Le tecnologie di archiviazione di Google sono alla base di alcune delle applicazioni più grandi al mondo. Tuttavia, la scalabilità non è sempre un risultato automatico dell'utilizzo di questi sistemi. I progettisti devono riflettere attentamente su come modellare i dati per garantire che la loro applicazione possa essere scalata e avere un buon rendimento man mano che cresce in varie dimensioni.
Spanner è un database distribuito e per utilizzarlo in modo efficace è necessario ragionare in modo diverso sul design dello schema e sui pattern di accesso rispetto ai database tradizionali. Per loro natura, i sistemi distribuiti costringono i progettisti a pensare alla località dei dati e dell'elaborazione.
Spanner supporta query e transazioni SQL con la possibilità di eseguire il scaling in orizzontale. Spesso è necessaria una progettazione attenta per sfruttare appieno i vantaggi di Spanner. Questo documento illustra alcune delle idee chiave che ti aiuteranno a garantire che la tua applicazione possa scalare a livelli arbitrari e a massimizzare il suo rendimento. Due strumenti in particolare hanno un grande impatto sulla scalabilità: la definizione delle chiavi e l'interlacciamento.
Layout della tabella
Le righe di una tabella Spanner sono organizzate in ordine lessicografico in base a PRIMARY
KEY. In termini concettuali, le chiavi sono ordinate in base alla concatenazione delle colonne nell'ordine in cui sono dichiarate nella clausola PRIMARY KEY. Mostra tutte le proprietà
standard della località:
- La scansione della tabella in ordine alfabetico è efficiente.
- Le righe sufficientemente vicine verranno memorizzate negli stessi blocchi di disco e verranno lette e memorizzate nella cache insieme.
Spanner replica i dati in più zone per garantire disponibilità e scalabilità. Ogni zona contiene una replica completa dei tuoi dati. Quando esegui il provisioning di un nodo dell'istanza Spanner, ne specifichi la capacità di calcolo. La capacità di calcolo è la quantità di risorse di calcolo allocata all'istanza in ciascuna di queste zone. Sebbene ogni replica sia un insieme completo di dati, i dati all'interno di una replica sono suddivisi tra le risorse di calcolo della zona.
I dati all'interno di ogni replica di Spanner sono organizzati in due livelli di gerarchia fisica: suddivisioni del database e poi blocchi. Le suddivisioni contengono intervalli di righe contigue e sono l'unità con cui Spanner distribuisce il database tra le risorse di calcolo. Nel tempo, le suddivisioni possono essere suddivise in parti più piccole, unite o spostate in altri nodi dell'istanza per aumentare il parallelismo e consentire alla tua applicazione di scalare. Le operazioni che coprono più suddivisioni sono più costose di quelle equivalenti che non lo fanno, a causa dell'aumento della comunicazione. Ciò vale anche se queste suddivisioni vengono pubblicate dallo stesso node.
In Spanner esistono due tipi di tabelle: tabelle principali (a volte chiamate tabelle di primo livello) e tabelle con interleaving. Le tabelle con interleaving vengono definite specificando un'altra tabella come principale, in modo che le righe della tabella con interleaving vengano raggruppate con la riga principale. Le tabelle principali non hanno tabella principale e ogni riga di una tabella principale definisce una nuova riga di primo livello o riga principale. Le righe interlacciate con questa riga principale sono chiamate righe secondarie e la raccolta di una riga principale più tutti i suoi discendenti è chiamata albero di righe. La riga principale deve essere esistente prima di poter inserire le righe secondarie. La riga principale può già essere presente nel database o può essere inserita prima dell'inserimento delle righe secondarie nella stessa transazione.
Spanner suddivide automaticamente le partizioni quando lo ritiene necessario a causa delle dimensioni o del carico. Per preservare la localizzazione dei dati, Spanner preferisce aggiungere confini di suddivisione il più vicino possibile alle tabelle principali, in modo che qualsiasi albero di righe possa essere mantenuto in un'unica suddivisione. Ciò significa che le operazioni all'interno di un albero di righe tendono a essere più efficienti perché è improbabile che richiedano la comunicazione con altre suddivisioni.
Tuttavia, se è presente un hotspot in una riga secondaria, Spanner tenterà di aggiungere confini di suddivisione alle tabelle con interfoliazione per isolare la riga hotspot, insieme a tutte le righe secondarie sottostanti.
Scegliere quali tabelle devono essere le tabelle principali è una decisione importante per progettare un'applicazione scalabile. Le tabelle principali sono in genere Utenti, Account, Progetti e simili e le relative tabelle secondarie contengono la maggior parte degli altri dati sull'entità in questione.
Consigli:
- Utilizza un prefisso della chiave comune per le righe correlate nella stessa tabella per migliorare la località.
- Intercala i dati correlati in un'altra tabella, se opportuno.
