Questa pagina offre una panoramica della configurazione ad alta disponibilità (HA) per le istanze Cloud SQL. Per configurare una nuova istanza per l'alta disponibilità o per abilitare l'alta disponibilità su un'istanza esistente, consulta Abilitazione e disabilitazione dell'alta disponibilità su un'istanza.
Panoramica della configurazione ad alta disponibilità
Lo scopo di una configurazione HA è ridurre i tempi di inattività quando una zona o un'istanza non è disponibile. Ciò può accadere durante un'interruzione zonale o quando si verifica un problema hardware. Con l'alta disponibilità, i tuoi dati continuano a essere disponibili per le applicazioni client.
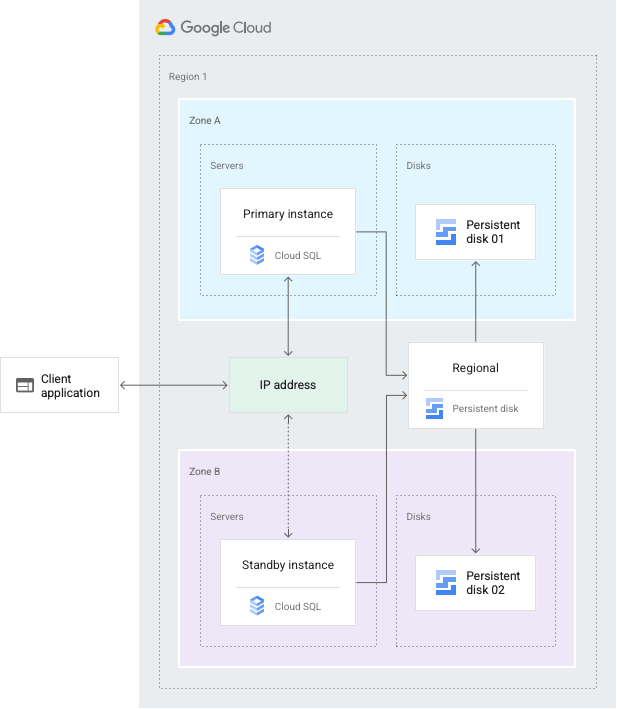
La configurazione HA fornisce la ridondanza dei dati. Un'istanza Cloud SQL configurata per l'alta disponibilità è chiamata anche istanza regionale e ha una zona primaria e una secondaria all'interno della regione configurata*. All'interno di un'istanza regionale, la configurazione include un'istanza principale e un'istanza in standby. Tramite la replica sincrona nel disco permanente di ciascuna zona, tutte le scritture effettuate nell'istanza principale vengono replicate nei dischi di entrambe le zone prima che venga confermato il commit di una transazione. In caso di errore di un'istanza o una zona, l'istanza in standby diventa la nuova istanza primaria. Gli utenti vengono quindi reindirizzati alla nuova istanza primaria. Questo processo è noto come failover.
Dopo un failover, l'istanza che ha ricevuto il failover continua a essere l'istanza principale, anche dopo che l'istanza originale torna online. Una volta che la zona o l'istanza che ha subito un'interruzione diventa di nuovo disponibile, l'istanza primaria originale viene eliminata e ricreata. Poi diventa la nuova istanza in standby. Se in futuro si verifica un failover, la nuova istanza primaria eseguirà il failover all'istanza originale nella zona originale.
Se devi avere l'istanza primaria nella zona in cui si è verificata l'interruzione, puoi eseguire un failback. Un failback esegue gli stessi passaggi del failover, ma nella direzione opposta, per reindirizzare il traffico all'istanza originale. Per eseguire un failback, utilizza la procedura descritta in Avvio del failover.
Il supporto dei disco permanente regionali per la configurazione HA di Cloud SQL con almeno una CPU dedicata ha una copertura completa dell'accordo sul livello del servizio (SLA). Un'istanza configurata per l'alta disponibilità costa il doppio di un'istanza autonoma. Questo prezzo include CPU, RAM e spazio di archiviazione. Per ulteriori informazioni, consulta la pagina dei prezzi.
