Spanner adalah database yang skalabel, terdistribusi, dan sangat konsisten yang dibuat oleh engineer Google untuk mendukung beberapa aplikasi Google yang paling penting. Database NoSQL mengambil ide inti dari komunitas database dan sistem terdistribusi, lalu memperluasnya dengan cara baru. Spanner mengekspos layanan Spanner internal ini sebagai layanan yang tersedia secara publik di Google Cloud Platform.
Karena Spanner harus menangani persyaratan skala dan waktu aktif yang menuntut yang diberlakukan oleh aplikasi bisnis penting Google, kami mem-build Spanner dari awal menjadi database yang didistribusikan secara luas. Layanan ini dapat mencakup beberapa mesin dan beberapa data center serta region. Kami memanfaatkan distribusi ini untuk menangani set data dan beban kerja yang sangat besar, sekaligus tetap mempertahankan ketersediaan yang sangat tinggi. Kami juga bertujuan agar Spanner memberikan jaminan konsistensi ketat yang sama dengan yang diberikan oleh database tingkat perusahaan lainnya, karena kami ingin menciptakan pengalaman yang luar biasa bagi developer. Sangat mudah untuk memahami dan menulis software untuk database yang mendukung konsistensi yang kuat daripada database yang hanya mendukung konsistensi tingkat baris, konsistensi tingkat entity, atau tidak memiliki jaminan konsistensi sama sekali.
Dalam dokumen ini, kami menjelaskan secara mendetail cara kerja operasi tulis dan baca di Spanner serta cara Spanner memastikan konsistensi yang kuat.
Titik awal
Ada beberapa set data yang terlalu besar untuk dimuat di satu mesin. Ada juga skenario saat set data kecil, tetapi beban kerja terlalu berat untuk ditangani oleh satu mesin. Artinya, kita perlu menemukan cara untuk membagi data menjadi beberapa bagian terpisah yang dapat disimpan di beberapa mesin. Pendekatan kami adalah mempartisi tabel database menjadi rentang kunci yang berdekatan yang disebut bagian. Satu mesin dapat menayangkan beberapa bagian, dan ada layanan pencarian cepat untuk menentukan mesin yang menayangkan rentang kunci tertentu. Detail tentang cara data dibagi dan mesin tempat data berada bersifat transparan bagi pengguna Spanner. Hasilnya adalah sistem yang dapat memberikan latensi rendah untuk operasi baca dan tulis, bahkan dalam beban kerja yang berat, pada skala yang sangat besar.
Kami juga ingin memastikan bahwa data dapat diakses meskipun terjadi kegagalan. Untuk memastikannya, kami mereplikasi setiap bagian ke beberapa mesin di domain kegagalan yang berbeda. Replikasi yang konsisten ke berbagai salinan bagian dikelola oleh algoritma Paxos. Di Paxos, selama mayoritas replika pemungutan suara untuk pemisahan aktif, salah satu replika tersebut dapat dipilih sebagai pemimpin untuk memproses operasi tulis dan mengizinkan replika lain untuk menayangkan operasi baca.
Spanner menyediakan transaksi hanya baca dan transaksi baca-tulis. Yang pertama adalah jenis transaksi yang lebih disukai untuk operasi (termasuk pernyataan SELECT SQL) yang tidak mengubah data Anda. Transaksi hanya baca
masih memberikan konsistensi yang kuat dan beroperasi, secara default, pada
salinan terbaru data Anda. Namun, keduanya dapat berjalan tanpa memerlukan bentuk
penguncian apa pun secara internal, sehingga membuatnya lebih cepat dan lebih skalabel. Transaksi baca-tulis
digunakan untuk transaksi yang menyisipkan, memperbarui, atau menghapus data; ini
mencakup transaksi yang melakukan operasi baca, diikuti dengan operasi tulis. Transaksi tersebut masih
sangat skalabel, tetapi transaksi baca-tulis memperkenalkan penguncian dan harus
diorkestrasi oleh pemimpin Paxos. Perhatikan bahwa penguncian bersifat transparan untuk klien
Spanner.
