Spanner è un database distribuito, scalabile e a elevata coerenza creato dagli ingegneri di Google per supportare alcune delle applicazioni più importanti di Google. Prende le idee di base delle community di database e sistemi distribuiti e le espande in nuovi modi. Spanner espone questo servizio Spanner interno come servizio pubblico disponibile sulla piattaforma Google Cloud.
Poiché Spanner deve gestire i rigorosi requisiti di uptime e scalabilità imposti dalle applicazioni aziendali critiche di Google, lo abbiamo creato da zero per essere un database ampiamente distribuito: il servizio può essere utilizzato su più macchine, più data center e più regioni. Sfruttiamo questa distribuzione per gestire set di dati e carichi di lavoro enormi, mantenendo al contempo una disponibilità molto elevata. Inoltre, volevamo che Spanner fornisse le stesse garanzie di coerenza rigorosa offerte da altri database di livello enterprise, perché volevamo creare un'esperienza eccezionale per gli sviluppatori. È molto più facile ragionare e scrivere software per un database che supporta la coerenza forte rispetto a un database che supporta solo la coerenza a livello di riga, la coerenza a livello di entità o non offre affatto garanzie di coerenza.
In questo documento descriviamo in dettaglio il funzionamento delle scritture e delle letture in Spanner e come Spanner garantisce una coerenza elevata.
Punti di partenza
Alcuni set di dati sono troppo grandi per essere inseriti in un'unica macchina. Esistono anche scenari in cui il set di dati è piccolo, ma il carico di lavoro è troppo elevato per essere gestito da un'unica macchina. Ciò significa che dobbiamo trovare un modo per suddividere i dati in parti separate che possono essere archiviate su più macchine. Il nostro approccio consiste nel partizionare le tabelle di database in intervalli di chiavi contigui chiamati split. Una singola macchina può gestire più suddivisioni ed è disponibile un servizio di ricerca rapida per determinare le macchine che gestiscono un determinato intervallo di chiavi. I dettagli su come vengono suddivisi i dati e su quali macchine si trovano sono trasparenti per gli utenti di Spanner. Il risultato è un sistema in grado di fornire latenze ridotte sia per le letture che per le scritture, anche sotto carichi di lavoro elevati, su larga scala.
Vogliamo inoltre assicurarci che i dati siano accessibili nonostante gli errori. Per garantire questo, replichiamo ogni suddivisione su più macchine in domini di errore distinti. La replica coerente alle diverse copie della suddivisione è gestita dall'algoritmo Paxos. In Paxos, purché la maggior parte delle repliche di voto per la suddivisione sia attiva, una di queste repliche può essere eletta leader per elaborare le scritture e consentire alle altre repliche di gestire le letture.
Spanner fornisce sia transazioni di sola lettura sia transazioni di lettura/scrittura. I primi sono il tipo di transazione preferito per le operazioni
(incluse le istruzioni SELECT SQL) che non modificano i dati. Le transazioni di sola lettura continuano a fornire una coerenza elevata e, per impostazione predefinita, operano sulla copia più recente dei dati. Tuttavia, possono essere eseguiti senza la necessità di alcun tipo di blocco interno, il che li rende più veloci e scalabili. Le transazioni di lettura/scrittura vengono utilizzate per le transazioni che inseriscono, aggiornano o eliminano i dati; sono incluse le transazioni che eseguono letture seguite da una scrittura. Sono ancora molto scalabili, ma le transazioni di lettura/scrittura introducono i blocchi e devono essere orchestrate dai leader Paxos. Tieni presente che il blocco è trasparente per i clienti Spanner.
