As tecnologias de armazenamento do Google alimentam alguns dos maiores aplicativos do mundo. No entanto, o escalonamento nem sempre é um resultado automático do uso desses sistemas. Os designers precisam pensar cuidadosamente sobre como modelar os dados para garantir que o aplicativo possa escalonar e executar à medida que cresce em várias dimensões.
O Spanner é um banco de dados distribuído. Para usá-lo de maneira eficaz, é preciso pensar de maneira diferente sobre o projeto do esquema e os padrões de acesso em relação aos bancos de dados tradicionais. Os sistemas distribuídos, pela natureza deles, forçam os desenvolvedores a pensar sobre localidade de processamento e dados.
O Spanner é compatível com transações e consultas SQL com a capacidade de escalonamento horizontal. Um projeto cuidadoso muitas vezes é necessário para que se atinja o benefício total do Spanner. Este artigo trata de algumas das ideias fundamentais que o ajudarão a garantir que seu aplicativo possa escalonar a níveis arbitrários e a maximizar desempenho dele. Duas ferramentas em particular têm grande impacto na escalabilidade: a definição de chave e a intercalação.
Layout da tabela
As linhas em uma tabela do Spanner são organizadas lexicograficamente por PRIMARY
KEY. Conceitualmente, as chaves são ordenadas pela concatenação das colunas na ordem em que são declaradas na cláusula PRIMARY KEY. Isso exibe todas as propriedades padrão da localidade:
- A verificação da tabela em ordem lexicográfica é eficiente.
- Linhas suficientemente próximas serão armazenadas nos mesmos blocos de disco e serão lidas e armazenadas em cache em conjunto.
O Spanner replica seus dados em várias zonas para disponibilidade e escala. Cada zona contém uma réplica completa dos seus dados. Ao provisionar um nó de instância do Spanner, você especifica a capacidade de computação dele. A capacidade de computação é a quantidade de recursos de computação alocados à instância em cada uma dessas zonas. Cada réplica é um conjunto completo dos dados, mas os dados dentro de uma réplica são particionados nos recursos de computação nessa zona.
Os dados em cada réplica do Spanner são organizados em dois níveis de hierarquia física: divisões de banco de dados e blocos. As divisões contêm intervalos adjacentes de linhas e são a unidade pela qual o Spanner distribui o banco de dados em recursos de computação. Ao longo do tempo, as divisões podem ser fracionadas em partes menores, mescladas ou movidas para outros nodes na instância para aumentar o paralelismo e permitir que o aplicativo faça o escalonamento. As operações que abrangem as divisões são mais caras do que as operações equivalentes que não fazem isso, devido ao aumento da comunicação. Isso ocorre mesmo que essas divisões sejam atendidas pelo mesmo node.
Há dois tipos de tabelas no Spanner: raiz (às vezes chamadas de tabelas de nível superior) e intercaladas. As tabelas intercaladas são definidas por meio da especificação de outra tabela como pai, fazendo com que as linhas da tabela intercalada sejam agrupadas com a linha pai. As tabelas raiz não têm pai, e cada linha delas define uma nova linha de nível superior ou linha raiz. As linhas intercaladas com essa linha raiz são chamadas de linhas filho, e o conjunto de uma linha raiz com todas as descendentes dela é chamado de árvore de linhas. A linha mãe já precisa existir para que seja possível inserir linhas filhas. A linha mãe já pode existir no banco de dados ou pode ser inserida antes da inserção das linhas filha na mesma transação.
O Spanner particiona automaticamente as divisões quando considera necessário devido ao tamanho ou à carga. Para preservar a localidade dos dados, o Spanner prefere adicionar limites de divisão o mais perto das tabelas raiz, para que qualquer árvore de linhas possa ser mantida em uma única divisão. Isso significa que as operações em uma árvore de linhas tendem a ser mais eficientes porque é improvável que elas precisem se comunicar com outras divisões.
No entanto, se houver um ponto de acesso em uma linha filha, o Spanner tentará adicionar limites de divisão a tabelas intercaladas para isolar essa linha de ponto de acesso, juntamente com todas as linhas filhas abaixo dela.
Escolher quais tabelas precisam ser raízes é uma decisão importante ao projetar o aplicativo para o escalonamento. As raízes são normalmente usuários, contas, projetos e similares, cujas tabelas secundárias detêm a maior parte dos demais dados sobre a entidade em questão.
Recomendações:
- Use um prefixo de chave comum para linhas relacionadas na mesma tabela com o objetivo de melhorar a localidade.
- Intercale dados relacionados em outra tabela sempre que fizer sentido.