Banyak sistem database terdistribusi sebelumnya telah memilih untuk tidak memberikan jaminan konsistensi yang kuat karena komunikasi lintas mesin yang mahal yang biasanya diperlukan. Spanner dapat memberikan snapshot yang sangat konsisten
di seluruh database menggunakan teknologi yang dikembangkan Google
yang disebut TrueTime. Seperti Flux Capacitor di mesin waktu tahun
1985, TrueTime adalah yang memungkinkan Spanner. Ini adalah API yang memungkinkan
mesin apa pun di pusat data Google mengetahui waktu global yang tepat dengan tingkat
akurasi yang tinggi (yaitu, dalam beberapa milidetik). Hal ini memungkinkan mesin Spanner yang berbeda untuk memahami pengurutan operasi transaksional (dan membuat pengurutan tersebut cocok dengan yang diamati klien) sering kali tanpa komunikasi sama sekali. Google harus melengkapi pusat datanya dengan hardware khusus
(jam atom!) agar TrueTime berfungsi. Akurasi dan presisi waktu yang dihasilkan jauh lebih tinggi daripada yang dapat dicapai oleh protokol lain (seperti NTP). Secara khusus, Spanner menetapkan stempel waktu ke semua operasi baca dan tulis. Transaksi
pada stempel waktu T1 dijamin akan mencerminkan hasil semua operasi tulis
yang terjadi sebelum T1. Jika ingin memenuhi operasi baca di T2, mesin harus
memastikan bahwa tampilan datanya sudah yang terbaru setidaknya hingga T2. Karena TrueTime, penentuan ini biasanya sangat murah. Protokol untuk
memastikan konsistensi data bersifat rumit, tetapi dibahas lebih lanjut dalam
makalah Spanner asli dan dalam
makalah ini tentang Spanner dan konsistensi.
Contoh praktis
Mari kita pelajari beberapa contoh praktis untuk melihat cara kerjanya:
CREATE TABLE ExampleTable (
Id INT64 NOT NULL,
Value STRING(MAX),
) PRIMARY KEY(Id);
Dalam contoh ini, kita memiliki tabel dengan kunci utama bilangan bulat sederhana.
| Bagi | KeyRange |
|---|---|
| 0 | [-∞,3) |
| 1 | [3,224) |
| 2 | [224.712) |
| 3 | [712,717) |
| 4 | [717,1265) |
| 5 | [1265,1724) |
| 6 | [1724,1997) |
| 7 | [1997,2456) |
| 8 | [2456,∞) |
Dengan skema untuk ExampleTable di atas, ruang kunci utama dipartisi
menjadi bagian. Misalnya: Jika ada baris di ExampleTable dengan Id
3700, baris tersebut akan berada di Bagian 8. Seperti yang dijelaskan di atas, Bagian 8 itu sendiri direplikasi di beberapa mesin.
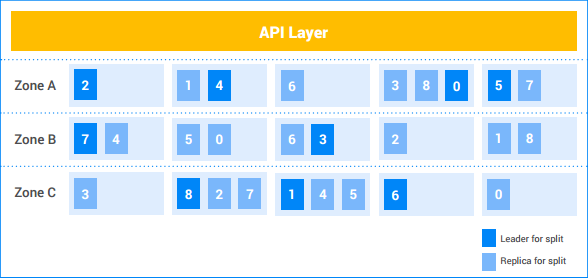
Dalam contoh instance Spanner ini, pelanggan memiliki lima node, dan instance direplikasi di tiga zona. Sembilan bagian diberi nomor 0-8, dengan pemimpin Paxos untuk setiap bagian diarsir gelap. Bagian data juga memiliki replika di setiap zona (diarsir tipis). Distribusi bagian di antara node mungkin berbeda di setiap zona, dan pemimpin Paxos tidak semuanya berada di zona yang sama. Fleksibilitas ini membantu Spanner menjadi lebih andal terhadap jenis profil beban dan mode kegagalan tertentu.
Operasi tulis bagian tunggal
Misalnya, klien ingin menyisipkan baris baru (7, "Seven") ke dalam
ExampleTable.
- Lapisan API mencari bagian yang memiliki rentang kunci yang berisi
7. Class ini berada di Split 1. - Lapisan API mengirimkan permintaan operasi tulis ke Pemimpin Bagian 1.
- Pemimpin memulai transaksi.