* Per saperne di più sulle considerazioni specifiche per le regioni, consulta Area geografica e regioni.
Repliche di lettura
Se la disponibilità è un fattore importante per le repliche di lettura, puoi abilitare l'alta disponibilità sulle repliche. Quando promuovi una replica di questo tipo a istanza principale, è già configurata come istanza ad alta affidabilità.
Durante un'interruzione zonale, il traffico si interrompe per le repliche di lettura in quella zona. Una volta che la zona torna disponibile, tutte le repliche di lettura nella zona riprendono la replica dall'istanza principale. Se le repliche di lettura non si trovano in una zona interessata da un'interruzione, si connettono all'istanza in standby quando diventa l'istanza principale.
Come best practice, valuta la possibilità di inserire alcune delle repliche di lettura in una zona diversa dalle istanze primaria e in standby. Ad esempio, se hai un'istanza primaria nella zona A e un'istanza di standby nella zona B, inserisci una replica di lettura nella zona C per migliorare l'affidabilità. Questa pratica garantisce che le repliche di lettura continuino a funzionare anche se la zona dell'istanza principale non è più disponibile. Devi anche aggiungere la logica di business nell'applicazione client per inviare le letture all'istanza principale quando le repliche di lettura non sono disponibili.
Nota:l'istanza di standby non può essere utilizzata per le query di lettura. Questa configurazione è diversa dalla configurazione HA legacy di Cloud SQL per MySQL.
Panoramica del failover
Se un'istanza configurata per l'alta disponibilità smette di rispondere, Cloud SQL passa automaticamente all'erogazione dei dati dall'istanza in standby. Per verificare se si è verificato un failover, controlla la cronologia dei failover nel log delle operazioni.
Scopri di più su come creare query in Esplora log. Se hai bisogno di informazioni più dettagliate su un'operazione, ad esempio l'utente che l'ha eseguita, devi attivare i log di controllo.
Fai clic sulle schede per vedere in che modo il failover influisce sulla tua istanza.
Normale

Failover

Post-failover

Failback
Processo
Si verifica il seguente processo:
L'istanza o la zona primaria non funziona.
Ogni secondo, il sistema heartbeat rileva se l'istanza primaria è integra. Se non vengono rilevati più heartbeat, viene avviato il failover.
L'istanza in standby ora gestisce i dati al momento della riconnessione.
Tramite un indirizzo IP statico condiviso con l'istanza principale, l'istanza di standby ora gestisce i dati della zona secondaria.
Requisiti
Affinché Cloud SQL consenta un failover, la configurazione deve soddisfare i seguenti requisiti:
- L'istanza primaria deve essere in uno stato operativo normale (non arrestata, in manutenzione o in esecuzione di un'operazione Cloud SQL a lunga esecuzione, ad esempio un'operazione di backup).
- La zona secondaria e l'istanza di standby devono essere entrambe in stato integro. Quando l'istanza di standby non risponde, le operazioni di failover vengono bloccate. Dopo che Cloud SQL ripara l'istanza di standby e la zona secondaria è disponibile, Cloud SQL consente il failover.
Backup e ripristino
I backup automatici e il recupero point-in-time devono essere abilitati per le istanze ad alta disponibilità, escluse le repliche di lettura.
Opzioni di recupero per le istanze autonome
Cloud SQL non recupera automaticamente le istanze autonome da un'interruzione zonale. Per ristabilire un'istanza non configurata per l'alta disponibilità in una zona integra, devi ripristinare manualmente tutte le istanze di zona. Puoi recuperare manualmente un'istanza autonoma da un'interruzione zonale utilizzando una delle seguenti opzioni:
Esegui il recupero point-in-time sull'istanza in una nuova istanza che crei. Per utilizzare questa opzione, devi aver abilitato PITR sull'istanza di zona prima dell'interruzione di zona. I log delle transazioni per l'istanza devono essere archiviati in Cloud Storage. Se i log delle transazioni sono archiviati su disco, puoi passarli a Cloud Storage. Per utilizzare questa opzione, segui i passaggi descritti in Esegui il PITR su un'istanza non disponibile.
