Google 存储技术为一些全球最大型的应用提供支持。 但是,使用这些系统并不总是伴随着应用规模的自动扩展。 设计师必须仔细思考如何对数据进行建模,以确保应用可以随着在各个维度的发展而进行扩展并正常运行。
Spanner 是一个分布式数据库,若想有效使用它,您需要在架构设计和访问模式方面采用不同于传统数据库的思考方式。由于其本身性质,分布式系统会迫使设计者考虑数据局部性和处理局部性。
Spanner 支持 SQL 查询和事务,且具备横向扩展能力。要想实现 Spanner 的全部优势,通常需要精心的设计。此白皮书探讨了一些关键理念,这些理念有助于确保您的应用可以扩展到任意规模,还有助于实现应用性能最大化。特别是以下两种工具对可扩展性有很大影响:键定义和交错。
表的布局
Spanner 表中的行按 PRIMARY
KEY 的字典顺序排序。从概念上讲,键通过列的串联按照其在 PRIMARY KEY 子句中声明的顺序排列。这表现出了局部性的所有标准属性:
- 按字典顺序扫描表是有效的。
- 足够接近的行将存储在相同的磁盘块中,并将被一起读取和缓存。
Spanner 可将您的数据复制到多个可用区,以实现可用性和可扩展性。每个可用区都拥有完整的数据副本。预配 Spanner 实例节点时,您可以指定其计算容量。计算容量是指在每个可用区中分配给实例的计算资源量。虽然每个副本都是一组完整的数据,但副本中的数据会在该可用区中的计算资源之间进行分区。
每个 Spanner 副本中的数据被分为两个级别的物理层次结构:数据库分块和区块。分块具备连续的行范围,并且是 Spanner 将数据库分配到各个计算资源时所采用的单位。随着时间的推移,分片可能会分成更小的部分、进行合并或移动到实例中的其他节点,以提高并行性并允许您的应用进行扩展。由于增加了通信,跨分片的操作比不跨分片的等效操作成本更高。即使这些分片碰巧由同一节点提供也是如此。
Spanner 中有两种类型的表:根表(有时称为顶层表)和交织表。交错表通过指定另一个表作为其父表来定义,因此交错表中的行与父行聚集。根表没有父表,并且根表中的每一行都定义了一个新的顶层行或根行。与此根行交错的行称为子行,根行及其所有后代行的集合称为行树。在插入子行之前,父行必须已经存在。父行可以已经存在于数据库中,也可以在将子行插入到同一事务中之前插入。
Spanner 会基于大小或负载在其认为必要时自动对分块进行分区。为了保留数据的局部性,Spanner 倾向于添加尽可能靠近根表的分块边界,以便任何给定的行树可以保留在单个分块中。这意味着行树内部的操作往往效率更高,因为它们不需要与其他分片进行通信。
但是,如果子行中包含热点,Spanner 会尝试将分块边界添加到交织表中,以隔离该热点行及其下面的所有子行。
选择哪些表作为根是设计可扩展应用时需要做出的重要决定。根通常是用户、账号、项目之类的东西,其子表保存了关于相关实体的大多数其他数据。
建议:
- 为同一个表中的相关行使用共同的键前缀,以提升局部性。
- 尽可能将相关数据交错到另一个表中。
局部性权衡
如果数据经常被一起写入或读取,那么通过谨慎选择主键和使用交错来对数据进行聚集,可以缩短延迟时间并提高吞吐量。这是因为与任何服务器或磁盘块进行通信都有固定的费用,所以应尽可能在通信时完成更多操作。 此外,与您通信的服务器越多,您遇到暂时繁忙的服务器的可能性就越大,尾延迟时间也会随之增加。 最后,由于两段式提交所具有的分布式特性,虽然跨分块的事务在 Spanner 中自动进行且透明,但其 CPU 成本和延迟时间稍高。
反之,如果数据具备相关性,但不经常一起被访问,可以考虑特意将它们分开。当不常访问的数据较大时,这是最有利的方式。例如,许多数据库存储主行数据中的大型带外二进制数据,只引用交错的大型数据。
请注意,分布式数据库中不可避免地存在一定程度的两段式提交和非局部性数据操作。无需过分注重为每个操作实现完美的局部性。只需专注于为最重要的根实体和最常见的访问模式实现所需的局部性,并在需要时执行频率较低或性能敏感度较低的分布式操作即可。两段式提交和分布式读取有助于简化架构并减轻程序员的工作量:除了最以性能为导向的用例之外,最好允许这两种操作的存在。
建议:
- 将数据整理到层次结构中,以便一起读取或写入的数据彼此之间往往相隔不远。
- 如果访问频率较低,可以考虑将大型列存储在非交错表中。
索引选项
通过二级索引,您可以使用主键以外的值来快速查找行。Spanner 同时支持非交织索引和交织索引。非交错索引为默认选项,并且其类型与传统 RDBMS 支持的类型最相似。它们对被编入索引的列不设任何限制,虽然其功能强大,但并不总是最好的选择。交错索引必须定义在与父表共用前缀的列上,并且能够更好地控制局部性。