Compensações de localidade
Se os dados são frequentemente gravados ou lidos em conjunto, eles podem beneficiar a latência e a capacidade para agrupá-los por meio da seleção cuidadosa das chaves primárias e do uso da intercalação. Isso ocorre porque há um custo fixo para se comunicar com qualquer servidor ou bloco de disco. Então por que não aproveitar isso ao máximo? Além disso, quanto maior for o número de servidores com os quais você se comunica, maior a chance de encontrar um servidor temporariamente ocupado, aumentando as latências da cauda. Por fim, as transações que abrangem divisões, por mais que sejam automáticas e transparentes no Spanner, apresentam latência e custo de CPU ligeiramente superiores devido à natureza distribuída da confirmação em duas fases.
Por outro lado, se os dados estão relacionados, mas não são frequentemente acessados em conjunto, tome providências para separá-los. Essa ação traz mais benefícios quando os dados acessados com pouca frequência são grandes. Por exemplo, muitos bancos de dados armazenam grandes dados binários fora de banda de dados da linha principal, com apenas referências aos grandes dados intercalados.
Observe que um certo nível de confirmação em duas fases e operações de dados não locais são inevitáveis em um banco de dados distribuído. Não se preocupe demais em conseguir uma história de localidade perfeita para cada operação. Concentre-se em alcançar a localidade desejada para as entidades raiz mais importantes e os padrões de acesso mais comuns e deixe que as operações distribuídas menos frequentes ou menos sensíveis ao desempenho aconteçam quando for necessário. As leituras distribuídas e a confirmação em duas fases estão disponíveis para ajudar a simplificar os esquemas e facilitar o trabalho do programador. Em todos os casos de uso, exceto os mais críticos para o desempenho, é melhor deixá-los.
Recomendações:
- Organize seus dados em hierarquias, de modo que os dados lidos ou gravados juntos tendam a estar próximos.
- Pense em armazenar grandes colunas em tabelas não intercaladas se elas forem acessadas com menor frequência.
Opções de índice
Os índices secundários permitem que você encontre rapidamente linhas por valores diferentes da chave primária. O Spanner oferece suporte a índices intercalados e não intercalados. Os índices não intercalados são o padrão e o tipo mais semelhante ao que é compatível com um RDBMS tradicional. Eles não colocam restrições sobre as colunas indexadas e, mesmo sendo eficientes, nem sempre são a melhor escolha. Os índices intercalados precisam ser definidos em colunas que compartilham um prefixo com a tabela primária e permitem um controle maior da localidade.
O Spanner armazena dados de índice da mesma forma que as tabelas, com uma linha por entrada de índice. Muitas das considerações do projeto para tabelas também se aplicam a índices. Os índices não intercalados armazenam dados em tabelas raiz. Como as tabelas raiz podem ser divididas entre qualquer linha raiz, isso garante que os índices não intercalados possam escalonar em tamanho arbitrário e ignorando pontos de acesso a praticamente qualquer carga de trabalho. Infelizmente, isso também significa que as entradas de índice geralmente não estão nas mesmas divisões que os dados principais. Isso cria latência e trabalho extra para qualquer processo de gravação e inclui divisões adicionais para consultar no tempo da leitura.
Os índices intercalados, ao contrário, armazenam dados em tabelas intercaladas. Eles são adequados quando você faz uma busca dentro do domínio de uma única entidade. Os índices intercalados forçam dados e entradas de índice a permanecer na mesma árvore de linhas, tornando as uniões entre elas muito mais eficientes. Exemplos de usos de índice intercalado:
- Acessar suas fotos por várias ordens de classificação, como data de captura, data da última modificação, título, álbum etc.
- Encontrar todas as postagens com um conjunto específico de tags.
- Encontrar compras anteriores que continham um item específico.
Recomendações:
- Use índices não intercalados quando precisar encontrar linhas de qualquer lugar no banco de dados.
- Prefira índices intercalados sempre que o escopo de uma busca for uma única entidade.
Cláusula de índice STORING
Os índices secundários permitem que você encontre linhas por atributos diferentes da chave primária. Se todos os dados solicitados estiverem no próprio índice, eles podem ser consultados por conta própria sem a leitura do registro principal. Isso pode economizar recursos significativos, já que nenhuma associação é necessária.
Infelizmente, as chaves de índice são limitadas a 16 em número e 8 KiB em tamanho agregado, restringindo o que pode ser colocado nelas. Para compensar essas limitações,
o Spanner tem a capacidade de armazenar dados extras em qualquer índice por meio da
cláusula STORING. Usar a cláusula STORING em uma coluna em um índice resulta na duplicação dos valores dela, com uma cópia armazenada no índice. Pense em um índice com
STORING como uma visualização simples materializada de tabela única. No momento, as visualizações não têm suporte nativo
no Spanner.
Outra aplicação útil de STORING é como parte de um índice NULL_FILTERED.
Isso permite que você defina o que efetivamente é uma visão materializada de um subconjunto esparso de uma tabela que você pode verificar de maneira eficiente. Por exemplo, é possível criar esse índice na coluna is_unread de uma caixa de e-mais para poder exibir a visualização de mensagens não lidas em uma única verificação de tabela, mas sem pagar por uma cópia completa de cada caixa de correio.