Svantaggi della località
Se i dati vengono scritti o letti di frequente insieme, raggrupparli selezionando attentamente le chiavi principali e utilizzando l'interlacciamento può migliorare sia la latenza sia il throughput. Questo perché la comunicazione con qualsiasi server o blocco di disco ha un costo fisso, quindi perché non ottenere il massimo possibile? Inoltre, più server con cui comunichi, maggiori sono le probabilità di trovare un server temporaneamente occupato, aumentando le latenze in coda. Infine, le transazioni che coprono più suddivisioni, sebbene automatiche e trasparenti in Spanner, hanno un costo e una latenza della CPU leggermente superiori a causa della natura distribuita del commit a due fasi.
Al contrario, se i dati sono correlati, ma non vengono spesso utilizzati insieme, valuta la possibilità di separarli. Questo approccio offre i maggiori vantaggi quando i dati a cui si accede raramente sono di grandi dimensioni. Ad esempio, molti database archiviano i dati binari di grandi dimensioni out-of-band rispetto ai dati di riga principali, con solo riferimenti ai dati di grandi dimensioni interlacciati.
Tieni presente che un certo livello di commit a due fasi e operazioni sui dati non locali sono inevitabili in un database distribuito. Non preoccuparti troppo di ottenere una storia della località perfetta per ogni operazione. Concentrati sull'ottenimento della località desiderata per le entità principali più importanti e per i pattern di accesso più comuni e lascia che le operazioni distribuite meno frequenti o meno sensibili al rendimento vengano eseguite quando necessario. Il commit a due fasi e le letture distribuite sono lì per semplificare gli schemi e sgravare il lavoro dei programmatori: in tutti i casi d'uso, tranne quelli più critici per le prestazioni, è meglio utilizzarli.
Consigli:
- Organizza i dati in gerarchie in modo che i dati letti o scritti insieme tendano a trovarsi nelle vicinanze.
- Valuta la possibilità di archiviare colonne di grandi dimensioni in tabelle non interlacciate se accedute meno di frequente.
Opzioni di indice
Gli indici secondari ti consentono di trovare rapidamente le righe in base a valori diversi dalla chiave primaria. Spanner supporta sia gli indici non interlacciati sia quelli interlacciati. Gli indici non interlacciati sono quelli predefiniti e il tipo più simile a quello supportato in un RDBMS tradizionale. Non impongono limitazioni alle colonne da indicizzare e, sebbene siano molto efficaci, non sono sempre la scelta migliore. Gli indici interlacciati devono essere definiti su colonne che condividono un prefisso con la tabella principale e consentono un maggiore controllo della località.
Spanner memorizza i dati dell'indice nello stesso modo delle tabelle, con una riga per voce dell'indice. Molte delle considerazioni di progettazione per le tabelle si applicano anche agli indici. Gli indici non interlacciati archiviano i dati nelle tabelle principali. Poiché le tabelle principali possono essere suddivise tra qualsiasi riga principale, questo garantisce che gli indici non interlacciati possano essere scalati in base a dimensioni arbitrarie e, ignorando gli hot spot, a quasi tutti i carichi di lavoro. Purtroppo, significa anche che le voci dell'indice in genere non si trovano nelle stesse suddivisioni dei dati principali. Ciò comporta un lavoro e una latenza aggiuntivi per qualsiasi processo di scrittura e aggiunge ulteriori suddivisioni da consultare al momento della lettura.
Gli indici con interfoliazione, invece, archiviano i dati in tabelle con interfoliazione. Sono adatti quando esegui ricerche all'interno del dominio di una singola entità. Gli indici interlacciati forzano le voci di dati e di indice a rimanere nella stessa struttura ad albero di righe, rendendo le unioni tra di loro molto più efficienti. Esempi di utilizzo di un indice interlacciato:
- Accedere alle foto in base a vari ordini di ordinamento, ad esempio data di scatto, data di ultima modifica, titolo, album e così via.
- Trovare tutti i tuoi post che hanno un determinato insieme di tag.
- Trovare i miei ordini precedenti che contenevano un articolo specifico.
Consigli:
- Utilizza gli indici non interlacciati quando devi trovare righe da qualsiasi punto del database.
- Preferisci gli indici interlacciati quando le tue ricerche sono limitate a una singola entità.
Clausola di indice STORING
Gli indici secondari ti consentono di trovare righe in base ad attributi diversi dalla chiave primaria. Se tutti i dati richiesti sono nell'indice stesso, possono essere consultati autonomamente senza leggere il record principale. In questo modo puoi risparmiare risorse significative poiché non è richiesta alcuna unione.
Purtroppo, il numero di chiavi di indice è limitato a 16 e le dimensioni aggregate sono pari a 8 KiB, il che limita ciò che è possibile inserire. Per compensare queste limitazioni,
Spanner ha la possibilità di memorizzare dati aggiuntivi in qualsiasi indice tramite la
clausola STORING. STORING una colonna in un indice comporta la duplicazione dei relativi valori, con una copia memorizzata nell'indice. Puoi considerare un indice conSTORING come una semplice vista materializzata a tabella singola (al momento le viste non sono supportate in modo nativo in Spanner).
Un'altra applicazione utile di STORING è all'interno di un indice NULL_FILTERED.