Molti sistemi di database distribuiti precedenti hanno scelto di non fornire forti garanzie di coerenza a causa della costosa comunicazione tra macchine solitamente richiesta. Spanner è in grado di fornire snapshot fortemente coerenti
in tutto il database utilizzando una tecnologia sviluppata da Google
chiamata TrueTime. Come il condensatore di flusso in una macchina del tempo di circa il 1985, TrueTime è ciò che rende possibile Spanner. Si tratta di un'API che consente a qualsiasi macchina nei data center di Google di conoscere l'ora globale esatta con un elevato grado di precisione (ovvero entro pochi millisecondi). In questo modo, diverse macchine Spanner possono ragionare sull'ordine delle operazioni di transazione (e fare in modo che l'ordine corrisponda a quello osservato dal cliente), spesso senza alcuna comunicazione. Per far funzionare TrueTime, Google ha dovuto dotare i suoi data center di hardware speciale (orologi atomici). La precisione e l'accuratezza del tempo risultanti sono molto più elevate di quelle che possono essere raggiunte con altri protocolli (come NTP). In particolare, Spanner assegna un timestamp a tutte le letture e le scritture. Una
transazione con timestamp T1 rifletterà sempre i risultati di tutte le scritture
avvenute prima di T1. Se una macchina vuole soddisfare una lettura a T2, deve assicurarsi che la sua visualizzazione dei dati sia aggiornata almeno fino a T2. Grazie a TrueTime, questa determinazione è in genere molto economica. I protocolli per garantire la coerenza dei dati sono complicati, ma sono trattati più nel documento originale su Spanner e in questo documento su Spanner e sulla coerenza.
Esempio pratico
Vediamo alcuni esempi pratici per capire come funziona:
CREATE TABLE ExampleTable (
Id INT64 NOT NULL,
Value STRING(MAX),
) PRIMARY KEY(Id);
In questo esempio abbiamo una tabella con una semplice chiave primaria intera.
| Suddividi | KeyRange |
|---|---|
| 0 | [-∞,3) |
| 1 | [3224) |
| 2 | [224,712) |
| 3 | [712,717) |
| 4 | [717,1265) |
| 5 | [1265,1724) |
| 6 | [1724,1997) |
| 7 | [1997,2456) |
| 8 | [2456,∞) |
Dato lo schema di ExampleTable riportato sopra, lo spazio delle chiavi principali è suddiviso in split. Ad esempio, se in ExampleTable è presente una riga con un Id di
3700, verrà visualizzata in Separa 8. Come descritto sopra, la suddivisione 8 stessa viene replicata su più macchine.
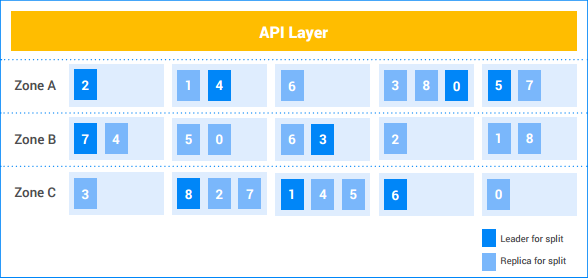
In questo esempio di istanza Spanner, il cliente ha cinque nodi e l'istanza è replicata in tre zone. Le nove suddivisioni sono numerate da 0 a 8, con i leader di Paxos per ogni suddivisione in ombra scura. Le suddivisioni hanno anche repliche in ogni zona (ombreggiatura chiara). La distribuzione delle suddivisioni tra i nodi può essere diversa in ogni zona e i leader Paxos non si trovano tutti nella stessa zona. Questa flessibilità consente a Spanner di essere più robusto nei confronti di determinati tipi di profili di carico e modalità di errore.
Scrittura con suddivisione singola
Supponiamo che il cliente voglia inserire una nuova riga (7, "Seven") in
ExampleTable.
- Il livello API cerca la suddivisione proprietaria dell'intervallo di chiavi contenente
7. Risiede in Particella 1. - Il livello API invia la richiesta di scrittura al leader del gruppo 1.
- Il leader avvia una transazione.
