Client
Spanner supporta le query SQL. Ecco una query di esempio:
SELECT s.SingerId, s.FirstName, s.LastName, s.SingerInfo
FROM Singers AS s
WHERE s.FirstName = @firstName;
La struttura @firstName è un riferimento a un parametro di query. Puoi utilizzare un parametro di query ovunque sia possibile utilizzare un valore letterale. Ti consigliamo vivamente di utilizzare i parametri nelle API programmatiche. L'utilizzo dei parametri di query consente di evitare gli attacchi di SQL injection e le query risultanti hanno maggiori probabilità di trarre vantaggio da varie cache lato server. Consulta la sezione Memorizzazione nella cache di seguito.
I parametri di query devono essere associati a un valore quando la query viene eseguita. Ad esempio:
Statement statement =
Statement.newBuilder("SELECT s.SingerId...").bind("firstName").to("Jimi").build();
try (ResultSet resultSet = dbClient.singleUse().executeQuery(statement)) {
while (resultSet.next()) {
...
}
}
Quando Spanner riceve una chiamata API, analizza la query e i parametri vincolati per determinare quale nodo del server Spanner deve elaborare la query. Il server restituisce uno stream di righe di risultati che vengono utilizzate dalle chiamate a ResultSet.next().
Esecuzione delle query
L'esecuzione della query inizia con l'arrivo di una richiesta di "esecuzione query" su un server Spanner. Il server esegue i seguenti passaggi:
- Convalida la richiesta
- Analizza il testo della query
- Genera un'algebra di query iniziale
- Genera un'algebra delle query ottimizzata
- Generare un piano di query eseguibile
- Esegui il piano (controlla le autorizzazioni, leggi i dati, codifica i risultati e così via)
Analisi
Il parser SQL analizza il testo della query e lo converte in un albero di sintassi astratta. Estrae la struttura di query di base (SELECT …
FROM … WHERE …) ed esegue controlli sintattici.
Algebra
Il sistema di tipi di Spanner può rappresentare scalari, array, strutture e così via. L'algebra delle query definisce operatori per scansioni di tabelle, filtri, ordinamento/raggruppamento, tutti i tipi di join, aggregazione e molto altro. L'algebra delle query iniziale viene creata dall'output del parser. I riferimenti ai nomi dei campi nella struttura di analisi vengono risolti utilizzando lo schema del database. Questo codice controlla anche gli errori semantici (ad es. numero errato di parametri, mancata corrispondenza dei tipi e così via).
Il passaggio successivo ("ottimizzazione delle query") prende l'algebra iniziale e genera un'algebra più ottimale. Potrebbe essere più semplice, più efficiente o semplicemente più adatto alle funzionalità del motore di esecuzione. Ad esempio, l'algebra iniziale potrebbe specificare solo un "join", mentre l'algebra ottimizzata specifica un "join hash".
Esecuzione
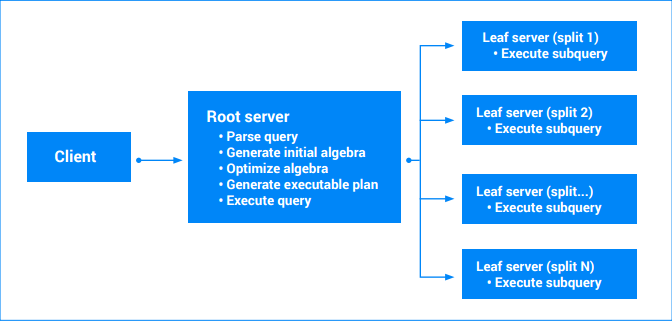
Il piano di query eseguibile finale viene creato dall'algebra riscritta. In sostanza, il piano eseguibile è un grafo aciclico diretto di "iteratori". Ogni iteratore espone una sequenza di valori. Gli iteratori possono consumare input per produrre output (ad es. l'iteratore di ordinamento). Le query che prevedono un singolo split possono essere eseguite da un singolo server (quello che contiene i dati). Il server eseguirà la scansione di intervalli di varie tabelle, eseguirà join, aggregazione e tutte le altre operazioni definite dall'algebra delle query.
Le query che prevedono più suddivisioni verranno prese in considerazione in più parti. Alchuma parte della query continuerà a essere eseguita sul server principale (root). Altre subquery parziali vengono trasferite ai nodi foglia (quelli che possiedono le suddivisioni in fase di lettura). Questo trasferimento può essere applicato in modo ricorsivo per query complesse, generando un albero di esecuzioni del server. Tutti i server concordano su un timestamp in modo che i risultati della query siano uno snapshot coerente dei dati. Ogni server secondario invia un flusso di risultati parziali. Per le query che richiedono l'aggregazione, potrebbero essere risultati parzialmente aggregati. Il server radice della query elabora i risultati dei server a foglia ed esegue il resto del piano di query. Per ulteriori informazioni, consulta Piani di esecuzione delle query.
Quando una query prevede più suddivisioni, Spanner può eseguirla in parallelo nelle suddivisioni. Il grado di parallelismo dipende dall'intervallo di dati sottoposti a scansione dalla query, dal piano di esecuzione della query e dalla distribuzione dei dati tra le suddivisioni. Spanner imposta automaticamente il grado massimo di parallelismo per una query in base alle dimensioni e alla configurazione dell'istanza (regionale o multi-regionale) per ottenere prestazioni ottimali delle query ed evitare di sovraccaricare la CPU.
Memorizzazione nella cache
Molti degli elementi dell'elaborazione delle query vengono memorizzati nella cache e riutilizzati automaticamente per le query successive. Sono inclusi algebra delle query, piani di query eseguibili e così via. La memorizzazione nella cache si basa sul testo della query, sui nomi e sui tipi di parametri vincolati e così via. Ecco perché è preferibile utilizzare i parametri vincolati (come @firstName nell'esempio precedente) rispetto all'utilizzo di valori letterali nel testo della query. Il primo può essere memorizzato nella cache una volta e riutilizzato indipendentemente dal valore vincolato effettivo. Per ulteriori dettagli, consulta
Ottimizzazione delle prestazioni delle query di Spanner.
Gestione degli errori
Lo stream di righe di risultati del metodo executeQuery può essere interrotto per diversi motivi: errori di rete temporanei, trasferimento di un split da un server a un altro (ad es. bilanciamento del carico), riavvii del server (ad es. upgrade a una nuova versione) e così via. Per aiutarti a recuperare da questi errori, Spanner invia "token di ripresa" opachi insieme a batch di dati parziali dei risultati. Questi token di ripresa possono essere utilizzati quando si ritenta la query per continuare da dove si è interrotta. Se utilizzi le librerie client Spanner, questa operazione viene eseguita automaticamente. Pertanto, gli utenti della libreria client non devono preoccuparsi di questo tipo di errore transitorio.