Recomendações:
- Faça um uso prudente de
STORINGpara compensar o desempenho do tempo de leitura sobre o tamanho de armazenamento e o tempo de gravação. - Use
NULL_FILTEREDpara controlar os custos de armazenamento de índices esparsos.
Antipadrões
Antipadrão: ordem do carimbo de data/hora
Muitos desenvolvedores de esquemas estão inclinados a definir uma tabela raiz que seja ordenada por carimbo de data/hora e atualizada a cada gravação. Infelizmente, essa é uma das coisas menos escalonáveis que você pode fazer. O motivo é que esse projeto resulta em um ponto de acesso enorme no final da tabela que não pode ser mitigado com facilidade. Conforme as taxas de gravação aumentam, o mesmo acontece com os RPCs em uma única divisão, assim como eventos de contenção de bloqueio e outros problemas. Muitas vezes, esses tipos de problemas não aparecem em testes com carga pequena e, em vez disso, aparecem depois de o aplicativo estar em produção por algum tempo. A essa altura, já é tarde demais.
Se o aplicativo precisar muito incluir um registro ordenado por carimbo de data/hora, confira se é possível torná-lo local intercalando-o em uma das outras tabelas raiz. Essa ação tem o benefício de distribuir o ponto de acesso em muitas raízes. Mas você ainda precisa ter cuidado para que cada raiz distinta tenha uma taxa de gravação suficientemente baixa.
Se você precisar de uma tabela global (de raiz cruzada) ordenada por carimbo de data/hora e necessitar de compatibilidade com taxas de gravação mais altas do que um único node é capaz, use a fragmentação no nível do aplicativo. Fragmentar uma tabela significa dividi-la em algum número N de divisões aproximadamente iguais, chamadas de fragmentos. Isso é feito normalmente prefixando a chave primária original com uma coluna ShardId adicional que detém valores inteiros entre [0, N). O ShardId de uma determinada gravação normalmente é selecionado aleatoriamente ou fazendo o hash de uma parte da chave base. Geralmente, o hash é preferido porque pode ser usado para garantir que todos os registros de um determinado tipo entrem no mesmo fragmento, melhorando o desempenho da recuperação. De qualquer forma, o objetivo é garantir que, ao longo do tempo, as gravações sejam distribuídas igualmente por todos os fragmentos.
Com essa abordagem, às vezes as leituras precisam verificar todos os fragmentos para reconstruir a ordem original total das gravações.
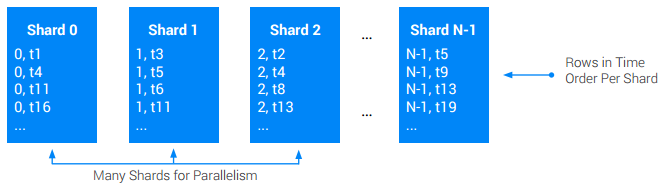
Recomendações:
- Evite tabelas e índices ordenados por carimbo de data/hora com alta taxa de gravação a todo o custo.
- Use alguma técnica para espalhar pontos de acesso, seja intercalando em outra tabela ou fragmentando.
Antipadrão: sequências
Os desenvolvedores de aplicativos adoram usar sequências de banco de dados (ou incremento automático) para gerar chaves primárias. Infelizmente, esse hábito dos tempos do RDBMS (chamado de chaves alternativas) é quase tão prejudicial quanto o antipadrão de ordenar por carimbo de data/hora descrito acima. A razão é que as sequências de banco de dados tendem a emitir valores de maneira quase monotônica, ao longo do tempo, para produzir valores em cluster um perto do outro. Isso geralmente produz pontos de acesso quando os valores são usados como chaves primárias, especialmente para linhas raiz.
Ao contrário do conhecimento convencional do RDBMS, recomendamos que você use atributos reais para chaves primárias sempre que fizer sentido, principalmente se o atributo jamais mudar.
Se você quiser gerar chaves primárias numéricas exclusivas, procure fazer com que os bits de ordem superior dos números subsequentes sejam distribuídos de modo aproximadamente igual em todo o espaço de números. Um truque é gerar números sequenciais por meios convencionais e, em seguida, fazer uma reversão em bits para chegar a um valor final. Como alternativa, você pode procurar um gerador UUID, mas tenha cuidado: nem todas as funções UUID são criadas igualmente, e algumas armazenam o carimbo de data/hora nos bits de ordem superior, anulando o benefício de maneira efetiva. Certifique-se de que seu gerador UUID escolha pseudoaleatoriamente os bits de ordem superior.
Recomendações:
- Evite usar valores de sequência de incremento como chaves primárias. Em vez disso, faça reversão em bits de um valor de sequência ou use um UUID cuidadosamente escolhido.
- Use valores reais para chaves primárias em vez de chaves alternativas.