- Il leader tenta di ottenere un blocco di scrittura sulla riga
Id=7. Si tratta di un'operazione locale. Se un'altra transazione di lettura/scrittura concorrente sta attualmente leggendo questa riga, l'altra transazione ha un blocco di lettura e la transazione corrente si blocca finché non riesce ad acquisire il blocco di scrittura.- È possibile che la transazione A sia in attesa di un blocco detenuto dalla transazione B e che la transazione B sia in attesa di un blocco detenuto dalla transazione A. Poiché nessuna transazione rilascia un blocco finché non acquisisce tutti i blocchi, questo può portare a un deadlock. Spanner utilizza un algoritmo standard di prevenzione dei deadlock "wound-wait" per garantire l'avanzamento delle transazioni. In particolare, una transazione "più recente" attenderà un blocco detenuto da una transazione "più vecchia", ma una transazione "più vecchia" "interromperà" (abortirà) una transazione più recente che detiene un blocco richiesto dalla transazione precedente. Pertanto, non abbiamo mai cicli di deadlock di attendenti di blocco.
- Una volta acquisito il blocco, il leader assegna alla transazione un timestamp basato su TrueTime.
- Questo timestamp è garantito essere maggiore di quello di qualsiasi transazione precedentemente confermata che ha modificato i dati. In questo modo, l'ordine delle transazioni (come percepito dal cliente) corrisponde all'ordine delle modifiche ai dati.
- Il leader comunica alle repliche di Spalla 1 la transazione e il relativo timestamp. Una volta che la maggior parte di queste repliche ha archiviato la mutazione della transazione in un sistema di archiviazione stabile (nel file system distribuito), la transazione viene confermata. In questo modo, la transazione è recuperabile anche se si verifica un errore in una minoranza di macchine. Le repliche non applicano ancora le mutazioni alla propria copia dei dati.
Il leader attende fino a quando non può essere certo che il timestamp della transazione sia trascorso in tempo reale. In genere sono necessari alcuni millisecondi per eliminare qualsiasi incertezza nel timestamp TrueTime. Questo garantisce una forte coerenza: una volta che un cliente ha appreso l'esito di una transazione, è garantito che tutti gli altri lettori vedranno gli effetti della transazione. Questo "tempo di attesa del commit" in genere si sovrappone alla comunicazione della replica nel passaggio precedente, pertanto il costo effettivo della latenza è minimo. Ulteriori dettagli sono descritti in questo documento.
Il leader risponde al cliente per comunicare che la transazione è stata committata, indicando facoltativamente il timestamp del commit della transazione.
Parallelamente alla risposta al client, le mutazioni delle transazioni vengono applicate ai dati.
- Il leader applica le mutazioni alla propria copia dei dati e poi libera i blocchi delle transazioni.
- Il leader informa anche le altre repliche del gruppo 1 di applicare la mutazione alle proprie copie dei dati.
- Qualsiasi transazione di lettura/scrittura o di sola lettura che deve vedere gli effetti delle mutazioni attende che le mutazioni vengano applicate prima di tentare di leggere i dati. Per le transazioni di lettura/scrittura, questo viene applicato perché la transazione deve acquisire un blocco di lettura. Per le transazioni di sola lettura, questo viene applicato confrontando il timestamp della lettura con quello dei dati applicati più recenti.
Tutto ciò avviene in genere in pochi millisecondi. Questa scrittura è il tipo di scrittura più economica eseguita da Spanner, poiché è coinvolta una singola suddivisione.
Scrittura con più suddivisioni
Se sono coinvolte più suddivisioni, è necessario un livello aggiuntivo di coordinamento (utilizzando l'algoritmo di commit in due fasi standard).
Supponiamo che la tabella contenga quattromila righe:
| 1 | "one" |
| 2 | "due" |
| … | … |
| 4000 | "four thousand" |
Supponiamo che il cliente voglia leggere il valore della riga 1000 e scrivere un valore nelle righe 2000, 3000 e 4000 all'interno di una transazione. Verrà eseguita
in una transazione di lettura/scrittura come segue:
- Il client avvia una transazione di lettura/scrittura, t.
- Il client invia una richiesta di lettura della riga 1000 al livello API e la contrassegna come parte di t.