- Pemimpin mencoba mendapatkan kunci tulis pada baris
Id=7. Ini adalah operasi lokal. Jika transaksi baca-tulis serentak lainnya saat ini membaca baris ini, transaksi lain tersebut memiliki kunci baca dan transaksi saat ini akan diblokir hingga dapat memperoleh kunci tulis.- Mungkin transaksi A menunggu kunci yang dipegang oleh transaksi B, dan transaksi B menunggu kunci yang dipegang oleh transaksi A. Karena tidak ada transaksi yang melepaskan kunci apa pun hingga memperoleh semua kunci, hal ini dapat menyebabkan deadlock. Spanner menggunakan algoritma pencegahan deadlock "wound-wait" standar untuk memastikan transaksi membuat progres. Secara khusus, transaksi "lebih baru" akan menunggu kunci yang dipegang oleh transaksi "lebih lama", tetapi transaksi "lebih lama" akan "menghentikan" (membatalkan) transaksi yang lebih baru yang memegang kunci yang diminta oleh transaksi yang lebih lama. Oleh karena itu, kita tidak pernah mengalami siklus deadlock dari penunggu kunci.
- Setelah kunci diperoleh, Pemimpin menetapkan stempel waktu ke transaksi
berdasarkan TrueTime.
- Stempel waktu ini dijamin lebih besar dari transaksi yang di-commit sebelumnya yang menyentuh data. Hal ini memastikan bahwa urutan transaksi (seperti yang dirasakan oleh klien) cocok dengan urutan perubahan pada data.
- Pemimpin memberi tahu replika Bagian 1 tentang transaksi dan stempel waktunya. Setelah sebagian besar replika tersebut menyimpan mutasi transaksi dalam penyimpanan stabil (dalam sistem file terdistribusi), transaksi akan di-commit. Hal ini memastikan bahwa transaksi dapat dipulihkan, meskipun terjadi kegagalan di sebagian kecil mesin. (Replika belum menerapkan mutasi ke salinan datanya.)
Pemimpin menunggu hingga dapat memastikan bahwa stempel waktu transaksi telah diteruskan secara real time; hal ini biasanya memerlukan beberapa milidetik sehingga kita dapat menunggu ketidakpastian dalam stempel waktu TrueTime. Hal ini yang memastikan konsistensi yang kuat—setelah klien mempelajari hasil transaksi, semua pembaca lainnya akan melihat efek transaksi tersebut. "Proses tunggu commit" ini biasanya tumpang-tindih dengan komunikasi replika pada langkah di atas, sehingga biaya latensi sebenarnya minimal. Detail selengkapnya dibahas dalam makalah ini.
Pemimpin membalas klien untuk menyatakan bahwa transaksi telah di-commit, secara opsional melaporkan stempel waktu commit transaksi.
Secara paralel dengan membalas klien, mutasi transaksi diterapkan ke data.
- Pemimpin menerapkan mutasi ke salinan datanya, lalu melepaskan kunci transaksinya.
- Pemimpin juga memberi tahu replika Bagian 1 lainnya untuk menerapkan mutasi ke salinan data mereka.
- Setiap transaksi baca-tulis atau hanya baca yang akan melihat efek mutasi menunggu hingga mutasi diterapkan sebelum mencoba membaca data. Untuk transaksi baca-tulis, hal ini diterapkan karena transaksi harus mengambil kunci baca. Untuk transaksi hanya baca, hal ini diberlakukan dengan membandingkan stempel waktu baca dengan data terbaru yang diterapkan.
Semua ini biasanya terjadi dalam beberapa milidetik. Operasi tulis ini adalah jenis operasi tulis termurah yang dilakukan oleh Spanner, karena hanya melibatkan satu bagian.
Penulisan multi-bagian
Jika ada beberapa pemisahan, lapisan koordinasi tambahan (menggunakan algoritma commit dua fase standar) diperlukan.
Misalnya, tabel berisi empat ribu baris:
| 1 | "one" |
| 2 | "two" |
| ... | ... |
| 4000 | "four thousand" |
Dan misalkan klien ingin membaca nilai untuk baris 1000 dan menulis
nilai ke baris 2000, 3000, dan 4000 dalam transaksi. Hal ini akan
dijalankan dalam transaksi baca-tulis sebagai berikut:
- Klien memulai transaksi baca-tulis, t.
- Klien mengeluarkan permintaan baca untuk baris 1000 ke Lapisan API dan memberi tag sebagai bagian dari t.