Se l'istanza ha una replica di lettura in una zona diversa, puoi promuovere questa replica di lettura per sostituire l'istanza autonoma che sta riscontrando l'interruzione zonale. Per utilizzare questa opzione, segui i passaggi descritti in Promuovere una replica.
Per entrambe le opzioni, valgono le seguenti considerazioni:
Alcune transazioni recenti eseguite sull'istanza principale potrebbero non essere visualizzate sull'istanza appena recuperata. L'intervallo di tempo in cui le transazioni potrebbero essere andate perse è l'RPO (Recovery Point Objective).
- Per il recupero PITR, l'RPO è in genere di cinque minuti o meno.
- Per la promozione della replica di lettura, l'RPO varia in base al carico di lavoro del database. Per saperne di più su come monitorare e ridurre il ritardo di replica, vedi Ritardo di replica.
Dopo aver eseguito una delle opzioni di ripristino, devi riconfigurare tutti i client delle istanze interessate dall'interruzione zonale perché le istanze recuperate avranno indirizzi IP e nomi di connessione diversi.
Applicazioni e istanze
Non c'è alcuna differenza nel funzionamento con istanze non HA e HA, quindi la tua applicazione non deve essere configurata in modo particolare. Quando si verifica il failover, tutte le connessioni esistenti all'istanza primaria e alle repliche di lettura vengono chiuse e ci vogliono circa 60 secondi prima che le connessioni all'istanza primaria vengano ristabilite. L'applicazione si riconnette utilizzando la stessa stringa di connessione o lo stesso indirizzo IP, quindi non è necessario aggiornarla dopo il failover.
Per vedere esattamente in che modo le tue applicazioni sono interessate dal failover, avvia manualmente il failover.
Tempo di inattività per manutenzione
Gli eventi di manutenzione influiscono sulle istanze primarie configurate con HA allo stesso modo delle altre istanze. Puoi prevedere che le istanze principali non siano disponibili per un breve periodo di tempo. Per saperne di più su come la manutenzione influisce sulle istanze HA, consulta Come funziona la manutenzione. Per ridurre al minimo l'impatto sul servizio, modifica le impostazioni di manutenzione per controllare quando si verifica il tempo di inattività.
Prestazioni
Le prestazioni del disco permanente regionale dipendono da molti fattori. Le operazioni di I/O al secondo (IOPS) potrebbero essere ridotte con il disco permanente regionale rispetto al disco permanente zonale. Esamina le dimensioni del tipo di istanza VM e l'input e l'output del workload. Un'altra metrica da tenere presente è che la latenza per il disco permanente regionale con unità a stato solido (SSD) è superiore a quella di un disco permanente zonale con SSD. Ciò implica che se il tuo workload non è un workload di streaming ed è sensibile alla latenza, non può raggiungere il limite di IOPS perché il disco permanente regionale con SSD ha una latenza superiore a quella di un disco permanente zonale con SSD. Ciò è dovuto alla replica sincrona dei dati in più zone coinvolte in un disco permanente regionale per fornire più copie dei dati nelle zone di una regione.
Opzione di alta disponibilità MySQL legacy
La procedura precedente per aggiungere l'alta disponibilità alle istanze MySQL utilizza una replica di failover. La funzionalità precedente non è disponibile nella console Google Cloud . Consulta Configurazione legacy: creazione di una nuova istanza configurata per l'alta disponibilità o Configurazione legacy: configurazione di un'istanza esistente per l'alta disponibilità.
Passaggi successivi
- Abilita e disabilita l'alta disponibilità su un'istanza.
- Avvia failover.
- Scopri di più sulla gestione delle connessioni al database.
- Scopri di più su regioni e zone in Cloud SQL.