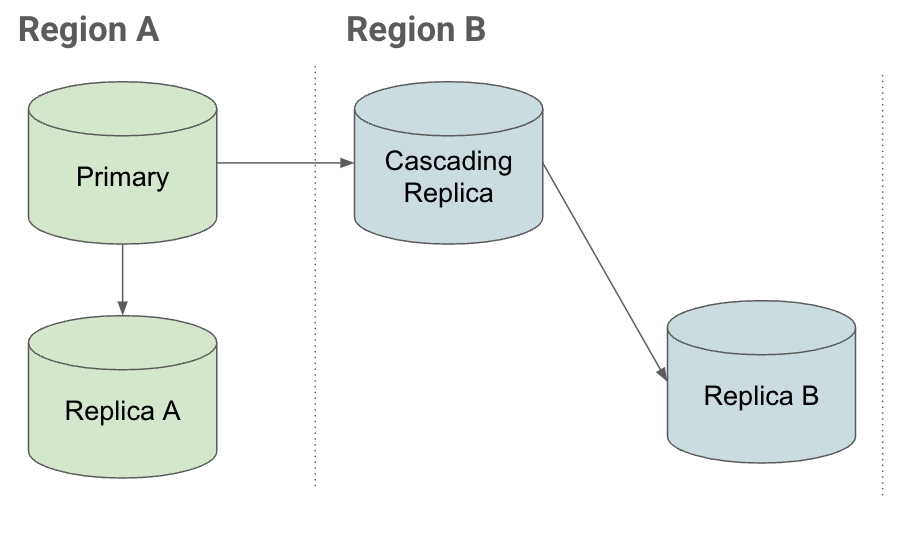
Per capire in che modo le repliche a cascata ti aiutano a eseguire il ripristino rapidamente durante un'interruzione, considera lo scenario di replica seguente:
Configurazione
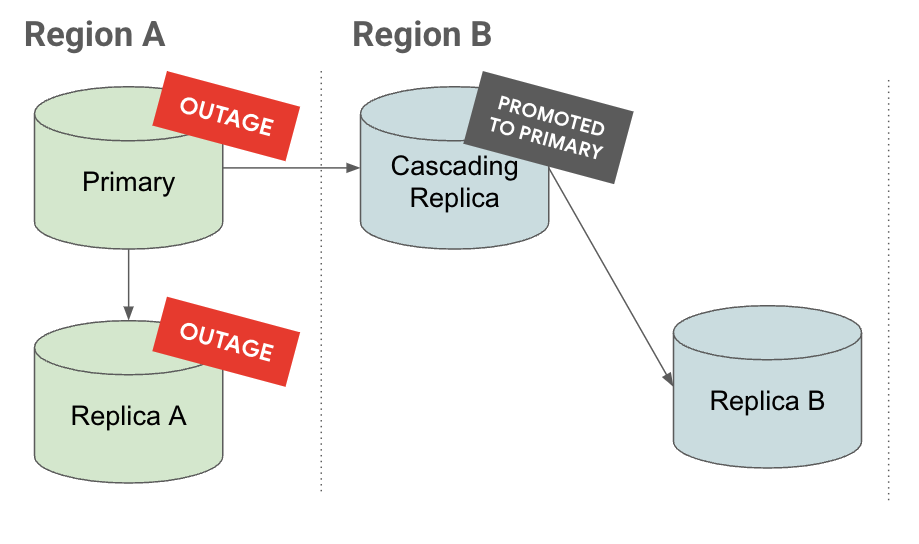
Interruzione
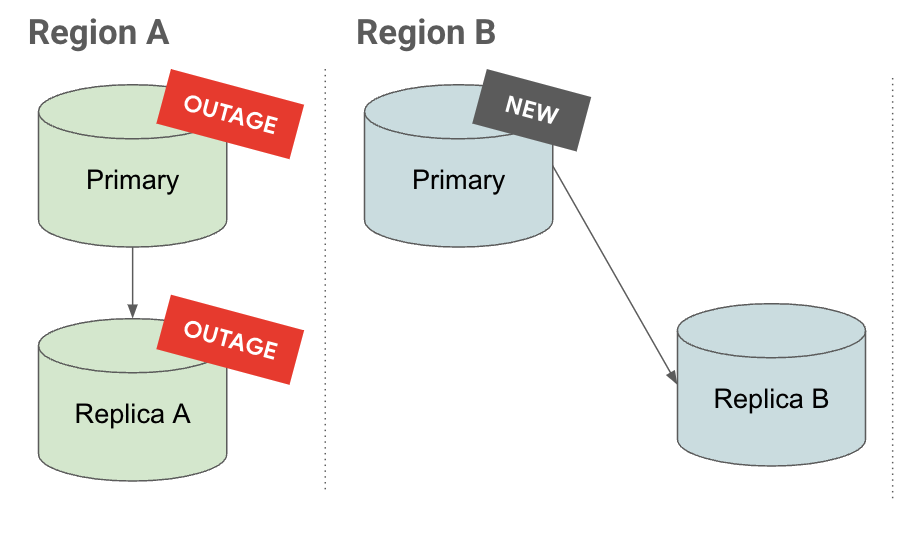
Promozione
Se vuoi utilizzare un'istanza nella regione B in una configurazione di ripristino di emergenza e hai:
- Repliche nella stessa regione collegate all'istanza principale (replica A)
- Replica in altre regioni (replica a cascata) collegata alla replica primaria.