- Lapisan API mencari bagian yang memiliki kunci
1000. File ini berada di Bagian 4. Lapisan API mengirimkan permintaan baca ke Pemimpin Bagian 4 dan memberi tag sebagai bagian dari t.
Pemimpin Bagian 4 mencoba mendapatkan kunci baca pada baris
Id=1000. Tindakan ini adalah operasi lokal. Jika transaksi serentak lainnya memiliki kunci tulis pada baris ini, transaksi saat ini akan diblokir hingga dapat memperoleh kunci. Namun, kunci baca ini tidak mencegah transaksi lain mendapatkan kunci baca.- Seperti dalam kasus pemisahan tunggal, deadlock dicegah melalui "wound-wait".
Leader mencari nilai untuk
Id1000("Seribu") dan menampilkan hasil pembacaan ke klien.
Nanti...Klien mengeluarkan permintaan Commit untuk transaksi t. Permintaan commit ini berisi 3 mutasi: (
[2000, "Dos Mil"],[3000, "Tres Mil"], dan[4000, "Quatro Mil"]).- Semua bagian yang terlibat dalam transaksi menjadi peserta dalam
transaksi. Dalam hal ini, Bagian 4 (yang menyalurkan operasi baca untuk kunci
1000), Bagian 7 (yang akan menangani mutasi untuk kunci2000), dan Bagian 8 (yang akan menangani mutasi untuk kunci3000dan kunci4000) adalah peserta.
- Semua bagian yang terlibat dalam transaksi menjadi peserta dalam
transaksi. Dalam hal ini, Bagian 4 (yang menyalurkan operasi baca untuk kunci
Satu peserta menjadi koordinator. Dalam hal ini, mungkin pemimpin untuk Bagian 7 menjadi koordinator. Tugas koordinator adalah memastikan transaksi di-commit atau dibatalkan secara atomik pada semua peserta. Artinya, tidak akan melakukan commit pada satu peserta dan membatalkan pada peserta lain.
- Pekerjaan yang dilakukan oleh peserta dan koordinator sebenarnya dilakukan oleh mesin pemimpin bagian tersebut.
Peserta memperoleh kunci. (Ini adalah fase pertama dari commit dua fase.)
- Bagian 7 memperoleh kunci tulis pada kunci
2000. - Bagian 8 memperoleh kunci tulis pada kunci
3000dan kunci4000. - Bagian 4 memverifikasi bahwa bagian tersebut masih memegang kunci baca pada kunci
1000(dengan kata lain, bahwa kunci tidak hilang karena error mesin atau algoritma wound-wait.) - Setiap bagian peserta mencatat kumpulan kuncinya dengan mereplikasinya ke (setidaknya) sebagian besar replika bagian. Hal ini memastikan kunci dapat tetap dipegang meskipun terjadi kegagalan server.
- Jika semua peserta berhasil memberi tahu koordinator bahwa kunci mereka ditahan, maka keseluruhan transaksi dapat di-commit. Hal ini memastikan adanya titik waktu saat semua kunci yang diperlukan oleh transaksi dipegang, dan titik waktu ini menjadi titik commit transaksi, yang memastikan bahwa kita dapat mengurutkan efek transaksi ini dengan benar terhadap transaksi lain yang terjadi sebelum atau sesudahnya.
- Mungkin kunci tidak dapat diperoleh (misalnya, jika kita mengetahui bahwa mungkin ada deadlock melalui algoritma wound-wait). Jika ada peserta yang mengatakan bahwa transaksi tidak dapat di-commit, seluruh transaksi akan dibatalkan.
- Bagian 7 memperoleh kunci tulis pada kunci
Jika semua peserta, dan koordinator, berhasil memperoleh kunci, Koordinator (Bagian 7) memutuskan untuk melakukan transaksi. Fungsi ini menetapkan stempel waktu ke transaksi berdasarkan TrueTime.
- Keputusan commit ini, serta mutasi untuk kunci
2000, direplikasi ke anggota Bagian 7. Setelah sebagian besar replika Split 7 mencatat keputusan commit ke penyimpanan yang stabil, transaksi akan di-commit.
- Keputusan commit ini, serta mutasi untuk kunci
Koordinator menyampaikan hasil transaksi kepada semua Peserta. (Ini adalah fase kedua dari commit dua fase.)