Spanner 以与表相同的方式存储索引数据,每个索引条目占用一行。表的许多设计注意事项也适用于索引。 非交错索引将数据存储在根表中。 由于根表可以在任何根行之间进行拆分,因此可确保非交错索引能够扩展为任意大小以及(忽略热点)几乎任何工作负载。遗憾的是,这也意味着索引条目与主数据通常不在同一分片中。这一点为写入过程带来了额外的工作量和延迟时间,并导致读取时需要查询更多的分片。
相反,交错索引将数据存储在交错表中。当您在单个实体域中搜索时,这种索引较为合适。 交错索引强制将数据和索引条目保留在同一个行树中,使得它们之间的连接效率更高。 交错索引的用途示例如下:
- 按拍摄日期、上次修改日期、标题、相册等各种排序顺序访问您的照片。
- 查找包含特定一组标记的所有帖子。
- 查找包含特定商品的历史购物订单。
建议:
- 当您需要从数据库的任意位置查找行时,请使用非交错索引。
- 如果您的搜索范围限定为单个实体,请优先使用交错索引。
STORING 索引子句
通过二级索引,您可以使用主键以外的属性来查找行。如果请求的所有数据都在索引本身中,则可以在不读取主记录的情况下自行查询。这样可以节省大量资源,因为不需要连接。
遗憾的是,索引键的数量最多为 16 个,总大小限制为 8 KiB,因此可以存储的内容有限。为了应对这些限制,Spanner 可以通过 STORING 子句在任意索引中存储额外的数据。对索引中的列采用 STORING 子句可复制其值,同时在索引中存储其副本。您可以将采用 STORING 子句的索引想象为单个简单表的物化视图(目前,Spanner 本身不支持视图)。
STORING 的另一个实用用法是作为 NULL_FILTERED 索引的一部分。
它允许您定义可以有效扫描的表的稀疏子集的有效物化视图。例如,您可以在邮箱的 is_unread 列上创建此类索引,以便在单次表扫描中提供未读邮件视图,而无需为每个邮箱的完整副本付费。
建议:
- 谨慎使用
STORING,在读取时间性能与存储大小和写入时间性能间进行权衡。 - 使用
NULL_FILTERED来控制稀疏索引的存储成本。
反模式
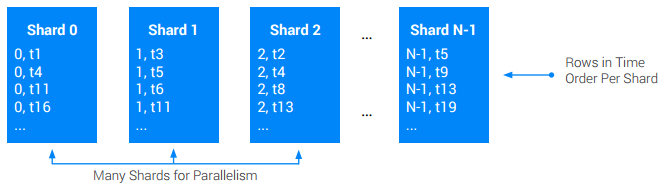
反模式:时间戳排序
许多架构设计者倾向于定义一个按时间戳排序的根表,并在每次写入时进行更新。遗憾的是,这是您可以进行的最不具备可扩展性的操作之一。原因在于,这种设计会在表的末尾形成巨大的热点,且这个热点无法轻易消除。随着写入速率的提升,对单个分片的远程过程调用 (RPC) 也会增加,锁争用事件和其他问题也会随之增加。这些问题通常不会出现在小负载测试中,而是会在应用进入生产环境一段时间后出现。但那时已经太晚了!
如果您的应用确实必须包含按时间戳排序的日志,请考虑是否可以将日志交错到其他某个根表以赋予其局部性。这样做的优点是可以将热点分布到许多根表中。 但是您仍然需要注意让每个根表的写入速率足够低。
如果您需要按时间戳排序的全局(跨根)表,并且您需要在该表中支持比单个节点更高的写入速率,请使用应用级分片。将表分片意味着将其划分为 N 个大致相等的称为碎片的部分。通常,这是通过在原始主键前添加一个额外的 ShardId 列来完成的,该列具有介于 [0, N) 之间的整数值。给定写入的 ShardId 通常通过以下两种方式选择:随机选择,或者通过对基本键的一部分执行哈希算法来选择。哈希算法通常是首选,因为它可用于确保给定类型的所有记录分入同一碎片,从而提高检索性能。无论哪种方式,目标都是确保随着时间的推移,写入均匀分布在所有碎片中。
这种方法有时意味着读取操作需要扫描所有碎片以重新构建写入的原始总排序。
建议:
- 不惜一切代价避免高写入速率且按时间戳排序的表和索引。
- 使用一些技术来分散热点,无论是交错到另一个表还是分片。
反模式:序列
应用开发者喜欢使用数据库序列(或自动增量)来生成主键。遗憾的是,源自 RDBMS 时代的这种习惯(称为代理键)几乎与上述时间戳排序反模式一样不利。原因在于数据库序列倾向于以拟单调的方式发出值,随着时间的推移,会生成彼此近距离聚集的值。在用作主键(尤其是用于根行)时,这通常会产生热点。
与 RDBMS 传统方式相反,我们建议您尽可能使用主键的真实属性。如果属性永远不会改变,则尤其要如此。
如果您希望生成唯一的数值主键,则目标是在整个数值空间中大致均匀地分布后续数值的高序位。一种方法是通过常规方式生成序列号,然后进行位反转以获得最终值。或者,您可以查看 UUID 生成器,但要注意:并非所有 UUID 函数都是以同样的方式创建的,有些将时间戳存储在高序位中,因而会将优势抵消掉。请确保您的 UUID 生成器伪随机选择高序位。
建议:
- 避免使用递增序列值作为主键。相反,您应对序列值进行位反转,或使用精心选择的 UUID。
- 使用主键(而非代理键)的真实值。