Utilisez un modèle Speech-to-Text personnalisé entraîné dans votre application de production ou dans des workflows d'analyse comparative. Vous devez déployer et exposer le modèle via un point de terminaison dédié, créé en partie pour déployer le modèle dans la région de votre choix. Vous obtenez automatiquement un accès programmatique via un objet de reconnaissance. Vous pouvez l'utiliser directement via l'API V2 ou dans la console Google Cloud . Vous pouvez déployer votre modèle dans une région différente de celle où il a été entraîné, mais une copie du modèle est créée dans la région spécifiée par le point de terminaison.
Pour utiliser un modèle de reconnaissance vocale personnalisé, vous devez le déployer et l'exposer via un point de terminaison dédié. En créant un point de terminaison, vous déployez le modèle dans la région de votre choix. Vous disposez automatiquement d'un accès programmatique via un objet de reconnaissance à utiliser directement via l'API V2 pour l'inférence ou dans la console Google Cloud .
Avant de commencer
Assurez-vous d'avoir créé un compte Google Cloud , un projet et entraîné un modèle de reconnaissance vocale personnalisé.
- Accédez à Speech dans la console Google Cloud , puis à Speech-to-Text.
- Accédez à la section Modèles personnalisés de la barre de navigation de gauche.
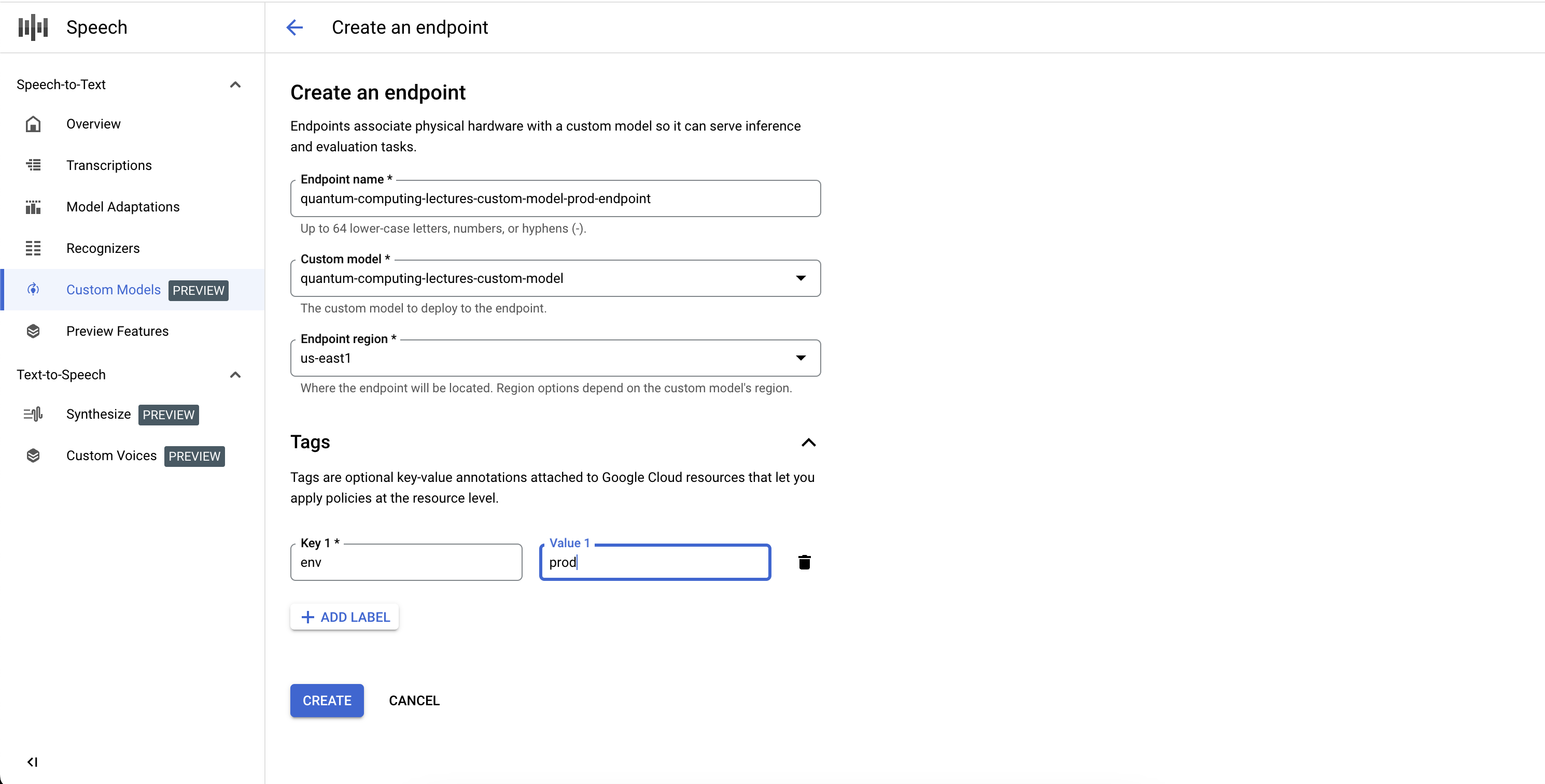
Créer un point de terminaison
- Accédez à l'onglet Points de terminaison de la section Modèles personnalisés.
- Cliquez sur Nouveau point de terminaison.
- Saisissez un nom pour votre point de terminaison. Il sert d'identifiant unique pour votre ressource de point de terminaison et permet d'appeler votre modèle de reconnaissance vocale personnalisé pour l'inférence.