Puoi creare repliche di lettura nella replica a cascata nella regione B.
Nella scheda Interruzione, se si verifica un'interruzione nella regione A, la replica in cascata viene promossa a istanza principale. Ha già repliche di lettura sottostanti, riducendo il Recovery Time Objective (RTO).
Nella scheda Promuovi, puoi notare che quando viene promossa una replica a cascata, anche le relative repliche vengono promosse e continuano a essere replicate.
Replica su più regioni
Un altro caso d'uso per le repliche a cascata è la distribuzione della capacità di lettura a una seconda regione in modo conveniente. È possibile creare le repliche a cascata C e D che vengono replicate dalla replica B. I client possono distribuire le query di lettura tra le repliche B, C e D per ridurre il carico su ciascuna replica. Il costo del traffico di rete tra regioni viene addebitato una sola volta, dall'istanza primaria alla replica B. La replica da B a C e D utilizza il trasferimento di rete nella regione, che è gratuito.
Puoi creare una gerarchia di massimo quattro istanze utilizzando repliche a cascata per la replica multiregionale:
Primario A → Replica B → Replica C e Replica D
Limitazioni
- Non puoi eliminare una replica che contiene altre repliche. Per eliminare la replica, devi iniziare dalle repliche foglia e procedere verso l'alto nella gerarchia.
- La dipendenza circolare della regione non è supportata. Per avere la replica di una replica a cascata nella stessa regione dell'istanza primaria, anche la replica a cascata deve trovarsi nella stessa regione.
Repliche di lettura esterne
Le repliche di lettura esterne sono istanze MySQL esterne che vengono replicate da un'istanza Cloud SQL principale. Ad esempio, un'istanza MySQL in esecuzione su Compute Engine è considerata un'istanza esterna.
Le repliche di lettura esterne presentano le seguenti limitazioni:
- L'istanza principale per la replica esterna non può essere una replica di lettura Cloud SQL.
- La replica in un'istanza MySQL ospitata da un'altra piattaforma cloud potrebbe non essere
possibile. Consulta la documentazione dell'altro provider. Ad esempio,
è necessario impostare il campo di configurazione
replicate-ignore-dbe i fornitori di servizi cloud in cui questa operazione non è consentita non sono supportati. Per altri campi di configurazione obbligatori, consulta Configurazione delle repliche esterne. - Se la replica viene interrotta per alcune ore, ad esempio a causa di un'interruzione della rete o del server, la replica rimane indietro rispetto al database primario. La replica si aggiorna una volta che si ricollega all'istanza primaria e inizia di nuovo la replica. Tuttavia, se la replica viene interrotta per un periodo di tempo superiore a quello in cui vengono conservati i log di replica di Cloud SQL (sette backup), devi eliminare la replica e crearne una nuova.
- I dati che scorrono dalla replica principale a quella esterna vengono addebitati come trasferimento di dati in uscita. Consulta la pagina Prezzi per i prezzi del trasferimento dei dati per il tuo tipo di istanza Cloud SQL.
Se crei una replica di lettura esterna per un'istanza e applichi l'utilizzo solo del proxy di autenticazione Cloud SQL o dei connettori dei linguaggi di Cloud SQL per connetterti a un'istanza per cui è configurato l'accesso privato ai servizi, devi aggiungere gli intervalli di subnet della replica alle reti autorizzate dell'istanza primaria. Devi configurare tutti gli intervalli come reti autorizzate dell'istanza Cloud SQL.
gcloud
Per impostare l'autorizzazione IP per un'istanza in modo da consentire il traffico dagli intervalli di indirizzi IP di una replica di lettura esterna, utilizza il comando
gcloud sql instances patch:gcloud sql instances patch \ --authorized-networks=IP_ADDRESS_RANGE_1/24,IP_ADDRESS_RANGE_2/24
Sostituisci IP_ADDRESS_RANGE_1 e IP_ADDRESS_RANGE_2 con gli intervalli di indirizzi IP della replica di lettura esterna.
