Questa pagina fornisce informazioni da esaminare prima di ripristinare un'istanza da un backup o di eseguire un recupero point-in-time (PITR).
Cosa succede durante un ripristino?
Per Cloud SQL Enterprise e Cloud SQL Enterprise Plus, puoi ripristinare un'istanza da un backup. Puoi anche ripristinare i backup tra istanze di edizioni diverse.
Quando ripristini un'istanza, i seguenti dati dell'istanza principale vengono ripristinati nella nuova istanza:
- Database
- Utenti
L'operazione di ripristino causa il riavvio dell'istanza.
Recupero point-in-time (PITR)
Il recupero point-in-time (PITR) ti aiuta a recuperare un'istanza in un momento specifico. Ad esempio, se un errore causa una perdita di dati, puoi ripristinare un database nello stato in cui si trovava prima che si verificasse l'errore.
Il PITR crea sempre una nuova istanza. Non puoi eseguire un PITR su un'istanza esistente. La nuova istanza eredita le impostazioni dell'istanza di origine, in modo simile al funzionamento della creazione di cloni.
Quando crei un'istanza Cloud SQL nella console Google Cloud , il PITR è abilitato per impostazione predefinita.Il PITR utilizza il logging binario per archiviare i log. Per impostazione predefinita, il PITR è abilitato per le istanze Cloud SQL Enterprise Plus.
Quando ripristini un backup su un'istanza Cloud SQL prima di abilitare PITR, perdi i log archiviati che ti consentono di utilizzare PITR. Se le dimensioni dei log binari sul disco causano problemi di prestazioni per l'istanza, disattiva PITR e riattivalo. Questa azione garantisce che i nuovi log vengano archiviati in Cloud Storage anziché su disco.Per istruzioni passo passo su come eseguire il PITR, consulta Utilizzare il recupero point-in-time (PITR).
Ripristinare un'istanza non disponibile
Puoi utilizzare il PITR per ripristinare un'istanza Cloud SQL non disponibile. In genere, PITR offre un Recovery Point Objective (RPO) di cinque minuti o meno.
Se l'istanza non è disponibile, puoi utilizzare l'API per ottenere l'ora di recupero più recente e più remota a cui puoi ripristinare l'istanza ed eseguire il recupero fino a quell'ora. Se la zona in cui è configurata l'istanza non è accessibile, puoi ripristinare l'istanza in una zona primaria o secondaria diversa fornendo valori per le zone preferite.
Supponiamo che un'istanza Cloud SQL non sia più disponibile alle 16:00 EST. Se l'ultimo orario di recupero è alle 15:55 EST, puoi recuperare l'istanza fino a questo orario.
Ripristinare un'istanza eliminata utilizzando il recupero point-in-time
Puoi utilizzare il PITR per ripristinare un'istanza Cloud SQL dopo l'eliminazione. Per utilizzare questa funzionalità, prima dell'eliminazione dell'istanza devono essere attivati PITR e backup conservati. Se questa opzione è attivata, i log PITR vengono conservati dopo l'eliminazione dell'istanza.
Dopo l'eliminazione di un'istanza, i log PITR continuano a seguire le impostazioni di conservazione definite dall'istanza quando era attiva. I log PITR scadono in base alle impostazioni di conservazione su base rotativa dopo l'eliminazione dell'istanza. Il periodo di rotazione è definito in base al periodo di conservazione PITR impostato sull'istanza prima dell'eliminazione. Ad esempio, se la conservazione PITR è impostata su 14 giorni per l'istanza Cloud SQL Enterprise Plus, l'ultimo log PITR verrà eliminato 14 giorni dopo l'eliminazione dell'istanza. Quando un log PITR scade, non può essere recuperato.
Poiché i nomi delle istanze possono essere riutilizzati dopo l'eliminazione di un'istanza in Cloud SQL, i log PITR conservati possono essere identificati in Google Cloud con i seguenti campi:
instance_deletion_timelog_retention_days
Questi campi ti consentono di identificare se un log PITR appartiene a un'istanza eliminata.
La finestra di recupero PITR è definita come i tempi di recupero più recenti e meno recenti disponibili per ripristinare l'istanza utilizzando PITR. Per trovare gli orari di recupero più recenti e meno recenti dell'istanza eliminata, consulta Recuperare l'orario di recupero più recente e meno recente.