- Setiap pemimpin peserta mereplikasi keputusan commit ke replika pembagian peserta.
Jika transaksi di-commit, Koordinator dan semua Peserta akan menerapkan mutasi ke data.
- Seperti dalam kasus pemisahan tunggal, pembaca data berikutnya di Koordinator atau Peserta harus menunggu hingga data diterapkan.
Pemimpin koordinator membalas klien untuk menyatakan bahwa transaksi telah di-commit, secara opsional menampilkan stempel waktu commit transaksi
- Seperti dalam kasus pemisahan tunggal, hasilnya dikomunikasikan kepada klien setelah menunggu commit, untuk memastikan konsistensi yang kuat.
Semua ini biasanya terjadi dalam beberapa milidetik, meskipun biasanya lebih lama daripada dalam kasus pemisahan tunggal karena koordinasi lintas pemisahan tambahan.
Pembacaan andal (multi-bagian)
Misalkan klien ingin membaca semua baris dengan Id >= 0 dan Id < 700 sebagai
bagian dari transaksi hanya baca.
- Lapisan API mencari bagian yang memiliki kunci apa pun dalam rentang
[0, 700). Baris ini dimiliki oleh Bagian 0, Bagian 1, dan Bagian 2. - Karena ini adalah pembacaan yang kuat di beberapa mesin, Lapisan API memilih
stempel waktu baca menggunakan TrueTime saat ini. Hal ini memastikan bahwa kedua pembacaan
menampilkan data dari snapshot database yang sama.
- Jenis pembacaan lainnya, seperti pembacaan yang sudah tidak berlaku, juga memilih stempel waktu untuk dibaca (tetapi stempel waktu mungkin sudah lama).
- Lapisan API mengirimkan permintaan baca ke beberapa replika Bagian 0, beberapa replika Bagian 1, dan beberapa replika Bagian 2. File ini juga menyertakan stempel waktu baca yang telah dipilih pada langkah di atas.
Untuk pembacaan yang kuat, replika penayangan biasanya membuat RPC ke pemimpin untuk meminta stempel waktu transaksi terakhir yang perlu diterapkan dan pembacaan dapat dilanjutkan setelah transaksi tersebut diterapkan. Jika replika adalah pemimpin atau menentukan bahwa replika sudah cukup untuk melayani permintaan dari status internal dan TrueTime, replika akan langsung melayani operasi baca.
Hasil dari replika digabungkan dan ditampilkan ke klien (melalui lapisan API).
Perhatikan bahwa operasi baca tidak memperoleh kunci apa pun dalam transaksi hanya baca. Selain itu, karena pembacaan berpotensi ditayangkan oleh replika terbaru dari bagian tertentu, throughput pembacaan sistem berpotensi sangat tinggi. Jika klien dapat mentoleransi pembacaan yang sudah tidak berlaku setidaknya sepuluh detik, throughput baca dapat lebih tinggi. Karena pemimpin biasanya memperbarui replika dengan stempel waktu aman terbaru setiap sepuluh detik, pembacaan pada stempel waktu yang sudah tidak berlaku dapat menghindari RPC tambahan ke pemimpin.
Kesimpulan
Secara tradisional, desainer sistem database terdistribusi telah menemukan bahwa jaminan transaksional yang kuat harganya mahal, karena semua komunikasi lintas mesin yang diperlukan. Dengan Spanner, kami telah berfokus untuk mengurangi biaya transaksi agar dapat dilakukan dalam skala besar dan terlepas dari distribusi. Alasan utama hal ini berhasil adalah TrueTime, yang mengurangi komunikasi lintas mesin untuk banyak jenis koordinasi. Selain itu, rekayasa yang cermat dan penyesuaian performa telah menghasilkan sistem yang berperforma tinggi, sekaligus memberikan jaminan yang kuat. Di Google, kami mendapati bahwa hal ini telah sangat memudahkan pengembangan aplikasi di Spanner dibandingkan dengan sistem database lain yang memiliki jaminan yang lebih lemah. Jika developer aplikasi tidak perlu khawatir tentang kondisi race atau inkonsistensi dalam data mereka, mereka dapat berfokus pada hal yang benar-benar mereka minati—mem-build dan mengirimkan aplikasi yang hebat.