REST
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT_ID: l'ID o il numero di progetto del progetto Google Cloud che contiene l'istanza
- INSTANCE_NAME: il nome dell'istanza Cloud SQL
- IP_ADDRESS_RANGE_1: il primo intervallo di indirizzi IP della replica di lettura esterna
- IP_ADDRESS_RANGE_2: il secondo intervallo di indirizzi IP della replica di lettura esterna
Metodo HTTP e URL:
PATCH https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_NAME
Corpo JSON della richiesta:
{ "kind": "sql#instance", "name": INSTANCE_NAME, "project": PROJECT_ID, "settings": { "ipConfiguration": { "authorizedNetworks": [{"kind": "sql#aclEntry", "value": "IP_ADDRESS_RANGE_1/24"}, {"kind": "sql#aclEntry", "value": "IP_ADDRESS_RANGE_2/24"}]}, "kind": "sql#settings" } }Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{ "kind": "sql#operation", "targetLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_NAME", "status": "PENDING", "user": "user@example.com", "insertTime": "2020-01-16T02:32:12.281Z", "operationType": "UPDATE", "name": "OPERATION_ID", "targetId": "INSTANCE_NAME", "selfLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/operations/OPERATION_ID", "targetProject": "PROJECT_ID" }
Casi d'uso della replica
I seguenti casi d'uso si applicano a ogni tipo di replica.
| Nome | Principale | Replica | Vantaggi e casi d'uso | Ulteriori informazioni |
|---|---|---|---|---|
| Replica in lettura | Istanza Cloud SQL | Istanza Cloud SQL |
|
|
| Replica di lettura tra regioni | Istanza Cloud SQL | Istanza Cloud SQL |
|
|
| Replica di lettura esterna | Istanza Cloud SQL autonoma o principale | Istanza MySQL esterna a Cloud SQL |
|
|
| Replica da un server esterno | Istanza MySQL esterna a Cloud SQL | Istanza Cloud SQL per MySQL |
|
Prerequisiti per la creazione di una replica di lettura
Prima di poter creare una replica di lettura di un'istanza Cloud SQL primaria, l'istanza deve soddisfare i seguenti requisiti:
- I backup automatici devono essere abilitati.
- Il logging binario deve essere abilitato e richiede l'abilitazione del recupero point-in-time. Scopri di più sull'impatto di questi log.
- Almeno un backup deve essere stato creato dopo l'attivazione della registrazione binaria.
Requisiti aggiuntivi per la replica esterna:
- La versione di MySQL della replica deve essere uguale o superiore alla versione di MySQL dell'istanza principale. Scopri di più.
- Per motivi di sicurezza, devi configurare SSL/TLS sull'istanza principale. Scopri di più.
Impatto dell'abilitazione del logging binario
Per abilitare il logging binario sull'istanza primaria per supportare le repliche di lettura, devi abilitare il recupero point-in-time. Questa operazione ha i seguenti impatti:
- Overhead delle prestazioni
Cloud SQL utilizza la replica basata sulle righe con i flag MySQL
sync_binlog=1einnodb_support_xa=true. Pertanto, è necessario un fsync aggiuntivo per ogni operazione di scrittura, il che riduce le prestazioni. - Overhead di archiviazione
L'archiviazione dei log binari viene addebitata alla stessa tariffa dei dati normali. I log binari vengono troncati automaticamente in base all'età del backup automatico meno recente. Cloud SQL conserva i sette backup automatici più recenti e tutti i backup on demand. Le dimensioni dei log binari e, di conseguenza, l'importo addebitato, dipendono dal carico di lavoro. Ad esempio, un carico di lavoro con molte operazioni di scrittura consuma più spazio nel log binario rispetto a un carico di lavoro con molte operazioni di lettura.
Puoi visualizzare le dimensioni dei log binari utilizzando il comando MySQL SHOW BINARY LOGS.
Quando vengono eseguiti i backup, i log vengono archiviati nel backup insieme ai dati.
Logging binario sulle repliche di lettura
- Il logging binario è supportato sulle istanze di replica di lettura (solo MySQL 5.7 e 8.0). Puoi abilitare la registrazione binaria su una replica con gli stessi
comandi API della
replica principale, utilizzando il nome dell'istanza della replica anziché il nome
dell'istanza principale. Tieni presente che i termini
enable binary loggingeenable point-in-time recoverysono intercambiabili.La durabilità del logging binario sull'istanza di replica (ma non su quella primaria) può essere impostata con il flag
sync_binlog, che controlla la frequenza con cui il server MySQL sincronizza il log binario su disco.Il logging binario può essere abilitato su una replica anche quando il backup è disattivato sulla replica primaria.
