À l'aide de l'API, sans code, vous pouvez créer et entraîner un modèle Speech-to-Text personnalisé pour améliorer la précision de la reconnaissance à partir d'un modèle Speech-to-Text existant. Ce service entièrement géré provisionne automatiquement les ressources de calcul, exécute le code de l'application d'entraînement et garantit la suppression des ressources de calcul après le job d'entraînement. Vous obtenez un modèle de transcription entièrement affiné, utile pour toute application en aval.
À l'instar des modèles de machine learning, l'entraînement d'un modèle Speech-to-Text personnalisé est généralement itératif et implique de sélectionner un modèle de base comme point de départ, de l'affiner avec vos ensembles de données texte et audio, puis de tester la qualité de la reconnaissance du modèle. Si les résultats ne sont pas ceux attendus, vous pouvez réentraîner un nouveau modèle avec un mélange de données différent, effectuer un nouveau test ou l'utiliser directement pour la transcription dans votre domaine.
Avant de commencer
Assurez-vous d'avoir créé un compte Google Cloud , d'avoir créé un projet Google Cloud et d'avoir activé l'API Speech-to-Text : accédez à Speech dans la console Google Cloud , puis accédez à l'API Speech-to-Text. Accédez à la section Modèles personnalisés de la barre de navigation de gauche.
Créer un modèle personnalisé
Commencez par créer un modèle Speech-to-Text personnalisé et définissez ses paramètres, tels que le modèle de base et le langage de transcription :
- Cliquez sur Créer pour créer un modèle personnalisé.
- Saisissez un nom de modèle. Celui-ci sera utilisé pour l'affichage et référencé dans vos requêtes API et la console Speech Google Cloud .
- Saisissez une description pour le modèle.
- Sélectionnez un modèle de base qui correspond le mieux à votre cas d'utilisation.
- Sélectionnez la langue de transcription du modèle.