- Il livello API cerca la suddivisione proprietaria della chiave
1000. Si trova in Split 4. Il livello API invia una richiesta di lettura al leader del gruppo 4 e la contrassegna come parte di t.
Il leader del gruppo 4 tenta di ottenere un blocco di lettura sulla riga
Id=1000. Si tratta di un'operazione locale. Se un'altra transazione concorrente ha un blocco di scrittura su questa riga, la transazione corrente si blocca finché non riesce ad acquisire il blocco. Tuttavia, questo blocco di lettura non impedisce ad altre transazioni di ottenere blocchi di lettura.- Come nel caso di una singola partizione, il deadlock viene evitato tramite "attesa con ritardo".
Il leader cerca il valore di
Id1000("Mille") e restituisce il risultato della lettura al client.
Più tardi…Il client invia una richiesta di commit per la transazione t. Questa richiesta di commit contiene 3 mutazioni: (
[2000, "Dos Mil"],[3000, "Tres Mil"]e[4000, "Quatro Mil"]).- Tutte le suddivisioni coinvolte in una transazione diventano partecipanti della transazione. In questo caso, il set di partizione 4 (che ha eseguito la lettura per la chiave
1000), il set di partizione 7 (che gestirà la mutazione per la chiave2000) e il set di partizione 8 (che gestirà le mutazioni per le chiavi3000e4000) sono partecipanti.
- Tutte le suddivisioni coinvolte in una transazione diventano partecipanti della transazione. In questo caso, il set di partizione 4 (che ha eseguito la lettura per la chiave
Un partecipante diventa il coordinatore. In questo caso, forse il leader del gruppo 7 diventa il coordinatore. Il compito del coordinatore è assicurarsi che la transazione venga eseguita o interrotta in modo atomico su tutti i partecipanti. In altre parole, non verrà eseguito il commit per un partecipante e l'interruzione per un altro.
- Il lavoro svolto dai partecipanti e dai coordinatori viene in realtà svolto dalle macchine leader di queste suddivisioni.
I partecipanti acquisiscono delle serrature. Questa è la prima fase dell'commit a due fasi.
- Il set di partizione 7 acquisisce un blocco di scrittura sulla chiave
2000. - La partizione 8 acquisisce una serratura di scrittura sulla chiave
3000e sulla chiave4000. - La partizione 4 verifica di avere ancora un blocco di lettura sulla chiave
1000(in altre parole, che il blocco non sia andato perso a causa di un arresto anomalo della macchina o dell'algoritmo wound-wait). - Ogni partecipante suddivide i propri set di chiavi replicandoli su almeno la maggior parte delle repliche suddivise. In questo modo, le chiavi possono rimanere bloccate anche in caso di errori del server.
- Se tutti i partecipanti informano correttamente il coordinatore che i loro blocchi sono trattenuti, la transazione complessiva può essere confermata. In questo modo, esiste un punto in cui tutte le chiavi necessarie per la transazione sono tratte e questo punto diventa il punto di commit della transazione, in modo da poter ordinare correttamente gli effetti di questa transazione rispetto alle altre transazioni che si sono verificate prima o dopo.
- È possibile che le chiavi non possano essere acquisite (ad esempio, se viene rilevato un blocco tramite l'algoritmo di attesa con ritardo). Se un partecipante afferma di non poter eseguire il commit della transazione, l'intera transazione viene interrotta.
- Il set di partizione 7 acquisisce un blocco di scrittura sulla chiave
Se tutti i partecipanti e il coordinatore acquisiscono correttamente le chiavi, il coordinatore (partizione 7) decide di eseguire il commit della transazione. Assegna un timestamp alla transazione in base a TrueTime.
- Questa decisione di commit, così come le mutazioni per la chiave
2000, vengono replicate nei membri del gruppo di suddivisione 7. Una volta che la maggior parte delle repliche di Split 7 registra la decisione di commit nello spazio di archiviazione stabile, la transazione viene committata.