In questo modo puoi definire quella che è effettivamente una vista materializzata di un sottoinsieme sparso di una tabella che puoi eseguire la scansione in modo efficiente. Ad esempio, potresti creare un indice di questo tipo nella colonna is_unread di una casella di posta per poter visualizzare la visualizzazione dei messaggi non letti in un'unica scansione della tabella, ma senza pagare una copia completa di ogni casella di posta.
Consigli:
- Utilizza
STORINGcon cautela per trovare il giusto equilibrio tra il rendimento in termini di tempo di lettura e le dimensioni dello spazio di archiviazione e il rendimento in termini di tempo di scrittura. - Utilizza
NULL_FILTEREDper controllare i costi di archiviazione degli indici sparsi.
Antipattern
Anti-pattern: ordinamento dei timestamp
Molti progettisti di schemi sono inclini a definire una tabella principale ordinata in base al timestamp e aggiornata a ogni scrittura. Purtroppo, questa è una delle opzioni meno scalabili che puoi adottare. Il motivo è che questo design genera un enorme hotspot alla fine della tabella che non può essere facilmente mitigato. Man mano che le velocità di scrittura aumentano, aumentano anche le chiamate RPC a una singola suddivisione, così come gli eventi di contesa dei blocchi e altri problemi. Spesso questi tipi di problemi non si verificano nei test di carico ridotto, ma compaiono dopo che l'applicazione è in produzione da un po' di tempo. A quel punto, è troppo tardi.
Se la tua applicazione deve includere un log ordinato in base al timestamp, valuta la possibilità di renderlo locale intercalandolo in una delle altre tabelle principali. Il vantaggio è che l'hotspot viene distribuito su molti root. Tuttavia, devi comunque assicurarti che ogni radice distinta abbia una frequenza di scrittura sufficientemente bassa.
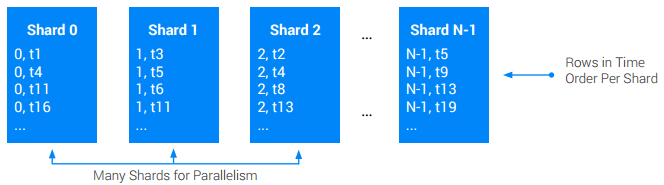
Se hai bisogno di una tabella globale (con radice incrociata) ordinata per timestamp e devi supportare velocità di scrittura più elevate rispetto a quelle supportate da un singolo nodo, utilizza lo sharding a livello di applicazione. La suddivisione in parti di una tabella significa suddividerla in un numero N di suddivisioni approssimativamente uguali chiamate shard. In genere, questo viene fatto anteponendo alla chiave primaria originale una colonna ShardId aggiuntiva contenente valori interi compresi tra [0, N). Il ShardId per una determinata scrittura viene solitamente selezionato in modo casuale o sottoponendo ad hashing una parte della chiave di base. L'hashing è spesso preferito perché può essere utilizzato per garantire che tutti i record di un determinato tipo vengano inseriti nello stesso shard, migliorando le prestazioni del recupero. In ogni caso, l'obiettivo è assicurarsi che, nel tempo, le scritture vengano distribuite equamente su tutti gli shard.
A volte, questo approccio comporta che le letture debbano eseguire la scansione di tutti i frammenti per ricostruire
l'ordinamento totale originale delle scritture.
Consigli:
- Evita a tutti i costi tabelle e indici ordinati per timestamp con una frequenza di scrittura elevata.
- Utilizza una tecnica per distribuire gli hot spot, ad esempio l'interlacciamento in un'altra tabella o la suddivisione in parti.
Antipattern: sequenze
Gli sviluppatori di applicazioni amano utilizzare le sequenze del database (o l'incremento automatico) per generare chiavi principali. Purtroppo, questa abitudine dei tempi degli RDBMS (chiamate chiavi surrogate) è quasi dannosa quanto l'antipattern di ordinamento dei timestamp descritto sopra. Il motivo è che le sequenze di database tendono a emettere valori in modo quasi monotono, nel tempo, per produrre valori raggruppati tra loro. In genere, questo genera hot spot se vengono utilizzate come chiavi principali, in particolare per le righe principali.
Contrariamente alla saggezza convenzionale dei sistemi RDBMS, ti consigliamo di utilizzare attributi reali per le chiavi principali, se opportuno. Questo accade soprattutto se l'attributo non cambierà mai.
Se vuoi generare chiavi principali univoche numeriche, cerca di ottenere i bit di ordine elevato dei numeri successivi in modo che siano distribuiti in modo approssimativamente uniforme nell'intero spazio numerico. Un trucco è generare numeri sequenziali con metodi convenzionali, quindi eseguire il bit-reversing per ottenere un valore finale. In alternativa, puoi utilizzare un generatore di UUID, ma fai attenzione: non tutte le funzioni UUID sono create allo stesso modo e alcune memorizzano il timestamp nei bit di ordine superiore, vanificando di fatto il vantaggio. Assicurati che il generatore di UUID scelga in modo pseudo-casuale i bit di ordine superiore.
Consigli:
- Evita di utilizzare valori di sequenza incrementali come chiavi principali. Esegui invece l'inversione dei bit di un valore di sequenza o utilizza un UUID scelto con cura.
- Utilizza valori reali per le chiavi principali anziché chiavi surrogate.