- Définissez la région dans laquelle vous souhaitez déployer votre modèle de reconnaissance vocale personnalisé. Si le modèle a été entraîné dans une région différente de celle définie dans la configuration du point de terminaison, une nouvelle copie de modèle est créée automatiquement.
- Dans la liste, sélectionnez le modèle de reconnaissance vocale personnalisé entraîné que vous souhaitez exposer via le point de terminaison.
- Cliquez sur Créer. Après quelques instants, votre modèle de reconnaissance vocale personnalisé est déployé sur votre point de terminaison. Il est prêt à être utilisé pour l'inférence et l'analyse comparative.
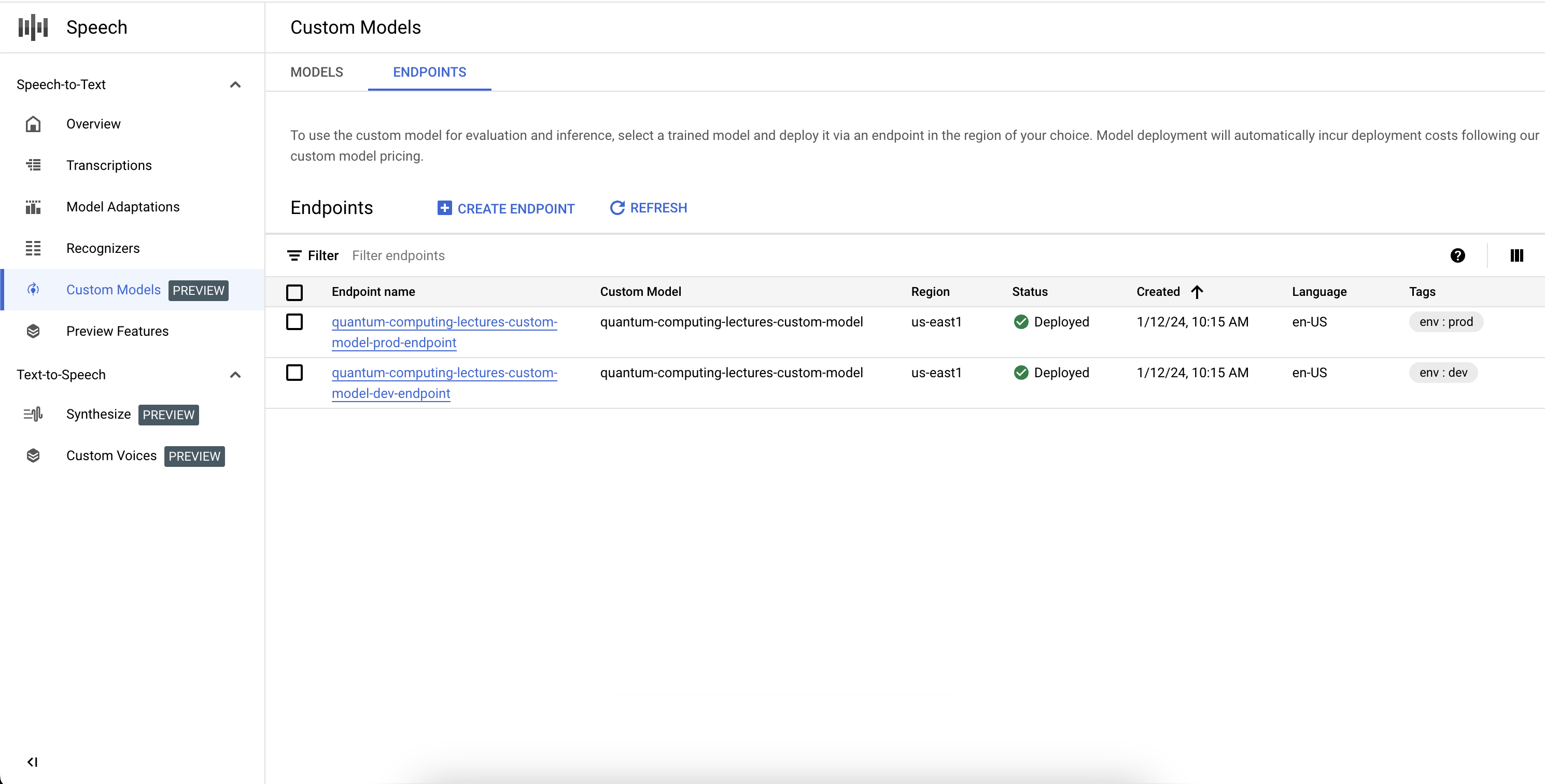
Répertorier vos points de terminaison
Vous pouvez gérer les points de terminaison associés dans la console en sélectionnant l'onglet "Points de terminaison" de la section "Modèles personnalisés". Vous pouvez également répertorier les points de terminaison que vous avez créés dans la console, ainsi que leur état actuel et le modèle Speech-to-Text personnalisé associé.
Supprimer un point de terminaison
Avant de commencer, assurez-vous qu'aucun trafic n'est acheminé via votre point de terminaison, car sa suppression empêchera la diffusion des requêtes.
- Accédez à l'onglet Points de terminaison de la section Modèles personnalisés.
- Dans l'onglet Points de terminaison, développez les options, puis cliquez sur Supprimer. Après quelques instants, le point de terminaison est supprimé et ne diffuse plus de trafic.
Effectuer une analyse comparative du modèle
En utilisant le modèle Speech-to-Text personnalisé et votre ensemble de données de benchmarking pour évaluer la précision de votre modèle, suivez le guide Mesurer et améliorer la précision.