Per ripristinare un'istanza utilizzando il PITR dopo l'eliminazione dell'istanza, consulta Esegui il PITR su un'istanza eliminata.
Suggerimenti generali per l'esecuzione di un ripristino
Quando ripristini un'istanza da un backup, nella stessa istanza o in un'altra, tieni presente quanto segue:
- L'operazione di ripristino sovrascrive tutti i dati nell'istanza di destinazione.
- L'istanza di destinazione non è disponibile per le connessioni durante l'operazione di ripristino; le connessioni esistenti vengono perse.
- Se esegui il ripristino in un'istanza con repliche di lettura, devi eliminare tutte le repliche e ricrearle al termine dell'operazione di ripristino.
- L'operazione di ripristino riavvia l'istanza.
Per istruzioni passo passo su come eseguire un ripristino, vedi:
Suggerimenti e requisiti per il ripristino in un'altra istanza
Quando ripristini un backup in un'istanza diversa, tieni presente le seguenti limitazioni e best practice:
L'istanza di destinazione deve avere la stessa versione del database dell'istanza da cui è stato eseguito il backup.
Se vuoi eseguire l'upgrade della versione del database per la tua istanza, segui i passaggi descritti in Eseguire l'upgrade in loco della versione principale del database.
Cloud SQL imposta sempre la capacità di archiviazione dell'istanza di destinazione sul valore massimo delle dimensioni sia del disco configurato sia del disco di backup. Il disco di backup ha le dimensioni del disco al momento della creazione del backup.
La capacità di archiviazione dell'istanza di destinazione deve essere almeno pari alla capacità dell'istanza di cui viene eseguito il backup. La quantità di spazio di archiviazione utilizzato non ha importanza. Puoi visualizzare la capacità di archiviazione dell'istanza nella pagina Istanze Cloud SQL della console.
L'istanza di destinazione deve essere nello stato
RUNNABLE.L'istanza di destinazione può utilizzare un numero diverso di core e quantità di memoria rispetto all'istanza da cui è stato eseguito il backup.
L'istanza di destinazione può trovarsi in una regione diversa da quella dell'istanza di origine.
Durante un'interruzione, puoi comunque recuperare un elenco di backup in un progetto specifico. Vedi Visualizzare i backup durante un'interruzione.
Ripristinare le limitazioni di frequenza
Sono consentite un massimo di tre operazioni di ripristino ogni 30 minuti per istanza per regione per progetto. Se un'operazione di ripristino non va a buon fine, non viene conteggiata ai fini di questa quota. Se raggiungi il limite, l'operazione non va a buon fine e viene visualizzato un messaggio di errore che ti indica quando potrai eseguirla di nuovo.
Diamo un'occhiata a come Cloud SQL esegue limitazione di frequenza per i ripristini.
Cloud SQL utilizza i token di un bucket per determinare il numero di operazioni di ripristino disponibili in un determinato momento. Per ogni backup, esiste un bucket per ogni progetto di destinazione e regione di destinazione. Le istanze di destinazione dello stesso progetto condividono un bucket se si trovano nella stessa regione. In ogni bucket sono presenti al massimo tre token che puoi utilizzare per le operazioni di ripristino. Ogni 10 minuti viene aggiunto un nuovo token al bucket. Se il bucket è pieno, il token va in overflow.
Ogni volta che esegui un'operazione di ripristino, viene concesso un token dal bucket. Se l'operazione va a buon fine, il token viene rimosso dal bucket. Se non va a buon fine, il token viene restituito al bucket. Il seguente diagramma mostra come funziona:

Ad esempio, nella figura seguente, Backup1, Backup2 e Backup3 sono i backup della stessa istanza di origine.