- Sélectionnez la région dans laquelle l'entraînement doit avoir lieu.
- Cliquez sur Continuer.
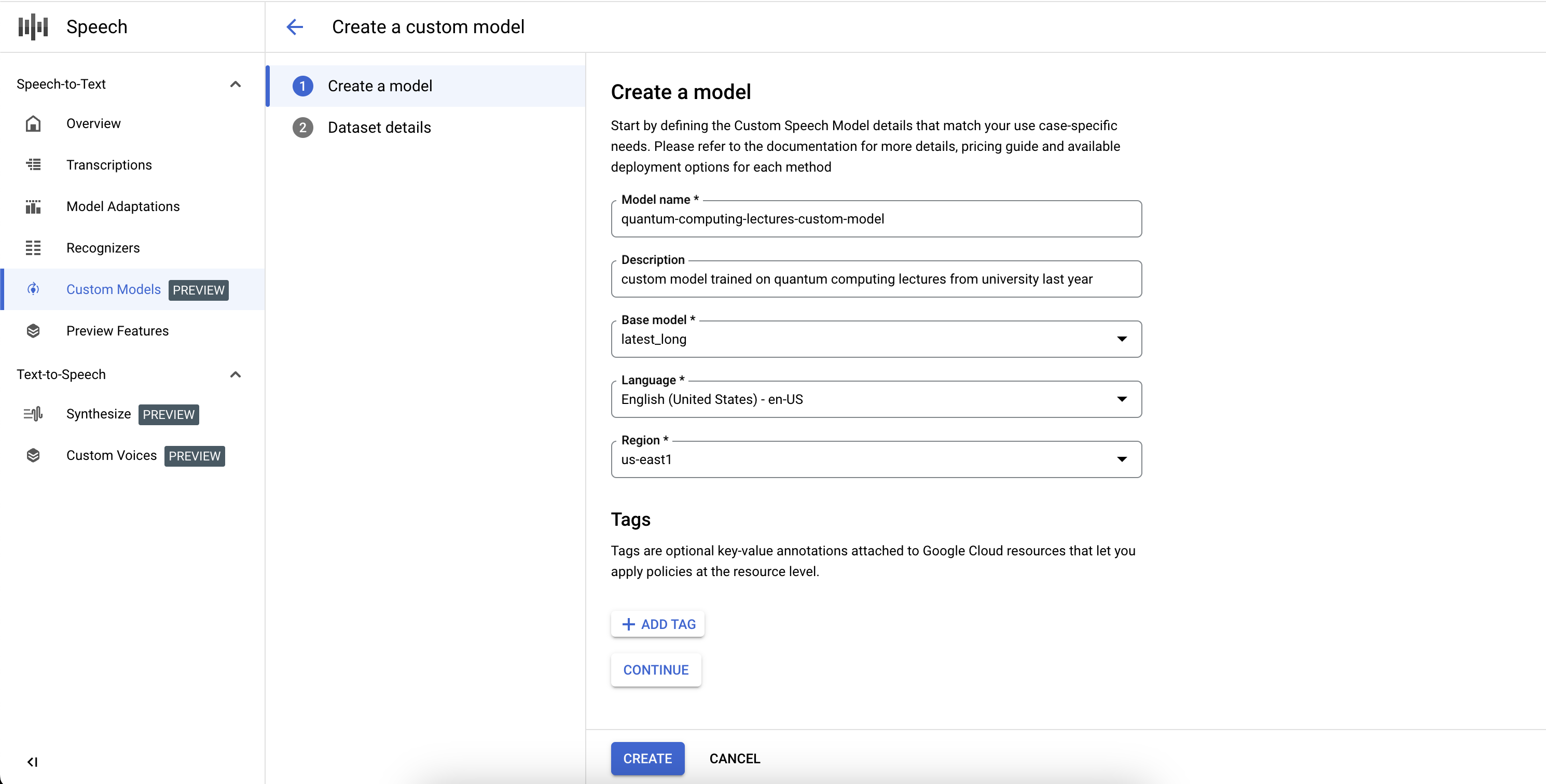
Pour terminer la définition de la tâche du modèle Speech-to-Text personnalisé et démarrer l'entraînement, vous devez définir les ensembles de données d'entraînement et de validation.
- Sélectionnez un ensemble de données d'entraînement en fournissant un URI de répertoire Cloud Storage valide. Assurez-vous que seuls des fichiers audio et texte sont présents, et que la durée totale de l'audio respecte les exigences concernant l'ensemble de données d'entraînement.
- Sélectionnez un ensemble de données de validation en fournissant un URI de répertoire Cloud Storage valide. Assurez-vous que seuls des fichiers audio et texte sont présents, et que la durée totale de l'audio respecte les exigences concernant l'ensemble de données de validation.
- Cliquez sur Créer pour lancer le processus d'entraînement.
Si le nombre d'heures audio indexées est insuffisant ou si les fichiers ne respectent pas les consignes, le job d'entraînement échouera.
Les jobs d'entraînement peuvent être mis en file d'attente derrière d'autres jobs dans notre système. L'entraînement d'un modèle peut prendre de quelques heures à quelques jours, selon la taille de l'ensemble de données. Une fois le modèle entraîné, son état est indiqué comme Actif.
Supprimer un modèle personnalisé
Avant de commencer, assurez-vous qu'aucun trafic n'est acheminé vers votre modèle Speech-to-Text personnalisé via un point de terminaison, car sa suppression empêchera la diffusion des requêtes.
- Accédez à l'onglet Modèles de la section Modèles personnalisés.
- Développez les options, puis cliquez sur Supprimer. Après quelques instants, le modèle Speech-to-Text personnalisé sera supprimé, ainsi que tous ses points de terminaison, et ne diffusera plus de trafic.