- Questa decisione di commit, così come le mutazioni per la chiave
Il Coordinatore comunica l'esito della transazione a tutti i partecipanti. Questa è la seconda fase del commit a due fasi.
- Ogni leader del partecipante esegue la replica della decisione di commit alle repliche della suddivisione del partecipante.
Se la transazione viene eseguita, il Coordinatore e tutti i Partecipanti applicano le mutazioni ai dati.
- Come nel caso della suddivisione singola, i lettori successivi dei dati presso il Coordinatore o i partecipanti devono attendere che i dati vengano applicati.
Il coordinatore risponde al cliente per indicare che la transazione è stata committata, restituendo facoltativamente il timestamp del commit della transazione
- Come nel caso di una singola suddivisione, il risultato viene comunicato al cliente dopo un'attesa del commit, per garantire una coerenza rigorosa.
Tutto ciò avviene in genere in pochi millisecondi, anche se in genere un po' più che nel caso di una singola suddivisione a causa della maggiore coordinazione tra le suddivisioni.
Lettura efficace (multi-split)
Supponiamo che il cliente voglia leggere tutte le righe in cui Id >= 0 e Id < 700 fanno parte di una transazione di sola lettura.
- Il livello API cerca le suddivisioni che possiedono le chiavi nell'intervallo
[0, 700). Queste righe sono di proprietà di Suddivisione 0, Suddivisione 1 e Suddivisione 2. - Poiché si tratta di una lettura affidabile su più macchine, il livello API sceglie il timestamp di lettura utilizzando il TrueTime corrente. In questo modo, entrambe le letture
restituiranno i dati della stessa istantanea del database.
- Anche altri tipi di letture, come le letture non aggiornate, scelgono un timestamp per la lettura, ma il timestamp potrebbe essere nel passato.
- Il livello API invia la richiesta di lettura a una replica di Split 0, a una replica di Split 1 e a una replica di Split 2. Include anche il timestamp di lettura selezionato nel passaggio precedente.
Per le letture sicure, la replica di servizio in genere esegue un'RPC al leader per chiedere il timestamp dell'ultima transazione da applicare e la lettura può procedere dopo l'applicazione della transazione. Se la replica è il leader o stabilisce di essere sufficientemente aggiornata per soddisfare la richiesta dal suo stato interno e da TrueTime, esegue direttamente la lettura.
I risultati delle repliche vengono combinati e restituiti al client (tramite il livello API).
Tieni presente che le letture non acquisiscono blocchi nelle transazioni di sola lettura. Inoltre, poiché le letture possono essere potenzialmente eseguite da qualsiasi replica aggiornata di una determinata suddivisione, la velocità effettiva di lettura del sistema è potenzialmente molto elevata. Se il client è in grado di tollerare letture non aggiornate da almeno dieci secondi, la velocità effettiva di lettura può essere ancora più elevata. Poiché in genere il leader aggiorna le repliche con l'ultimo timestamp sicuro ogni dieci secondi, le letture con un timestamp obsoleto possono evitare un RPC aggiuntivo al leader.
Conclusione
Tradizionalmente, i progettisti di sistemi di database distribuiti hanno riscontrato che le garanzie transazionali solide sono costose, a causa di tutte le comunicazioni tra macchine richieste. Con Spanner, ci siamo concentrati sulla riduzione del costo delle transazioni per renderle possibili su larga scala e nonostante la distribuzione. Uno dei motivi principali per cui funziona è TrueTime, che riduce la comunicazione tra macchine per molti tipi di coordinamento. Inoltre, un'attenta progettazione e ottimizzazione delle prestazioni ha dato vita a un sistema altamente performante, offrendo al contempo solide garanzie. In Google abbiamo riscontrato che questo ha semplificato notevolmente lo sviluppo di applicazioni su Spanner rispetto ad altri sistemi di database con garanzie meno stringenti. Quando gli sviluppatori di applicazioni non devono preoccuparsi di condizioni di gara o incoerenze nei dati, possono concentrarsi su ciò che conta davvero: creare e rilasciare un'applicazione eccezionale.