Se una replica con questo valore impostato viene promossa a server autonomo, l'impostazione viene reimpostata sul valore sicuro
1sul server autonomo.
Fatturazione
- Una replica di lettura viene addebitata alla stessa tariffa di un'istanza Cloud SQL standard. Non è previsto alcun costo per la replica dei dati.
- Per le repliche esterne, i dati che fluiscono dalla replica primaria a quella esterna vengono addebitati come trasferimento di dati. Consulta la pagina Prezzi per i prezzi del trasferimento dei dati per il tuo tipo di istanza Cloud SQL.
- Il prezzo di una replica di lettura tra regioni è lo stesso della creazione di una nuova istanza Cloud SQL nella regione. Consulta i prezzi delle istanze Cloud SQL e seleziona la regione appropriata. Oltre al costo normale associato all'istanza, una replica tra regioni comporta costi di trasferimento di dati tra regioni per i log di replica inviati dall'istanza principale all'istanza di replica, come descritto in Prezzi del traffico di rete in uscita.
Guida di riferimento rapida per le repliche di lettura Cloud SQL
| Argomento | Discussione |
|---|---|
| Backup | Non puoi configurare i backup sulla replica. |
| Core e memoria | Le repliche di lettura possono utilizzare un numero diverso di core e una quantità di memoria rispetto a quelli dell'istanza principale. |
| Eliminazione dell'istanza primaria | Prima di poter eliminare un'istanza primaria, devi promuovere tutte le relative repliche di lettura a istanze autonome o eliminare le repliche di lettura. |
| Eliminazione della replica | Quando elimini una replica, lo stato dell'istanza principale non viene modificato. |
| Disattivazione del logging binario | Prima di poter disabilitare i log binari su un'istanza principale, devi promuovere o eliminare tutte le relative repliche di lettura. |
| Failover | Un'istanza principale può eseguire il failover su una replica solo se la replica è una replica di RE. Le repliche di lettura non sono in grado di eseguire il failover in alcun modo durante un'interruzione. |
| Alta disponibilità | Le repliche di lettura ti consentono di abilitare l'alta disponibilità sulle repliche. |
| Bilanciamento del carico | Cloud SQL non fornisce il bilanciamento del carico tra le repliche. Puoi scegliere di implementare il bilanciamento del carico per l'istanza Cloud SQL. Puoi anche utilizzare il pooling delle connessioni per distribuire le query tra le repliche con la configurazione del bilanciamento del carico per ottenere prestazioni migliori. |
| Periodi di manutenzione | Le repliche di lettura condividono i periodi di manutenzione con l'istanza principale. Le repliche seguono le impostazioni di manutenzione per l'istanza principale, inclusi il periodo di manutenzione, la riprogrammazione e il periodo di manutenzione negata. Durante la manutenzione, Cloud SQL aggiorna prima tutte le repliche di lettura e poi l'istanza principale. |
| Più repliche di lettura | Cloud SQL supporta le repliche a cascata. Di conseguenza, puoi creare fino a 10 repliche per una singola istanza principale e creare repliche di queste repliche, fino a quattro livelli inclusa l'istanza principale. |
| Replica parallela | Per informazioni sull'utilizzo della replica parallela per migliorare le prestazioni, consulta Configurazione della replica parallela. |
| IP privato | Se ti connetti a una replica utilizzando un indirizzo IP privato, non devi creare una connessione privata VPC aggiuntiva per la replica, in quanto viene ereditata dall'istanza principale. |
| Ripristino dell'istanza principale | Non puoi ripristinare l'istanza principale di una replica mentre la replica esiste. Prima di ripristinare un'istanza da un backup o di eseguire un recupero point-in-time, devi promuovere o eliminare tutte le relative repliche. |
| Impostazioni | Le impostazioni MySQL dell'istanza principale vengono propagate alla replica, inclusi la password root e le modifiche alla tabella utenti. Le modifiche alla CPU e alla memoria non vengono propagate alla replica. |
| Arresto di una replica | Non puoi stop una replica. Puoi restart,
delete o disable replication, ma non puoi
interromperla come un'istanza principale. |
| Eseguire l'upgrade di una replica | Le repliche di lettura possono subire un upgrade distruttivo in qualsiasi momento. |
| Tabelle degli utenti | Non puoi apportare modifiche alla replica. Tutte le modifiche all'utente devono essere apportate all'istanza principale. |
Passaggi successivi
- Scopri come creare una replica di lettura.
- Scopri come configurare una configurazione di replica esterna.
- Scopri come replicare i dati da un server esterno.
- Scopri come configurare una configurazione di server esterno.
- Scopri di più sulla replica in MySQL.
- Scopri come configurare un'istanza per l'alta disponibilità.
- Scopri di più sul disaster ripristino di emergenza (RE) avanzato