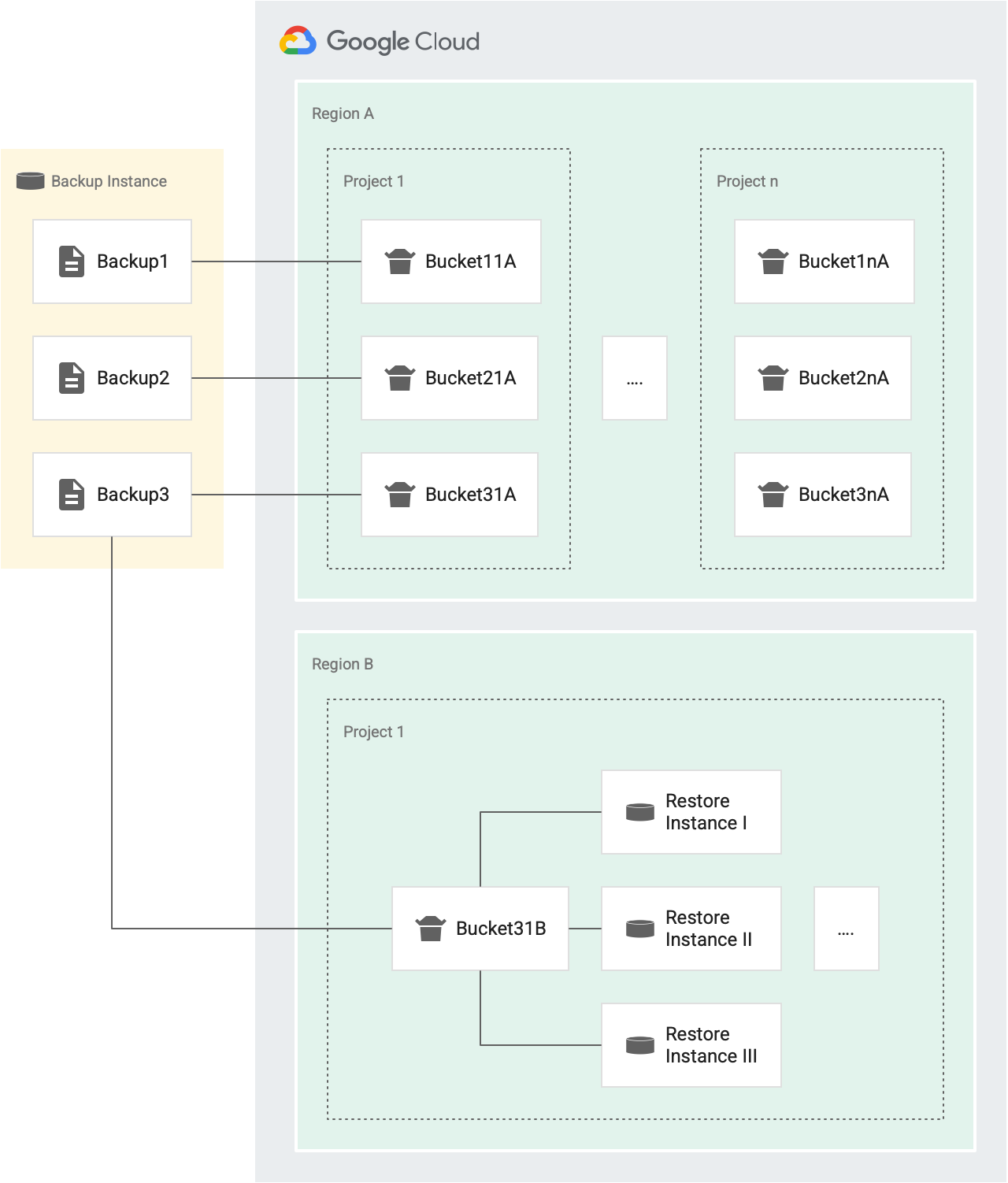
- Ogni backup (Backup1, Backup2 e Backup3) ha il proprio bucket di token per le operazioni di ripristino che hanno come target istanze diverse nel progetto 1 nella regione A (Bucket11A, Bucket21A e Bucket31A). Poiché ogni backup ha il proprio bucket, puoi ripristinare ogni backup nella stessa istanza tre volte ogni 30 minuti.
- Ogni backup ha un bucket per un progetto separato e per una regione separata.
Ad esempio, se in una regione sono presenti cinque progetti, in quella regione sono presenti cinque bucket per il backup, uno in ogni progetto. Nella figura
precedente, abbiamo due progetti nella regione A: il progetto 1 e il progetto n.
- Backup1 ha due bucket di token per le operazioni di ripristino nella regione A. Un bucket per il progetto 1 (Bucket11A) e un bucket per il progetto n (Bucket1nA).
- Allo stesso modo, Backup3 ha due bucket per le operazioni di ripristino nella regione A. Uno per il progetto 1 (Bucket31A) e uno per il progetto n (Bucket3nA).
- Backup3 ha un bucket nella regione B per il progetto 1, perché tutte le istanze nello stesso progetto di destinazione e nella stessa regione di destinazione condividono un bucket.