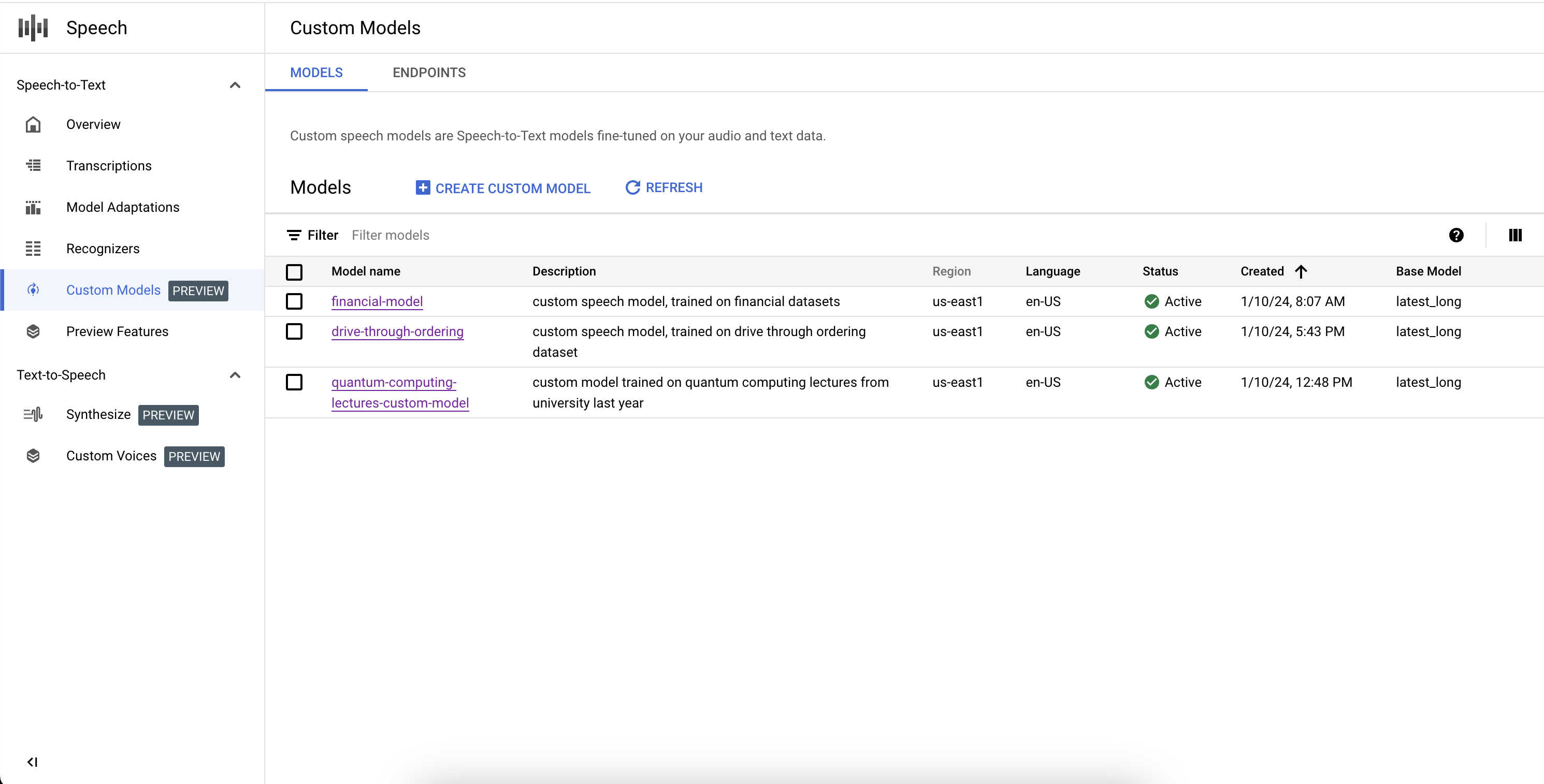
Lister vos modèles personnalisés
En sélectionnant Modèles dans la section Modèles personnalisés, vous pouvez également répertorier tous vos modèles Speech-to-Text personnalisés, y compris ceux qui sont en cours d'entraînement, actifs ou en cours de suppression.
Étapes suivantes
Suivez les ressources pour tirer parti des modèles de reconnaissance vocale personnalisés dans votre application :
- Déployer et gérer des points de terminaison de modèles
- Utiliser vos modèles personnalisés
- Évaluer vos modèles personnalisés